Modelimplementatiepatronen
In dit artikel worden twee veelvoorkomende patronen beschreven voor het verplaatsen van ML-artefacten via fasering en productie. De asynchrone aard van wijzigingen in modellen en code betekent dat er meerdere mogelijke patronen zijn die een ML-ontwikkelingsproces kan volgen.
Modellen worden gemaakt op basis van code, maar de resulterende modelartefacten en de code die ze hebben gemaakt, kunnen asynchroon werken. Dat wil gezegd dat nieuwe modelversies en codewijzigingen mogelijk niet tegelijkertijd plaatsvinden. Neem bijvoorbeeld de volgende scenario's:
- Als u frauduleuze transacties wilt detecteren, ontwikkelt u een ML-pijplijn waarmee een model wekelijks opnieuw wordt getraind. De code kan mogelijk niet erg vaak veranderen, maar het model kan elke week opnieuw worden getraind om nieuwe gegevens op te nemen.
- U kunt een groot, diep neuraal netwerk maken om documenten te classificeren. In dit geval is het trainen van het model rekenkracht duur en tijdrovend en wordt het model waarschijnlijk onregelmatig opnieuw getraind. De code die dit model implementeert, verwerkt en bewaakt, kan echter worden bijgewerkt zonder het model opnieuw te trainen.
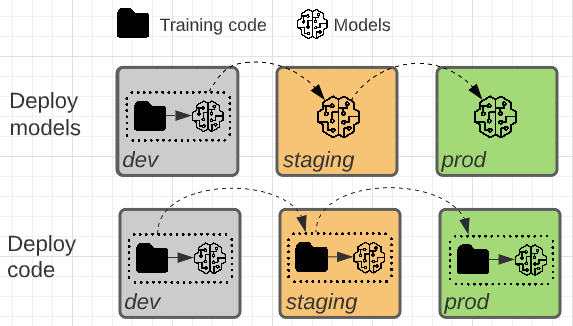
De twee patronen verschillen in het feit of het modelartefact of de trainingscode die het modelartefact produceert, naar productie wordt gepromoveerd.
Code implementeren (aanbevolen)
In de meeste gevallen raadt Databricks de benadering 'code implementeren' aan. Deze benadering wordt opgenomen in de aanbevolen MLOps-werkstroom.
In dit patroon wordt de code voor het trainen van modellen ontwikkeld in de ontwikkelomgeving. Dezelfde code wordt verplaatst naar fasering en vervolgens productie. Het model wordt getraind in elke omgeving: in eerste instantie in de ontwikkelomgeving als onderdeel van modelontwikkeling, fasering (op een beperkte subset van gegevens) als onderdeel van integratietests en in de productieomgeving (op de volledige productiegegevens) om het uiteindelijke model te produceren.
Voordelen:
- In organisaties waar de toegang tot productiegegevens wordt beperkt, kan dit patroon het model trainen op productiegegevens in de productieomgeving.
- Geautomatiseerde hertraining van modellen is veiliger, omdat de trainingscode wordt beoordeeld, getest en goedgekeurd voor productie.
- Ondersteunende code volgt hetzelfde patroon als modeltrainingscode. Beide gaan door integratietests in fasering.
Nadelen:
- De leercurve voor gegevenswetenschappers om code af te geven aan medewerkers kan steil zijn. Vooraf gedefinieerde projectsjablonen en werkstromen zijn handig.
In dit patroon moeten gegevenswetenschappers ook trainingsresultaten uit de productieomgeving kunnen bekijken, omdat ze de kennis hebben om ML-specifieke problemen te identificeren en op te lossen.
Als uw situatie vereist dat het model wordt getraind in fasering via de volledige productiegegevensset, kunt u een hybride benadering gebruiken door code te implementeren voor fasering, het model te trainen en vervolgens het model in productie te implementeren. Deze benadering bespaart trainingskosten in productie, maar voegt extra bewerkingskosten toe in fasering.
Modellen implementeren
In dit patroon wordt het modelartefact gegenereerd door trainingscode in de ontwikkelomgeving. Het artefact wordt vervolgens getest in de faseringsomgeving voordat het in productie wordt geïmplementeerd.
Houd rekening met deze optie wanneer een of meer van de volgende opties van toepassing zijn:
- Modeltraining is erg duur of moeilijk te reproduceren.
