Uitvoering van adaptieve queries
Adaptieve queryuitvoering (AQE) is het opnieuw optimaliseren van query's die plaatsvinden tijdens het uitvoeren van query's.
De motivatie voor het opnieuw optimaliseren van runtimes is dat Azure Databricks de meest up-tonauwkeurige statistieken heeft aan het einde van een shuffle- en broadcast-uitwisseling (ook wel een queryfase in AQE genoemd). Als gevolg hiervan kan Azure Databricks kiezen voor een betere fysieke strategie, een optimale partitiegrootte en -aantal na de shuffle kiezen, of optimalisaties uitvoeren die voorheen hints vereisten, zoals bijvoorbeeld scheve join-afhandeling.
Dit kan zeer nuttig zijn wanneer het verzamelen van statistieken niet is ingeschakeld of wanneer statistieken verouderd zijn. Het is ook handig op plaatsen waar statisch afgeleide statistieken onnauwkeurig zijn, zoals in het midden van een gecompliceerde query of na het voorkomen van scheeftrekken van gegevens.
Mogelijkheden
AQE is standaard ingeschakeld. Het heeft vier belangrijke functies:
- Wijzigt dynamisch de samenvoegbewerking in een broadcast-hash-join.
- Partities worden dynamisch samengevoegd (kleine partities combineren tot een redelijk formaat) na een shuffle-uitwisseling. Zeer kleine taken hebben slechtere I/O-doorvoer en hebben meestal meer last van planningsoverhead en overhead voor het instellen van taken. Door kleine taken te combineren, bespaart men middelen en verbetert men de doorvoer van het cluster.
- Verwerkt dynamisch scheefheid in sort merge-join en shuffle hash-join door scheefgetrokken taken te splitsen (en indien nodig te repliceren) in ongeveer even grote taken.
- Automatisch worden lege relaties gedetecteerd en doorgegeven.
Toepassing
AQE is van toepassing op alle query's die:
- Niet-streaming
- Bevatten ten minste één uitwisseling (meestal wanneer er een join, aggregaat of venster is), één subquery of beide.
Niet alle AQE-toegepaste query's zijn noodzakelijkerwijs opnieuw geoptimaliseerd. De heroptimalisatie kan al dan niet een ander queryplan opleveren dan het plan dat statisch is gecompileerd. Als u wilt bepalen of het plan van een query is gewijzigd door AQE, raadpleegt u de volgende sectie, Query-plannen.
Queryplannen
In deze sectie wordt beschreven hoe u queryplannen op verschillende manieren kunt onderzoeken.
In deze sectie:
Spark-gebruikersinterface
AdaptiveSparkPlan knooppunt
AQE-toegepaste queries bevatten een of meerdere AdaptiveSparkPlan knooppunten, meestal als de hoofdnode van elke hoofdquery of subquery.
Voordat de query wordt uitgevoerd of wanneer deze wordt uitgevoerd, wordt de isFinalPlan vlag van het bijbehorende AdaptiveSparkPlan knooppunt weergegeven als false; nadat de uitvoering van de query is voltooid, verandert de isFinalPlan vlag in true.
Evoluerend plan
Het queryplandiagram ontwikkelt zich naarmate de uitvoering vordert en weerspiegelt het meest recente plan dat wordt uitgevoerd. Knooppunten die al zijn uitgevoerd (waarin metrische gegevens beschikbaar zijn) zullen niet veranderen, maar knooppunten die nog niet zijn uitgevoerd, kunnen na verloop van tijd veranderen als gevolg van heroptimalisaties.
Hier volgt een voorbeeld van een queryplandiagram:
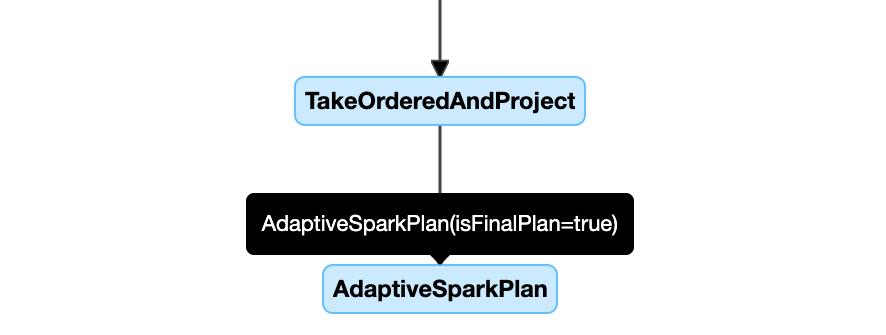
DataFrame.explain()
AdaptiveSparkPlan knooppunt
AQE-toegepaste queries bevatten een of meer AdaptiveSparkPlan-knooppunten, meestal als het hoofdknooppunt van elke hoofdquery of subquery. Voordat de query wordt uitgevoerd of wanneer deze wordt uitgevoerd, wordt de isFinalPlan vlag van het bijbehorende AdaptiveSparkPlan knooppunt weergegeven als false; Nadat de uitvoering van de query is voltooid, wordt de vlag isFinalPlan gewijzigd in true.
