AI-agents ontwerpen in code
In dit artikel wordt beschreven hoe u een AI-agent in Python maakt met behulp van Mosaic AI Agent Framework en populaire bibliotheken voor het ontwerpen van agents, zoals LangGraph, PyFunc en OpenAI.
Eisen
Databricks raadt aan de nieuwste versie van de MLflow Python-client te installeren bij het ontwikkelen van agents.
Als u agents wilt maken en implementeren met behulp van de methode in dit artikel, moet u de volgende minimale pakketversies hebben:
-
databricks-agentsversie 0.16.0 en hoger -
mlflowversie 2.20.2 en hoger - Python 3.10 of hoger. U kunt serverloze rekenkracht of Databricks Runtime 13.3 LTS en hoger gebruiken om aan deze vereiste te voldoen.
%pip install -U -qqqq databricks-agents>=0.16.0 mlflow>=2.20.2
Databricks raadt ook aan om Databricks AI Bridge te installeren integratiepakketten bij het ontwerpen van agents. Deze integratiepakketten (zoals databricks-langchain, databricks-openai) bieden een gedeelde laag API's om te communiceren met Databricks AI-functies, zoals Databricks AI/BI Genie en Vector Search, in frameworks en SDK's voor agentcreatie.
LangChain/LangGraph
%pip install -U -qqqq databricks-langchain
OpenAI
%pip install -U -qqqq databricks-openai
Zuivere Python-agenten
%pip install -U -qqqq databricks-ai-bridge
ChatAgent gebruiken om agents te schrijven
Databricks raadt aan om de ChatAgent-interface van MLflow te gebruiken om agents op productieniveau te maken. Deze specificatie van het chatschema is ontworpen voor agentscenario's en is vergelijkbaar met, maar niet strikt compatibel met, het OpenAI-ChatCompletion schema.
ChatAgent voegt ook functionaliteit toe voor meerdere interactierondes en hulpmiddelenaanroepende agenten.
Het ontwikkelen van uw agent met behulp van ChatAgent biedt de volgende voordelen:
Geavanceerde agentmogelijkheden
- streaming-uitvoer: interactieve gebruikerservaringen inschakelen door uitvoer te streamen in kleinere segmenten.
- Uitgebreide berichtgeschiedenis voor het aanroepen van hulpprogramma's: Meerdere berichten retourneren, inclusief tussenliggende berichten voor bellen via hulpprogramma's, voor verbeterde kwaliteit en gespreksbeheer.
- Bevestigingsondersteuning bij oproep van tools
- Multiagentsysteemondersteuning
Gestroomlijnde ontwikkeling, implementatie en bewaking
- Framework-agnostische Databricks-functieintegratie: Schrijf uw agent in elk framework naar keuze en krijg directe compatibiliteit met AI Playground, Agent Evaluation en Agent Monitoring.
- Getypte ontwerpinterfaces: Agentcode schrijven met behulp van getypte Python-klassen en profiteren van automatisch aanvullen van IDE en notebook.
-
Automatische handtekeningdeductie: MLflow bepaalt automatisch
ChatAgenthandtekeningen bij het registreren van de agent, waardoor registratie en implementatie eenvoudiger worden. Zie Modelhandtekening vaststellen tijdens het loggen. - door AI Gateway verbeterde deductietabellen: AI Gateway-deductietabellen worden automatisch ingeschakeld voor geïmplementeerde agents en bieden toegang tot gedetailleerde metagegevens van aanvraaglogboeken.
Om te leren hoe je een ChatAgent maakt, zie de voorbeelden in de volgende sectie en de MLflow-documentatie - Wat is de ChatAgent-interface.
voorbeelden van ChatAgent
In de volgende notebooks zie je hoe je streaming- en niet-streaming-ChatAgents kunt creëren met behulp van de populaire bibliotheken OpenAI en LangGraph.
LangGraph-agent voor het aanroepen van hulpprogramma's
OpenAI-agent voor het aanroepen van hulpprogramma's
OpenAI-antwoorden-API-toolaanroepagent
OpenAI-agent voor alleen-chat
Voor het uitbreiden van de mogelijkheden van deze agents door tools toe te voegen, zie AI agent tools.
Voorbeeld van ChatAgent multiagentsysteem
Zie Genie gebruiken in systemen met meerdere agentsvoor meer informatie over het maken van een multiagentsysteem met behulp van Genie.
streaming-uitvoeragents maken
Streamingagents leveren antwoorden in een continue stroom kleinere, incrementele segmenten, zodat eindgebruikers agentuitvoer kunnen lezen terwijl deze wordt gegenereerd en de waargenomen latentie verminderen. Streaming-uitvoer is een handige manier om de eindgebruikerservaring voor gespreksagenten te verbeteren.
Als u een streaming-ChatAgentwilt maken, definieert u een predict_stream methode die een generator retourneert die ChatAgentChunk objecten oplevert, die elk een deel van het antwoord bevatten. Lees meer over het ideale streaminggedrag van ChatAgent in de MLflow-documenten.