- Al het werk wordt uitgevoerd in één Azure Databricks-werkruimte.
- U werkt niet met externe opslagplaatsen of een CI/CD-proces.
Voordelen:
- Een eenvoudigere overdracht voor gegevenswetenschappers
- In gevallen waarin modeltraining duur is, is het trainen van het model slechts eenmaal vereist.
Nadelen:
- Als productiegegevens niet toegankelijk zijn vanuit de ontwikkelomgeving (wat om veiligheidsredenen waar kan zijn), is deze architectuur mogelijk niet haalbaar.
- Geautomatiseerde hertraining van modellen is lastig in dit patroon. U kunt het opnieuw trainen automatiseren in de ontwikkelomgeving, maar het team dat verantwoordelijk is voor het implementeren van het model in productie, accepteert mogelijk niet het resulterende model als productieklaar.
- Ondersteunende code, zoals pijplijnen die worden gebruikt voor functie-engineering, deductie en bewaking, moet afzonderlijk worden geïmplementeerd in productie.
Doorgaans komt een omgeving (ontwikkeling, fasering of productie) overeen met een catalogus in Unity Catalog. Zie de upgradehandleiding voor meer informatie over het implementeren van dit patroon.
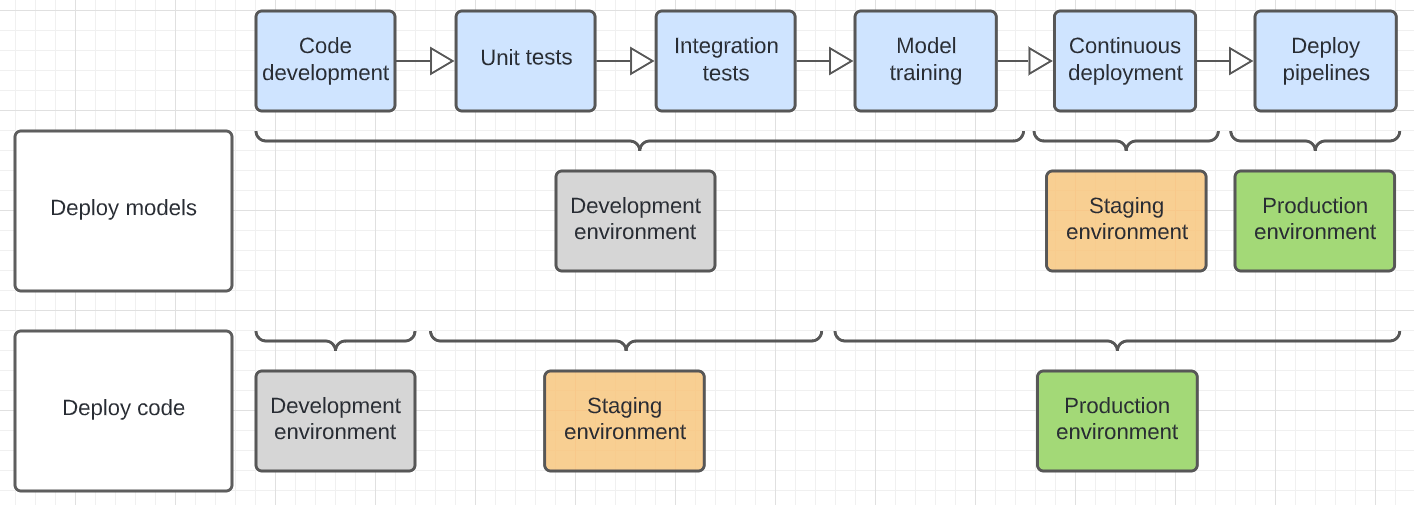
Het onderstaande diagram contrasteert de levenscyclus van de code voor de bovenstaande implementatiepatronen in de verschillende uitvoeringsomgevingen.
De omgeving die in het diagram wordt weergegeven, is de laatste omgeving waarin een stap wordt uitgevoerd. In het implementatiemodelpatroon worden bijvoorbeeld de laatste eenheids- en integratietests uitgevoerd in de ontwikkelomgeving. In het implementatiecodepatroon worden eenheidstests en integratietests uitgevoerd in de ontwikkelomgevingen en wordt de laatste eenheid en integratietests uitgevoerd in de faseringsomgeving.