Waarom incrementele stroomverwerking?
De huidige gegevensgestuurde bedrijven produceren continu gegevens, wat technische gegevenspijplijnen vereist die deze gegevens continu opnemen en transformeren. Deze pijplijnen moeten gegevens exact één keer kunnen verwerken en leveren, resultaten produceren met latenties van minder dan 200 milliseconden en altijd proberen de kosten te minimaliseren.
In dit artikel worden methoden voor batch- en incrementele stroomverwerking beschreven voor engineeringgegevenspijplijnen, waarom incrementele stroomverwerking de betere optie is en de volgende stappen voor het aan de slag gaan met incrementele stroomverwerkingsaanbiedingen van Databricks, Streamen op Azure Databricks en Wat is Delta Live Tables?. Met deze functies kunt u snel pijplijnen schrijven en uitvoeren die semantiek, latentie, kosten en meer garanderen.
De valkuilen van herhaalde batchtaken
Bij het instellen van uw gegevenspijplijn kunt u in eerste instantie herhaalde batchtaken schrijven om uw gegevens op te nemen. U kunt bijvoorbeeld elk uur een Spark-taak uitvoeren die uit uw bron leest en gegevens naar een sink schrijft, zoals Delta Lake. De uitdaging met deze aanpak is het incrementeel verwerken van uw bron, omdat de Spark-taak die elk uur wordt uitgevoerd, moet beginnen met where het laatste einde. U kunt de meest recente tijdstempel opnemen van de gegevens die u hebt verwerkt en vervolgens alle rijen select met tijdstempels die recenter zijn dan die tijdstempel, maar er zijn valkuilen:
Als u een pijplijn voor continue gegevens wilt uitvoeren, kunt u proberen een batchtaak per uur te plannen die incrementeel wordt gelezen uit uw bron, transformaties uitvoert en het resultaat naar een sink schrijft, zoals Delta Lake. Deze aanpak kan valkuilen hebben:
- Een Spark-taak die na een tijdstempel alle nieuwe gegevens opvraagt, mist late gegevens.
- Een Spark-taak die mislukt, kan leiden tot het verbreken van exact eenmaal gegarandeerde garanties, als deze niet zorgvuldig worden afgehandeld.
- Een Spark-taak waarin de inhoud van cloudopslaglocaties wordt vermeld om nieuwe bestanden te vinden, wordt duur.
Vervolgens moet u deze gegevens nog steeds herhaaldelijk transformeren. U kunt herhaalde batchtaken schrijven die vervolgens uw gegevens aggregeren of andere bewerkingen toepassen, wat de efficiëntie van de pijplijn verder bemoeilijkt en vermindert.
Een voorbeeld van een batch
Bekijk de volgende voorbeelden om de valkuilen van batchopname en -transformatie voor uw pijplijn volledig te begrijpen.
Gemiste gegevens
Gezien een Kafka-onderwerp met gebruiksgegevens waarmee wordt bepaald hoeveel kosten uw klanten in rekening worden gebracht en uw pijplijn in batches opneemt, kan de volgorde van gebeurtenissen er als volgt uitzien:
- Uw eerste batch heeft twee records om 8:30 en 8:30 uur.
- U update de laatste tijdstempel tot 8:30 uur.
- U get nog een record om 8:15 uur.
- Uw tweede batchquery's voor alles na 8:30 uur, dus u mist de record om 8:15 uur.
Bovendien wilt u uw gebruikers niet te veel op- of ontladen, zodat u ervoor moet zorgen dat u elke record precies één keer opneemt.
