Grote taalmodellen uitbreiden met retrieval-verrijkte generatie of fijnslijpen.
In een reeks artikelen bespreken we de mechanismen voor het ophalen van kennis die door grote taalmodellen (LLM's) worden gebruikt om antwoorden te genereren. Een LLM heeft standaard alleen toegang tot de trainingsgegevens. U kunt het model echter uitbreiden om realtime gegevens of persoonlijke gegevens op te nemen.
Het eerste mechanisme is het ophalen van augmented generation (RAG). RAG is een vorm van voorverwerking die semantische zoekopdrachten combineert met contextuele priming. nl-NL: Contextuele priming wordt uitvoerig besproken in Kernconcepten en overwegingen voor het ontwikkelen van generatieve AI-oplossingen.
Het tweede mechanisme is het fijn afstellen van. Bij het afstemmen wordt een LLM verder getraind op een specifieke gegevensset na de eerste brede training. Het doel is om de LLM aan te passen om beter te presteren op taken of om inzicht te krijgen in concepten die betrekking hebben op de gegevensset. Dit proces helpt het model zich te specialiseren of de nauwkeurigheid en efficiëntie ervan te verbeteren bij het verwerken van specifieke typen invoer of domeinen.
In de volgende secties worden deze twee mechanismen gedetailleerder beschreven.
Rag begrijpen
RAG wordt vaak gebruikt om het scenario 'Chatten via mijn gegevens' in te schakelen. In dit scenario heeft een organisatie mogelijk een grote verzameling tekstinhoud, zoals documenten, documentatie en andere eigendomsgegevens. Het gebruikt dit corpus als basis voor antwoorden op gebruikersprompts.
Op hoog niveau maakt u een databasevermelding voor elk document of voor een gedeelte van een document dat een chunkwordt genoemd. Het segment wordt geïndexeerd op zijn embedding, dat wil zeggen, een vector (array) van getallen die facetten van het document vertegenwoordigen. Wanneer een gebruiker een query indient, zoekt u in de database naar vergelijkbare documenten en verzendt u vervolgens de query en de documenten naar de LLM om een antwoord op te stellen.
Notitie
We gebruiken de term retrieval-augmented generation (RAG) op een flexibele manier. Het proces voor het implementeren van een RAG-chatsysteem, zoals beschreven in dit artikel, kan worden toegepast of u externe gegevens wilt gebruiken in een ondersteunende capaciteit (RAG) of als het middelpunt van het antwoord (RCG). Het genuanceerde onderscheid wordt niet behandeld in de meeste lectuur over RAG.
Een index van gevectoriseerde documenten maken
De eerste stap bij het maken van een RAG-chatsysteem is het maken van een vectorgegevensarchief dat de vector-insluiting van het document of segment bevat. Bekijk het volgende diagram, waarin de basisstappen voor het maken van een gevectoriseerde index van documenten worden beschreven.

Het diagram vertegenwoordigt een gegevenspijplijn. De pijplijn is verantwoordelijk voor de opname, verwerking en het beheer van gegevens die door het systeem worden gebruikt. De pijplijn bevat voorverwerkingsgegevens die moeten worden opgeslagen in de vectordatabase en ervoor zorgen dat de gegevens die in de LLM worden ingevoerd, de juiste indeling hebben.
Het hele proces wordt aangestuurd door het idee van een insluiting, een numerieke weergave van gegevens (meestal woorden, woordgroepen, zinnen of zelfs hele documenten) waarmee de semantische eigenschappen van de invoer worden vastgelegd op een manier die kan worden verwerkt door machine learning-modellen.
Als u een insluiting wilt maken, verzendt u het stuk inhoud (zinnen, alinea's of volledige documenten) naar de Azure OpenAI Embeddings-API. De API retourneert een vector. Elke waarde in de vector vertegenwoordigt een kenmerk (dimensie) van de inhoud. Dimensies kunnen onderwerp, semantische betekenis, syntaxis en grammatica, gebruik van woorden en woordgroepen, contextuele relaties, stijl of toon zijn. Samen vertegenwoordigen alle waarden van de vector de dimensionale ruimte van de inhoud. Als u denkt aan een 3D-weergave van een vector met drie waarden, bevindt een specifieke vector zich in een bepaald gebied van het XYZ-vlak. Wat gebeurt er als u 1000 waarden of nog meer hebt? Hoewel het niet mogelijk is voor mensen om een grafiek met 1000 dimensies te tekenen op een vel papier om het begrijpelijker te maken, hebben computers geen probleem om die mate van dimensionale ruimte te begrijpen.
