Richtlijnen voor het lakehouse
Leidende principes zijn regels op niveau nul die uw architectuur definiëren en beïnvloeden. Als u een Data Lakehouse wilt bouwen waarmee uw bedrijf nu en in de toekomst kan slagen, is consensus tussen belanghebbenden in uw organisatie essentieel.
Gegevens cureren en vertrouwde gegevens als producten aanbieden
Het cureren van gegevens is essentieel voor het maken van een hoogwaardige data lake voor BI en ML/AI. Gegevens behandelen zoals een product met een duidelijke definitie, schema en levenscyclus. Zorg voor semantische consistentie en dat de gegevenskwaliteit verbetert van laag naar laag, zodat zakelijke gebruikers de gegevens volledig kunnen vertrouwen.
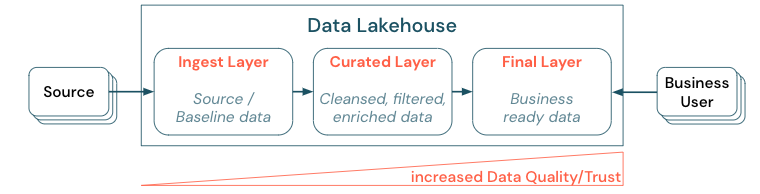
Gegevens cureren door een gelaagde (of multihop)-architectuur tot stand te brengen, is een essentiële best practice voor het Lakehouse, omdat gegevensteams de gegevens kunnen structureren op basis van kwaliteitsniveaus en rollen en verantwoordelijkheden per laag kunnen definiëren. Een algemene gelaagde benadering is:
- opnamelaag: brongegevens worden opgenomen in het lakehouse in de eerste laag en moeten daar worden bewaard. Wanneer alle downstreamgegevens zijn gegenereerd op basis van de invoeringslaag, is het mogelijk om, indien nodig, de volgende lagen opnieuw van de invoeringslaag te herbouwen.
- Gecureerde laag: het doel van de tweede laag is om opgeschoonde, verfijnde, gefilterde en geaggregeerde gegevens te bewaren. Het doel van deze laag is om een goede, betrouwbare basis te bieden voor analyses en rapporten voor alle rollen en functies.
- laatste laag: de derde laag wordt gemaakt rond bedrijfs- of projectbehoeften; het biedt een andere weergave als gegevensproducten voor andere bedrijfseenheden of projecten, het voorbereiden van gegevens rond beveiligingsbehoeften (bijvoorbeeld geanonimiseerde gegevens) of optimaliseren voor prestaties (met vooraf geaggregeerde weergaven). De gegevensproducten in deze laag worden gezien als de waarheid voor het bedrijf.
Pijplijnen in alle lagen moeten ervoor zorgen dat aan beperkingen van gegevenskwaliteit wordt voldaan, wat betekent dat gegevens altijd nauwkeurig, volledig, toegankelijk en consistent zijn, zelfs tijdens gelijktijdige lees- en schrijfbewerkingen. De validatie van nieuwe gegevens vindt plaats op het moment van gegevensinvoer in de gecureerde laag en de volgende ETL-stappen werken om de kwaliteit van deze gegevens te verbeteren. De gegevenskwaliteit moet worden verbeterd naarmate de gegevens zich door de lagen ontwikkelen en als zodanig het vertrouwen in de gegevens vervolgens toeneemt vanuit het oogpunt van het bedrijf.
Gegevenssilo's elimineren en gegevensverplaatsing minimaliseren
Maak geen kopieën van een gegevensset met bedrijfsprocessen die afhankelijk zijn van deze verschillende kopieën. Kopieën kunnen gegevenssilo's worden die niet meer gesynchroniseerd zijn, wat leidt tot een lagere kwaliteit van uw Data Lake en ten slotte tot verouderde of onjuiste inzichten. Voor het delen van gegevens met externe partners gebruikt u ook een mechanisme voor het delen van ondernemingen waarmee directe toegang tot de gegevens op een veilige manier mogelijk is.
