Het bereik van het Lakehouse-platform
Een modern data- en AI-platformframework
Als u het bereik van het Databricks Data Intelligence Platform wilt bespreken, is het handig om eerst een basisframework te definiëren voor het moderne gegevens- en AI-platform:
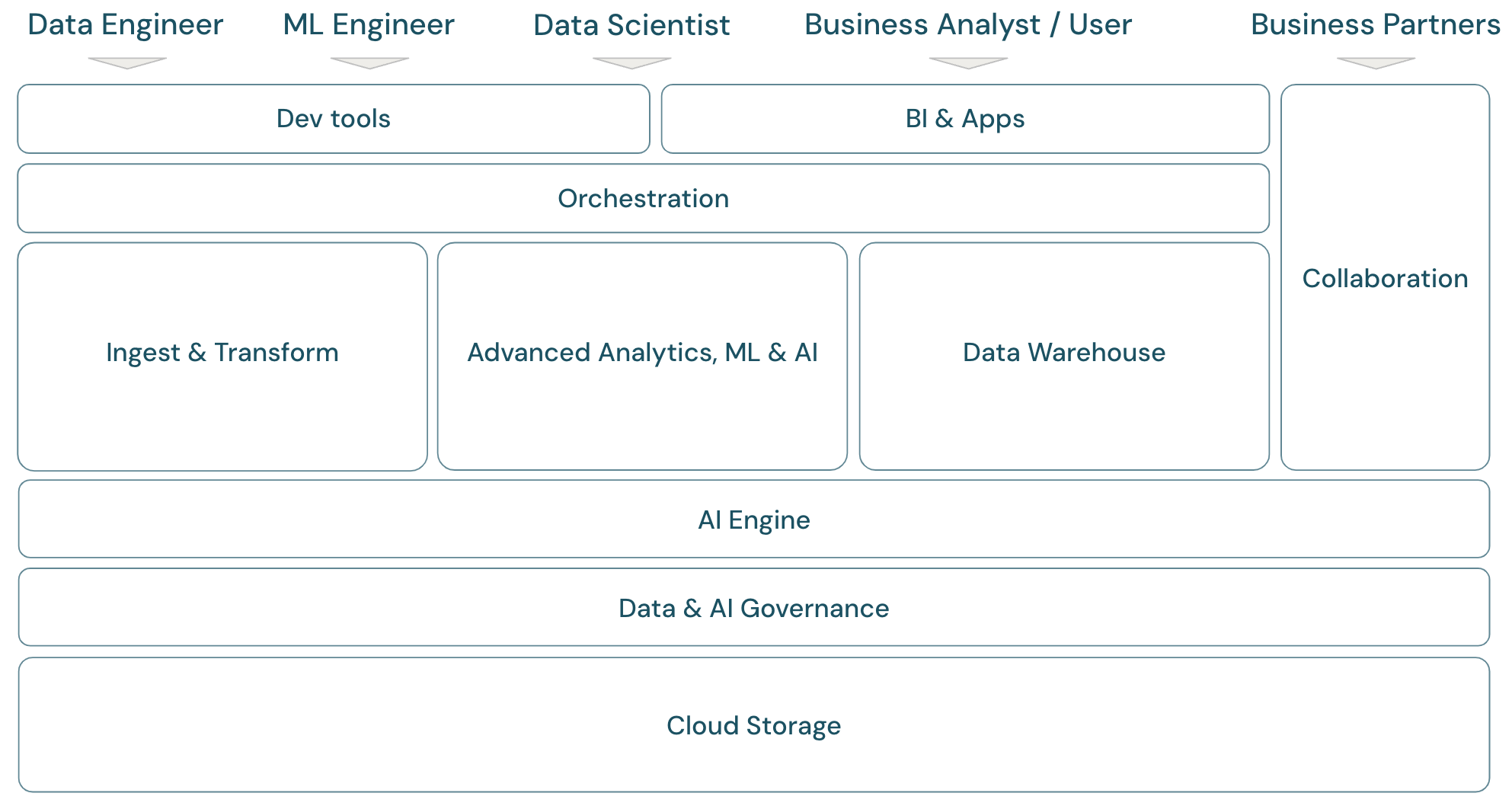
Overzicht van het lakehouse-bereik
Het Databricks Data Intelligence Platform omvat het volledige moderne gegevensplatformframework. Het is gebouwd op de lakehouse-architectuur en wordt mogelijk gemaakt door een data intelligence-engine die inzicht heeft in de unieke kwaliteiten van uw gegevens. Het is een open en uniforme basis voor ETL-, ML/AI- en DWH/BI-workloads en heeft Unity Catalog als de centrale oplossing voor gegevens en AI-governance.
