Wat is Apache Spark™ in HDInsight in AKS? (Preview)
Notitie
Op 31 januari 2025 wordt Azure HDInsight buiten gebruik gesteld op AKS. Vóór 31 januari 2025 moet u uw workloads migreren naar Microsoft Fabric of een gelijkwaardig Azure-product om te voorkomen dat uw workloads plotseling worden beëindigd. De resterende clusters in uw abonnement worden gestopt en verwijderd van de host.
Alleen basisondersteuning is beschikbaar tot de buitengebruikstellingsdatum.
Belangrijk
Deze functie is momenteel beschikbaar in preview. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews bevatten meer juridische voorwaarden die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet beschikbaar zijn in algemene beschikbaarheid. Zie Azure HDInsight op AKS Preview-informatie voor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight met de details en volgt u ons voor meer updates in de Azure HDInsight-community.
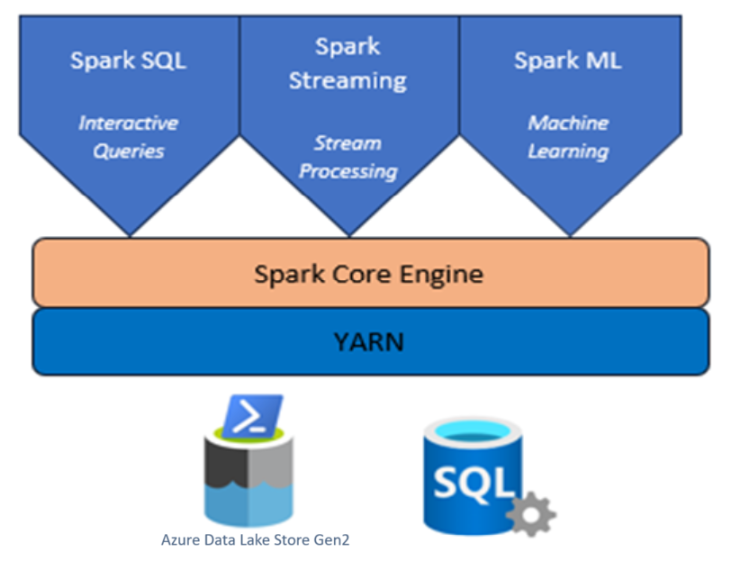
Apache Spark™ is een framework voor parallelle verwerking dat ondersteuning biedt voor in-memory verwerking om de prestaties van analysetoepassingen voor big data te verbeteren.
Apache Spark™ biedt primitieven voor clustercomputing in het geheugen. Een Spark-taak kan gegevens laden en in het geheugen cachen en er herhaaldelijk query’s op uitvoeren. In-memory computing is sneller dan op schijven gebaseerde toepassingen, zoals Hadoop, die gegevens deelt via Hadoop Distributed File System (HDFS). Met Apache Spark kunt u met de programmeertalen Scala en Python gedistribueerde gegevenssets bewerken, zoals lokale verzamelingen. Het is niet nodig om alles te structureren als toewijzings- en verminderingsbewerkingen.
Apache Spark-cluster met HDInsight in AKS
Azure HDInsight is een beheerde, zeer uitgebreide open-source analyseservice voor bedrijven.
Apache Spark™ in Azure HDInsight in AKS is de beheerde Spark-service in Microsoft Azure. Met Apache Spark in Azure HDInsight in AKS kunt u uw gegevens allemaal in Azure opslaan en verwerken. Spark-clusters in HDInsight zijn compatibel met of Met Azure Data Lake Storage Gen2 kunt u Spark-verwerking toepassen op uw bestaande gegevensarchieven.
Het Apache Spark-framework voor HDInsight in AKS maakt snelle gegevensanalyse en clustercomputing mogelijk met behulp van in-memory verwerking. Via Jupyter Notebook kunt u met uw gegevens werken, code combineren met markdown-tekst en eenvoudige visualisaties uitvoeren.
Apache Spark in AKS in HDInsight bestaat uit meerdere onderdelen als pods.
Clustercontrollers
Clustercontrollers zijn verantwoordelijk voor het installeren en beheren van de respectieve service. Verschillende controllers worden geïnstalleerd en beheerd in een Spark-cluster.
Apache Spark-serviceonderdelen
Zookeeper-service: Een Zookeeper-cluster met drie knooppunten fungeert als gedistribueerde coördinator of opslag met hoge beschikbaarheid voor andere services.
Yarn-service: Hadoop Yarn-cluster, Spark-taken worden gepland in het cluster als Yarn-toepassingen.
Clientinterfaces: Apache Spark-clusters in HDInsight op AKS bieden verschillende clientinterfaces. Livy Server, Jupyter Notebook, Spark History Server, biedt Spark-services aan HDInsight op AKS-gebruikers.
Verwijzing
- Apache, Apache Spark, Spark en bijbehorende opensource-projectnamen zijn handelsmerken van de Apache Software Foundation (ASF).