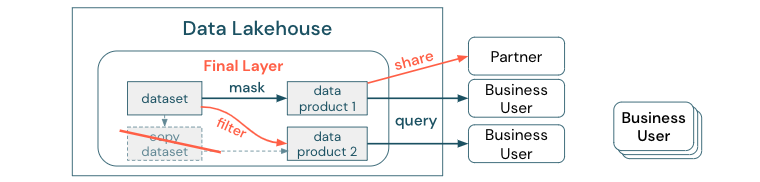
Om het onderscheid duidelijk te maken tussen een gegevenskopie versus een gegevenssilo: een zelfstandige of wegwerpkopie van gegevens is zelf niet schadelijk. Het is soms noodzakelijk om flexibiliteit, experimenten en innovatie te stimuleren. Als deze kopieën echter operationeel worden met downstreamproducten voor zakelijke gegevens die hiervan afhankelijk zijn, worden ze gegevenssilo's.
Om gegevenssilo's te voorkomen, proberen gegevensteams meestal een mechanisme of gegevenspijplijn te bouwen om alle kopieën gesynchroniseerd te houden met het origineel. Omdat dit waarschijnlijk niet consistent gebeurt, neemt de gegevenskwaliteit uiteindelijk af. Dit kan ook leiden tot hogere kosten en een aanzienlijk verlies van gebruikersvertrouwen. Aan de andere kant vereisen verschillende zakelijke use cases het delen van gegevens met partners of leveranciers.
Een belangrijk aspect is het veilig en betrouwbaar delen van de nieuwste versie van de gegevensset. Kopieën van de gegevensset zijn vaak niet voldoende, omdat ze snel niet meer synchroon lopen. In plaats daarvan moeten gegevens worden gedeeld via hulpprogramma's voor het delen van zakelijke gegevens.
Het creëren van waarde democratiseren via selfservice
Een uitstekende data lake kan niet voldoende waarde bieden als gebruikers geen eenvoudige toegang hebben tot het platform of de gegevens voor hun BI- en ML/AI-taken. Verlaag de obstakels voor toegang tot gegevens en platforms voor alle bedrijfseenheden. Overweeg lean data management processen en bieden selfservicetoegang voor het platform en de onderliggende gegevens.
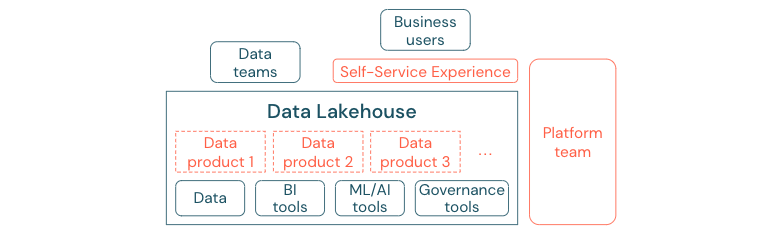
Bedrijven die succesvol zijn overgestapt naar een gegevensgestuurde cultuur zullen bloeien. Dit betekent dat elke bedrijfseenheid zijn beslissingen afleidt van analytische modellen of van het analyseren van eigen of centraal verstrekte gegevens. Voor consumenten moeten gegevens gemakkelijk kunnen worden gedetecteerd en veilig toegankelijk zijn.
Een goed concept voor gegevensproducenten is 'gegevens als product': de gegevens worden aangeboden en onderhouden door één bedrijfseenheid of zakenpartner, zoals een product en gebruikt door andere partijen met de juiste machtigingscontrole. In plaats van te vertrouwen op een centraal team en mogelijk trage aanvraagprocessen, moeten deze gegevensproducten worden gemaakt, aangeboden, gedetecteerd en gebruikt in een selfservice-ervaring.
Het zijn echter niet alleen de gegevens die belangrijk zijn. Voor de democratisering van gegevens zijn de juiste hulpmiddelen vereist om iedereen in staat te stellen de gegevens te produceren of te gebruiken en te begrijpen. Hiervoor hebt u het Data Lakehouse nodig om een modern data- en AI-platform te zijn dat de infrastructuur en hulpprogramma's biedt voor het bouwen van gegevensproducten zonder dat u de moeite hoeft te dupliceren om een andere hulpprogrammastack in te stellen.