Persona's van het platformframework
Het framework behandelt de primaire leden van het gegevensteam (persona's) die met de toepassingen in het framework werken:
- Data engineers bieden gegevenswetenschappers en bedrijfsanalisten nauwkeurige en reproduceerbare gegevens voor tijdige besluitvorming en realtime inzichten. Ze implementeren zeer consistente en betrouwbare ETL-processen om het vertrouwen van gebruikers in gegevens te vergroten. Ze zorgen ervoor dat gegevens goed zijn geïntegreerd met de verschillende pijlers van het bedrijf en doorgaans de best practices voor software-engineering volgen.
- Gegevenswetenschappers combineren analytische expertise en bedrijfskennis om gegevens te transformeren in strategische inzichten en voorspellende modellen. Ze zijn bedreven in het vertalen van zakelijke uitdagingen in gegevensgestuurde oplossingen, hetzij door middel van retrospectief analytische inzichten of vooruitziende voorspellende modellering. Door gebruik te maken van gegevensmodellering en machine learning-technieken, ontwerpen, ontwikkelen en implementeren ze modellen die patronen, trends en prognoses van gegevens onthullen. Ze fungeren als een brug, zetten complexe gegevensverhalen om in begrijpelijke verhalen, zodat zakelijke belanghebbenden niet alleen begrijpen, maar ook kunnen reageren op de gegevensgestuurde aanbevelingen, op hun beurt een gegevensgerichte benadering van probleemoplossing binnen een organisatie stimuleren.
- ML-engineers (machine learning-engineers) leiden tot de praktische toepassing van data science in producten en oplossingen door machine learning-modellen te bouwen, te implementeren en te onderhouden. Hun primaire focus is gericht op het technische aspect van modelontwikkeling en -implementatie. ML-technici zorgen voor de robuustheid, betrouwbaarheid en schaalbaarheid van machine learning-systemen in liveomgevingen, waarbij uitdagingen worden aangepakt met betrekking tot gegevenskwaliteit, infrastructuur en prestaties. Door AI- en ML-modellen te integreren in operationele bedrijfsprocessen en gebruikersgerichte producten, vergemakkelijken ze het gebruik van gegevenswetenschap bij het oplossen van zakelijke uitdagingen, waardoor modellen niet alleen in onderzoek blijven, maar tastbare bedrijfswaarde stimuleren.
- bedrijfsanalisten en zakelijke gebruikers: bedrijfsanalisten bieden belanghebbenden en zakelijke teams met bruikbare gegevens. Ze interpreteren vaak gegevens en maken rapporten of andere documentatie voor beheer met behulp van standaard BI-hulpprogramma's. Ze zijn doorgaans het eerste contactpunt voor niet-technische zakelijke gebruikers en operationele collega's voor snelle analysevragen. Dashboards en zakelijke apps die op het Databricks-platform worden geleverd, kunnen rechtstreeks door zakelijke gebruikers worden gebruikt.
- Zakelijke partners zijn belangrijke belanghebbenden in een steeds meer genetwerkte bedrijfswereld. Ze worden gedefinieerd als een bedrijf of personen met wie een bedrijf een formele relatie heeft om een gemeenschappelijk doel te bereiken en kunnen leveranciers, leveranciers, distributeurs en andere partners van derden omvatten. Het delen van gegevens is een belangrijk aspect van zakelijke partnerschappen, omdat het de overdracht en uitwisseling van gegevens mogelijk maakt om samenwerking en besluitvorming op basis van gegevens te verbeteren.
Domeinen van het platformframework
Het platform bestaat uit meerdere domeinen:
Storage: In de cloud worden gegevens voornamelijk opgeslagen in schaalbare, efficiënte en flexibele objectopslag in de cloud providers.
