Prestaties evalueren: metrische gegevens die belangrijk zijn
Dit artikel bevat informatie over het meten van de prestaties van een RAG-toepassing voor de kwaliteit van het ophalen, reageren en systeemprestaties.
Ophalen, reageren en prestaties
Met een evaluatie-setkunt u de prestaties van uw RAG-toepassing meten op een aantal verschillende dimensies, waaronder:
- Kwaliteit ophalen: Metrische gegevens ophalen beoordelen hoe succesvol uw RAG-toepassing relevante ondersteunende gegevens ophaalt. Precisie en relevante overeenkomsten zijn twee belangrijke metrische gegevens voor het ophalen.
- Antwoordkwaliteit: metrische gegevens over responskwaliteit beoordelen hoe goed de RAG-toepassing reageert op de aanvraag van een gebruiker. Metrische antwoordgegevens kunnen bijvoorbeeld meten of het resulterende antwoord nauwkeurig is volgens de grondwaar, hoe goed geaard het antwoord de opgehaalde context heeft gekregen (bijvoorbeeld de LLM hallu computete?) of hoe veilig het antwoord was (met andere woorden, geen toxiciteit).
- Systeemprestaties (kosten en latentie): metrische gegevens leggen de totale kosten en prestaties van RAG-toepassingen vast. Algemene latentie en tokenverbruik zijn voorbeelden van metrische gegevens over ketenprestaties.
Het is erg belangrijk om metrische gegevens voor zowel reacties als ophalen te verzamelen. Een RAG-toepassing kan slecht reageren ondanks het ophalen van de juiste context; het kan ook goede antwoorden bieden op basis van defecte ophaalfouten. Alleen door beide onderdelen te meten, kunnen we problemen in de toepassing nauwkeurig diagnosticeren en oplossen.
Methoden voor het meten van prestaties
Er zijn twee belangrijke benaderingen voor het meten van prestaties in deze metrische gegevens:
- Deterministische meting: metrische kosten- en latentiegegevens kunnen deterministisch worden berekend op basis van de uitvoer van de toepassing. Als uw evaluatie-set een list van documenten bevat die het antwoord op een vraag bevatten, kan ook een subset van de ophaalmetriek deterministisch worden berekend.
- LLM-meting op basis van rechters: In deze benadering fungeert een afzonderlijke LLM als rechter om de kwaliteit van het ophalen en antwoorden van de RAG-toepassing te evalueren. Sommige LLM-rechters, zoals antwoord correctheid, vergelijken de door mensen gelabelde grondwaar versus de uitvoer van de app. Andere LLM-rechters, zoals geaardheid, vereisen geen door mensen gelabelde grondwaar om hun app-uitvoer te beoordelen.
Belangrijk
Om een LLM-rechter effectief te laten zijn, moet deze worden afgestemd om inzicht te krijgen in de use-case. Hiervoor is zorgvuldige aandacht vereist om te begrijpen wanneer where de rechter goed werkt en wanneer niet, en vervolgens de rechter af te stemmen om deze te verbeteren voor de gevallen waarin het fout gaat.
Mozaïek AI Agent Evaluation biedt een kant-en-klare implementatie, met behulp van gehoste LLM-rechtermodellen, voor elke metriek die op deze pagina wordt besproken. De documentatie van de agentevaluatie beschrijft de details van hoe deze metrische gegevens en rechters worden geïmplementeerd en biedt mogelijkheden om de rechters af te stemmen met uw gegevens om de nauwkeurigheid ervan te vergroten
Overzicht van metrische gegevens
Hieronder ziet u een samenvatting van de metrische gegevens die Door Databricks worden aanbevolen voor het meten van de kwaliteit, kosten en latentie van uw RAG-toepassing. Deze metrische gegevens worden geïmplementeerd in de evaluatie van de Mozaïek AI-agent.
