Taken verzenden en beheren op een Apache Spark-cluster™ in HDInsight in AKS
Notitie
Op 31 januari 2025 wordt Azure HDInsight buiten gebruik gesteld op AKS. Vóór 31 januari 2025 moet u uw workloads migreren naar Microsoft Fabric of een gelijkwaardig Azure-product om te voorkomen dat uw workloads plotseling worden beëindigd. De resterende clusters in uw abonnement worden gestopt en verwijderd van de host.
Alleen basisondersteuning is beschikbaar tot de buitengebruikstellingsdatum.
Belangrijk
Deze functie is momenteel beschikbaar in preview. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews bevatten meer juridische voorwaarden die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet beschikbaar zijn in algemene beschikbaarheid. Zie Azure HDInsight op AKS Preview-informatie voor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight met de details en volgt u ons voor meer updates in de Azure HDInsight-community.
Zodra het cluster is gemaakt, kan de gebruiker verschillende interfaces gebruiken om taken te verzenden en te beheren door
- jupyter gebruiken
- met Behulp van Zeppelin
- ssh gebruiken (spark-submit)
Jupyter gebruiken
Vereisten
Een Apache Spark-cluster™ in HDInsight op AKS. Zie Een Apache Spark-cluster maken voor meer informatie.
Jupyter Notebook is een interactieve notitieblokomgeving die ondersteuning biedt voor verschillende programmeertalen.
Een Jupyter Notebook maken
Ga naar de pagina van het Apache Spark-cluster™ en open het tabblad Overzicht . Klik op Jupyter. U wordt gevraagd om de Jupyter-webpagina te verifiëren en te openen.

Selecteer nieuw > PySpark op de Jupyter-webpagina om een notebook te maken.
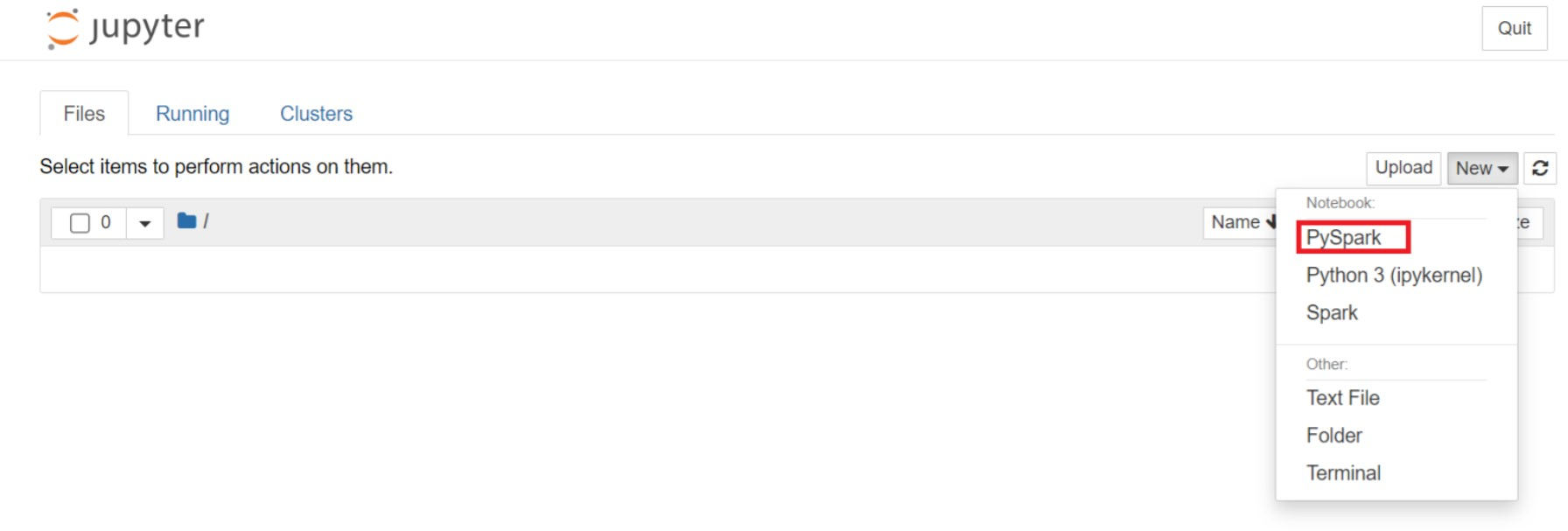
Er is een nieuw notitieblok gemaakt en geopend met de naam
Untitled(Untitled.ipynb).Notitie
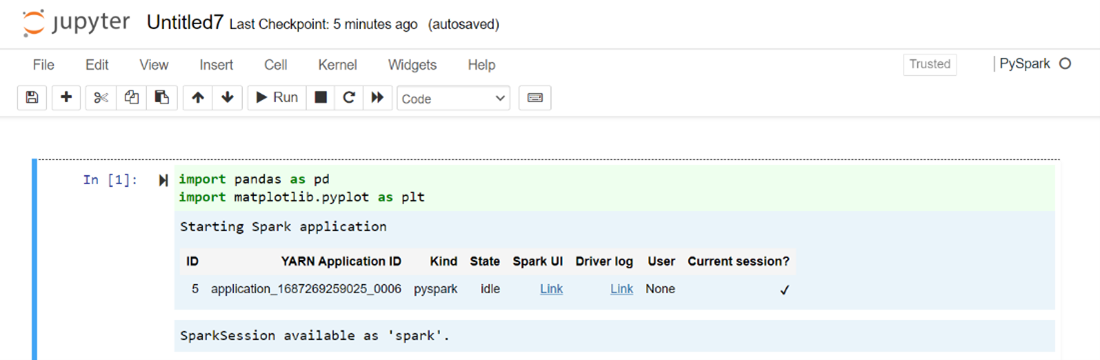
