Een trainingsuitvoering maken met behulp van de Foundation Model Fine-tuning-API
Belangrijk
Deze functie bevindt zich in openbare preview in de volgende regio's: , centralus, eastus, en eastus2northcentralus.westus
In dit artikel wordt beschreven hoe u een trainingsuitvoering maakt en configureert met behulp van de Foundation Model Fine-tuning (nu onderdeel van de Mosaic AI Model Training) API en beschrijft alle parameters die worden gebruikt in de API-aanroep. U kunt ook een uitvoering maken met behulp van de gebruikersinterface. Zie Een trainingsuitvoering maken met behulp van de gebruikersinterface voor het verfijnen van foundationmodellen voor instructies.
Eisen
Zie Vereisten.
Een trainingsuitvoering maken
Als u programmatisch trainingsuitvoeringen wilt maken, gebruikt u de create() functie. Met deze functie traint u een model op de opgegeven gegevensset en converteert u het uiteindelijke controlepunt Composer naar een met Hugging Face opgemaakt controlepunt voor deductie.
De vereiste invoer is het model dat u wilt trainen, de locatie van uw trainingsgegevensset en where om uw model te registreren. Er zijn ook optionele parameters waarmee u evaluatie kunt uitvoeren en de hyperparameters van uw uitvoering kunt wijzigen.
Nadat de uitvoering is voltooid, worden de voltooide uitvoering en het uiteindelijke controlepunt opgeslagen, wordt het model gekloond en wordt die kloon geregistreerd bij Unity Catalog als modelversie voor deductie.
Het model uit de voltooide uitvoering niet de gekloonde modelversie in Unity Catalogen de bijbehorende Composer- en Hugging Face-controlepunten worden opgeslagen in MLflow. De Composer-controlepunten kunnen worden gebruikt voor vervolgafstemmingstaken.
Zie Een trainingsuitvoering configureren voor meer informatie over argumenten voor de create() functie.
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Een trainingsuitvoering configureren
De volgende table vat de parameters voor de functie foundation_model.create() samen.
| Parameter | Vereist | Type | Omschrijving |
|---|---|---|---|
model |
x | Str | De naam van het model dat moet worden gebruikt. Zie Ondersteunde modellen. |
train_data_path |
x | Str | De locatie van uw trainingsgegevens. Dit kan een locatie zijn in Unity Catalog (<catalog>.<schema>.<table> of dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl), of een HuggingFace-gegevensset.Hiervoor INSTRUCTION_FINETUNEmoeten de gegevens worden opgemaakt met elke rij die een prompt en response veld bevat.Dit CONTINUED_PRETRAINis een map met .txt bestanden. Zie Gegevens voorbereiden voor het verfijnen van Foundation-modellen voor geaccepteerde gegevensindelingen en aanbevolen gegevensgrootte voor modeltraining voor aanbevelingen voor gegevensgrootte. |
register_to |
x | Str | De Unity-Catalogcatalog en schema (<catalog>.<schema> of <catalog>.<schema>.<custom-name>) where het model wordt geregistreerd nadat het model is getraind voor eenvoudige implementatie. Als custom-name dit niet is opgegeven, wordt deze standaard ingesteld op de uitvoeringsnaam. |
data_prep_cluster_id |
Str | De cluster-id van het cluster dat moet worden gebruikt voor spark-gegevensverwerking. Dit is vereist voor instructietrainingstaken where, waarbij de trainingsgegevens zich in een Delta-tablebevinden. Zie Get cluster-idvoor meer informatie over het vinden van de cluster-id. | |
experiment_path |
Str | Het pad naar het MLflow-experiment where de uitvoer van de trainingsuitvoering (metrische gegevens en controlepunten) wordt opgeslagen. De standaardinstelling is de uitvoeringsnaam binnen de persoonlijke werkruimte van de gebruiker (dat wil bijvoorbeeld /Users/<username>/<run_name>). |
|
task_type |
Str | Het type taak dat moet worden uitgevoerd.