Governance: Mogelijkheden voor gegevensbeheer, zoals toegangsbeheer, controle, metagegevensbeheer, tracering van herkomst en bewaking voor alle gegevens en AI-assets.
AI-engine: De AI-engine biedt generatieve AI-mogelijkheden voor het hele platform.
Opnemen en transformeren: de mogelijkheden voor ETL-workloads.
Geavanceerde analyses, ML en AI: alle mogelijkheden rond machine learning, AI, Generatieve AI en streaming-analyses.
Datawarehouse: het domein dat DWH- en BI-use cases ondersteunt.
Automatisering: werkstroombeheer voor gegevensverwerking, machine learning, analysepijplijnen, waaronder ONDERSTEUNING voor CI/CD en MLOps.
ETL & DS-hulpprogramma's: de front-endhulpprogramma's die data engineers, gegevenswetenschappers en ML-engineers voornamelijk gebruiken voor werk.
BI-hulpprogramma's: de front-endhulpprogramma's die BI-analisten voornamelijk gebruiken voor werk.
Samenwerking: Mogelijkheden voor het delen van gegevens tussen twee of meer partijen.
Het bereik van het Databricks-platform
Het Databricks Data Intelligence Platform en de bijbehorende onderdelen kunnen op de volgende manier worden toegewezen aan het framework:
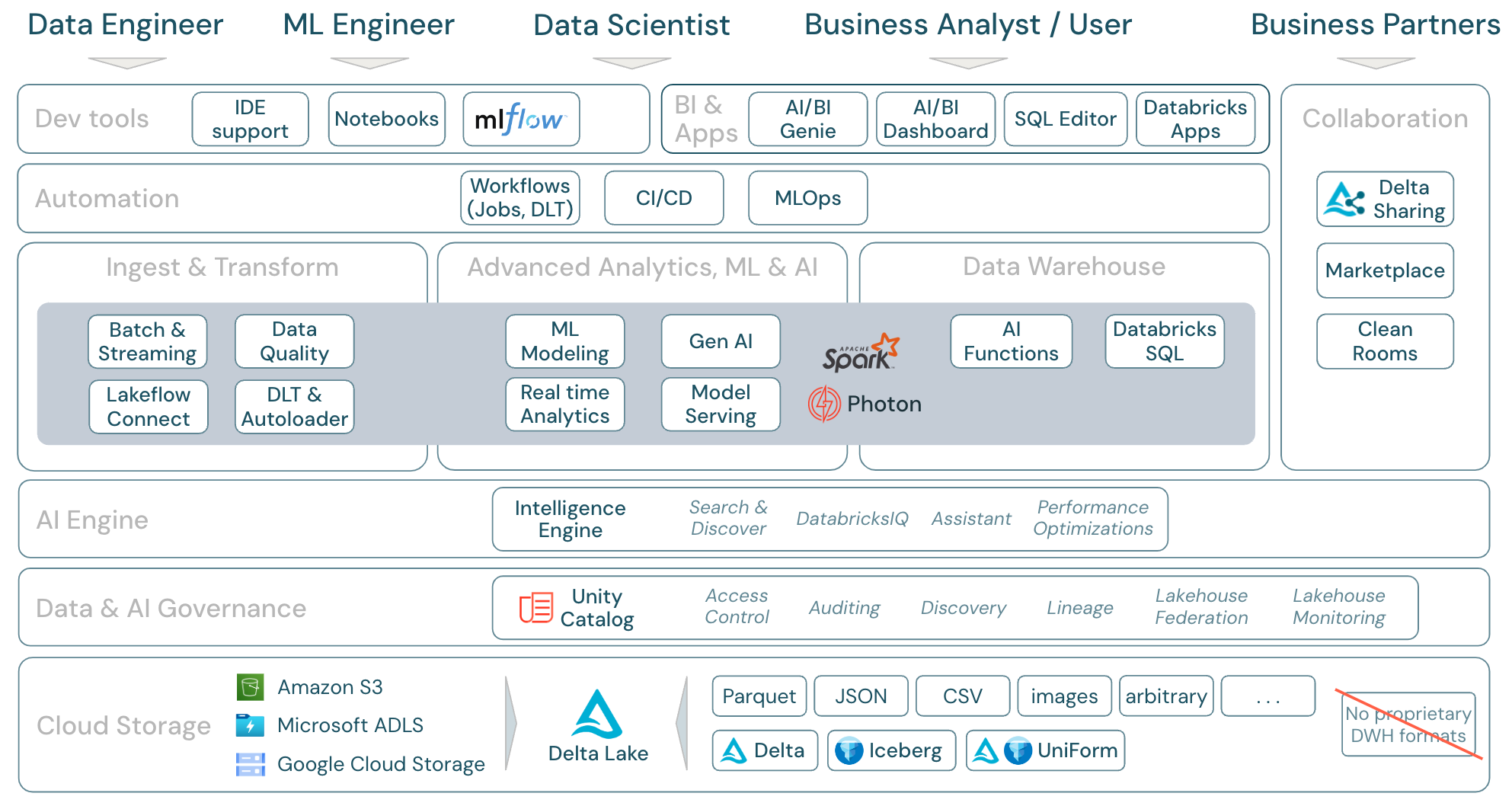
Download: Bereik van de Lakehouse - Databricks-onderdelen
Gegevensworkloads in Azure Databricks
Het belangrijkste is dat het Databricks Data Intelligence Platform alle relevante workloads voor het gegevensdomein in één platform omvat, met Apache Spark/Photon als de engine:
Opnemen en transformeren
Databricks biedt verschillende manieren om gegevens op te nemen:
- Databricks LakeFlow Connect biedt ingebouwde connectors voor opname van bedrijfstoepassingen en -databases. De resulterende opnamepijplijn wordt beheerd door Unity Catalog en wordt mogelijk gemaakt door serverloze compute en Delta Live Tables.
- Automatisch laadprogramma incrementeel en automatisch bestanden verwerkt die in de cloudopslag binnenkomen in geplande of doorlopende taken, zonder dat u statusinformatie hoeft te beheren. Zodra de gegevens zijn opgenomen, moeten onbewerkte gegevens worden getransformeerd, zodat deze klaar zijn voor BI en ML/AI. Databricks biedt krachtige ETL-mogelijkheden voor data engineers, gegevenswetenschappers en analisten.