Door de PySpark- of python 3-kernel te gebruiken om een notebook te maken, wordt de Spark-sessie automatisch voor u gemaakt wanneer u de eerste codecel uitvoert. U hoeft de sessie dus niet expliciet te maken.
Plak de volgende code in een lege cel van het Jupyter-notebook en druk op Shift + Enter om de code uit te voeren. Zie hier voor meer besturingselementen op Jupyter.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Een grafiek met salaris en leeftijd uitzetten als de X- en Y-assen
Plak in hetzelfde notebook de volgende code in een lege cel van het Jupyter Notebook en druk op Shift+Enter om de code uit te voeren.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()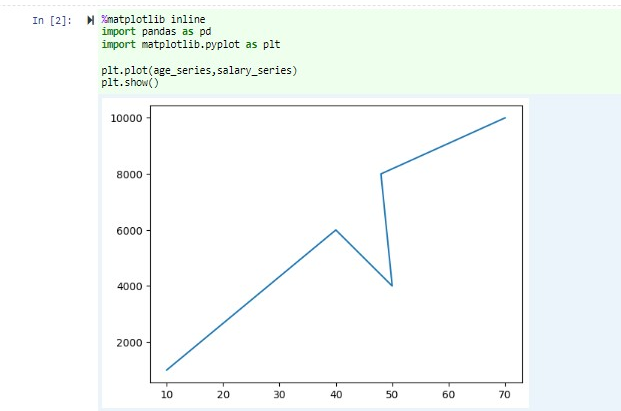




Het notitieblok opslaan
Navigeer in de menubalk van het notitieblok naar Bestand > opslaan en Controlepunt.
Sluit het notebook af om de clusterbronnen vrij te geven: ga in de menubalk van het notitieblok naar Bestand > sluiten en Stoppen. U kunt ook een van de notebooks uitvoeren in de map met voorbeelden.


Apache Zeppelin-notebooks gebruiken
Apache Spark-clusters in HDInsight in AKS bevatten Apache Zeppelin-notebooks. Gebruik de notebooks om Apache Spark-taken uit te voeren. In dit artikel leert u hoe u het Zeppelin-notebook gebruikt in een HDInsight op een AKS-cluster.
Vereisten
Een Apache Spark-cluster in HDInsight op AKS. Zie Een Apache Spark-cluster maken voor instructies.
Een Apache Zeppelin-notebook starten
Navigeer naar de overzichtspagina van het Apache Spark-cluster en selecteer Zeppelin-notebook in clusterdashboards. Er wordt gevraagd om de Zeppelin-pagina te verifiëren en te openen.
Maak een nieuwe notebook. Navigeer in het koptekstvenster naar Notitieblok Nieuwe notitieblok > maken. Zorg ervoor dat de koptekst van het notitieblok een verbonden status weergeeft. Het geeft een groene stip aan in de rechterbovenhoek.
