HDInsight automatisch schalen op AKS-clusters
Notitie
Op 31 januari 2025 wordt Azure HDInsight buiten gebruik gesteld op AKS. Vóór 31 januari 2025 moet u uw workloads migreren naar Microsoft Fabric of een gelijkwaardig Azure-product om te voorkomen dat uw workloads plotseling worden beëindigd. De resterende clusters in uw abonnement worden gestopt en verwijderd van de host.
Alleen basisondersteuning is beschikbaar tot de buitengebruikstellingsdatum.
Belangrijk
Deze functie is momenteel beschikbaar in preview. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews bevatten meer juridische voorwaarden die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet beschikbaar zijn in algemene beschikbaarheid. Zie Azure HDInsight op AKS Preview-informatie voor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight met de details en volgt u ons voor meer updates in de Azure HDInsight-community.
Het aanpassen van de grootte van een cluster om te voldoen aan de prestaties van de taak en het beheren van de kosten van tevoren is altijd lastig en moeilijk te bepalen! Een van de lucratieve voordelen van het bouwen van Data Lake House via Cloud is de elasticiteit, wat betekent dat u de functie voor automatisch schalen kunt gebruiken om het gebruik van resources bij de hand te maximaliseren. Automatisch schalen met Kubernetes is een belangrijke sleutel voor het tot stand brengen van een ecosysteem dat is geoptimaliseerd voor kosten. Met verschillende gebruikspatronen in elke onderneming kunnen er in de loop van de tijd variaties in clusterbelastingen zijn die ertoe kunnen leiden dat clusters te weinig worden ingericht (slechte prestaties) of overprovisioned (onnodige kosten vanwege niet-actieve resources).
De functie voor automatisch schalen die in HDInsight op AKS wordt aangeboden, kan het aantal werkknooppunten in uw cluster automatisch vergroten of verkleinen. Automatisch schalen maakt gebruik van de metrische clustergegevens en het schaalbeleid dat door de klanten wordt gebruikt.
Deze functie is zeer geschikt voor bedrijfskritieke workloads, die mogelijk
- Variabele of onvoorspelbare verkeerspatronen en vereisen SLA's op hoge prestaties en schaal of
- Vooraf vastgestelde planning voor vereiste werkknooppunten die beschikbaar zijn om de taken in het cluster uit te voeren.
Automatisch schalen met HDInsight op AKS-clusters maakt de clusters kostenefficiënt en elastisch in Azure.
Met automatisch schalen kunnen klanten clusters omlaag schalen zonder dat dit van invloed is op workloads. Het is ingeschakeld met geavanceerde mogelijkheden, zoals een respijtende buitengebruikstelling en koelperiode. Met deze mogelijkheden kunnen gebruikers weloverwogen keuzes maken over het toevoegen en verwijderen van knooppunten op basis van de huidige belasting van het cluster.
Hoe het werkt
Deze functie werkt door het aantal knooppunten binnen vooraf ingestelde limieten te schalen op basis van metrische clustergegevens of een gedefinieerd schema voor opschalen en omlaag schalen. Er zijn twee soorten voorwaarden voor het activeren van gebeurtenissen voor automatisch schalen: triggers op basis van drempelwaarden voor verschillende metrische gegevens voor clusterprestaties (op basis van belasting) en tijdgebaseerde triggers (ook wel schaalaanpassing op basis van planning genoemd).
Op belasting gebaseerde schaalaanpassing wijzigt het aantal knooppunten in uw cluster, binnen een bereik dat u instelt, om optimaal CPU-gebruik te garanderen en de lopende kosten te minimaliseren.
Op schema's gebaseerde schaalaanpassing wijzigt het aantal knooppunten in uw cluster op basis van een schema van omhoog en omlaag schalen.
Notitie
Automatisch schalen biedt geen ondersteuning voor het wijzigen van het SKU-type van een bestaand cluster.
Clustercompatibiliteit
In de volgende tabel worden de clustertypen beschreven die compatibel zijn met de functie Automatisch schalen en wat er beschikbaar of gepland is.
| Workload | Op basis van belasting | Op basis van planning |
|---|---|---|
| Flink | Gepland | Ja |
| Trino | Ja** | Ja** |
| Spark | Ja** | Ja** |
**Graceful uit bedrijf nemen is configureerbaar.
Schaalmethoden
Schaalaanpassing op basis van een planning:
Wanneer uw taken naar verwachting worden uitgevoerd volgens vaste planningen en voor een voorspelbare duur of wanneer u een laag gebruik verwacht tijdens specifieke tijdstippen van de dag, bijvoorbeeld test- en ontwikkelomgevingen in werkuren, einde van de dagtaken.