Een organisatiebrede strategie voor gegevens en AI-governance aannemen
Gegevens zijn een essentieel activum van elke organisatie, maar u kunt iedereen geen toegang geven tot alle gegevens. Gegevenstoegang moet actief worden beheerd. Toegangsbeheer, controle en tracering van herkomst zijn essentieel voor het juiste en veilige gebruik van gegevens.
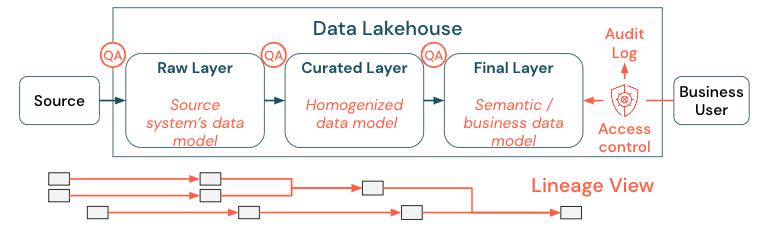
Gegevensbeheer is een breed onderwerp. Het meerhuis betreft de volgende dimensies:
gegevenskwaliteit
De belangrijkste vereiste voor juiste en zinvolle rapporten, analyseresultaten en modellen is gegevens van hoge kwaliteit. Kwaliteitscontrole (QA) moet bestaan rond alle pijplijnstappen. Voorbeelden van hoe u dit implementeert, zijn het hebben van gegevenscontracten, het vergaderen van SLA's, het stabiel houden van schema's en het ontwikkelen ervan op een gecontroleerde manier.
gegevenscatalogus
Een ander belangrijk aspect is gegevensdetectie: gebruikers van alle bedrijfsgebieden, met name in een selfservicemodel, moeten relevante gegevens eenvoudig kunnen detecteren. Daarom heeft een Lakehouse een gegevenscatalogus nodig die alle zakelijke relevante gegevens omvat. De belangrijkste doelen van een gegevenscatalogus zijn als volgt:
- Zorg ervoor dat hetzelfde bedrijfsconcept uniform wordt aangeroepen en gedeclareerd in het hele bedrijf. U kunt het beschouwen als een semantisch model in de gecureerde en de laatste laag.
- Houd de gegevensherkomst nauwkeurig bij zodat gebruikers kunnen uitleggen hoe deze gegevens zijn aangekomen bij hun huidige vorm en formulier.
- Behoud metagegevens van hoge kwaliteit, wat net zo belangrijk is als de gegevens zelf voor het juiste gebruik van de gegevens.
toegangsbeheer
Naarmate er waarde wordt gecreëerd uit de gegevens in het lakehouse en dit binnen alle bedrijfsgebieden plaatsvindt, moet het lakehouse worden gebouwd met beveiliging van het grootste belang. Bedrijven hebben mogelijk een meer open data access-beleid of volgen strikt het principe van minimale bevoegdheden. Onafhankelijk hiervan moeten besturingselementen voor gegevenstoegang in elke laag aanwezig zijn. Het is belangrijk om vanaf het begin nauwkeurige machtigingsschema's te implementeren (toegangsbeheer op kolom- en rijniveau, op rollen gebaseerd of op kenmerken gebaseerd toegangsbeheer). Bedrijven kunnen beginnen met minder strikte regels. Maar naarmate het Lakehouse-platform groeit, moeten alle mechanismen en processen voor een geavanceerdere beveiligingsregeling al aanwezig zijn. Bovendien moet alle toegang tot de gegevens in de lakehouse worden beheerd door auditlogboeken vanaf het begin.
Open interfaces en open indelingen aanmoedigen
Open interfaces en gegevensindelingen zijn van cruciaal belang voor interoperabiliteit tussen lakehouse en andere hulpprogramma's. Het vereenvoudigt de integratie met bestaande systemen en opent ook een ecosysteem van partners die hun hulpprogramma's hebben geïntegreerd met het platform.