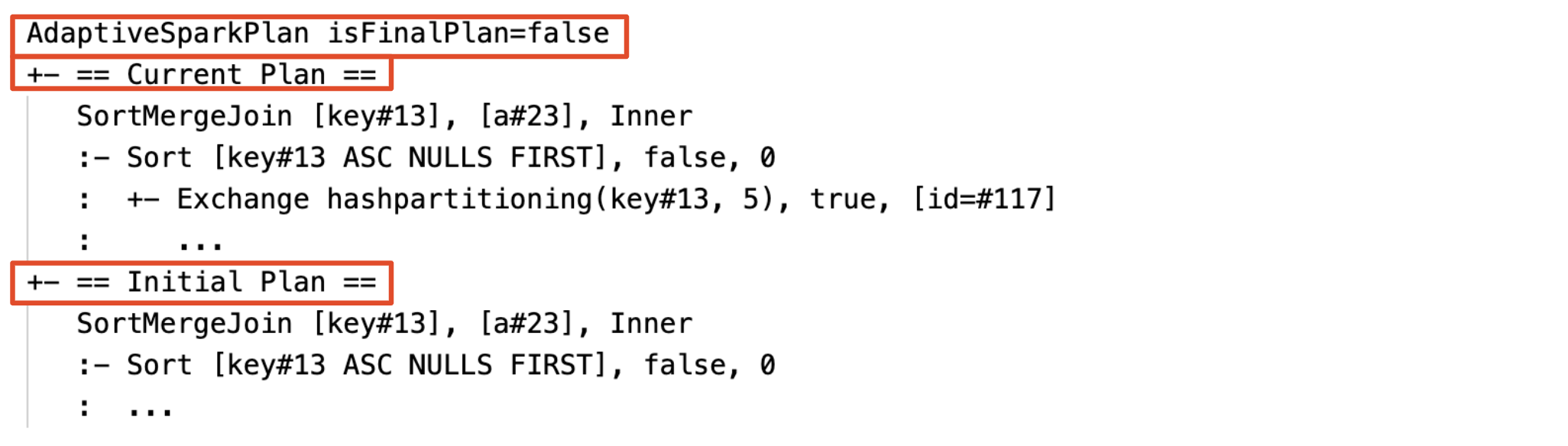
Huidig en eerste plan
Onder elk AdaptiveSparkPlan knooppunt zijn er zowel het eerste plan (het plan voordat AQE-optimalisaties worden toegepast) als het huidige of het uiteindelijke plan, afhankelijk van of de uitvoering is voltooid. Het huidige plan zal zich ontwikkelen naarmate de uitvoering vordert.
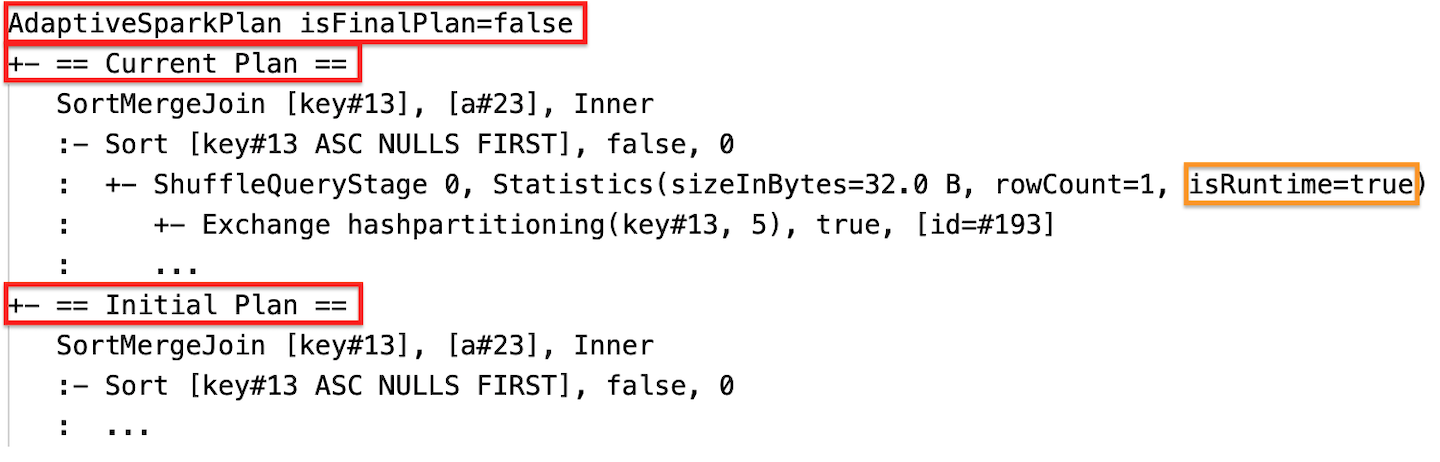
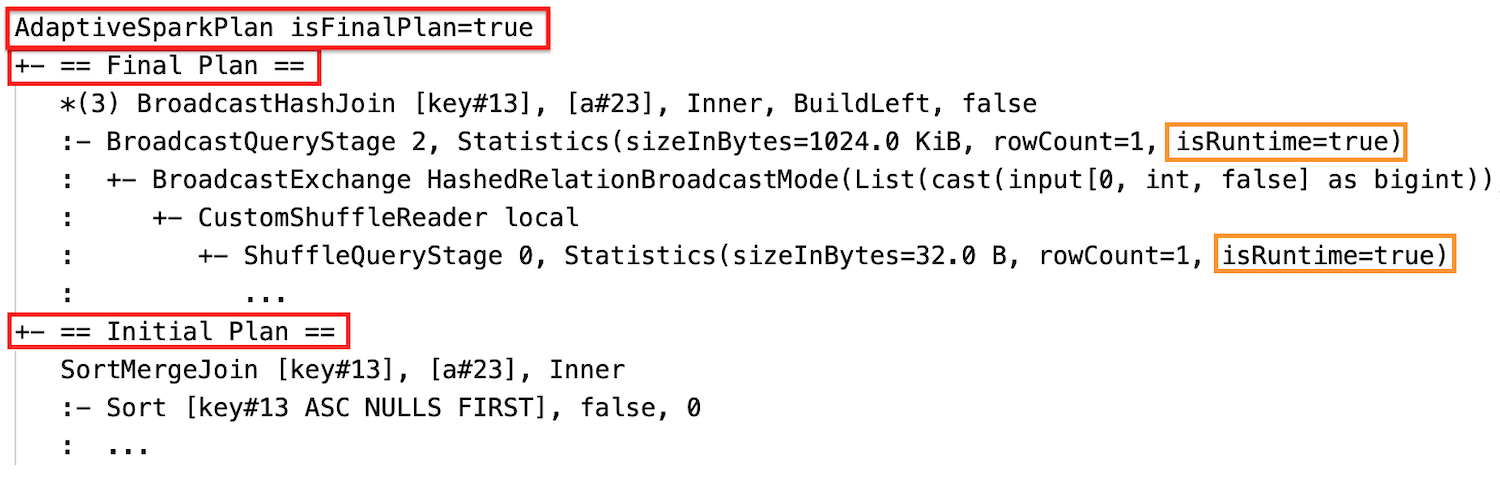
Runtimestatistieken
Elke shuffle- en broadcastfase bevat gegevensstatistieken.
Voordat de fase begint of wanneer de fase in uitvoering is, zijn de statistieken samensteltijdinschattingen, en is de vlag isRuntimefalse, bijvoorbeeld: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Nadat de uitvoering van de fase is voltooid, worden de statistieken verzameld tijdens runtime en wordt de vlag isRuntimetrue, bijvoorbeeld: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Hier volgt een DataFrame.explain voorbeeld:
Vóór de uitvoering
Tijdens de uitvoering
Na de uitvoering
SQL EXPLAIN
AdaptiveSparkPlan knooppunt
AQE-toegepaste queries bevatten een of meer AdaptiveSparkPlan-knooppunten, meestal als hoofdknooppunt van elke hoofdquery of subquery.
Geen huidig abonnement
Omdat SQL EXPLAIN de query niet uitvoert, is het huidige plan altijd hetzelfde als het oorspronkelijke plan en wordt niet weergegeven wat uiteindelijk door AQE wordt uitgevoerd.
Hier volgt een voorbeeld van een SQL-uitleg:

Effectiviteit
Het queryplan wordt gewijzigd als een of meer AQE-optimalisaties van kracht worden. Het effect van deze AQE-optimalisaties wordt gedemonstreerd door het verschil tussen de huidige en definitieve plannen en het eerste plan en specifieke planknooppunten in de huidige en definitieve plannen.