In de volgende stap van het diagram ziet u hoe u de vector en de inhoud (of een aanwijzer naar de locatie van de inhoud) en andere metagegevens in een vectordatabase opslaat. Een vectordatabase is net als elk type database, maar met twee verschillen:
- Vectordatabases gebruiken een vector als index om te zoeken naar gegevens.
- Vectordatabases implementeren een algoritme met de naam cosinus vergelijkbare zoekopdrachten, ook wel dichtstbijzijnde buurgenoemd. Het algoritme maakt gebruik van vectoren die het meest overeenkomen met de zoekcriteria.
Met het verzameling documenten dat is opgeslagen in een vectordatabase, kunnen ontwikkelaars een retriever-onderdeel bouwen om documenten op te halen die overeenkomen met de query van de gebruiker. De gegevens worden gebruikt om de LLM te leveren met wat deze nodig heeft om de query van de gebruiker te beantwoorden.
Query's beantwoorden met behulp van uw documenten
Een RAG-systeem maakt eerst gebruik van semantische zoekopdrachten om artikelen te vinden die nuttig kunnen zijn voor de LLM wanneer het een antwoord opstelt. De volgende stap is het verzenden van de overeenkomende artikelen met de oorspronkelijke prompt van de gebruiker naar de LLM om een antwoord op te stellen.
Bekijk het volgende diagram als een eenvoudige RAG-implementatie (ook wel naïef RAG-genoemd):
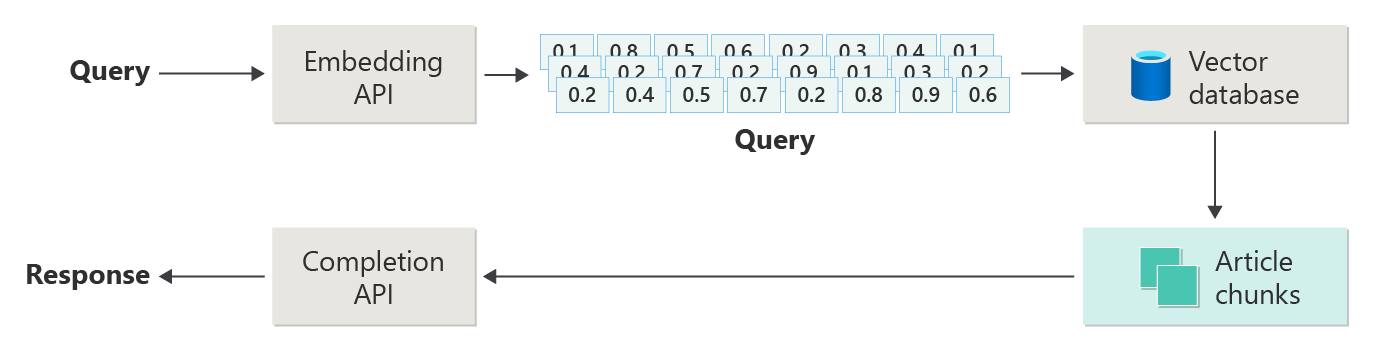
In het diagram verzendt een gebruiker een query. De eerste stap is het maken van een insluiting voor de prompt van de gebruiker om een vector te retourneren. De volgende stap bestaat uit het doorzoeken van de vectordatabase voor die documenten (of gedeelten van documenten) die overeenkomen met de dichtstbijzijnde buur.
cosinus-gelijkenis is een meting die helpt bepalen hoe vergelijkbare twee vectoren zijn. In wezen beoordeelt de metrische waarde de cosinus van de hoek ertussen. Een cosinusgelijkenis die bijna 1 is, geeft een hoge mate van gelijkenis aan, dat wil zeggen, een kleine hoek. Een gelijkenis in de buurt van -1 duidt op een ongelijksoortigheid (een hoek van bijna 180 graden). Deze metrische waarde is van cruciaal belang voor taken zoals document vergelijkbaarheid, waarbij het doel is documenten te vinden die vergelijkbare inhoud of betekenis hebben.
dichtstbijzijnde burenalgoritmen werken door de dichtstbijzijnde vectoren (buren) te vinden voor een punt in vectorruimte. In het K-dichtstbijzijnde buren (KNN)-algoritmeverwijst k naar het aantal dichtstbijzijnde buren dat moet worden overwogen. Deze benadering wordt veel gebruikt in classificatie en regressie, waarbij het algoritme het label van een nieuw gegevenspunt voorspelt op basis van het meerderheidslabel van de k dichtstbijzijnde buren in de trainingsset. KNN en cosinus-overeenkomsten worden vaak samen gebruikt in systemen zoals aanbevelingsengines, waarbij het doel is om items te vinden die het meest lijken op de voorkeuren van een gebruiker, die worden weergegeven als vectoren in de insluitruimte.