CHAT_COMPLETION Kan (standaard) CONTINUED_PRETRAINof INSTRUCTION_FINETUNE. |
|
eval_data_path |
Str | De externe locatie van uw evaluatiegegevens (indien van toepassing). Moet dezelfde indeling hebben als train_data_path. |
|
eval_prompts |
List[str] | Een list aan promptreeksen naar antwoorden met generate tijdens de evaluatie. De standaardinstelling is None (niet generate prompts). Resultaten worden bij het experiment geregistreerd wanneer het model wordt gecontroleerd. Generaties vinden plaats op elk controlepunt van het model met de volgende generatie parameters: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
Str | De externe locatie van een aangepast modelcontrolepunt voor training. Standaard is None, wat betekent dat de uitvoering begint vanaf de oorspronkelijke vooraf getrainde gewichten van het gekozen model. Als er aangepaste gewichten worden opgegeven, worden deze gewichten gebruikt in plaats van de oorspronkelijke vooraf getrainde gewichten van het model. Deze gewichten moeten een controlepunt van Composer zijn en moeten overeenkomen met de architectuur van de model opgegeven. Zie Bouwen op aangepaste modelgewichten |
|
training_duration |
Str | De totale duur van de uitvoering. De standaardwaarde is één epoch of 1ep. Kan worden opgegeven in epochs (10ep) of tokens (1000000tok). |
|
learning_rate |
Str | Het leerpercentage voor modeltraining. Voor alle andere modellen dan Llama 3.1 405B Instruct is 5e-7de standaardleersnelheid. Voor Llama 3.1 405B Instruct is 1.0e-5de standaardleersnelheid. De optimizer is Decoupled SliceW met bèta's van 0,99 en 0,95 en geen gewichtsverval. De learning rate scheduler is LinearWithWarmupSchedule met een opwarming van 2% van de totale trainingsduur en een uiteindelijke vermenigvuldiger van het leerpercentage van 0. |
|
context_length |
Str | De maximale reekslengte van een gegevensvoorbeeld. Dit wordt gebruikt voor het afkappen van gegevens die te lang zijn en om kortere reeksen samen te verpakken voor efficiëntie. De standaardwaarde is 8192 tokens of de maximale contextlengte voor het opgegeven model, afhankelijk van wat lager is. U kunt deze parameter gebruiken om de contextlengte te configureren, maar het configureren buiten de maximale contextlengte van elk model wordt niet ondersteund. Zie Ondersteunde modellen voor de maximale ondersteunde contextlengte van elk model. |
|
validate_inputs |
Booleaanse waarde | Hiermee wordt aangegeven of de toegang tot invoerpaden moet worden gevalideerd voordat u de trainingstaak indient. Standaard is True. |
Bouwen op aangepaste modelgewichten
Foundation Model Fine-tuning ondersteunt het toevoegen van aangepaste gewichten met behulp van de optionele parameter custom_weights_path om een model te trainen en aan te passen.
Om get te starten, setcustom_weights_path naar het Composer controlepunt van een eerdere trainingssessie. Controlepuntpaden vindt u op het tabblad Artefacten van een vorige MLflow-uitvoering. De mapnaam van het controlepunt komt overeen met de batch en het tijdvak van een bepaalde momentopname, zoals ep29-ba30/.

- Als u het laatste controlepunt van een vorige uitvoering wilt opgeven, set
custom_weights_pathnaar het controlepunt Composer. Bijvoorbeeld:custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Om een eerder controlepunt op te geven, geeft set
custom_weights_patheen pad op naar een map met.distcpbestanden die overeenkomen met het gewenste controlepunt, zoalscustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Vervolgens update de parameter model overeenkomen met het basismodel van het controlepunt dat u hebt doorgegeven aan custom_weights_path.
In het volgende voorbeeld ift-meta-llama-3-1-70b-instruct-ohugkq is een vorige uitvoering die fijn is meta-llama/Meta-Llama-3.1-70B. Om het nieuwste controlepunt vanuit ift-meta-llama-3-1-70b-instruct-ohugkqte verfijnen, stel de variabelen set, model en custom_weights_path als volgt in:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Zie Een trainingsuitvoering configureren voor het configureren van andere parameters in de uitvoering voor het afstemmen.
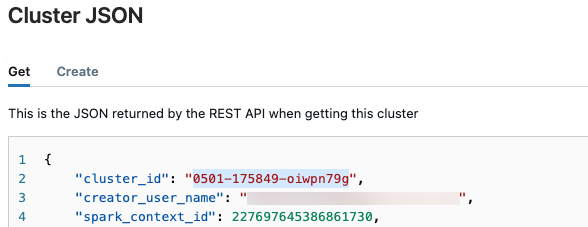
Get cluster ID
De cluster-id ophalen:
Klik in de linkernavigatiebalk van de Databricks-werkruimte op Compute.