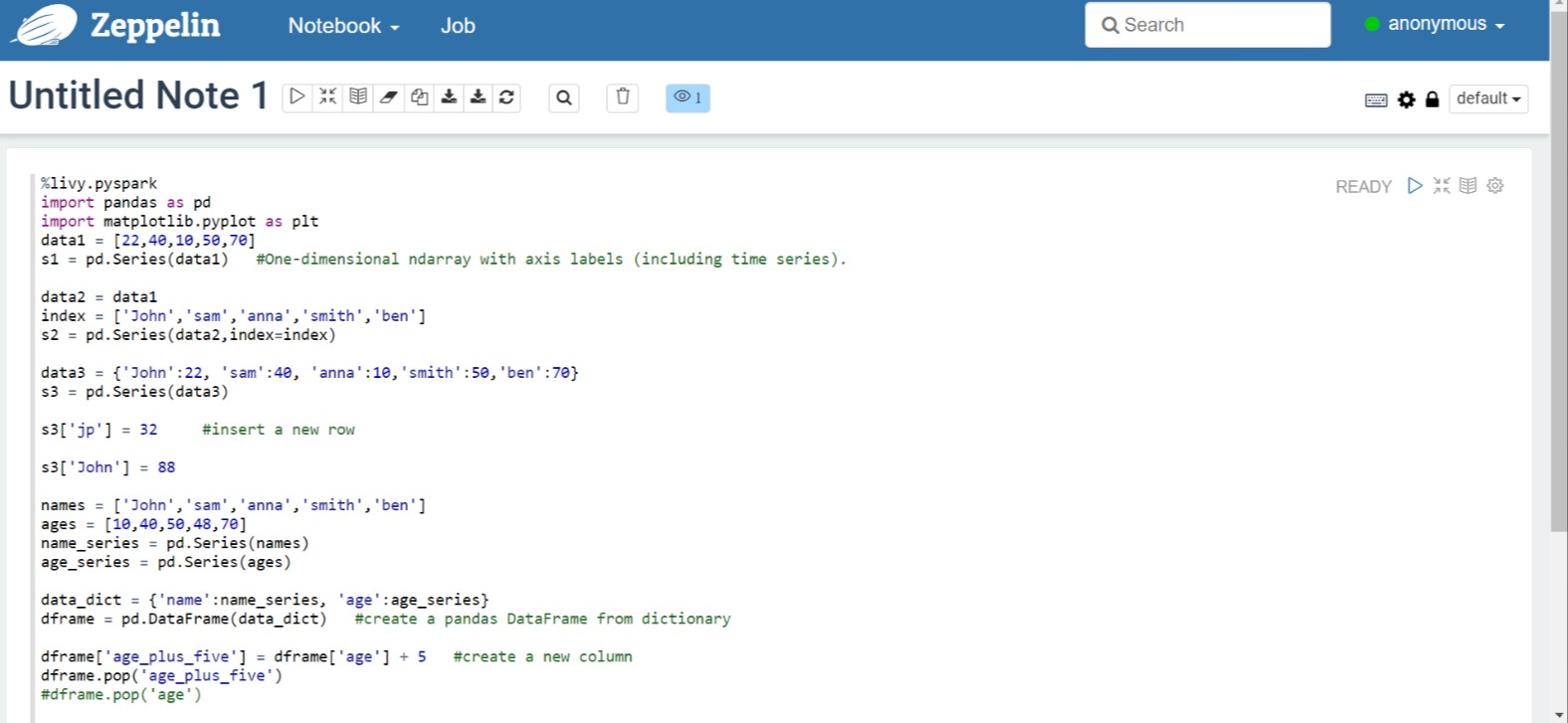
Voer de volgende code uit in Zeppelin Notebook:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Selecteer de knop Afspelen voor de alinea om het fragment uit te voeren. De status in de rechterhoek van de alinea moet worden uitgevoerd van GEREED, IN BEHANDELING tot VOLTOOID. De uitvoer wordt onder aan dezelfde alinea weergegeven. De schermopname ziet er als volgt uit:
Uitvoer:





Spark-taken verzenden gebruiken
Maak een bestand met behulp van de volgende opdracht '#vim samplefile.py'
Met deze opdracht opent u het vim-bestand
Plak de volgende code in het vim-bestand
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Sla het bestand op met de volgende methode.