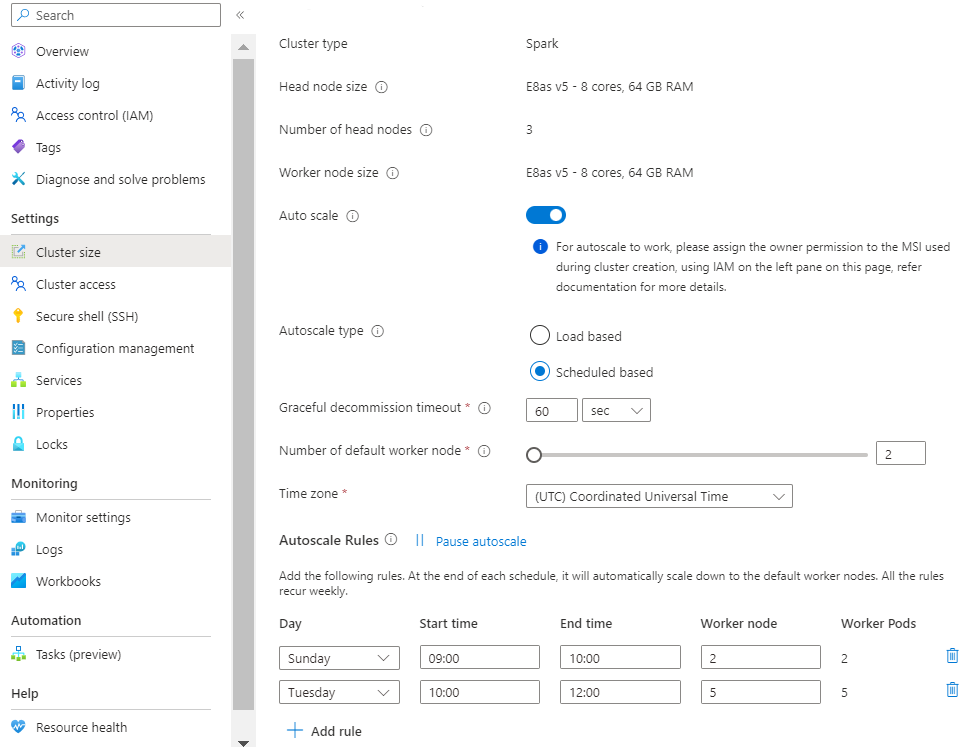
Schaal op basis van belasting:
Wanneer de belastingspatronen aanzienlijk en onvoorspelbaar gedurende de dag fluctueren, bijvoorbeeld ordergegevensverwerking met willekeurige schommelingen in belastingpatronen op basis van verschillende factoren.
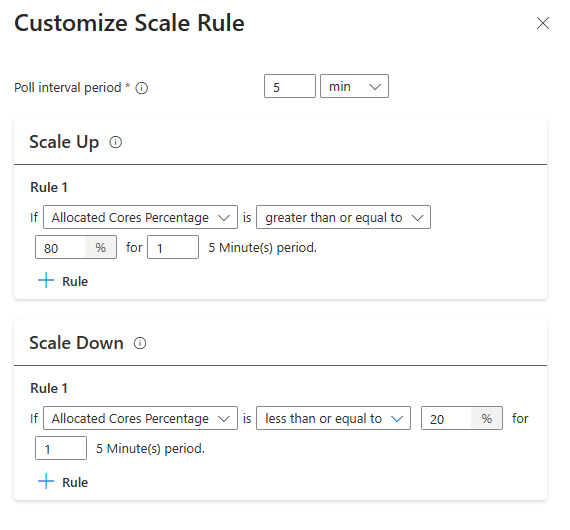
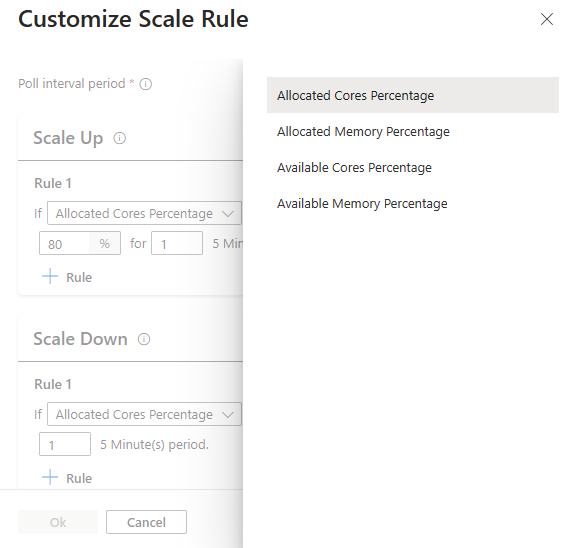
Met de nieuwe optie schaalregel configureren kunt u nu de schaalregels aanpassen.