Delta Live Tables (DLT) maakt het schrijven van ETL-taken op een declaratieve manier mogelijk, waardoor het hele implementatieproces wordt vereenvoudigd. Gegevenskwaliteit kan worden verbeterd door gegevens verwachtingen te definiëren.
Geavanceerde analyses, ML en AI
Het platform bevat Databricks Mosaic AI, een set van volledig geïntegreerde tools voor machine learning en AI voor klassieke machine en deep learning, evenals generatieve AI en grote taalmodellen (LLMs). Het omvat de hele werkstroom van het voorbereiden van gegevens tot het bouwen van machine learning - en deep learning-modellen , tot Mozaïek AI Model Serving.
Spark Structured Streaming en DLT maken realtime analyses mogelijk.
Datawarehouse
Het Databricks Data Intelligence Platform heeft ook een volledige datawarehouseoplossing met Databricks SQL-, centraal beheerd door Unity-Catalog met gedetailleerd toegangsbeheer.
AI-functies zijn ingebouwde SQL-functies waarmee u AI rechtstreeks vanuit SQL kunt toepassen op uw gegevens. De integratie van AI in analysewerkstromen biedt toegang tot informatie die voorheen niet toegankelijk was voor analisten en stelt hen in staat om beter geïnformeerde beslissingen te nemen, risico's te beheren en een concurrentievoordeel te behouden via gegevensgestuurde innovatie en efficiëntie.
Overzicht van Azure Databricks-functiegebieden
Dit is een toewijzing van de Databricks Data Intelligence Platform-functies aan de andere lagen van het framework, van onder naar boven:
Cloudopslag
Alle gegevens voor lakehouse worden opgeslagen in de objectopslag van de cloudprovider. Databricks ondersteunt drie cloud-providers: AWS, Azure en GCP. Bestanden in verschillende gestructureerde en semi-gestructureerde indelingen (bijvoorbeeld Parquet, CSV, JSON en Avro), evenals ongestructureerde indelingen (zoals afbeeldingen en documenten), worden opgenomen en getransformeerd met batch- of streamingprocessen.
