Aanbevelingen voor verwachtingen en geavanceerde patronen
Dit artikel bevat aanbevelingen voor het implementeren van verwachtingen op schaal en voorbeelden van geavanceerde patronen die worden ondersteund door verwachtingen. Deze patronen gebruiken meerdere gegevenssets in combinatie met verwachtingen en vereisen dat gebruikers de syntaxis en semantiek van gerealiseerde weergaven, streamingtabellen en verwachtingen begrijpen.
Zie Gegevenskwaliteit beheren met verwachtingenvoor een basisoverzicht van het gedrag en de syntaxis van verwachtingen voor pijplijnen.
draagbare en herbruikbare verwachtingen
Databricks raadt de volgende aanbevolen procedures aan bij het implementeren van verwachtingen om de draagbaarheid te verbeteren en onderhoudslasten te verminderen:
| Aanbeveling | Invloed |
|---|---|
| Sla verwachtingendefinities afzonderlijk op van pijplijnlogica. | U kunt eenvoudig verwachtingen toepassen op meerdere gegevenssets of pijplijnen. Werk verwachtingen bij, controleer en onderhoud zonder de broncode van de pijplijn te wijzigen. |
| Voeg aangepaste tags toe om groepen gerelateerde verwachtingen te maken. | Filter verwachtingen op basis van tags. |
| Pas verwachtingen consistent toe op vergelijkbare gegevenssets. | Gebruik dezelfde verwachtingen voor meerdere gegevenssets en pijplijnen om identieke logica te evalueren. |
In de volgende voorbeelden ziet u hoe u een Delta-tabel of -woordenlijst gebruikt om een centrale verwachtingsopslagplaats te maken. Aangepaste Python-functies passen vervolgens deze verwachtingen toe op gegevenssets in een voorbeeldpijplijn:
Delta-tabel
In het volgende voorbeeld wordt een tabel met de naam rules gemaakt om regels te onderhouden:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
In het volgende Python-voorbeeld worden de verwachtingen voor gegevenskwaliteit gedefinieerd op basis van de regels in de rules tabel. De get_rules() functie leest de regels uit de rules tabel en retourneert een Python-woordenlijst met regels die overeenkomen met het argument tag doorgegeven aan de functie.
In dit voorbeeld wordt de woordenlijst toegepast met behulp van @dlt.expect_all_or_drop() decorators om beperkingen voor gegevenskwaliteit af te dwingen.
Records die niet voldoen aan de regels die zijn getagd met validity, worden bijvoorbeeld verwijderd uit de raw_farmers_market tabel:
import dlt
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Pythonmodule
In het volgende voorbeeld wordt een Python-module gemaakt om regels te onderhouden. In dit voorbeeld slaat u deze code op in een bestand met de naam rules_module.py in dezelfde map als het notebook dat wordt gebruikt als broncode voor de pijplijn:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
In het volgende Python-voorbeeld worden verwachtingen voor gegevenskwaliteit gedefinieerd op basis van de regels die zijn gedefinieerd in het rules_module.py-bestand. De get_rules()-functie retourneert een Python-woordenlijst met regels die overeenkomen met het tag argument dat eraan is doorgegeven.
In dit voorbeeld wordt de woordenlijst toegepast met behulp van @dlt.expect_all_or_drop() decorators om beperkingen voor gegevenskwaliteit af te dwingen.