| Dimensie | Naam van meetwaarde | Vraag | Gemeten door | Heeft de grond waarheid nodig? |
|---|---|---|---|---|
| Ophalen | chunk_relevance/precisie | Welk percentage van de opgehaalde segmenten is relevant voor de aanvraag? | LLM-rechter | Nee |
| Ophalen | document_recall | Welk percentage van de grondwaardocumenten worden weergegeven in de opgehaalde segmenten? | Deterministische | Ja |
| Ophalen | context_toereikendheid | Zijn de opgehaalde segmenten toereikend om het verwachte antwoord te produceren? | LLM Rechter | Ja |
| Respons | correctheid | Heeft de agent over het algemeen correct gereageerd generate? | LLM-rechter | Ja |
| Respons | relevance_to_query | Is het antwoord relevant voor de aanvraag? | LLM-rechter | Nee |
| Respons | geaardheid | Is het antwoord een hallucinatie of geaard in context? | LLM-rechter | Nee |
| Respons | veiligheid | Is er schadelijke inhoud in het antwoord? | LLM-rechter | Nee |
| Kosten | total_token_count, total_input_token_count, total_output_token_count | Wat is het totale aantal tokens voor LLM-generaties? | Deterministische | Nee |
| Latentie | latency_seconds | Wat is de latentie van het uitvoeren van de app? | Deterministische | Nee |
Hoe metrische gegevens ophalen werken
Metrische gegevens ophalen helpen u te begrijpen of uw retriever relevante resultaten levert. Metrische gegevens voor het ophalen zijn gebaseerd op precisie en relevante overeenkomsten.
| Naam meetwaarde | Antwoord op vraag | DETAILS |
|---|---|---|
| Precisie | Welk percentage van de opgehaalde segmenten is relevant voor de aanvraag? | Precisie is het aandeel opgehaalde documenten dat daadwerkelijk relevant is voor de aanvraag van de gebruiker. Een LLM-rechter kan worden gebruikt om de relevantie van elk opgehaald segment te beoordelen op de aanvraag van de gebruiker. |
| Intrekken | Welk percentage van de grondwaardocumenten worden weergegeven in de opgehaalde segmenten? | Relevante overeenkomsten zijn het aandeel van de gemalen waarheidsdocumenten die worden weergegeven in de opgehaalde segmenten. Dit is een meting van de volledigheid van de resultaten. |
Precisie en relevante overeenkomsten
Hieronder vindt u een korte inleiding op Precision en relevante overeenkomsten die zijn aangepast uit het uitstekende Wikipedia-artikel.
Precisieformule
Precisiemetingen "Van de segmenten die ik heb opgehaald, welk percentage van deze items is eigenlijk relevant voor de query van mijn gebruiker?" Rekenprecisie vereist niet alle relevante items kennen.
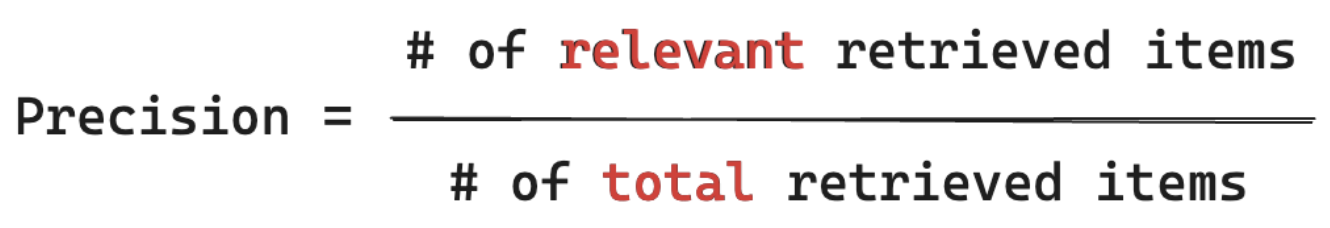
Formule intrekken
Relevante metingen 'Van ALLE documenten waarvan ik weet dat deze relevant zijn voor de query van mijn gebruiker, van welk percentage heb ik een segment opgehaald?' Voor het terughalen van computing moet uw grond-waarheid alle relevante items bevatten. Items kunnen een document of een segment van een document zijn.