Delta Lake is de aanbevolen gegevensindeling voor lakehouse (bestandstransacties, betrouwbaarheid, consistentie, updates, enzovoort) en is volledig open source om vergrendeling te voorkomen. En Delta Universal Format (UniForm) maakt het mogelijk om Delta tables te lezen met Iceberglezers.
Er worden geen eigen gegevensindelingen gebruikt in het Databricks Data Intelligence Platform.
gegevens- en AI-beheer
Naast de opslaglaag biedt Unity Catalog een breed scala aan mogelijkheden voor gegevens- en AI-governance, waaronder metagegevensbeheer in de metastore, toegangsbeheer, controle, gegevensdetectieen gegevensherkomst.
Lakehouse-bewaking biedt standaard metrische gegevens over kwaliteit voor gegevens en AI-assets en automatisch gegenereerde dashboards om deze metrische gegevens te visualiseren.
Externe SQL-bronnen kunnen worden geïntegreerd in het lakehouse en Unity Catalog via de lakehouse-federatie .
AI-engine
Het Data Intelligence Platform is gebaseerd op de lakehouse-architectuur en is verbeterd door de data intelligence-engine DatabricksIQ. DatabricksIQ combineert generatieve AI met de eenwordingsvoordelen van de lakehouse-architectuur om inzicht te hebben in de unieke semantiek van uw gegevens. Intelligent Search en de Databricks Assistant zijn voorbeelden van AI-services die het werken met het platform voor elke gebruiker vereenvoudigen.
Orchestration
Met Databricks-taken kunt u diverse workloads uitvoeren voor de volledige gegevens- en AI-levenscyclus in elke cloud. Hiermee kunt u taken orkestreren evenals Delta Live Tables voor SQL, Spark, notebooks, DBT, ML-modellen en meer.
ETL & DS-hulpprogramma's
In de verbruikslaag werken gegevenstechnici en ML-technici doorgaans met het platform met behulp van IDE's. Gegevenswetenschappers geven vaak de voorkeur aan notebooks en gebruiken de ML & AI-runtimes, en het machine learning-werkstroomsysteem MLflow om experimenten bij te houden en de levenscyclus van het model te beheren.
BI-hulpprogramma's
Bedrijfsanalisten gebruiken doorgaans hun favoriete BI-hulpprogramma voor toegang tot het Databricks-datawarehouse. Databricks SQL kan worden opgevraagd door verschillende analyse- en BI-hulpprogramma's, BI en visualisatie bekijken
Daarnaast biedt het platform standaard hulpprogramma's voor query's en analyses:
- AI/BI-dashboards om gegevensvisualisaties te slepen en neer te zetten en inzichten te delen.
- Domeinexperts, zoals gegevensanalisten, configureren AI/BI Genie-ruimten met gegevenssets, voorbeeldquery's en tekstrichtlijnen om Genie te helpen bij het vertalen van zakelijke vragen naar analytische query's. Na set, kunnen zakelijke gebruikers vragen stellen en met generate visualisaties inzicht krijgen in operationele gegevens.
- Databricks Apps kunnen ontwikkelaars beveiligde gegevens en AI-toepassingen maken op het Databricks-platform en deze apps delen met gebruikers.
- SQL-editor voor SQL-analisten voor het analyseren van gegevens.
Samenwerking
Delta Sharing is een open protocol dat door Databricks is ontwikkeld voor het veilig delen van gegevens met andere organisaties, ongeacht de computerplatforms die ze gebruiken.
Databricks Marketplace is een open forum voor het uitwisselen van gegevensproducten. Het maakt gebruik van Delta Sharing om gegevens providers van de hulpmiddelen te voorzien waarmee gegevensproducten veilig kunnen worden gedeeld, en gegevensgebruikers in staat te stellen hun toegang tot de gegevens- en gegevensservices die ze nodig hebben, te verkennen en uit te breiden.
Clean Rooms Gebruikmaken van Delta Sharing en serverloze berekeningen om een veilige en privacybeveiligde omgeving te bieden where meerdere partijen kunnen samenwerken aan gevoelige bedrijfsgegevens zonder directe toegang tot elkaars gegevens.