- Druk op de knop Escape
- Voer de opdracht in
:wq
Voer de volgende opdracht uit om de taak uit te voeren.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Query's bewaken op een Apache Spark-cluster in HDInsight in AKS
Gebruikersinterface voor Spark-geschiedenis
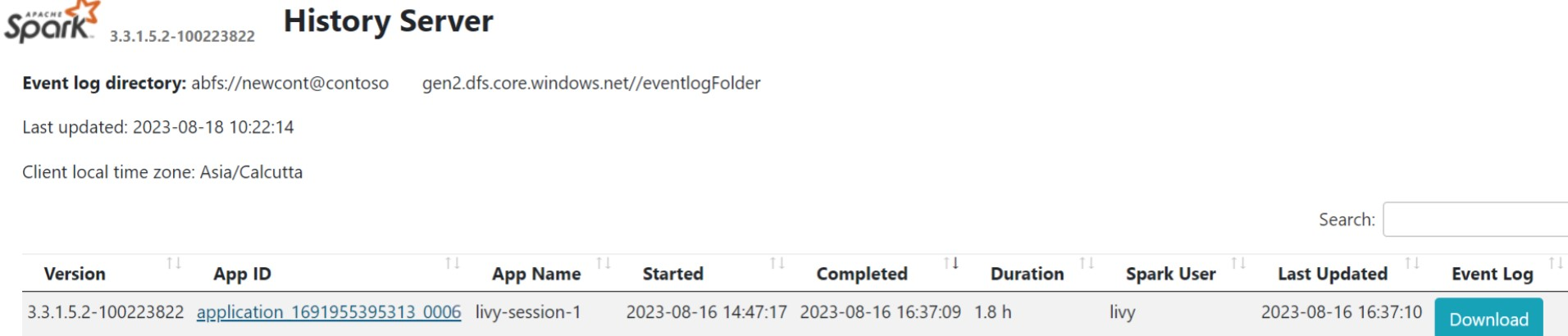
Klik op de gebruikersinterface van Spark History Server op het tabblad Overzicht.

Selecteer de recente uitvoering in de gebruikersinterface met dezelfde toepassings-id.
Bekijk de gerichte Acyclic Graph-cycli en de fasen van de taak in de gebruikersinterface van de Spark History-server.
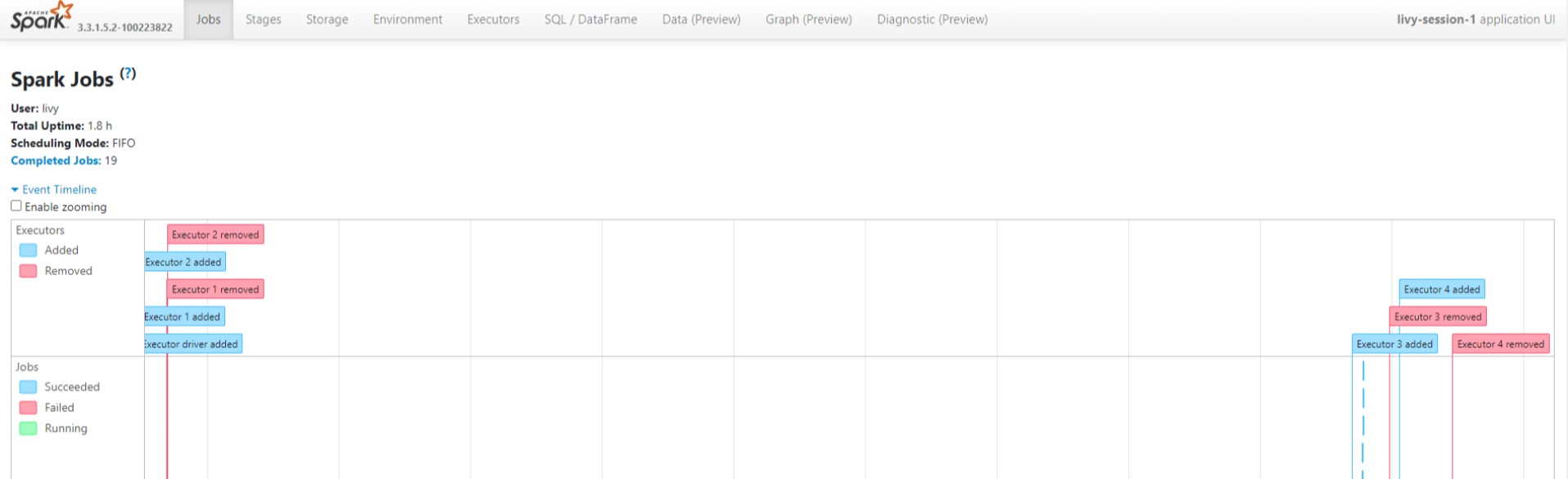



Gebruikersinterface van Livy-sessie
