Wat is de meldingsmodus voor het automatisch laden van bestanden?
In de bestandsmeldingsmodus stelt Automatisch laden automatisch een meldingsservice en wachtrijservice in die zich abonneert op bestandsevenementen uit de invoermap. U kunt bestandsmeldingen gebruiken om automatisch laden te schalen om miljoenen bestanden per uur op te nemen. In vergelijking met de modus mapvermelding is de modus voor bestandsmeldingen beter presterend en schaalbaar voor grote invoermappen of een groot aantal bestanden, maar hiervoor zijn extra cloudmachtigingen vereist.
U kunt op elk gewenst moment schakelen tussen bestandsmeldingen en adreslijstvermeldingen en nog steeds exactly-once gegevensverwerkingsgaranties onderhouden.
Notitie
De bestandsmeldingsmodus wordt niet ondersteund voor Azure Premium-opslagaccounts omdat Premium-accounts geen ondersteuning bieden voor wachtrijopslag.
Waarschuwing
Het wijzigen van het bronpad voor automatisch laden wordt niet ondersteund voor de modus voor bestandsmeldingen. Als de modus voor bestandsmeldingen wordt gebruikt en het pad wordt gewijzigd, kunt u mogelijk geen bestanden opnemen die al aanwezig zijn in de nieuwe map op het moment van de update van de map.
Cloudresources die worden gebruikt in de meldingsmodus voor het automatisch laden van bestanden
Belangrijk
U hebt verhoogde machtigingen nodig om de cloudinfrastructuur automatisch te configureren voor de modus voor bestandsmeldingen. Neem contact op met uw cloudbeheerder of werkruimtebeheerder. Zien:
Automatisch laden kan bestandsmeldingen automatisch voor u instellen wanneer u de optie cloudFiles.useNotifications instelt op true en de benodigde machtigingen voor het maken van cloudresources opgeeft. Bovendien moet u mogelijk aanvullende opties opgeven om Auto Loader-autorisatie te verlenen om deze resources te maken.
De volgende tabel bevat een overzicht van de resources die door Auto Loader worden gemaakt.
| Cloudopslag | Abonnementsservice | Wachtrijservice | Voorvoegsel* | Grens** |
|---|---|---|---|---|
| Amazon S3 | AWS SNS | AWS SQS | databricks-auto-opname | 100 per S3-bucket |
| ADLS Gen2 | Azure Event Grid | Azure Queue Storage | databricks | 500 per opslagaccount |
| GCS | Google Pub/Sub | Google Pub/Sub | databricks-auto-opname | 100 per GCS-bucket |
| Azure Blob-opslag | Azure Event Grid | Azure Queue Storage | databricks | 500 per opslagaccount |
- Automatisch laadprogramma noemt de resources met dit voorvoegsel.
** Hoeveel gelijktijdige bestandsmeldingspijplijnen kunnen worden gestart
Als u meer dan het beperkte aantal bestandsmeldingspijplijnen voor een bepaald opslagaccount wilt uitvoeren, kunt u het volgende doen:
- Gebruik een service zoals AWS Lambda, Azure Functions of Google Cloud Functions om meldingen van een enkele wachtrij, die naar een hele container of bucket luistert, te verspreiden naar mapspecifieke wachtrijen.
Gebeurtenissen voor bestandsmeldingen
Amazon S3 biedt een ObjectCreated gebeurtenis wanneer een bestand wordt geüpload naar een S3-bucket, ongeacht of het is geüpload door een put- of multi-part upload.
ADLS Gen2 biedt verschillende gebeurtenismeldingen voor bestanden die worden weergegeven in uw Gen2-container.
- Auto Loader luistert naar de gebeurtenis voor het
FlushWithCloseverwerken van een bestand. - Automatische laadprogramma's ondersteunen de actie voor het
RenameFiledetecteren van bestanden.RenameFileacties vereisen een API-aanvraag voor het opslagsysteem om de grootte van het hernoemde bestand op te halen. - Automatisch laden streams gemaakt met Databricks Runtime 9.0 en na ondersteuning van de actie voor het
RenameDirectorydetecteren van bestanden.RenameDirectoryacties vereisen API-aanvragen voor het opslagsysteem om de inhoud van de hernoemde map weer te geven.
