TensorBoard
TensorBoard is een reeks visualisatiehulpprogramma's voor foutopsporing, optimalisatie en begrip van TensorFlow, PyTorch, Hugging Face Transformers en andere machine learning-programma's.
TensorBoard gebruiken
Het starten van TensorBoard in Azure Databricks verschilt niet van het starten ervan op een Jupyter-notebook op uw lokale computer.
Laad de
%tensorboardmagic-opdracht en definieer uw logboekmap.%load_ext tensorboard experiment_log_dir = <log-directory>Roep de
%tensorboardmagic-opdracht aan.%tensorboard --logdir $experiment_log_dirDe TensorBoard-server wordt gestart en geeft de gebruikersinterface inline weer in het notebook. Het bevat ook een koppeling om TensorBoard te openen op een nieuw tabblad.
In de volgende schermopname ziet u hoe de Gebruikersinterface van TensorBoard is gestart in een gevulde logboekmap.
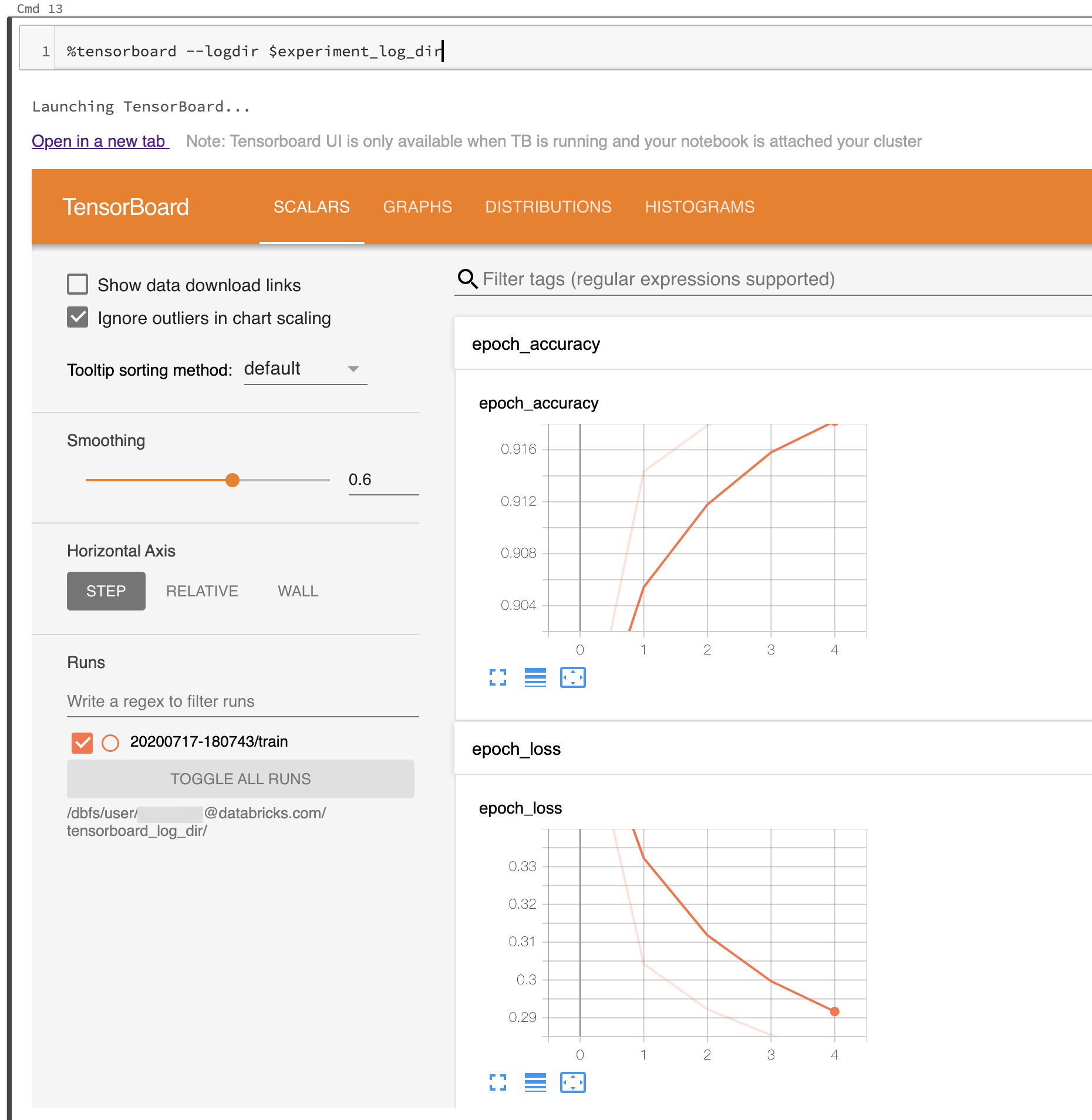
U kunt TensorBoard ook rechtstreeks starten met behulp van de notebookmodule van TensorBoard.