Tip
- Regels voor omhoog schalen hebben voorrang wanneer een of meer regels worden geactiveerd. Zelfs als slechts één van de regels voor omhoog schalen voorstelt dat het cluster te weinig wordt ingericht, probeert het cluster omhoog te schalen. Om omlaag te schalen, moet er geen regel voor omhoog schalen worden geactiveerd.


Schaalvoorwaarden op basis van belasting
Wanneer de volgende voorwaarden worden gedetecteerd, geeft automatisch schalen een schaalaanvraag
| Omhoog schalen | Omlaag schalen |
|---|---|
| Toegewezen kernen zijn groter dan 80% voor een poll-interval van 5 minuten (controleperiode van 1 minuut) | Toegewezen kernen zijn minder dan of gelijk aan 20% voor een poll-interval van 5 minuten (controleperiode van 1 minuut) |
Voor omhoog schalen problemen met automatisch schalen een aanvraag voor opschalen om het vereiste aantal knooppunten toe te voegen. Het omhoog schalen is gebaseerd op het aantal nieuwe werkknooppunten dat nodig is om te voldoen aan de huidige CPU- en geheugenvereisten. Deze waarde wordt beperkt tot het maximum aantal werkknooppunten dat is ingesteld.
Bij omlaag schalen wordt een aanvraag voor het verwijderen van sommige knooppunten automatisch geschaald. De overwegingen voor omlaag schalen omvatten het aantal pods per knooppunt, de huidige CPU- en geheugenvereisten en werkknooppunten, die kandidaten zijn voor verwijdering op basis van de huidige taakuitvoering. Met de bewerking omlaag schalen worden eerst de knooppunten buiten gebruik gesteld en vervolgens uit het cluster verwijderd.
Belangrijk
Met de regelengine voor automatisch schalen worden oude gebeurtenissen elke 30 minuten proactief leeggemaakt om het systeemgeheugen te optimaliseren. Als gevolg hiervan bestaat er een bovengrens van 30 minuten voor het interval van de schaalregel. Om ervoor te zorgen dat de consistente en betrouwbare triggering van schaalacties wordt gegarandeerd, is het noodzakelijk om het interval van de schaalregel in te stellen op een waarde die kleiner is dan de limiet. Door aan deze richtlijn te houden, kunt u een soepel en efficiënt schaalproces garanderen terwijl u systeemresources effectief beheert.
Metrische clustergegevens
Automatisch schalen bewaakt continu het cluster en verzamelt de volgende metrische gegevens voor automatisch schalen op basis van belasting:
Metrische clustergegevens beschikbaar voor schaalaanpassingsdoeleinden
| Metrisch | Beschrijving |
|---|---|
| Percentage beschikbare kernen | Het totale aantal kernen dat beschikbaar is in het cluster in vergelijking met het totale aantal kernen in het cluster. |
| Beschikbaar geheugenpercentage | Het totale geheugen (in MB) dat beschikbaar is in het cluster in vergelijking met de totale hoeveelheid geheugen in het cluster. |
| Percentage toegewezen kernen | Het totale aantal kernen dat in het cluster is toegewezen in vergelijking met het totale aantal kernen in het cluster. |
| Toegewezen geheugenpercentage | De hoeveelheid geheugen die in het cluster is toegewezen in vergelijking met de totale hoeveelheid geheugen in het cluster. |
Standaard worden de bovenstaande metrische gegevens elke 300 seconden gecontroleerd. Deze kan ook worden geconfigureerd wanneer u het poll-interval aanpast met de optie voor automatische schaalaanpassing. Automatische schaalaanpassing maakt beslissingen voor omhoog of omlaag schalen op basis van deze metrische gegevens.
Notitie
Automatisch schalen maakt standaard gebruik van de standaardresourcecalculator voor YARN voor Apache Spark. Schaalaanpassing op basis van belasting is beschikbaar voor Apache Spark-clusters.
Probleemloos buiten gebruik stellen
Ondernemingen hebben manieren nodig om petabyte te schalen met automatisch schalen en resources zonder problemen buiten gebruik te stellen wanneer ze niet meer nodig zijn. In dit scenario is een handige functie voor buiten gebruik stellen handig.
