Inleiding tot RAG in AI-ontwikkeling
Dit artikel is een inleiding tot retrieval-augmented generation (RAG): wat het is, hoe het werkt en belangrijke concepten.
Wat is het ophalen van augmented generation?
RAG is een techniek waarmee een groot taalmodel (LLM) verrijkte antwoorden kan genereren door de prompt van een gebruiker te vergroten met ondersteunende gegevens die zijn opgehaald uit een externe informatiebron. Door deze opgehaalde informatie op te nemen, stelt RAG de LLM in staat om nauwkeurigere antwoorden van hogere kwaliteit te genereren in vergelijking met het niet uitbreiden van de prompt met aanvullende context.
Stel dat u een vraag-en-antwoord-chatbot bouwt om werknemers te helpen vragen te beantwoorden over de eigendomsdocumenten van uw bedrijf. Een zelfstandige LLM kan vragen over de inhoud van deze documenten niet nauwkeurig beantwoorden als deze niet specifiek op deze documenten zijn getraind. De LLM kan weigeren antwoord te geven vanwege een gebrek aan informatie of, nog erger, het kan een onjuist antwoord genereren.
RAG lost dit probleem op door eerst relevante informatie op te halen uit de bedrijfsdocumenten op basis van de query van een gebruiker en vervolgens de opgehaalde informatie als aanvullende context aan de LLM op te geven. Hierdoor kan de LLM een nauwkeuriger antwoord genereren door gebruik te maken van de specifieke details in de relevante documenten. In wezen stelt RAG de LLM in staat om de opgehaalde informatie te "raadplegen" om het antwoord te formuleren.
Kernonderdelen van een RAG-toepassing
Een RAG-toepassing is een voorbeeld van een samengesteld AI-systeem: het breidt de taalmogelijkheden van het model alleen uit door deze te combineren met andere hulpprogramma's en procedures.
Wanneer een zelfstandige LLM wordt gebruikt, verzendt een gebruiker een aanvraag, zoals een vraag, naar de LLM en reageert de LLM met een antwoord op basis van de trainingsgegevens.
In de meest eenvoudige vorm worden de volgende stappen uitgevoerd in een RAG-toepassing:
- Ophalen: de aanvraag van de gebruiker wordt gebruikt om een query uit te voeren op een externe gegevensbron. Dit kan betekenen dat u query's uitvoert op een vectorarchief, een trefwoordzoekopdracht uitvoert op bepaalde tekst of een query uitvoert op een SQL-database. Het doel van de ophaalstap is het verkrijgen van ondersteunende gegevens waarmee de LLM een nuttig antwoord kan bieden.
- Augmentatie: De ondersteunende gegevens uit de ophaalstap worden gecombineerd met het verzoek van de gebruiker, vaak met behulp van een sjabloon met extra formatting en instructies voor de LLM, om een prompt te maken.
- Generatie: de resulterende prompt wordt doorgegeven aan de LLM en de LLM genereert een antwoord op de aanvraag van de gebruiker.
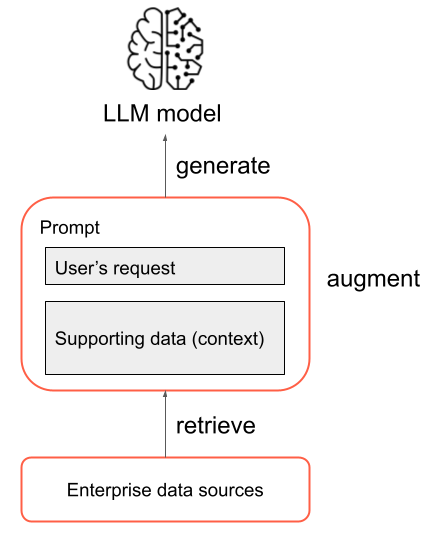
Dit is een vereenvoudigd overzicht van het RAG-proces, maar het is belangrijk om te weten dat het implementeren van een RAG-toepassing veel complexe taken omvat. Het vooraf verwerken van brongegevens om deze geschikt te maken voor gebruik in RAG, het effectief ophalen van gegevens, het opmaken van de uitgebreide prompt en het evalueren van de gegenereerde antwoorden vereisen zorgvuldige overwegingen en inspanningen. Deze onderwerpen worden uitgebreider besproken in latere secties van deze handleiding.
Waarom RAG gebruiken?