Google Cloud Storage biedt een OBJECT_FINALIZE gebeurtenis wanneer een bestand wordt geüpload, waaronder overschrijven en bestandskopieën. Mislukte uploads genereren deze gebeurtenis niet.
Notitie
Cloudproviders garanderen niet 100% levering van alle bestandsgebeurtenissen onder zeer zeldzame omstandigheden en bieden geen strikte SLA's voor de latentie van de bestandsgebeurtenissen. Databricks raadt u aan om reguliere backfills te activeren met autolader met behulp van de cloudFiles.backfillInterval optie om te garanderen dat alle bestanden in een bepaalde SLA worden gedetecteerd als volledigheid van gegevens een vereiste is. Het activeren van reguliere backfills veroorzaakt geen duplicaten.
Vereiste machtigingen voor het configureren van bestandsmeldingen voor ADLS Gen2 en Azure Blob Storage
U moet leesmachtigingen hebben voor de invoermap. Zie Azure Blob Storage.
Als u de modus voor bestandsmeldingen wilt gebruiken, moet u verificatiereferenties opgeven voor het instellen en openen van de gebeurtenismeldingsservices.
U kunt verifiëren met behulp van een van de volgende methoden:
- Databricks-servicereferentie (aanbevolen): maak een servicereferentie met behulp van een beheerde identiteit en de Databricks-toegangsconnector.
- Service-principal: Maak een Microsoft Entra ID-app (voorheen Azure Active Directory) en service-principal in de vorm van client-id en clientgeheim.
Nadat u verificatiereferenties hebt verkregen, wijst u de benodigde machtigingen toe aan de Databricks-toegangsconnector (voor servicereferenties) of de Microsoft Entra ID-app (voor een service-principal).
Ingebouwde Azure-rollen gebruiken
Wijs de toegangsconnector de volgende rollen toe aan het opslagaccount waarin het invoerpad zich bevindt:
- Inzender: Deze rol is bedoeld voor het instellen van resources in uw opslagaccount, zoals wachtrijen en gebeurtenisabonnementen.
- Inzender voor opslagwachtrijgegevens: deze rol is bedoeld voor het uitvoeren van wachtrijbewerkingen, zoals het ophalen en verwijderen van berichten uit de wachtrijen. Deze rol is alleen vereist wanneer u een service-principal zonder verbindingsreeks opgeeft.
Wijs aan deze toegangsconnector de volgende rol toe in de bijbehorende resourcegroep.
- EventGrid EventSubscription-inzender: deze rol is voor het uitvoeren van Azure Event Grid-abonnementsbewerkingen (Event Grid), zoals het maken of vermelden van gebeurtenisabonnementen.
Zie voor meer informatie Azure-rollen toewijzen met behulp van de Azure-portal.
Een aangepaste rol gebruiken
Als u zich bezig houdt met de overmatige machtigingen die zijn vereist voor de voorgaande rollen, kunt u een aangepaste rol maken met ten minste de volgende machtigingen, die hieronder worden vermeld in de JSON-indeling van De Azure-rol:
"permissions": [ { "actions": [ "Microsoft.EventGrid/eventSubscriptions/write", "Microsoft.EventGrid/eventSubscriptions/read", "Microsoft.EventGrid/eventSubscriptions/delete", "Microsoft.EventGrid/locations/eventSubscriptions/read", "Microsoft.Storage/storageAccounts/read", "Microsoft.Storage/storageAccounts/write", "Microsoft.Storage/storageAccounts/queueServices/read", "Microsoft.Storage/storageAccounts/queueServices/write", "Microsoft.Storage/storageAccounts/queueServices/queues/write", "Microsoft.Storage/storageAccounts/queueServices/queues/read", "Microsoft.Storage/storageAccounts/queueServices/queues/delete" ], "notActions": [], "dataActions": [ "Microsoft.Storage/storageAccounts/queueServices/queues/messages/delete", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/read", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/write", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/process/action" ], "notDataActions": [] } ]Vervolgens kunt u deze aangepaste rol toewijzen aan uw toegangsconnector.