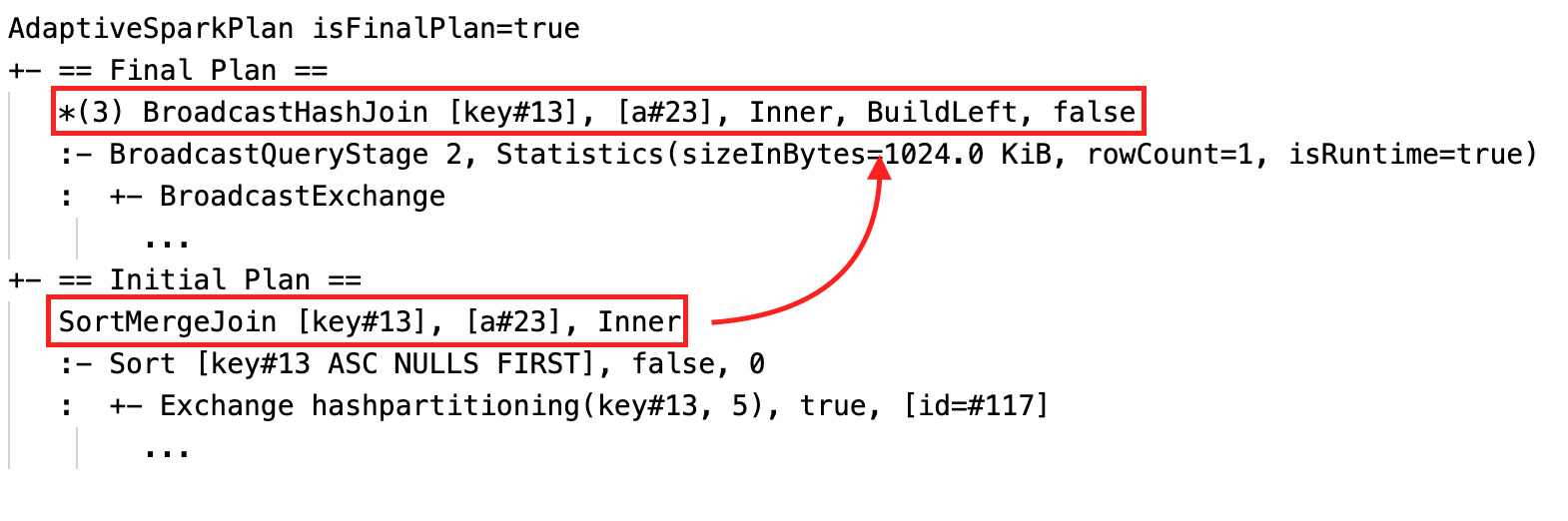
De samenvoeg-sortering dynamisch wijzigen in een uitzend-hash-join: verschillende fysieke samenvoegknooppunten tussen het huidige of definitieve plan en het beginplan.
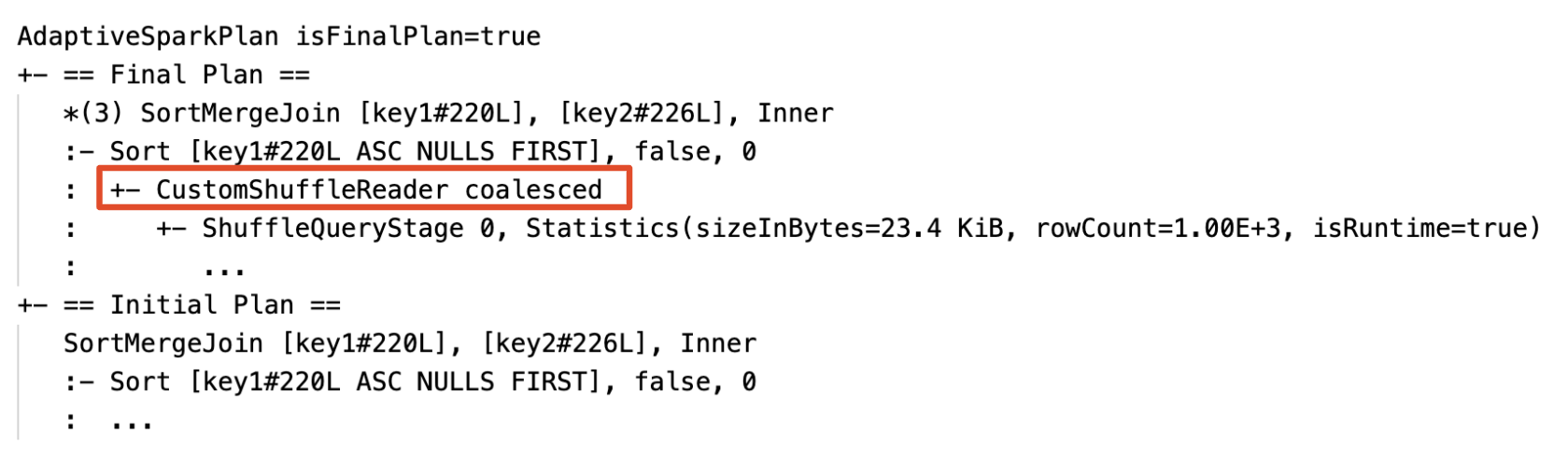
Partities dynamisch samenvoegen: knooppunt
CustomShuffleReadermet eigenschapCoalesced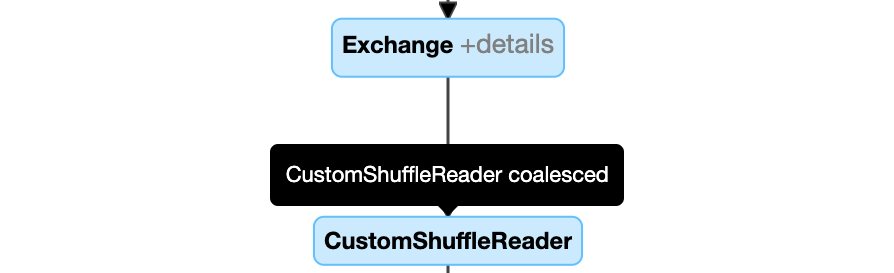
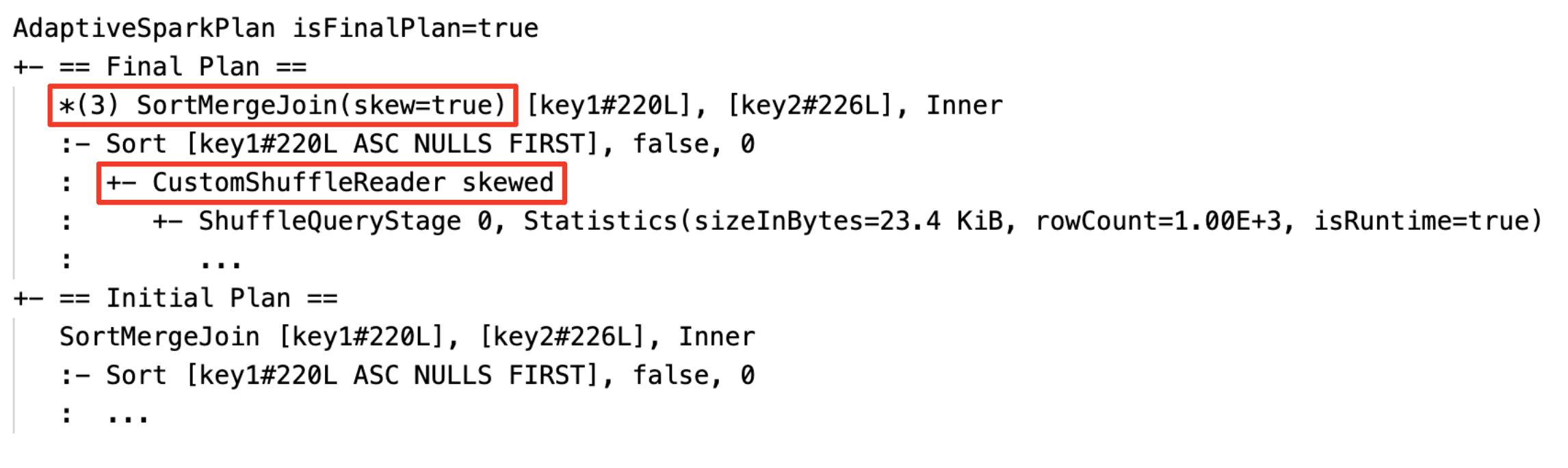
Scheve join dynamisch verwerken: knooppunt
SortMergeJoinmet veldisSkewals waar.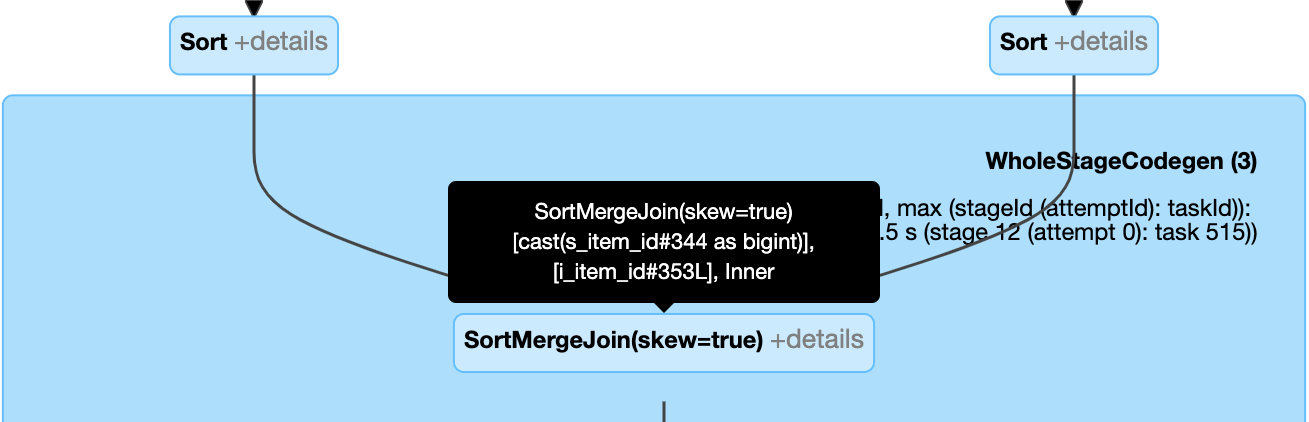
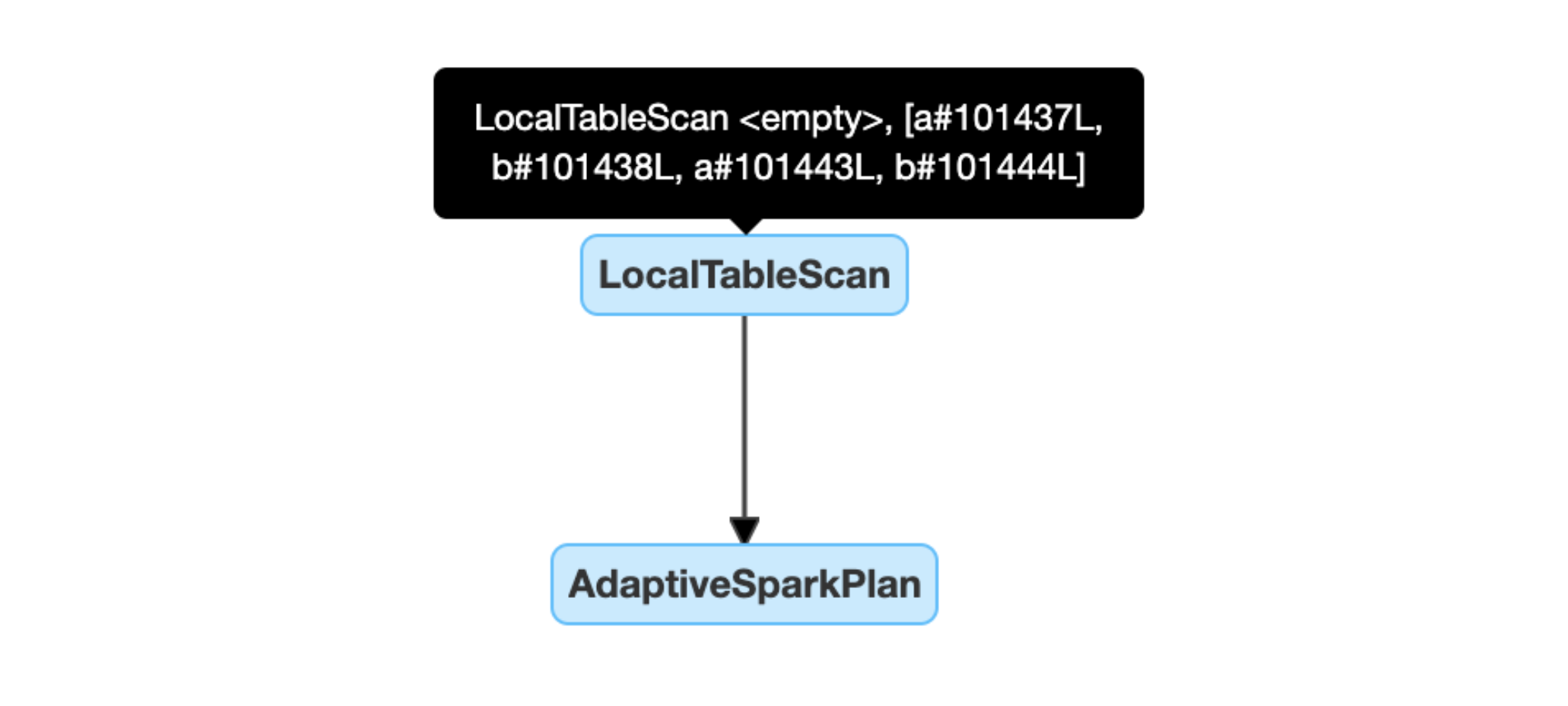
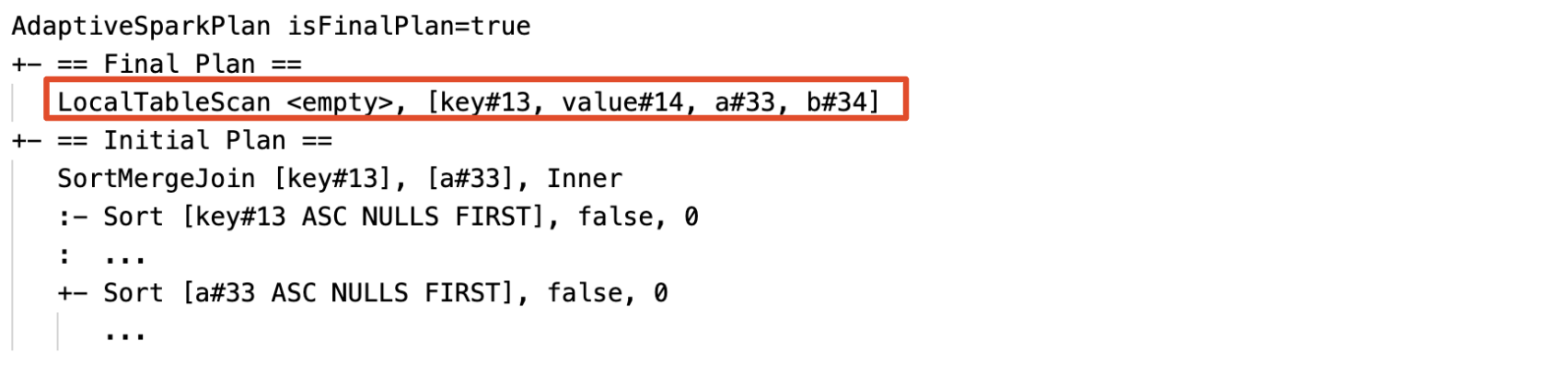
Lege relaties dynamisch detecteren en doorgeven: een deel van (of het gehele) plan wordt vervangen door de LocalTableScan-knoop, waarbij het relationele veld leeg is.
Configuratie
In deze sectie:
- adaptieve queryuitvoering in- en uitschakelen
- Automatisch geoptimaliseerde shuffle inschakelen
- de samenvoeging dynamisch wijzigen in hash-koppeling voor broadcast-