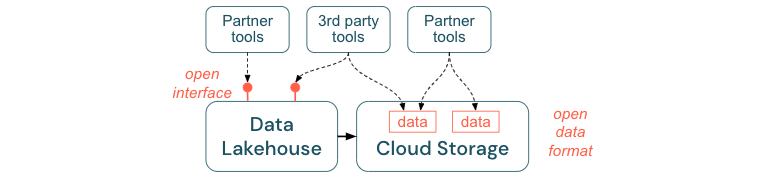
Open interfaces zijn essentieel voor het interoperabiliteit inschakelen en voorkomen van afhankelijkheid van één leverancier. Traditioneel bouwden leveranciers eigen technologieën en gesloten interfaces die beperkte ondernemingen op de manier waarop ze gegevens kunnen opslaan, verwerken en delen.
Voortbouwend op open interfaces kunt u bouwen voor de toekomst:
- Het verhoogt de levensduur en de draagbaarheid van de gegevens, zodat u deze kunt gebruiken met meer toepassingen en voor meer gebruiksvoorbeelden.
- Het opent een ecosysteem van partners die snel gebruik kunnen maken van de open interfaces om hun hulpprogramma's te integreren in het Lakehouse-platform.
Ten slotte, door te standaardiseren op open indelingen voor gegevens, zullen de totale kosten aanzienlijk lager zijn; men heeft rechtstreeks toegang tot de gegevens in de cloudopslag zonder dat u deze hoeft door te sturen via een eigen platform dat hoge uitgaande en rekenkosten kan kosten met zich meebrengen.
Bouwen om te schalen en optimaliseren voor prestaties en kosten
Gegevens blijven onvermijdelijk groeien en complexer worden. Om uw organisatie voor te bereiden op toekomstige behoeften, moet uw lakehouse schaalbaar zijn. U moet bijvoorbeeld eenvoudig nieuwe resources op aanvraag kunnen toevoegen. De kosten moeten worden beperkt tot het werkelijke verbruik.
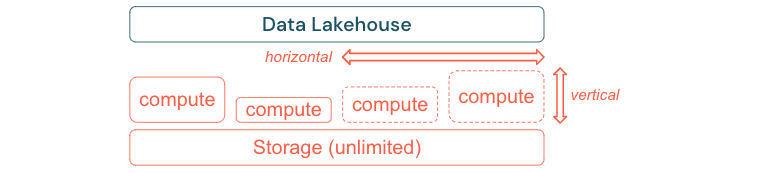
Standaard ETL-processen, bedrijfsrapporten en dashboards hebben vaak een voorspelbare resourcebehoefte vanuit het perspectief van geheugen en berekening. Nieuwe projecten, seizoenstaken of moderne benaderingen zoals modeltraining (verloop, prognose, onderhoud) genereren echter pieken in de resourcebehoefte. Om een bedrijf in staat te stellen al deze workloads uit te voeren, is een schaalbaar platform voor geheugen en berekening nodig. Nieuwe resources moeten eenvoudig op aanvraag worden toegevoegd en alleen het werkelijke verbruik moet kosten genereren. Zodra de piek voorbij is, kunnen resources weer worden vrijgemaakt en worden de kosten dienovereenkomstig verlaagd. Dit wordt vaak horizontale schaalaanpassing genoemd (minder of meer knooppunten) en verticaal schalen (grotere of kleinere knooppunten).
Door te schalen kunnen bedrijven ook de prestaties van query's verbeteren door knooppunten te selecteren met meer resources of clusters met meer knooppunten. Maar in plaats van grote machines en clusters permanent te leveren, kunnen ze alleen op aanvraag worden ingericht voor de tijd die nodig is om de algehele prestaties tot kostenverhouding te optimaliseren. Een ander aspect van optimalisatie is opslag versus rekenresources. Omdat er geen duidelijke relatie is tussen het volume van de gegevens en workloads die deze gegevens gebruiken (bijvoorbeeld alleen het gebruik van delen van de gegevens of het uitvoeren van intensieve berekeningen op kleine gegevens), is het een goede gewoonte om een infrastructuurplatform te gebruiken waarmee opslag- en rekenresources worden losgekoppeld.