Bij het buiten gebruik stellen van taken kunnen taken worden voltooid, zelfs nadat automatische schaalaanpassing het buiten gebruik stellen van de werkknooppunten heeft geactiveerd. Met deze functie kunnen knooppunten nog steeds worden ingericht totdat taken zijn voltooid.
Trino : Workers hebben standaard Graceful Decommission ingeschakeld. Coördinator stelt het beëindigen van werkrollen in staat om de taken voor geconfigureerde tijd te voltooien voordat de werkrol uit het cluster wordt verwijderd. U kunt de time-out configureren met behulp van de systeemeigen Trino-parameter
shutdown.grace-periodof op de configuratiepagina van de Azure-portalservice.Apache Spark : omlaag schalen kan van invloed zijn op/stoppen van actieve taken in het cluster. Als u graceful uit bedrijf nemen inschakelt in De Azure-portal, bevat het graceful buiten gebruik stellen van YARN-knooppunten en zorgt u ervoor dat werk dat wordt uitgevoerd op een werkknooppunt is voltooid voordat het knooppunt uit het HDInsight-cluster in AKS-cluster wordt verwijderd.
Afkoelperiode
Om continue opschaalbewerkingen te voorkomen, wacht de engine voor automatisch schalen op een configureerbaar interval voordat een andere set schaalbewerkingen wordt gestart. De standaardwaarde is ingesteld op 180 seconden
Notitie
- In aangepaste schaalregels kan er geen regeltrigger een triggerinterval van meer dan 30 minuten hebben. Nadat een gebeurtenis voor automatisch schalen is uitgevoerd, wordt de hoeveelheid tijd die moet worden gewacht voordat een ander schaalbeleid wordt afgedwongen.
- Afkoelperiode moet groter zijn dan het beleidsinterval, zodat de metrische clustergegevens opnieuw kunnen worden ingesteld.
Aan de slag
Als u automatisch schalen wilt laten functioneren, moet u de eigenaar of inzendermachtiging toewijzen aan de MSI (gebruikt tijdens het maken van het cluster) op clusterniveau, met behulp van IAM in het linkerdeelvenster.
Raadpleeg de volgende afbeelding en stappen voor het toevoegen van roltoewijzing
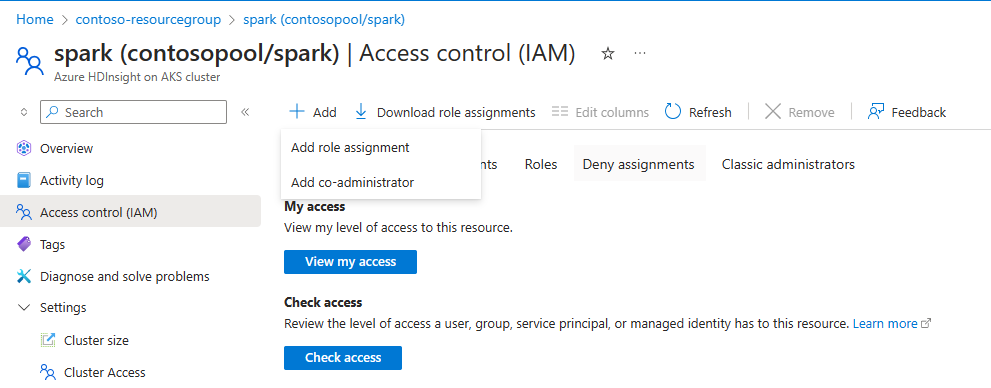
Selecteer Roltoewijzing toevoegen,
- Toewijzingstype: Bevoorrechte beheerdersrollen
- Rol: Eigenaar of Inzender
- Leden: Kies beheerde identiteit en selecteer de door de gebruiker toegewezen beheerde identiteit, die is gegeven tijdens de fase voor het maken van het cluster.
- De rol toewijzen.