Zie voor meer informatie Azure-rollen toewijzen met behulp van de Azure-portal.
instellingen voor 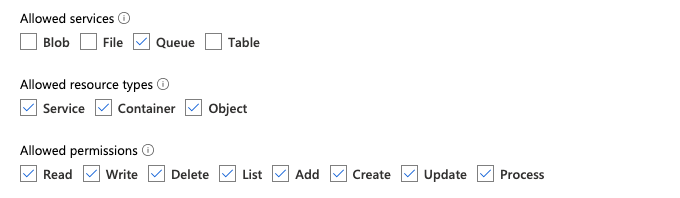
Vereiste machtigingen voor het configureren van bestandsmeldingen voor Amazon S3
U moet leesmachtigingen hebben voor de invoermap. Zie S3-verbindingsgegevens voor meer informatie.
Als u de modus voor bestandsmeldingen wilt gebruiken, voegt u het volgende JSON-beleidsdocument toe aan uw IAM-gebruiker of -rol. Deze IAM-rol is vereist om een servicereferentie aan te maken waarmee Auto Loader zich kan authentiseren.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderSetup",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"s3:PutBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:SetTopicAttributes",
"sns:CreateTopic",
"sns:TagResource",
"sns:Publish",
"sns:Subscribe",
"sqs:CreateQueue",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:SetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
},
{
"Sid": "DatabricksAutoLoaderList",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "*"
},
{
"Sid": "DatabricksAutoLoaderTeardown",
"Effect": "Allow",
"Action": [
"sns:Unsubscribe",
"sns:DeleteTopic",
"sqs:DeleteQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
}
]
}
waar:
-
<bucket-name>: de naam van de S3-bucket waarin uw stream bestanden leest, bijvoorbeeldauto-logs. U kunt bijvoorbeeld*als jokerteken gebruikendatabricks-*-logs. Als u de bijbehorende S3-bucket voor uw DBFS-pad wilt achterhalen, kunt u alle DBFS-koppelpunten in een notebook vertonen door%fs mountsuit te voeren. -
<region>: de AWS-regio waar de S3-bucket zich bevindt, bijvoorbeeldus-west-2. Als u de regio niet wilt opgeven, gebruikt*u . -
<account-number>: het AWS-accountnummer dat eigenaar is van de S3-bucket, bijvoorbeeld123456789012. Als u het accountnummer niet wilt opgeven, gebruikt u*.
De tekenreeks databricks-auto-ingest-* in de SPECIFICATIE SQS en SNS ARN is het naamvoorvoegsel dat de cloudFiles bron gebruikt bij het maken van SQS- en SNS-services. Omdat Azure Databricks de meldingsservices instelt in de eerste uitvoering van de stream, kunt u een beleid met beperkte machtigingen gebruiken na de eerste uitvoering (bijvoorbeeld de stream stoppen en vervolgens opnieuw opstarten).
Notitie
Het voorgaande beleid heeft alleen betrekking op de machtigingen die nodig zijn voor het instellen van bestandsmeldingsservices, namelijk S3 bucketmeldingen, SNS- en SQS-services en gaat ervan uit dat u al leestoegang hebt tot de S3-bucket. Als u S3 alleen-lezenmachtigingen wilt toevoegen, voegt u het volgende toe aan de Action lijst in de DatabricksAutoLoaderSetup-instructie in het JSON-document:
s3:ListBuckets3:GetObject
Beperkte machtigingen na de eerste installatie
De hierboven beschreven machtigingen voor het instellen van resources zijn alleen vereist tijdens de eerste uitvoering van de stream. Na de eerste uitvoering kunt u overschakelen naar het volgende IAM-beleid met beperkte machtigingen.
Belangrijk
Met de beperkte machtigingen kunt u geen nieuwe streamingquery's starten of resources opnieuw maken in geval van fouten (de SQS-wachtrij is bijvoorbeeld per ongeluk verwijderd); U kunt ook de API voor cloudresourcebeheer niet gebruiken om resources weer te geven of te verwijderen.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderUse",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:TagResource",
"sns:Publish",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:<queue-name>",
"arn:aws:sns:<region>:<account-number>:<topic-name>",
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucket-name>/*"
]
},
{
"Sid": "DatabricksAutoLoaderListTopics",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "arn:aws:sns:<region>:<account-number>:*"
}
]
}
Vereiste machtigingen voor het configureren van bestandsmeldingen voor GCS
U moet beschikken over en list machtigingen hebben get voor uw GCS-bucket en voor alle objecten. Zie de Google-documentatie over IAM-machtigingen voor meer informatie.