In de volgende code ziet u een voorbeeld van de predict_stream-functie; zie voor volledige voorbeelden van streamingagents, ChatAgent-voorbeelden.
def predict_stream(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> Generator[ChatAgentChunk, None, None]:
# Convert messages to a format suitable for your agent
request = {"messages": self._convert_messages_to_dict(messages)}
# Stream the response from your agent
for event in self.agent.stream(request, stream_mode="updates"):
for node_data in event.values():
# Yield each chunk of the response
yield from (
ChatAgentChunk(**{"delta": msg}) for msg in node_data["messages"]
)
Schrijf implementatieklare ChatAgents voor Databricks Model Serving
Databricks implementeert ChatAgents in een gedistribueerde omgeving op Databricks Model Serving, wat betekent dat tijdens een gesprek met meerdere beurten dezelfde serving-replica mogelijk niet alle aanvragen verwerkt. Houd rekening met de volgende implicaties voor het beheren van de agentstatus:
Vermijd lokale caching: bij het implementeren van een
ChatAgent, moet er niet van worden uitgegaan dat dezelfde replica alle aanvragen in een gesprek met meerdere wendingen zal afhandelen. De interne status reconstrueren met behulp van een woordenlijstChatAgentRequestschema voor elke beurt.Thread-veilige status: Ontwerp de agentstatus zodat deze thread-veilig is en conflicten in omgevingen met meerdere threads worden voorkomen.
de status initialiseren in de
predictfunctie: initialiseer de status telkens wanneer depredictfunctie wordt aangeroepen, niet tijdensChatAgentinitialisatie. Het opslaan van de status opChatAgentniveau kan informatie lekken tussen gesprekken en conflicten veroorzaken omdat éénChatAgentreplica aanvragen van meerdere gesprekken kan verwerken.
Aangepaste invoer en uitvoer
Voor sommige scenario's zijn mogelijk extra agentinvoer vereist, zoals client_type en session_id, of uitvoer zoals bronkoppelingen ophalen die niet moeten worden opgenomen in de chatgeschiedenis voor toekomstige interacties.
Voor deze scenario's biedt MLflow ChatAgent systeemeigen ondersteuning voor de velden custom_inputs en custom_outputs.
Waarschuwing
De agentevaluatie-app ondersteunt momenteel geen weergave van traceringen voor agents met extra invoervelden.
Zie de volgende voorbeelden voor meer informatie over het instellen van aangepaste invoer en uitvoer voor OpenAI/PyFunc- en LangGraph-agents.
OpenAI + PyFunc aangepast schema-agent-notitieboek
Aangepast schema-agentnotitieboek van LangGraph
Bied custom_inputs in de AI-programmeeromgeving en agentbeoordelingsapp
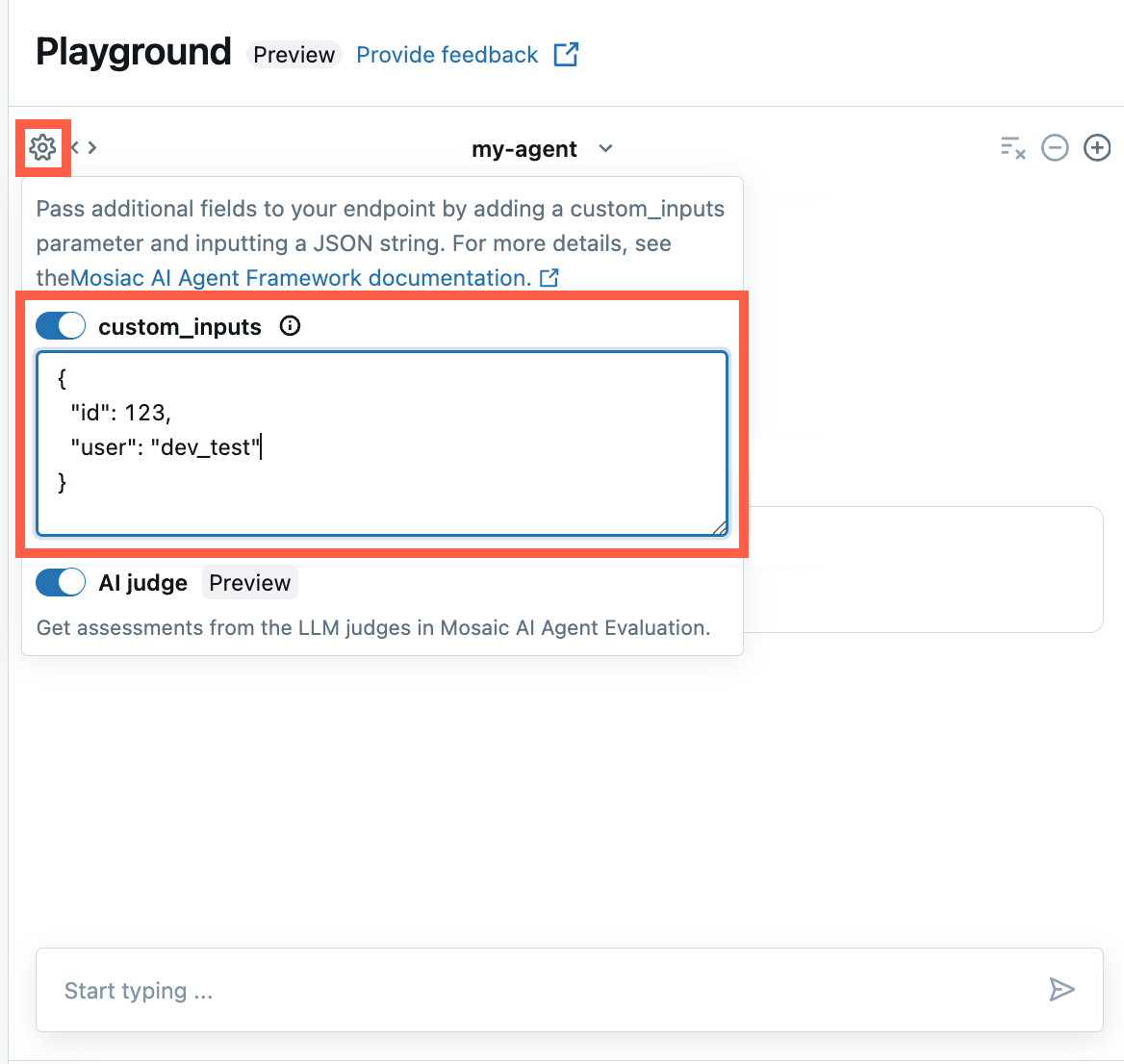
Als uw agent aanvullende invoer accepteert met behulp van het veld custom_inputs, kunt u deze invoer handmatig opgeven in zowel de AI Playground als de agent-beoordelingsapp .
In de AI Playground of de Agent Review-app selecteer je het tandwielpictogram
 .
.Schakel custom_inputs in.
Geef een JSON-object op dat overeenkomt met het gedefinieerde invoerschema van uw agent.
Aangepaste retrieverschema's opgeven