Redundante verwerking
Stel dat uw gegevens rijen met gebruikersaankopen bevatten en u de verkoop per uur wilt aggregeren, zodat u de populairste tijden in uw winkel kent. Als aankopen voor hetzelfde uur in verschillende batches binnenkomen, hebt u meerdere batches die uitvoer produceren voor hetzelfde uur:
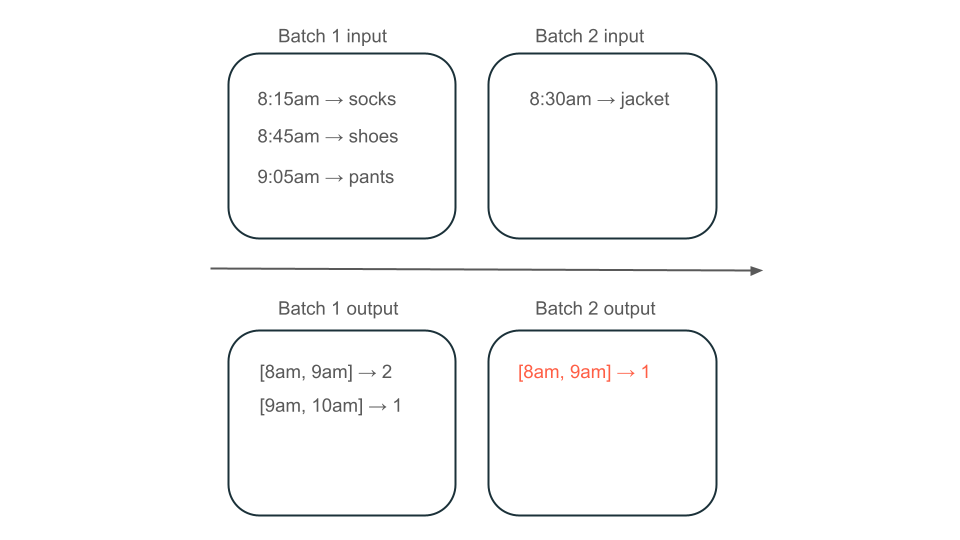
Heeft de 8:00 tot 9:00 uur window twee elementen (de uitvoer van batch 1), één element (de uitvoer van batch 2) of drie (de uitvoer van geen van de batches)? De gegevens die nodig zijn om een bepaalde window tijd te produceren, worden weergegeven in meerdere batches van transformatie. U kunt dit oplossen door uw gegevens per dag te partition en de hele partition opnieuw te verwerken wanneer u een resultaat wilt berekenen. Vervolgens kunt u de resultaten in uw sink overschrijven:
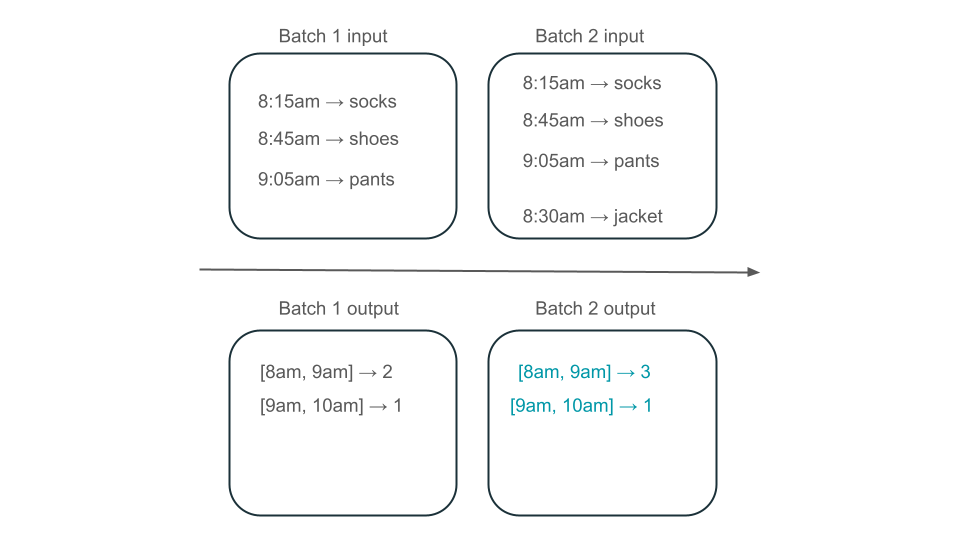
Dit gaat echter ten koste van latentie en kosten, omdat de tweede batch het onnodige werk moet doen van het verwerken van gegevens die het mogelijk al heeft verwerkt.