U neemt de beste resultaten uit die zoekopdracht en verzendt de overeenkomende inhoud met de opdracht van de gebruiker om een reactie te genereren die (hopelijk) gebaseerd is op overeenkomende inhoud.
Uitdagingen en overwegingen
Een RAG-systeem heeft zijn set uitdagingen op het gebied van implementatie. Gegevensprivacy is van het grootste belang. Het systeem moet op verantwoorde wijze omgaan met gebruikersgegevens, met name wanneer het informatie ophaalt en verwerkt uit externe bronnen. Rekenvereisten kunnen ook aanzienlijk zijn. Zowel het ophaalproces als de generatieve processen zijn resource-intensief. Het garanderen van nauwkeurigheid en relevantie van reacties tijdens het beheren van vooroordelen in de gegevens of het model is een andere belangrijke overweging. Ontwikkelaars moeten deze uitdagingen zorgvuldig doorlopen om efficiënte, ethische en waardevolle RAG-systemen te creëren.
Bouw geavanceerde ophaal-geaugmenteerde generatiesystemen geeft u meer informatie over het bouwen van gegevens- en invoerpijplijnen om een productie-klaar RAG-systeem mogelijk te maken.
Als u direct wilt experimenteren met het bouwen van een generatieve AI-oplossing, raden we u aan om aan de slag te gaan met de chat met behulp van uw eigen gegevensvoorbeeld voor Python. De zelfstudie is ook beschikbaar voor .NET-, Javaen JavaScript-.
Een model verfijnen
In de context van een LLM is fine-tuning het proces voor het aanpassen van de parameters van het model door het te trainen op een domeinspecifieke gegevensset nadat de LLM in eerste instantie is getraind op een grote, diverse gegevensset.
LLM's worden getraind (vooraf getraind) op een brede gegevensset, die de taalstructuur, context en een breed scala aan kennis begrijpt. Deze fase omvat het leren van algemene taalpatronen. Bij het afstemmen wordt meer training toegevoegd aan het vooraf getrainde model op basis van een kleinere, specifieke gegevensset. Deze secundaire trainingsfase is erop gericht het model aan te passen om beter te presteren op bepaalde taken of om specifieke domeinen te begrijpen, waardoor de nauwkeurigheid en relevantie voor deze gespecialiseerde toepassingen worden verbeterd. Tijdens het verfijnen worden de gewichten van het model aangepast om de nuances van deze kleinere gegevensset beter te voorspellen of te begrijpen.
Enkele overwegingen:
- Specialisatie: Afstemming van het model past het model aan op specifieke taken, zoals juridische documentanalyse, interpretatie van medische tekst of interacties met de klantenservice. Deze specialisatie maakt het model effectiever op deze gebieden.
- Efficiëntie: het is efficiënter om een vooraf getraind model voor een specifieke taak af te stemmen dan om een volledig nieuw model te trainen. Voor het afstemmen van gegevens zijn minder gegevens en minder rekenresources vereist.
- Aanpassingsvermogen: Met fine-tuning kunnen nieuwe taken of domeinen die geen deel uitmaken van de oorspronkelijke trainingsgegevens, worden aangepast. Dankzij de aanpassing van LLM's zijn ze veelzijdige hulpprogramma's voor verschillende toepassingen.
- Verbeterde prestaties: Voor taken die afwijken van de gegevens waarop het model oorspronkelijk is getraind, kan het afstemmen leiden tot betere prestaties. Het model wordt afgestemd om inzicht te krijgen in de specifieke taal, stijl of terminologie die in het nieuwe domein wordt gebruikt.
- Persoonlijke instellingen: In sommige toepassingen kunt u het aanpassen van de antwoorden of voorspellingen van het model aanpassen aan de specifieke behoeften of voorkeuren van een gebruiker of organisatie. Het afstemmen heeft echter specifieke nadelen en beperkingen. Als u deze factoren begrijpt, kunt u bepalen wanneer u moet kiezen voor fine-tuning versus alternatieven zoals RAG.
- gegevensvereiste: voor het afstemmen is een voldoende grote en hoogwaardige gegevensset vereist die specifiek is voor de doeltaak of het doeldomein. Het verzamelen en cureren van deze gegevensset kan lastig en resource-intensief zijn.