Als u de modus voor bestandsmeldingen wilt gebruiken, moet u machtigingen toevoegen voor het GCS-serviceaccount en het serviceaccount dat wordt gebruikt voor toegang tot de Google Cloud Pub/Sub-resources.
Voeg de Pub/Sub Publisher rol toe aan het GCS-serviceaccount. Hierdoor kan het account meldingen van gebeurtenissen van uw GCS-buckets publiceren naar Google Cloud Pub/Sub.
Wat betreft het serviceaccount dat wordt gebruikt voor de Google Cloud Pub/Sub-resources, moet u de volgende machtigingen toevoegen. Dit serviceaccount wordt automatisch aangemaakt wanneer u een Databricks--servicereferentie aanmaakt.
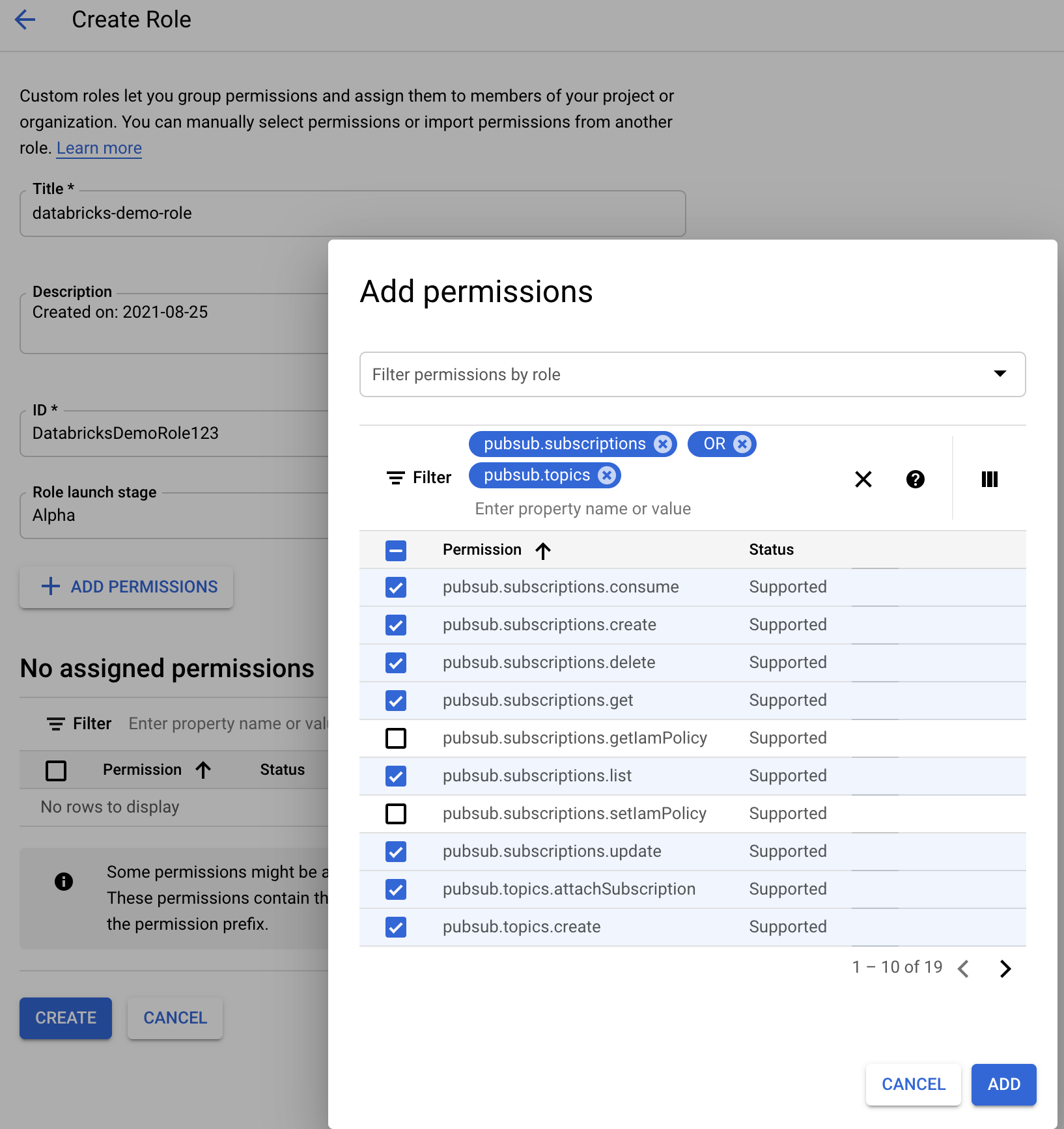
pubsub.subscriptions.consume
pubsub.subscriptions.create
pubsub.subscriptions.delete
pubsub.subscriptions.get
pubsub.subscriptions.list
pubsub.subscriptions.update
pubsub.topics.attachSubscription
pubsub.topics.create
pubsub.topics.delete
pubsub.topics.get
pubsub.topics.list
pubsub.topics.update
Hiervoor kunt u een aangepaste IAM-rol maken met deze machtigingen of vooraf bestaande GCP-rollen toewijzen om deze machtigingen te dekken.