- Dynamisch samenvoegen van partities
- Dynamisch omgaan met skew join
- lege relaties dynamisch detecteren en doorgeven
Adaptieve queryuitvoering in- en uitschakelen
| Eigenschap |
|---|
|
spark.databricks.optimizer.adaptive.enabled Type: BooleanOf u adaptieve query-uitvoering wilt inschakelen of uitschakelen. Standaardwaarde: true |
Automatisch geoptimaliseerde shuffle inschakelen
| Eigenschap |
|---|
|
spark.sql.shuffle.partitions Type: IntegerHet standaardaantal partities dat moet worden gebruikt bij het opsnipperen van gegevens voor joins of aggregaties. Door de waarde auto in te stellen, wordt de automatisch geoptimaliseerde shuffle ingeschakeld. Dit getal wordt dan automatisch bepaald op basis van het queryplan en de grootte van de queryinvoergegevens.Opmerking: Voor gestructureerd streamen kan deze configuratie niet worden gewijzigd tussen opnieuw opstarten van query's vanaf dezelfde controlepuntlocatie. Standaardwaarde: 200 |
Dynamisch sorteer-samenvoeg-verbinding wijzigen in uitzenden-hash-verbinding
| Eigendom |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Type: Byte StringDe drempelwaarde voor het activeren van overschakelen naar broadcast-join tijdens runtime. Standaardwaarde: 30MB |
Dynamisch samenvoegen van partities
| Onroerend goed |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Type: BooleanOf het samenvoegen van partities moet worden in- of uitgeschakeld. Standaardwaarde: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Type: Byte StringDe doelgrootte na het samenvoegen. De grootten van de gesamenceerde partities liggen dicht bij, maar niet groter dan deze doelgrootte. Standaardwaarde: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Type: Byte StringDe minimale grootte van partities na het samenvoegen. De grootten van de samengesamende partities zijn niet kleiner dan deze grootte. Standaardwaarde: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Type: IntegerHet minimale aantal partities na het samenvoegen. Niet aanbevolen, omdat het instellen expliciet overschrijft spark.sql.adaptive.coalescePartitions.minPartitionSize.Standaardwaarde: 2x aantal clustercores |
Scheefheidsdeelname dynamisch verwerken
| Eigendom |
|---|
|
spark.sql.adaptive.skewJoin.enabled Type: BooleanOf u het verwerken van schuine joins wilt in- of uitschakelen. Standaardwaarde: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Type: IntegerEen factor die bij vermenigvuldiging met de mediaanpartitiegrootte bijdraagt aan het bepalen of een partitie scheef is. Standaardwaarde: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Type: Byte StringEen drempelwaarde die bijdraagt aan het bepalen of een partitie scheef is. Standaardwaarde: 256MB |
Een partitie wordt als scheef beschouwd wanneer zowel (partition size > skewedPartitionFactor * median partition size) als (partition size > skewedPartitionThresholdInBytes)truezijn.