from tensorboard import notebook
notebook.start("--logdir {}".format(experiment_log_dir))
TensorBoard-logboeken en -mappen
TensorBoard visualiseert uw machine learning-programma's door logboeken te lezen die zijn gegenereerd door callbacks en functies van TensorBoard of PyTorch. Als u logboeken voor andere machine learning-bibliotheken wilt genereren, kunt u logboeken rechtstreeks schrijven met behulp van TensorFlow-bestandsschrijvers (zie Module: tf.summary voor TensorFlow 2.x en zie Module: tf.compat.v1.summary voor de oudere API in TensorFlow 1.x).
Om ervoor te zorgen dat uw experimentlogboeken betrouwbaar worden opgeslagen, raadt Databricks aan om logboeken naar cloudopslag te schrijven in plaats van in het tijdelijke clusterbestandssysteem. Start TensorBoard voor elk experiment in een unieke map. Voor elke uitvoering van uw machine learning-code in het experiment waarmee logboeken worden gegenereerd, stelt u de Callback van TensorBoard of file writer in om naar een submap van de experimentmap te schrijven. Op die manier worden de gegevens in de Gebruikersinterface van TensorBoard onderverdeeld in uitvoeringen.
Lees de officiële TensorBoard-documentatie om aan de slag te gaan met TensorBoard om informatie voor uw Machine Learning-programma te registreren.
TensorBoard-processen beheren
De TensorBoard-processen die zijn gestart in Azure Databricks-notebook, worden niet beëindigd wanneer het notebook wordt losgekoppeld of de REPL opnieuw wordt gestart (bijvoorbeeld wanneer u de status van het notebook wist). Als u een TensorBoard-proces handmatig wilt beëindigen, verzendt u het een beëindigingssignaal met behulp van %sh kill -15 pid. TensorBoard-processen kunnen notebook.list()beschadigd raken.
Als u de TensorBoard-servers wilt weergeven die momenteel worden uitgevoerd op uw cluster, met de bijbehorende logboekmappen en proces-id's, voert u deze uit notebook.list() vanuit de TensorBoard-notebookmodule.
Bekende problemen
- De inline TensorBoard-gebruikersinterface bevindt zich in een iframe. Browserbeveiligingsfuncties voorkomen dat externe koppelingen in de gebruikersinterface werken, tenzij u de koppeling op een nieuw tabblad opent.
- De
--window_titleoptie van TensorBoard wordt overschreven in Azure Databricks. - TensorBoard scant standaard een poortbereik voor het selecteren van een poort om naar te luisteren. Als er te veel TensorBoard-processen worden uitgevoerd op het cluster, zijn alle poorten in het poortbereik mogelijk niet beschikbaar. U kunt deze beperking omzeilen door een poortnummer met het
--portargument op te geven. De opgegeven poort moet tussen 6006 en 6106 zijn. - Als u koppelingen wilt downloaden, moet u TensorBoard openen op een tabblad.
- Wanneer u TensorBoard 1.15.0 gebruikt, is het tabblad Projector leeg. Als tijdelijke oplossing kunt u de projectorpagina rechtstreeks bezoeken door de URL
#projectorte vervangendata/plugin/projector/projector_binary.html. - TensorBoard 2.4.0 heeft een bekend probleem dat van invloed kan zijn op tensorBoard-rendering als de upgrade wordt uitgevoerd.
- Als u tensorBoard-gerelateerde gegevens aan DBFS of UC Volumes vastgeeft, krijgt u mogelijk een foutmelding zoals
No dashboards are active for the current data set. Om deze fout te verhelpen, is het raadzaam om aan te roepenwriter.flush()enwriter.close()na het gebruik van dewriterom gegevens te registreren. Dit zorgt ervoor dat alle vastgelegde gegevens correct zijn geschreven en beschikbaar zijn om TensorBoard weer te geven.