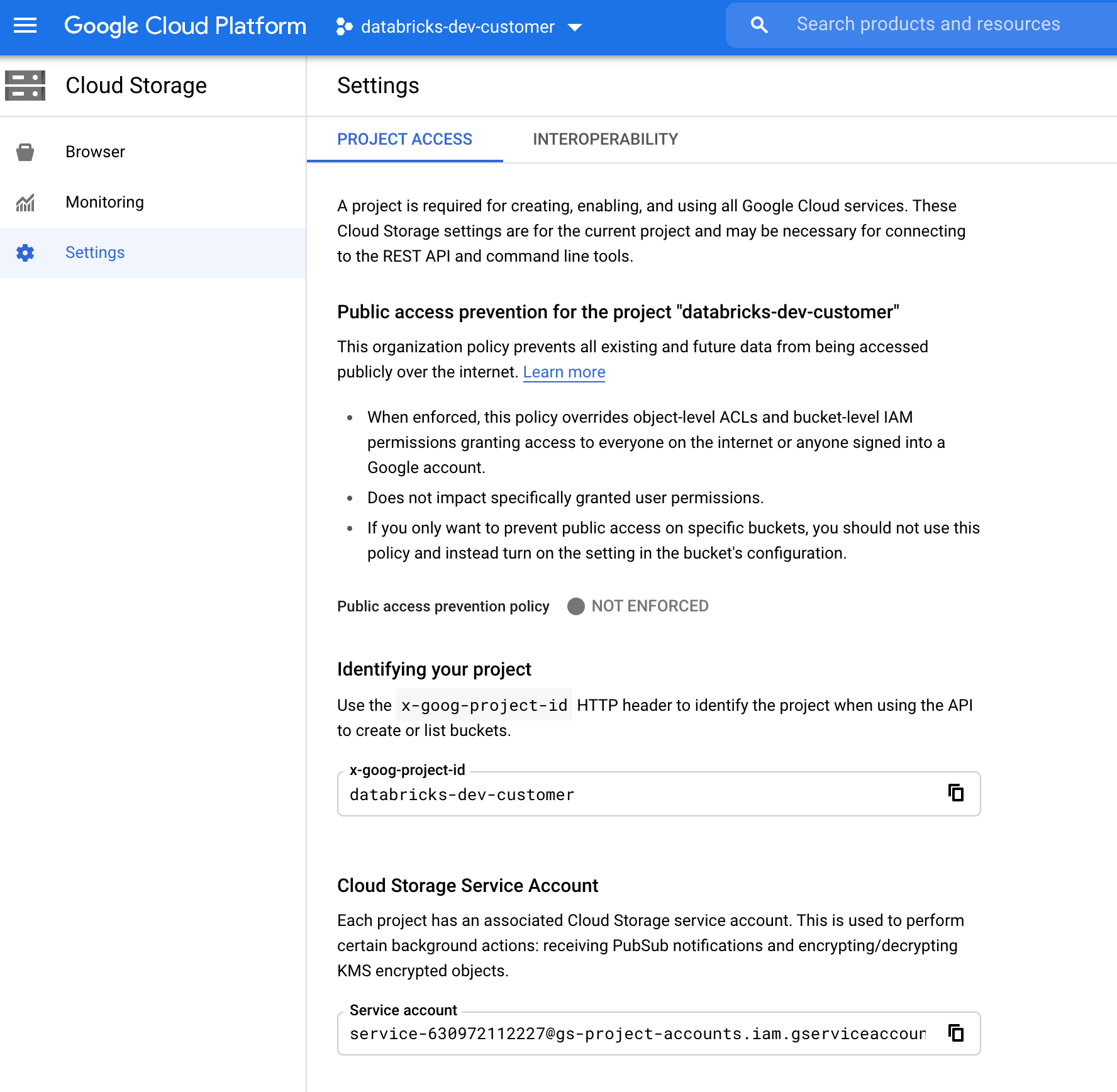
Het GCS-serviceaccount zoeken
Navigeer in de Google Cloud Console voor het bijbehorende project naar Cloud Storage > Settings.