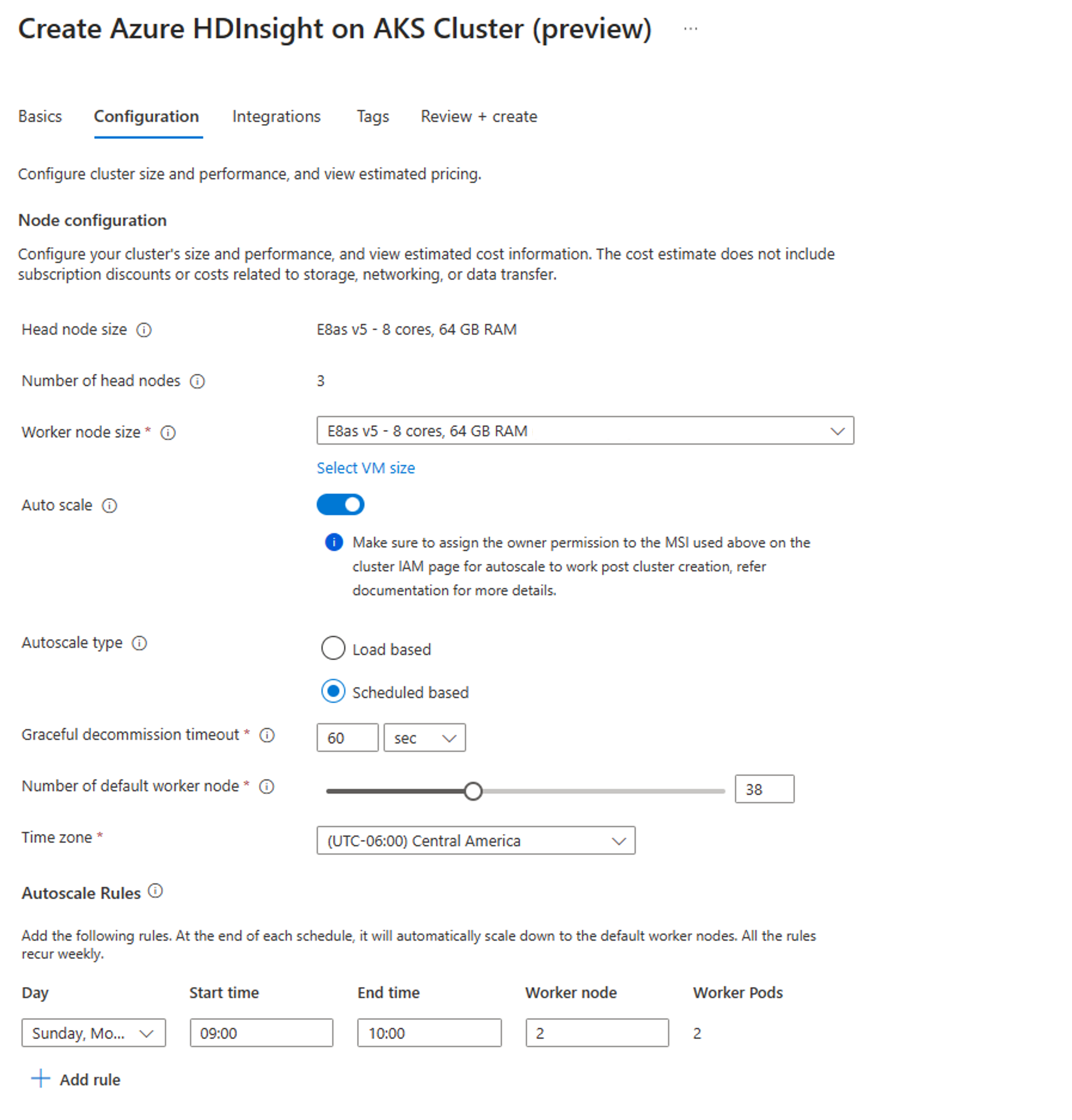
Een cluster maken met automatisch schalen op basis van planning
Zodra uw clustergroep is gemaakt, maakt u een nieuw cluster met de gewenste workload (op het clustertype) en voert u de andere stappen uit als onderdeel van het normale proces voor het maken van clusters.
Schakel op het tabblad Configuratie de wisselknop Automatisch schalen in.
Op planning gebaseerde automatische schaalaanpassing selecteren
Selecteer uw tijdzone en klik vervolgens op + Regel toevoegen
Selecteer de dagen van de week waarop de nieuwe voorwaarde van toepassing moet zijn.
Bewerk de tijd waarop de voorwaarde van kracht moet worden en het aantal knooppunten waarnaar het cluster moet worden geschaald.
Notitie
- De gebruiker moet de rol 'eigenaar' of 'inzender' hebben in het cluster-MSI om automatisch schalen te laten werken.
- De standaardwaarde definieert de begingrootte van het cluster wanneer het wordt gemaakt.
- Het verschil tussen twee planningen is standaard ingesteld op 30 minuten.
- De tijdwaarde volgt de notatie van 24 uur
- In het geval van een doorlopend venster van meer dan 24 uur over meerdere dagen, moet u een schema voor automatische schaalaanpassing instellen voor dagen en wordt voor automatische schaalaanpassing ervan uitgegaan dat 23:59 is ingesteld op 00:00 (met hetzelfde aantal nodes) gedurende twee dagen van 22:00 tot 23:59, 00:00 tot 02:00 uur.