Lege relaties dynamisch detecteren en doorgeven
| Eigendom |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Type: BooleanHiermee wordt aangegeven of dynamische leeg-relatie propagatie moet worden in- of uitgeschakeld. Standaardwaarde: true |
Veelgestelde vragen (FAQ)
In deze sectie:
- Waarom heeft AQE geen kleine koppelingstabel verspreid?
- Moet ik nog steeds een hint of aanwijzing voor een broadcast-joinstrategie gebruiken met AQE ingeschakeld?
- Wat is het verschil tussen de scheefheids-hint voor joins en de scheefheidsoptimalisatie voor AQE-joins? Welke moet ik gebruiken?
- Waarom heeft AQE mijn joinvolgorde niet automatisch aangepast?
- Waarom heeft AQE mijn gegevens scheeftrekken niet gedetecteerd?
Waarom heeft AQE geen kleine join-tabel uitgezonden?
Als de grootte van de verwachte relatie onder deze drempelwaarde valt, maar nog steeds niet wordt uitgezonden:
- Controleer het verbindingstype. Broadcast wordt niet ondersteund voor bepaalde jointypen, bijvoorbeeld de linkerrelatie van een
LEFT OUTER JOINkan niet worden uitgezonden. - Het kan ook zijn dat de relatie veel lege partities bevat. In dat geval kan het merendeel van de taken snel worden voltooid met sort merge join of kan deze worden geoptimaliseerd met de verwerking van scheve joins. AQE vermijdt het omzetten van sort merge joins naar broadcast-hash-joins als het percentage niet-lege partities lager is dan
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Kan ik nog steeds een hint voor een broadcast-joinstrategie gebruiken als AQE is ingeschakeld?
Ja. Een statisch geplande broadcast-join is meestal beter presterend dan een door AQE dynamisch geplande join, omdat AQE mogelijk pas overschakelt naar broadcast-join nadat voor beide zijden van de join een shuffle is uitgevoerd, tegen die tijd de werkelijke grootte van de relaties bekend zijn. Het gebruik van een broadcast-hint kan dus nog steeds een goede keuze zijn als u uw query goed kent. AQE respecteert queryhints op dezelfde manier als statische optimalisatie, maar kan dynamische optimalisaties toepassen die niet worden beïnvloed door de hints.
Wat is het verschil tussen skew join-hint en AQE scheve join- optimalisatie? Welke moet ik gebruiken?
Het wordt aanbevolen om te vertrouwen op AQE scheefheidsdeelnameverwerking in plaats van de scheefheidshint te gebruiken, omdat AQE-scheefheidsdeelname volledig automatisch is en in het algemeen beter presteert dan de hint-tegenhanger.
Waarom heeft AQE niet automatisch mijn join-volgorde aangepast?
Dynamische joins opnieuw ordenen maakt geen deel uit van AQE.
Waarom heeft AQE mijn gegevens scheeftrekken niet gedetecteerd?
Er zijn twee groottevoorwaarden waaraan moet worden voldaan voor AQE om een partitie te detecteren als een scheve partitie:
- De partitiegrootte is groter dan de
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(standaard 256 MB) - De partitiegrootte is groter dan de mediaangrootte van alle partities en de scheve partitiefactor
spark.sql.adaptive.skewJoin.skewedPartitionFactor(standaard 5)
Bovendien is de ondersteuning voor de optimalisatie van scheeftrekking beperkt voor bepaalde jointypen, bijvoorbeeld in LEFT OUTER JOINkan alleen scheeftrekking aan de linkerkant worden geoptimaliseerd.
Nalatenschap
De term Adaptieve uitvoering bestaat sinds Spark 1.6, maar de nieuwe AQE in Spark 3.0 is fundamenteel anders. Wat functionaliteit betreft, voert Spark 1.6 alleen de 'dynamisch samenvoegen van partities' uit. Wat de technische architectuur betreft, is de nieuwe AQE een framework van dynamische planning en herplanning van query's op basis van runtimestatistieken, die ondersteuning biedt voor diverse optimalisaties, zoals de optimalisaties die we in dit artikel hebben beschreven en kunnen worden uitgebreid om meer mogelijke optimalisaties mogelijk te maken.