De sectie Cloud Storage-serviceaccount bevat het e-mailadres van het GCS-serviceaccount.
Een aangepaste Google Cloud IAM-rol maken voor de modus Voor bestandsmeldingen
Ga in de Google Cloud-console voor het bijbehorende project naar IAM & Admin > Roles. Maak vervolgens een rol bovenaan of werk een bestaande rol bij. Klik op Add Permissionshet scherm voor het maken of bewerken van rollen. Er wordt een menu weergegeven waarin u de gewenste machtigingen aan de rol kunt toevoegen.
Bestandsmeldingsbronnen handmatig configureren of beheren
Bevoegde gebruikers kunnen bronnen voor bestandsmeldingen handmatig configureren of beheren.
- Stel de bestandsmeldingsservices handmatig in via de cloudprovider en geef handmatig de wachtrij-id op. Zie opties voor bestandsmeldingen voor meer informatie.
- Gebruik Scala-API's om de meldingen en wachtrijservices te maken of te beheren, zoals wordt weergegeven in het volgende voorbeeld:
Notitie
U moet over de juiste machtigingen beschikken om de cloudinfrastructuur te configureren of te wijzigen. Raadpleeg de documentatie over machtigingen voor Azure, S3 of GCS.
Python
# Databricks notebook source
# MAGIC %md ## Python bindings for CloudFiles Resource Managers for all 3 clouds
# COMMAND ----------
#####################################
## Creating a ResourceManager in AWS
#####################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.create()
# Using AWS access key and secret key
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("cloudFiles.awsAccessKey", <aws-access-key>) \
.option("cloudFiles.awsSecretKey", <aws-secret-key>) \
.option("cloudFiles.roleArn", <role-arn>) \
.option("cloudFiles.roleExternalId", <role-external-id>) \
.option("cloudFiles.roleSessionName", <role-session-name>) \
.option("cloudFiles.stsEndpoint", <sts-endpoint>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in Azure
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
# Using an Azure service principal
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.connectionString", <connection-string>) \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("cloudFiles.tenantId", <tenant-id>) \
.option("cloudFiles.clientId", <service-principal-client-id>) \
.option("cloudFiles.clientSecret", <service-principal-client-secret>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in GCP
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Using a Google service account
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("cloudFiles.client", <client-id>) \
.option("cloudFiles.clientEmail", <client-email>) \
.option("cloudFiles.privateKey", <private-key>) \
.option("cloudFiles.privateKeyId", <private-key-id>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
# List notification services created by <AL>
from pyspark.sql import DataFrame
df = DataFrame(manager.listNotificationServices(), spark)