Klik in de tableop de naam van het cluster.
Klik op de knop Meer
 in de rechterbovenhoek en selecteer selectJSON weergeven in het uitklapmenu.
in de rechterbovenhoek en selecteer selectJSON weergeven in het uitklapmenu.Het JSON-clusterbestand wordt weergegeven. Kopieer de cluster-id, de eerste regel in het bestand.
Get status van een run
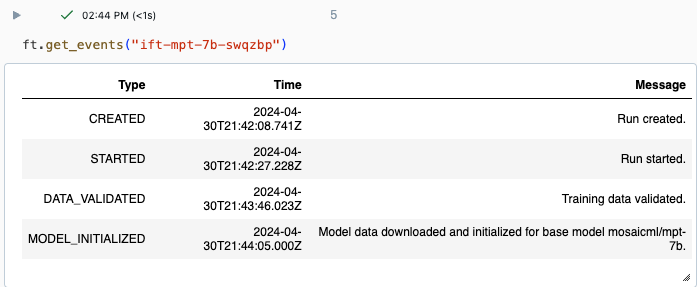
U kunt de voortgang van een uitvoering bijhouden met behulp van de pagina Experiment in de Databricks-gebruikersinterface of met behulp van de API-opdracht get_events(). Zie Uitvoeringen van Foundation-modellen weergeven, beheren en analyseren voor meer informatie.
Voorbeelduitvoer van get_events():
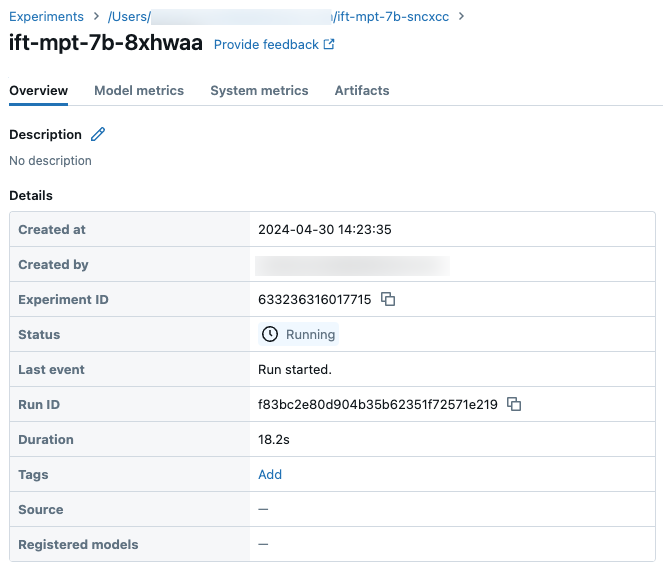
Details van voorbeelduitvoering op de pagina Experiment:
Volgende stappen
Nadat de trainingsuitvoering is voltooid, kunt u metrische gegevens bekijken in MLflow en uw model implementeren voor deductie. Zie stap 5 tot en met 7 van de zelfstudie: Een uitvoering voor het verfijnen van een Foundation-model maken en implementeren.
Zie het instructiedemonotitieblok: demonotitieblok voor entiteitsherkenning voor een voorbeeld van het verfijnen van instructies voor het voorbereiden van gegevens, het afstemmen van de configuratie en implementatie van trainingsuitvoeringen.
Voorbeeld van notitieblok
In het volgende notebook ziet u een voorbeeld van het generate van synthetische gegevens met behulp van het Meta Llama 3.1 405B Instruct-model en het gebruik van die gegevens om een model af te stemmen:
Generate synthetische gegevens met behulp van Llama 3.1 405B Instruct notebook
Aanvullende bronnen
- Foundation Model Fine-tuning
- Zelfstudie: Een uitvoering voor het verfijnen van een Foundation-model maken en implementeren
- Een trainingsuitvoering maken met behulp van de gebruikersinterface voor het verfijnen van foundationmodellen
- Uitvoeringen van Foundation-modellen weergeven, beheren en analyseren
- Gegevens voorbereiden voor het afstemmen van Foundation Model