Als u de gebruikersinterface van de Livy-sessie wilt openen, typt u de volgende opdracht in uw browser
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui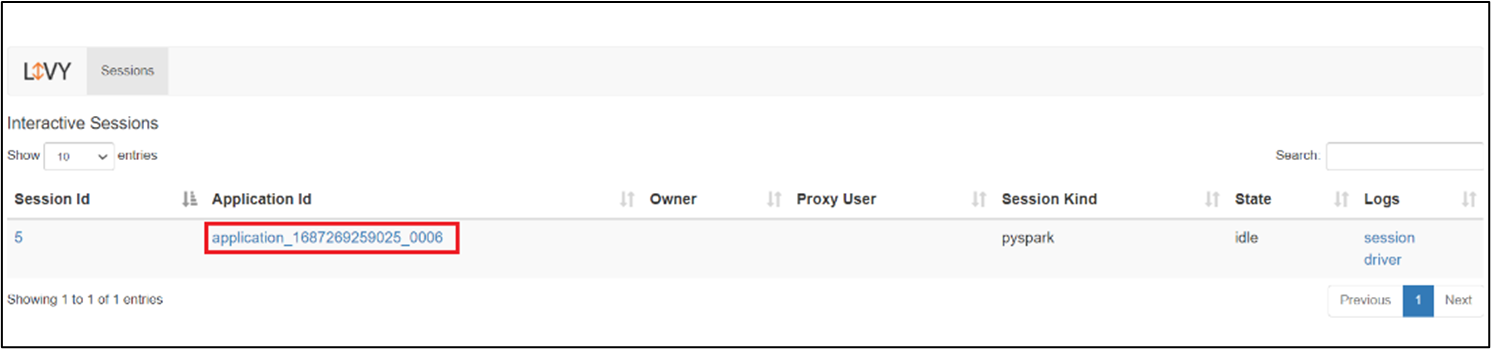
Bekijk de stuurprogrammalogboeken door te klikken op de optie stuurprogramma onder logboeken.

Yarn-gebruikersinterface
Klik op het tabblad Overzicht op Yarn en open de Yarn-gebruikersinterface.
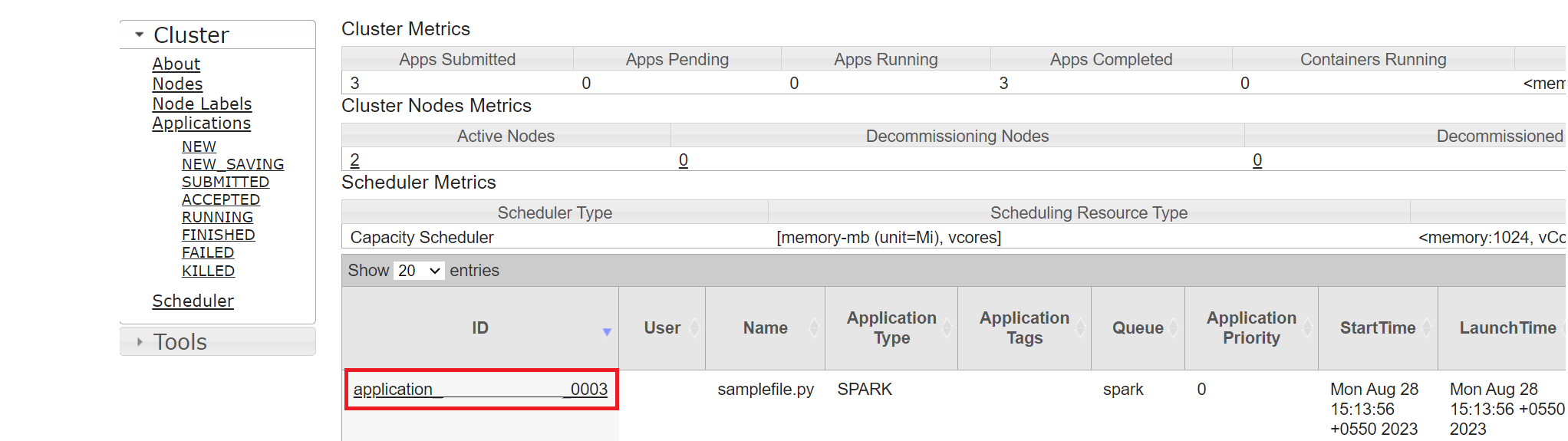
U kunt de taak bijhouden die u onlangs hebt uitgevoerd met dezelfde toepassings-id.
Klik op de toepassings-id in Yarn om gedetailleerde logboeken van de taak weer te geven.


Verwijzing
- Apache, Apache Spark, Spark en bijbehorende opensource-projectnamen zijn handelsmerken van de Apache Software Foundation (ASF).