- De planningen worden standaard ingesteld in Coordinated Universal Time (UTC). U kunt altijd bijwerken naar de tijdzone die overeenkomt met uw lokale tijdzone in de vervolgkeuzelijst die beschikbaar is. Wanneer u zich in een tijdzone bevindt die zomertijd ziet, wordt het schema niet automatisch aangepast, dan moet u de planningsupdates dienovereenkomstig beheren.

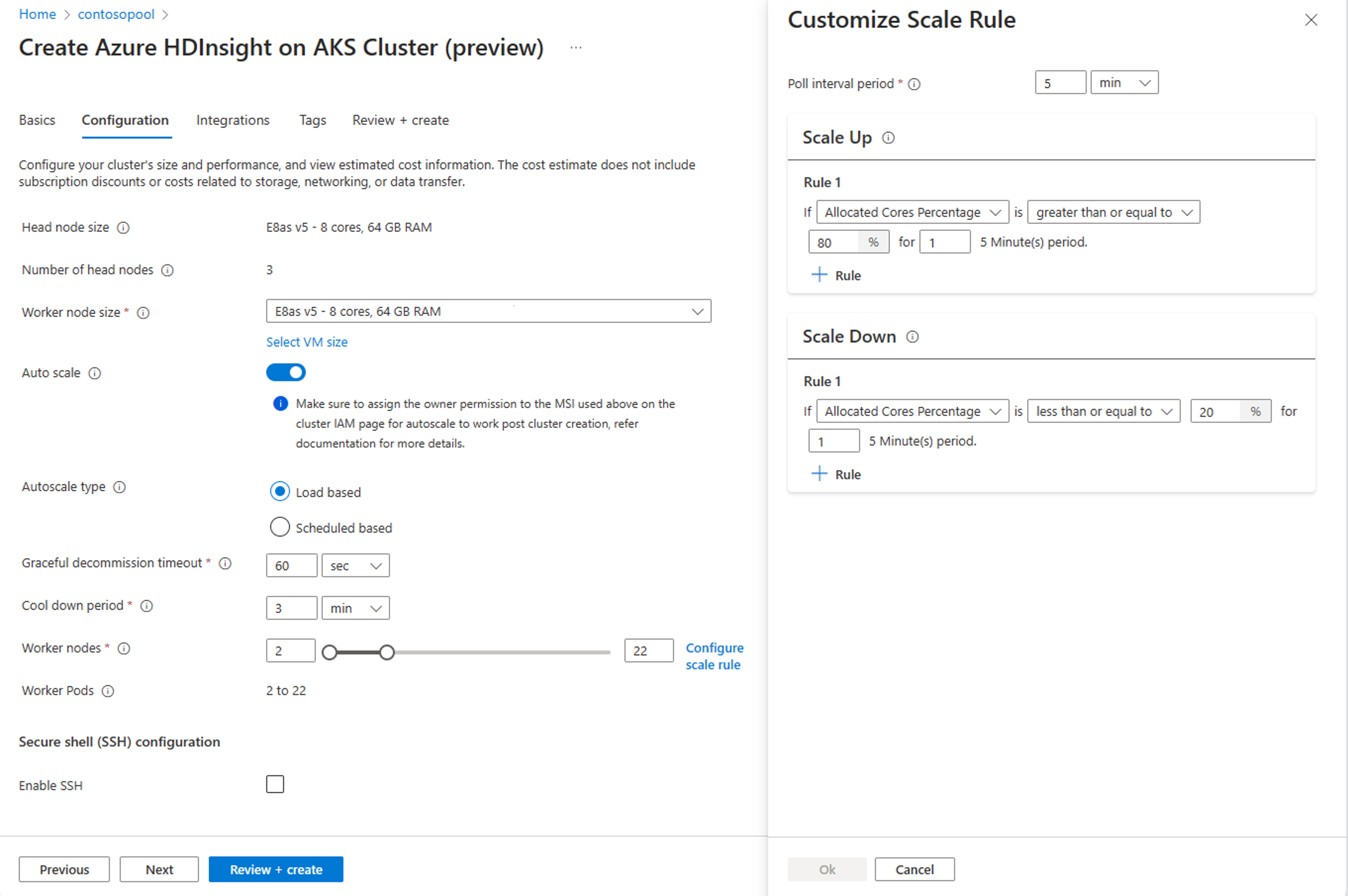
Een cluster maken met automatisch schalen op basis van laden
Zodra uw clustergroep is gemaakt, maakt u een nieuw cluster met de gewenste workload (op het clustertype) en voert u de andere stappen uit als onderdeel van het normale proces voor het maken van clusters.