De volgende tabel bevat een overzicht van de voordelen van het gebruik van RAG versus een zelfstandige LLM:
| Alleen met een LLM | LLMs gebruiken met RAG |
|---|---|
| Geen eigen kennis: LLM's worden over het algemeen getraind op openbaar beschikbare gegevens, zodat ze geen vragen over interne of eigendomsgegevens van een bedrijf nauwkeurig kunnen beantwoorden. | RAG-toepassingen kunnen eigen gegevens bevatten: een RAG-toepassing kan eigendomsdocumenten, zoals memo's, e-mailberichten en ontwerpdocumenten, leveren aan een LLM, zodat deze vragen over deze documenten kan beantwoorden. |
| Kennis wordt niet in realtime bijgewerkt: LLM's hebben geen toegang tot informatie over gebeurtenissen die zijn opgetreden nadat ze zijn getraind. Een zelfstandige LLM kan u bijvoorbeeld vandaag niets vertellen over aandelenverplaatsingen. | RAG-toepassingen hebben toegang tot realtime gegevens: een RAG-toepassing kan de LLM voorzien van tijdige informatie uit een bijgewerkte gegevensbron, zodat deze nuttige antwoorden kan geven over gebeurtenissen die zijn verstreken na de cut-offdatum van de training. |
| Gebrek aan bronvermeldingen: LLM's kunnen geen specifieke bronnen van informatie citeren bij het reageren, waardoor de gebruiker niet kan controleren of het antwoord feitelijk juist is of een hallucinatie. | RAG kan bronnen citeren: wanneer deze wordt gebruikt als onderdeel van een RAG-toepassing, kan een LLM worden gevraagd om de bronnen te citeren. |
| Gebrek aan besturingselementen voor gegevenstoegang (ACL's): LLM's alleen kunnen niet betrouwbaar verschillende antwoorden bieden op basis van specifieke gebruikersmachtigingen. | RAG biedt toegang tot gegevensbeveiliging/ACL's: De ophaalstap kan worden ontworpen om alleen de informatie te vinden waartoe de gebruiker referenties heeft om toegang te krijgen, zodat een RAG-toepassing selectief persoonlijke of eigendomsgegevens kan ophalen. |
RAG-componenten van applicaties
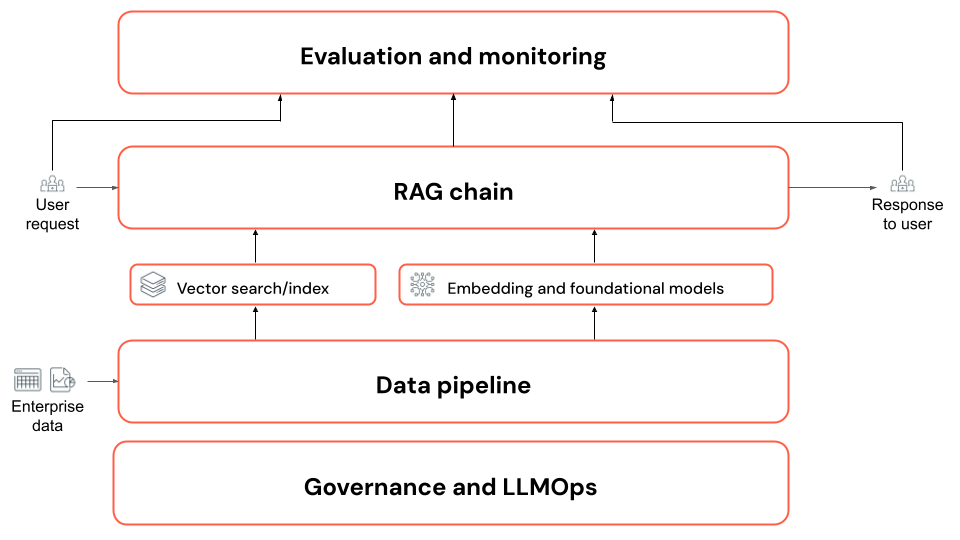
In het bijzonder:
- Gegevenspijplijn: ongestructureerde documenten, zoals verzamelingen PDF-bestanden, transformeren in een indeling die geschikt is voor het ophalen met behulp van de gegevenspijplijn van de RAG-toepassing.
-
Ophalen, Aanvulling en Generatie (RAG-keten): een reeks (of keten) van stappen die wordt aangeroepen om te:
- De vraag van de gebruiker begrijpen.
- Haal de ondersteunende gegevens op.
- Roep een LLM aan om een antwoord te genereren op basis van de vraag en ondersteunende gegevens van de gebruiker.
- Evaluatie: Beoordelen van de RAG-toepassing om de kwaliteit, kosten en latentie ervan te bepalen om ervoor te zorgen dat deze voldoet aan uw bedrijfsvereisten.
- Governance en LLMOps: de levenscyclus van elk onderdeel bijhouden en beheren, inclusief gegevensherkomst en -governance (toegangsbeheer).
De typen RAG
De RAG-architectuur kan werken met twee soorten ondersteunende gegevens:
| Gestructureerde gegevens | Niet-gestructureerd gegevens | |
|---|---|---|
| Definitie | Tabelgegevens gerangschikt in rijen en kolommen met een specifiek schema, bijvoorbeeld tabellen in een database. | Gegevens zonder een specifieke structuur of organisatie, bijvoorbeeld documenten die tekst en afbeeldingen of multimedia-inhoud bevatten, zoals audio of video's. |
| Voorbeeldgegevensbronnen |
|
|
Uw keuze aan gegevens voor RAG is afhankelijk van uw use-case. De rest van de zelfstudie is gericht op RAG voor ongestructureerde gegevens.