Records die niet voldoen aan de regels die zijn getagd met validity, worden bijvoorbeeld verwijderd uit de raw_farmers_market tabel:
import dlt
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Validatie van aantal rijen
In het volgende voorbeeld wordt de gelijkheid van het aantal rijen tussen table_a en table_b gevalideerd om te controleren of er geen gegevens verloren gaan tijdens transformaties:
validatiegrafiek voor 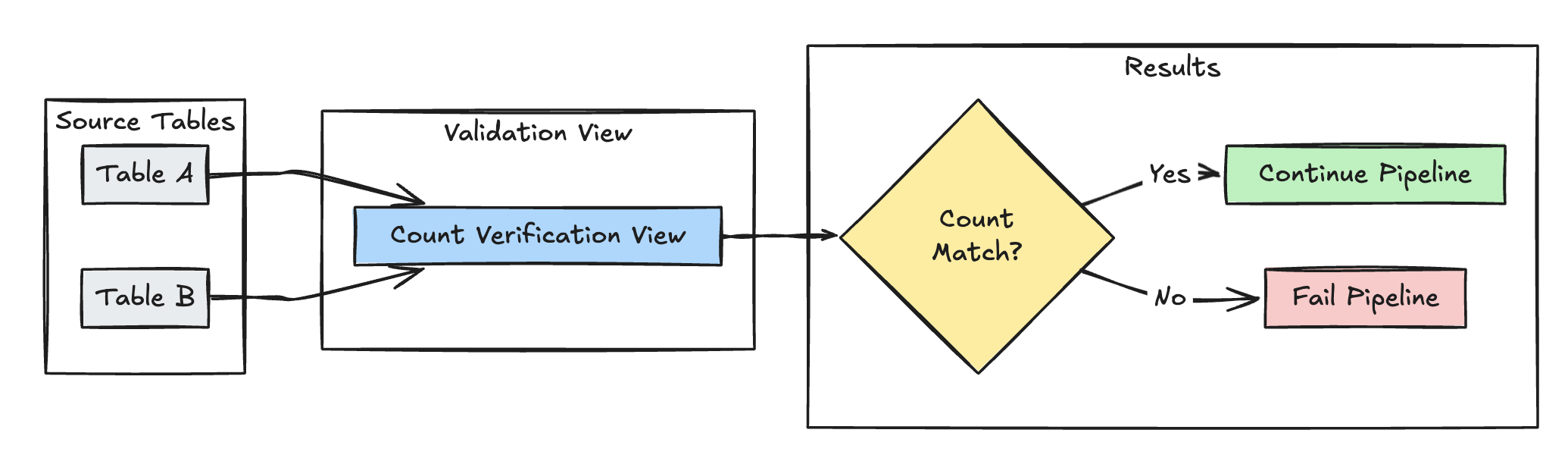
Python
@dlt.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dlt.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Detectie van ontbrekende records
In het volgende voorbeeld wordt gevalideerd of alle verwachte records aanwezig zijn in de report tabel:
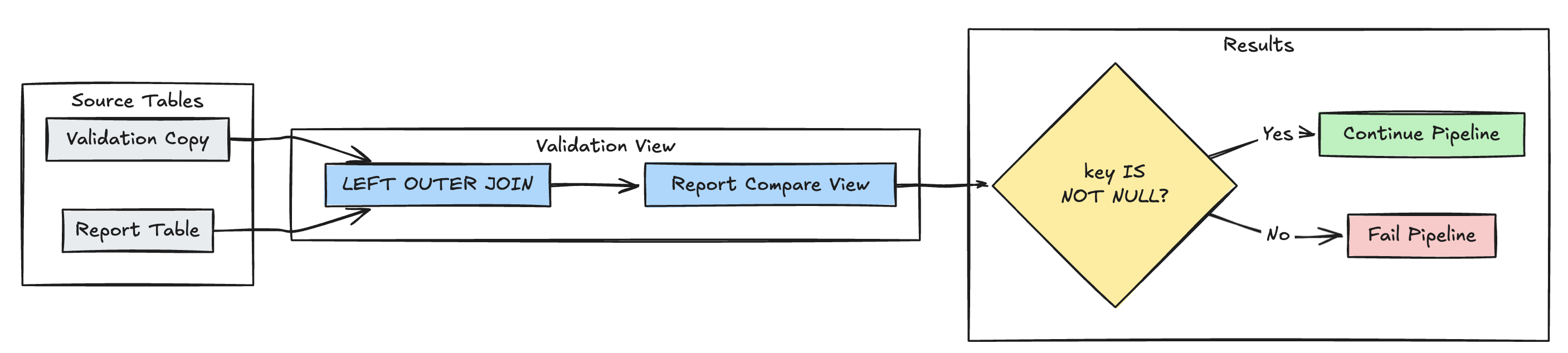
Python
@dlt.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dlt.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
dlt.read("validation_copy").alias("v")
.join(
dlt.read("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
primaire sleutel uniciteit
In het volgende voorbeeld worden primaire-sleutelbeperkingen in tabellen gevalideerd:
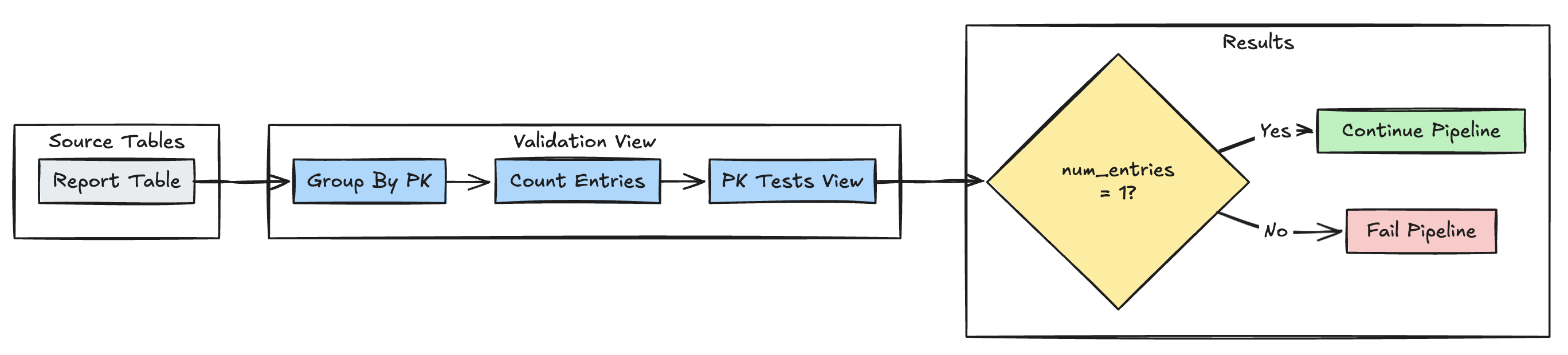
Python
@dlt.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dlt.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
dlt.read("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
patroon voor schemaontwikkeling
In het volgende voorbeeld ziet u hoe u de ontwikkeling van schema's voor extra kolommen kunt afhandelen. Gebruik dit patroon wanneer u gegevensbronnen migreert of meerdere versies van upstream-gegevens verwerkt, waardoor compatibiliteit met eerdere versies wordt gegarandeerd terwijl gegevenskwaliteit wordt afgedwongen:
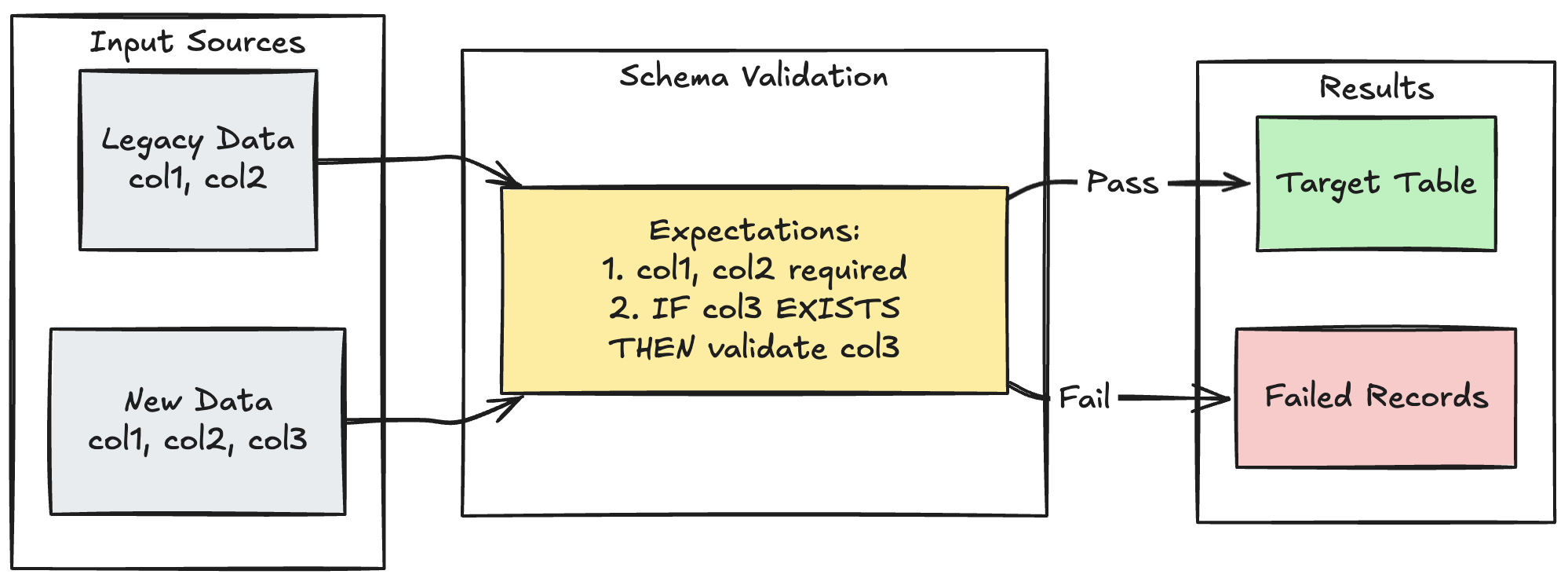
Python
@dlt.table
@dlt.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
Validatiepatroon voor -bereik
In het volgende voorbeeld ziet u hoe u nieuwe gegevenspunten kunt valideren op basis van historische statistische bereiken, zodat uitbijters en afwijkingen in uw gegevensstroom kunnen worden geïdentificeerd:
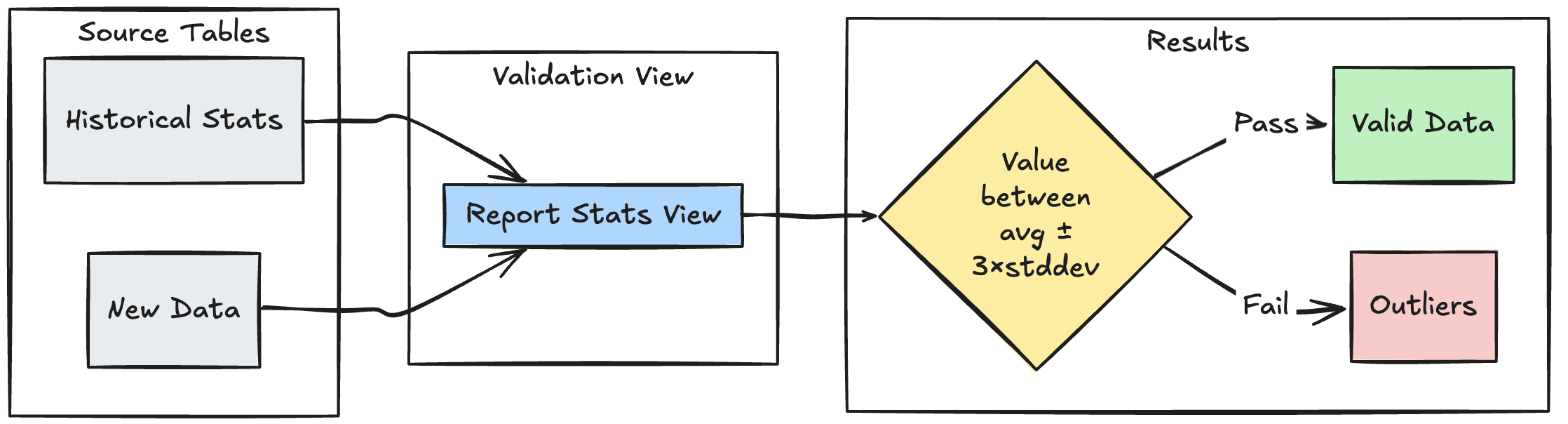
Python
@dlt.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dlt.table
@dlt.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return dlt.read("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
ongeldige records in quarantaine plaatsen
Dit patroon combineert verwachtingen met tijdelijke tabellen en weergaven om metrische gegevens van gegevenskwaliteit bij te houden tijdens pijplijnupdates en afzonderlijke verwerkingspaden in te schakelen voor geldige en ongeldige records in downstreambewerkingen.
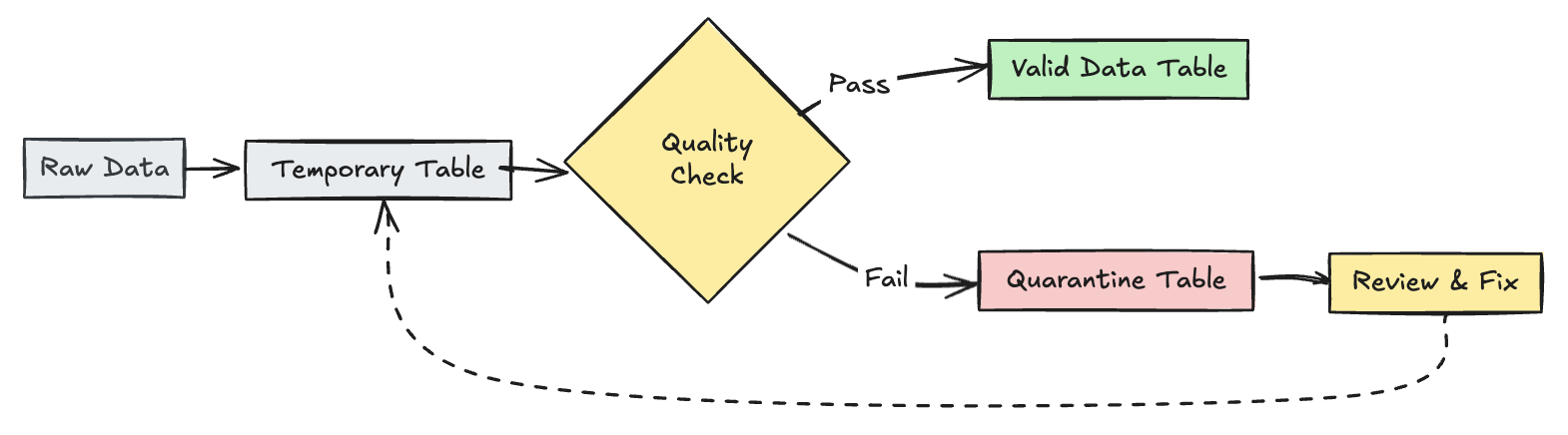
Python
import dlt
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dlt.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dlt.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dlt.expect_all(rules)
def trips_data_quarantine():
return (
dlt.readStream("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dlt.view
def valid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=false")
@dlt.view
def invalid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;