Schakel op het tabblad Configuratie de wisselknop Automatisch schalen in.
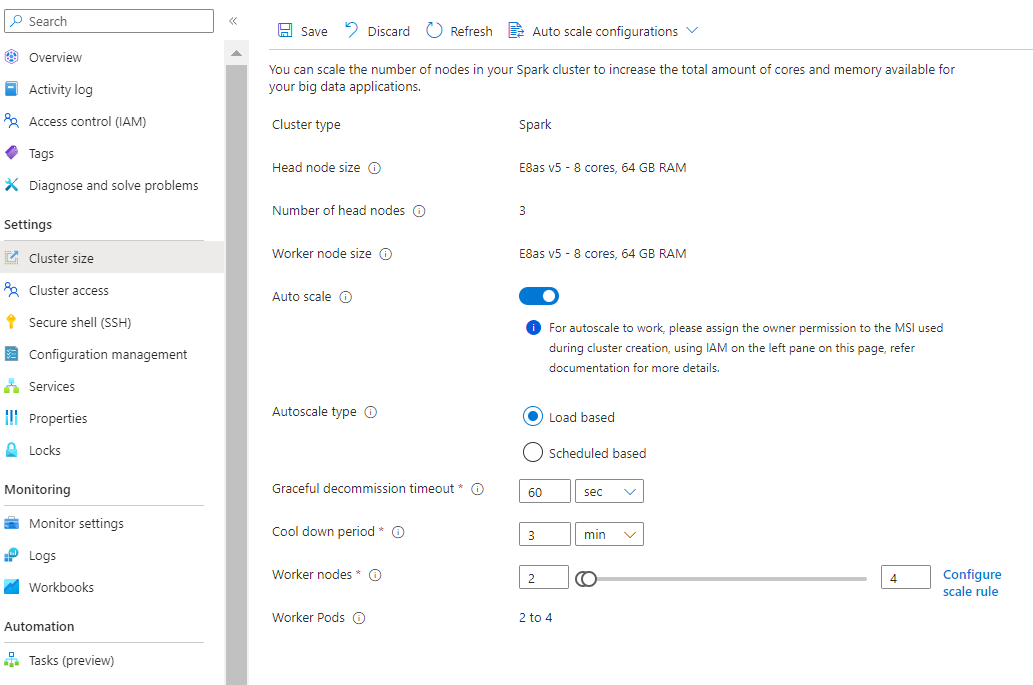
Automatische schaalaanpassing op basis van laden selecteren
Op basis van het type workload hebt u opties voor het toevoegen van een respijtvolle time-out voor buitengebruikstelling, afkoelperiode
Selecteer het minimum en maximum aantal knooppunten en configureer zo nodig de schaalregels om automatisch schalen aan te passen aan uw behoeften.
Tip
- Uw abonnement heeft een capaciteitsquotum voor elke regio. Het totale aantal kernen van uw hoofdknooppunten en de maximale werkknooppunten kunnen het capaciteitsquotum niet overschrijden. Dit quotum is echter een zachte limiet; u kunt altijd een ondersteuningsticket maken om het eenvoudig te laten toenemen.
- Als u de totale quotumlimiet voor kerngeheugens overschrijdt, krijgt u een foutbericht met de mededeling
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Regels voor omhoog schalen hebben voorrang wanneer een of meer regels worden geactiveerd. Zelfs als slechts één van de regels voor omhoog schalen voorstelt dat het cluster te weinig wordt ingericht, probeert het cluster omhoog te schalen. Om omlaag te schalen, moet er geen regel voor omhoog schalen worden geactiveerd.
- In openbare preview ondersteunt HDInsight in AKS maximaal 500 knooppunten in een cluster.

Een cluster maken met een Resource Manager-sjabloon
Automatisch schalen op basis van planning
U kunt een HDInsight op AKS-cluster maken met automatisch schalen op basis van een planning met behulp van een Azure Resource Manager-sjabloon door een automatische schaalaanpassing toe te voegen aan de sectie clusterProfile -> autoscaleProfile.
Het knooppunt voor automatisch schalen bevat een terugkeerpatroon met een tijdzone en planning die beschrijft wanneer de wijziging plaatsvindt. Zie voorbeeld-JSON voor een volledige Resource Manager-sjabloon
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Tip
- U moet niet-conflicterende planningen instellen met behulp van ARM-implementaties om fouten met schaalbewerkingen te voorkomen.