- Risico op overfitting: Overfitting is een risico, met name met een kleine gegevensset. Overfitting zorgt ervoor dat het model goed presteert op de trainingsgegevens, maar slecht op nieuwe, ongeziene gegevens. Generaliseerbaarheid wordt verminderd wanneer overfitting plaatsvindt.
- Kosten en middelen: Hoewel er minder rekenkracht nodig is dan wanneer je helemaal opnieuw traint, zijn er nog steeds aanzienlijke berekeningsmiddelen nodig, vooral voor grote modellen en datasets. De kosten kunnen onbetaalbaar zijn voor sommige gebruikers of projecten.
- Onderhoud en het bijwerken van: bijgesneden modellen hebben mogelijk regelmatige updates nodig om effectief te blijven als domeinspecifieke informatie in de loop van de tijd verandert. Dit doorlopende onderhoud vereist extra resources en gegevens.
- Modelverschuiving: Omdat het model is afgestemd op specifieke taken, kan het enig algemeen taalbegrip en veelzijdigheid verliezen. Dit fenomeen wordt modeldriftgenoemd.
Een model aanpassen door middel van het verfijnen van wordt uitgelegd hoe u een model kunt verfijnen. Op hoog niveau geeft u een JSON-gegevensset op met mogelijke vragen en voorkeursantwoorden. De documentatie stelt voor dat er merkbare verbeteringen zijn door 50 tot 100 vraag-en-antwoordparen te bieden, maar het juiste aantal verschilt sterk van de use-case.
Fine-tuning versus RAG
Op het oppervlak lijkt het erop dat er nogal wat overlap is tussen fine-tuning en RAG. Het kiezen tussen het afstemmen en ophalen van uitgebreide generatie hangt af van de specifieke vereisten van uw taak, waaronder prestatieverwachtingen, beschikbaarheid van resources en de noodzaak van domeinspecifiekheid versus generaliseerbaarheid.
Wanneer u fine-tuning gebruikt in plaats van RAG:
- Taakspecifieke prestaties: Fine-tuning is de voorkeur wanneer hoge prestaties voor een specifieke taak essentieel zijn en er voldoende domeinspecifieke gegevens bestaan om het model effectief te trainen zonder aanzienlijke overfitting risico's.
- Controle over gegevens: als u eigen of zeer gespecialiseerde gegevens hebt die aanzienlijk verschillen van de gegevens waarop het basismodel is getraind, kunt u deze unieke kennis in het model opnemen.
- Beperkte behoefte aan realtime-updates: als voor de taak niet vereist is dat het model voortdurend wordt bijgewerkt met de meest recente informatie, kan het afstemmen efficiënter zijn omdat RAG-modellen doorgaans toegang nodig hebben tot up-toexterne databases of internet om recente gegevens op te halen.
Wanneer de voorkeur aan RAG boven fine-tuning wordt gegeven
- dynamische inhoud of veranderende inhoud: RAG is geschikter voor taken waarbij de meest recente informatie essentieel is. Omdat RAG-modellen in realtime gegevens uit externe bronnen kunnen ophalen, zijn ze beter geschikt voor toepassingen zoals het genereren van nieuws of het beantwoorden van vragen over recente gebeurtenissen.
- Generalisatie ten opzichte van specialisatie: als het doel is om sterke prestaties te behouden voor een breed scala aan onderwerpen in plaats van uit te blinken in een smal domein, kan RAG de voorkeur hebben. Het maakt gebruik van externe Knowledge Bases, zodat er reacties kunnen worden gegenereerd in verschillende domeinen zonder dat er een risico bestaat op overfitting naar een specifieke gegevensset.
- Resourcebeperkingen: Voor organisaties met beperkte resources voor het verzamelen van gegevens en modeltraining biedt het gebruik van een RAG-benadering mogelijk een rendabel alternatief voor het afstemmen, met name als het basismodel al redelijk goed presteert op de gewenste taken.
Laatste overwegingen voor toepassingsontwerp
Hier volgt een korte lijst met zaken die u kunt overwegen en andere punten uit dit artikel die van invloed kunnen zijn op uw ontwerpbeslissingen voor toepassingen:
- Bepaal tussen afstemmen en RAG op basis van de specifieke behoeften van uw toepassing. Het afstemmen kan betere prestaties bieden voor gespecialiseerde taken, terwijl RAG flexibiliteit en up-to-datuminhoud biedt voor dynamische toepassingen.