AI-agents gebruiken vaak retrievers om ongestructureerde gegevens te zoeken en op te vragen uit vectorzoekindexen. Zie bijvoorbeeld retrieverhulpmiddelen Hulpmiddelen voor ongestructureerd ophalen door AI-agenten.
Traceer deze retrievers binnen uw agent met MLflow RETRIEVER-overspanningen om Databricks-productfuncties in te schakelen, waaronder:
- Automatisch koppelingen weergeven naar opgehaalde brondocumenten in de gebruikersinterface van AI Playground
- Het automatisch uitvoeren van ophaal- en beoordelingsprocessen voor onderbouwing en relevantie bij agentenevaluatie.
Notitie
Databricks raadt het gebruik van retriever-hulpprogramma's aan die worden geleverd door Databricks AI Bridge-pakketten, zoals databricks_langchain.VectorSearchRetrieverTool en databricks_openai.VectorSearchRetrieverTool, omdat ze al voldoen aan het MLflow-retrieverschema. Zie Hulpprogramma's voor vectorzoekopdrachten lokaal ontwikkelen met AI Bridge.
Als uw agent retriever-spans bevat met een aangepast schema, roept u mlflow.models.set_retriever_schema aan wanneer u uw agent in de code definieert. Hiermee worden de uitvoerkolommen van de retriever toegewezen aan de verwachte velden van MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="chunk_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="text_column",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
)
Notitie
De doc_uri kolom is vooral belangrijk bij het evalueren van de prestaties van de retriever.
doc_uri is de belangrijkste identificatie voor documenten die door de retriever worden geretourneerd, zodat u ze kunt vergelijken met grondwaarheidsevaluatiesets. Zie Evaluatiesets.
Parametriseer agentcode voor implementatie in verschillende omgevingen
U kunt agentcode parametrizeren om dezelfde agentcode opnieuw te gebruiken in verschillende omgevingen.
Parameters zijn sleutel-waardeparen die u definieert in een Python-woordenlijst of een .yaml-bestand.
Als u de code wilt configureren, maakt u een ModelConfig met behulp van een Python-woordenlijst of een .yaml -bestand.
ModelConfig is een set sleutelwaardeparameters waarmee flexibel configuratiebeheer mogelijk is. U kunt bijvoorbeeld een woordenlijst gebruiken tijdens de ontwikkeling en deze vervolgens converteren naar een .yaml-bestand voor productie-implementatie en CI/CD.
Zie de ModelConfigvoor meer informatie over .
Hieronder ziet u een voorbeeld ModelConfig:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
In uw agentcode kunt u verwijzen naar een standaardconfiguratie (ontwikkeling) vanuit het .yaml bestand of woordenlijst:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Bij het registreren van de agent specificeert u vervolgens de model_config parameter naar log_model om een aangepaste set parameters op te geven die moeten worden gebruikt bij het laden van de geregistreerde agent. Zie MLflow-documentatie - ModelConfig.
Verspreiding van streamingfouten
Mosaic AI verspreidt eventuele fouten die zijn opgetreden tijdens het streamen met de laatste token onder code databricks_output.error. Het is aan de aanroepende client om deze fout correct te verwerken en weer te geven.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}