Automatisch schalen op basis van belasting
U kunt een HDInsight op AKS-cluster maken met automatisch schalen op basis van belasting met behulp van een Azure Resource Manager-sjabloon door een automatische schaalaanpassing toe te voegen aan de sectie clusterProfile -> autoscaleProfile.
Het knooppunt voor automatisch schalen bevat
- een poll-interval, afkoelperiode,
- probleemloos buiten gebruik stellen,
- minimum- en maximumknooppunten,
- standaarddrempelregels,
- metrische gegevens schalen die beschrijven wanneer de wijziging plaatsvindt.
Zie voorbeeld-JSON als volgt voor een volledige Resource Manager-sjabloon
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
De REST API gebruiken
Als u automatische schaalaanpassing wilt in- of uitschakelen voor een actief cluster met behulp van de REST API, moet u een PATCH-aanvraag indienen bij uw eindpunt voor automatisch schalen: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Gebruik de juiste parameters in de nettolading van de aanvraag. De json-nettolading kan worden gebruikt om automatisch schalen in te schakelen.
- Gebruik de nettolading (autoscaleProfile: null) of gebruik vlag (ingeschakeld, onwaar) om automatisch schalen uit te schakelen.
- Raadpleeg de JSON-voorbeelden die in de bovenstaande stap zijn vermeld ter referentie.
Automatisch schalen onderbreken voor een actief cluster
We hebben de functie onderbreken geïntroduceerd in Automatisch schalen. Met behulp van Azure Portal kunt u automatisch schalen onderbreken op een actief cluster. In het onderstaande diagram ziet u hoe u automatische schaalaanpassing onderbreken en hervatten selecteert

U kunt hervatten zodra u de bewerkingen voor automatisch schalen wilt hervatten.

Tip
Wanneer u meerdere planningen configureert en u de automatische schaalaanpassing onderbroken, wordt de volgende planning niet geactiveerd. Het aantal knooppunten blijft hetzelfde, zelfs als de knooppunten buiten gebruik worden gesteld.
Configuraties voor automatisch schalen kopiëren
Met behulp van Azure Portal kunt u nu dezelfde configuraties voor automatische schaalaanpassing kopiëren voor dezelfde clustershape in uw clustergroep. U kunt deze functie gebruiken en dezelfde configuraties exporteren of importeren.

Activiteiten voor automatisch schalen bewaken
De clusterstatus
De clusterstatus die wordt vermeld in Azure Portal, kan u helpen bij het bewaken van activiteiten voor automatisch schalen. Alle clusterstatusberichten die u mogelijk ziet, worden uitgelegd in de lijst.
| De clusterstatus | Beschrijving |
|---|---|
| Geslaagd | Het cluster werkt normaal. Alle vorige activiteiten voor automatisch schalen zijn voltooid. |
| Geaccepteerd | De clusterbewerking (bijvoorbeeld: omhoog schalen) wordt geaccepteerd en wacht tot de bewerking is voltooid. |
| Mislukt | Dit betekent dat een huidige bewerking om een of andere reden is mislukt, het cluster mogelijk niet functioneel is. |
| Geannuleerd | De huidige bewerking wordt geannuleerd. |
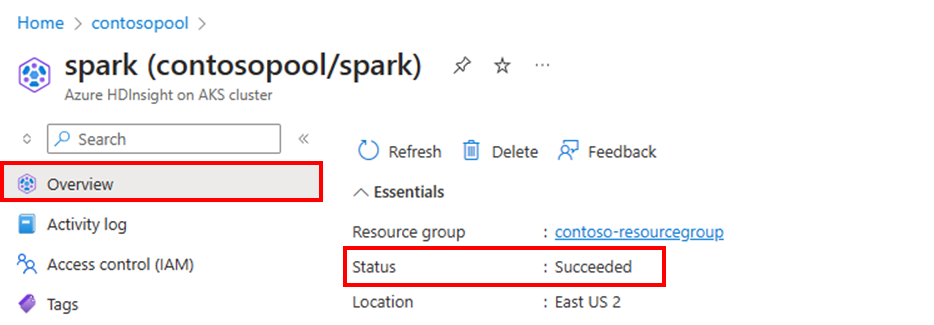
Als u het huidige aantal knooppunten in uw cluster wilt weergeven, gaat u naar de grafiek Clustergrootte op de pagina Overzicht voor uw cluster.

Bewerkingsgeschiedenis
U kunt de geschiedenis van het cluster omhoog en omlaag schalen bekijken als onderdeel van de metrische gegevens van het cluster. U kunt ook alle schaalbewerkingen weergeven gedurende de afgelopen dag, week of andere periode.

Aanvullende bronnen