# Tear down the notification services created for a specific stream ID.
# Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
Scala
/////////////////////////////////////
// Creating a ResourceManager in AWS
/////////////////////////////////////
import com.databricks.sql.CloudFilesAWSResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>) // optional, will use the region of the EC2 instances by default
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using AWS access key and secret key
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>)
.option("cloudFiles.awsAccessKey", <aws-access-key>)
.option("cloudFiles.awsSecretKey", <aws-secret-key>)
.option("cloudFiles.roleArn", <role-arn>)
.option("cloudFiles.roleExternalId", <role-external-id>)
.option("cloudFiles.roleSessionName", <role-session-name>)
.option("cloudFiles.stsEndpoint", <sts-endpoint>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in Azure
///////////////////////////////////////
import com.databricks.sql.CloudFilesAzureResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using an Azure service principal
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.connectionString", <connection-string>)
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("cloudFiles.tenantId", <tenant-id>)
.option("cloudFiles.clientId", <service-principal-client-id>)
.option("cloudFiles.clientSecret", <service-principal-client-secret>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in GCP
///////////////////////////////////////
import com.databricks.sql.CloudFilesGCPResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
/**
* Using a Google service account
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("cloudFiles.client", <client-id>)
.option("cloudFiles.clientEmail", <client-email>)
.option("cloudFiles.privateKey", <private-key>)
.option("cloudFiles.privateKeyId", <private-key-id>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
// Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
// List notification services created by <AL>
val df = manager.listNotificationServices()
// Tear down the notification services created for a specific stream ID.
// Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
Gebruik setUpNotificationServices(<resource-suffix>) dit diagram om een wachtrij en een abonnement met de naam <prefix>-<resource-suffix> te maken (het voorvoegsel is afhankelijk van het opslagsysteem dat wordt samengevat in cloudresources die worden gebruikt in de meldingsmodus voor het automatisch laden van bestanden. Als er een bestaande resource met dezelfde naam is, gebruikt Azure Databricks de bestaande resource opnieuw in plaats van een nieuwe resource te maken. Deze functie retourneert een wachtrij-id die u kunt doorgeven aan de cloudFiles bron met behulp van de id in opties voor bestandsmeldingen. Hierdoor kan de cloudFiles brongebruiker minder machtigingen hebben dan de gebruiker die de resources maakt.
Geef de "path" optie alleen op newManager als u belt setUpNotificationServices; dit is niet nodig voor listNotificationServices of tearDownNotificationServices. Dit is hetzelfde path dat u gebruikt bij het uitvoeren van een streamingquery.
De volgende matrix geeft aan welke API-methoden worden ondersteund waarin Databricks Runtime voor elk type opslag wordt ondersteund:
| Cloudopslag | API instellen | Lijst-API | Api voor uitsplitsen |
|---|---|---|---|
| Amazon S3 | Alle versies | Alle versies | Alle versies |
| ADLS Gen2 | Alle versies | Alle versies | Alle versies |
| GCS | Databricks Runtime 9.1 en hoger | Databricks Runtime 9.1 en hoger | Databricks Runtime 9.1 en hoger |
| Azure Blob-opslag | Alle versies | Alle versies | Alle versies |
| ADLS Gen1 | Niet ondersteund | Niet ondersteund | Niet ondersteund |
Veelvoorkomende fouten oplossen
In deze sectie worden veelvoorkomende fouten beschreven bij het gebruik van automatisch laden met de modus voor bestandsmeldingen en hoe u deze kunt oplossen.
Kan geen Event Grid-abonnement maken
Als u het volgende foutbericht ziet wanneer u AutoLoader voor het eerst uitvoert, wordt Event Grid niet geregistreerd als resourceprovider in het Azure-abonnement.
java.lang.RuntimeException: Failed to create event grid subscription.
Ga als volgt te werk om Event Grid als resourceprovider te registreren:
- Ga in Azure Portal naar uw abonnement.
- Klik op resourceproviders onder de sectie Instellingen.
- Registreer de provider
Microsoft.EventGrid.
Autorisatie vereist voor het uitvoeren van Event Grid-abonnementsbewerkingen
Als u het volgende foutbericht ziet wanneer u AutoLoader voor het eerst uitvoert, controleert u of de rol Inzender is toegewezen aan de service-principal voor Event Grid en het opslagaccount.
403 Forbidden ... does not have authorization to perform action 'Microsoft.EventGrid/eventSubscriptions/[read|write]' over scope ...
Event Grid-client omzeilt proxy
In Databricks Runtime 15.2 en hoger gebruiken Event Grid-verbindingen in Auto Loader standaard proxy-instellingen van systeemeigenschappen. In Databricks Runtime 13.3 LTS, 14.3 LTS en van 15.0 tot 15.2 kunt u Event Grid-verbindingen handmatig configureren om een proxy te gebruiken door de Spark-configuratie-eigenschapspark.databricks.cloudFiles.eventGridClient.useSystemProperties truein te stellen. Zie Spark-configuratie-eigenschappen instellen in Azure Databricks.