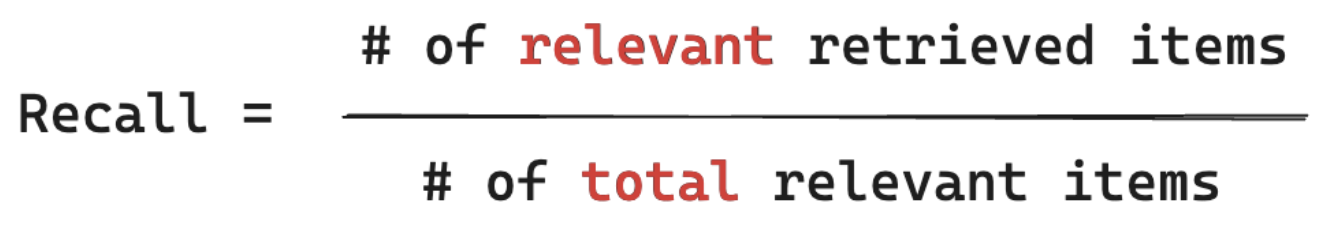
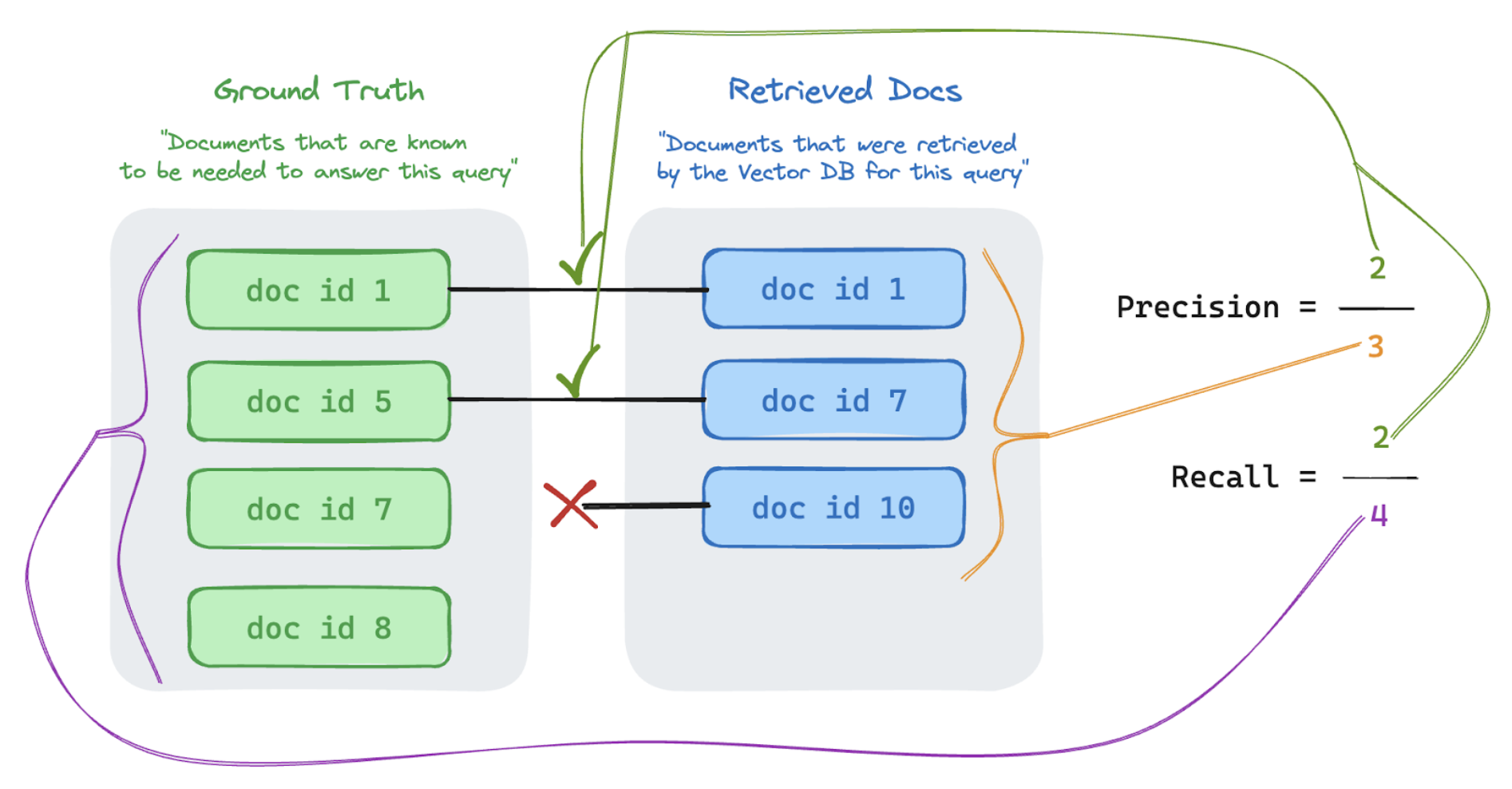
In het onderstaande voorbeeld waren twee van de drie opgehaalde resultaten relevant voor de query van de gebruiker, dus de precisie was 0,66 (2/3). De opgehaalde documenten bevatten in totaal twee van de vier relevante documenten, dus de relevante overeenkomsten waren 0,5 (2/4).