Geen valkuilen met incrementele stroomverwerking
Met incrementele stroomverwerking kunt u eenvoudig alle valkuilen van herhaalde batchtaken vermijden om gegevens op te nemen en te transformeren. Databricks Structured Streaming en Delta Live Tables implementatiecomplexiteiten van streaming beheren, zodat u zich kunt richten op alleen uw bedrijfslogica. U hoeft alleen op te geven met welke bron verbinding moet worden gemaakt, met welke transformaties de gegevens moeten worden uitgevoerd en where om het resultaat te schrijven.
Incrementele opname
Incrementele opname in Databricks wordt mogelijk gemaakt door Apache Spark Structured Streaming, waardoor incrementeel een gegevensbron kan worden verbruikt en naar een sink kan worden geschreven. De Structured Streaming-engine kan gegevens exact eenmaal verbruiken en de engine kan out-of-ordergegevens verwerken. De engine kan worden uitgevoerd in notebooks of met behulp van de streaming-tables in Delta Live Tables.
De structured streaming-engine op Databricks biedt eigen streamingbronnen zoals AutoLoader, die cloudbestanden incrementeel op een rendabele manier kunnen verwerken. Databricks biedt ook connectors voor andere populaire berichtbussen, zoals Apache Kafka, Amazon Kinesis, Apache Pulsar en Google Pub/Sub.
Incrementele transformatie
Met incrementele transformatie in Databricks met Structured Streaming kunt u transformaties naar DataFrames opgeven met dezelfde API als een batchquery, maar hiermee worden gegevens bijgehouden in batches en geaggregeerde values in de loop van de tijd, zodat u dat niet hoeft te doen. Het hoeft nooit gegevens opnieuw te verwerken, dus het is sneller en rendabeler dan herhaalde batchtaken. Structured Streaming produceert een stroom met gegevens die kunnen worden toegevoegd aan uw sink, zoals Delta Lake, Kafka of een andere ondersteunde connector.
gematerialiseerd Views in Delta Live Tables wordt aangedreven door de Enzyme-engine. Enzym verwerkt uw bron nog steeds incrementeel, maar in plaats van een stroom te produceren, wordt er een gematerialiseerde weergavegemaakt, wat een vooraf berekende table is waarin de resultaten van een query die u geeft, worden opgeslagen. Enzym kan efficiënt bepalen hoe nieuwe gegevens van invloed zijn op de resultaten van uw query en het houdt de vooraf berekende table up-to-date.
Materialiseer Views een weergave van uw aggregaties die zichzelf altijd efficiënt bijwerkt, zodat u in het hierboven beschreven scenario bijvoorbeeld weet dat de periode van 8:00 tot 9:00 uur window drie elementen bevat.
Gestructureerd streamen of Delta Live Tables?
Het belangrijke verschil tussen Structured Streaming en Delta Live Tables is de manier waarop u uw streamingquery's operationeel maakt. In Structured Streaming geeft u handmatig veel configuraties op en moet u query's handmatig samenvoegen. U moet expliciet query's starten, wachten tot ze zijn beëindigd, annuleren bij fouten en andere acties. In Delta Live Tablesgeeft u Delta Live Tables uw pijplijnen om te runnen, en het zorgt ervoor dat ze blijven draaien.
Delta Live Tables heeft ook functies zoals gematerialiseerde Views, die efficiënt en incrementeel transformaties van uw gegevens vooraf berekenen.
Zie Streamen op Azure Databricks en Wat is Delta Live Tablesvoor meer informatie over deze functies?.
Volgende stappen
Maak uw eerste pijplijn met Delta Live Tables. Zie Zelfstudie: Uw eerste Delta Live-Tables-pijplijn uitvoeren.
Voer uw eerste Structured Streaming-query's uit op Databricks. Zie Uw eerste structured streaming-workload uitvoeren.
Gebruik een gerealiseerde weergave. Zie Gerealiseerde views gebruiken in Databricks SQL.