Herstel na noodgeval
Een duidelijk herstelpatroon voor noodgevallen is essentieel voor een cloudeigen gegevensanalyseplatform zoals Azure Databricks. Het is essentieel dat uw gegevensteams het Azure Databricks-platform kunnen gebruiken, zelfs in het zeldzame geval van een storing van een regionale cloudserviceprovider, ongeacht of deze wordt veroorzaakt door een regionale ramp, zoals een orkaan of aardbeving, of een andere bron.
Azure Databricks is vaak een belangrijk onderdeel van een algemeen gegevensecosysteem dat veel services bevat, waaronder upstream-services voor gegevensopname (batch/streaming), cloudeigen opslag zoals ADLS Gen2 (voor werkruimten die zijn gemaakt vóór 6 maart 2023, Azure Blob Storage), downstreamhulpprogramma's en services zoals business intelligence-apps en indelingsprogramma's. Sommige van uw gebruiksscenario's zijn mogelijk bijzonder gevoelig voor een regionale servicebrede storing.
In dit artikel worden concepten en aanbevolen procedures beschreven voor een succesvolle oplossing voor herstel na noodgevallen voor het Databricks-platform.
Garanties voor hoge beschikbaarheid binnen regio's
Hoewel de rest van dit onderwerp gericht is op de implementatie van herstel na noodgevallen tussen regio's, is het belangrijk om inzicht te hebben in de hoge beschikbaarheidsgaranties die Azure Databricks binnen de ene regio biedt. Garanties voor hoge beschikbaarheid binnen regio's hebben betrekking op de volgende onderdelen:
Beschikbaarheid van het Azure Databricks-besturingsvlak
- De meeste besturingsvlakservices worden uitgevoerd op Kubernetes-clusters en verwerken automatisch verlies van VM's in de specifieke AZ.
- Werkruimtegegevens worden opgeslagen in databases met Premium Storage, gerepliceerd in de hele regio. De opslag van de database (één server) wordt niet gerepliceerd in verschillende AZ's of regio's. Als de zonestoring van invloed is op de opslag van de database, wordt de database hersteld door een nieuw exemplaar op te halen uit de back-up.
- Opslagaccounts die worden gebruikt om DBR-installatiekopieën te verwerken, zijn ook redundant in de regio en alle regio's hebben secundaire opslagaccounts die worden gebruikt wanneer de primaire installatiekopieën niet beschikbaar zijn. Zie Azure Databricks-regio's.
- Over het algemeen moet de functionaliteit van het besturingsvlak worden hersteld binnen ongeveer 15 minuten nadat de beschikbaarheidszone is hersteld.
Beschikbaarheid van het rekenvlak
- De beschikbaarheid van de werkruimte is afhankelijk van de beschikbaarheid van het besturingsvlak (zoals hierboven beschreven).
- Gegevens in DBFS Root worden niet beïnvloed als het opslagaccount voor DBFS Root is geconfigureerd met ZRS of GZRS (standaard is GRS).
- Knooppunten voor clusters worden opgehaald uit de verschillende beschikbaarheidszones door knooppunten aan te vragen bij de Azure-rekenprovider (ervan uitgaande dat er voldoende capaciteit in de resterende zones is om aan de aanvraag te voldoen). Als een knooppunt verloren gaat, vraagt de clusterbeheerder vervangende knooppunten aan bij de Azure-rekenprovider, die deze ophaalt uit de beschikbare AZ's. De enige uitzondering is wanneer het stuurprogrammaknooppunt verloren gaat. In dit geval start de taak of clusterbeheerder deze opnieuw op.
Overzicht van herstel na noodgevallen
Herstel na noodgevallen omvat een reeks beleidsregels, hulpprogramma's en procedures die het herstel of de voortzetting van essentiële technologie-infrastructuur en -systemen mogelijk maken na een natuur- of door mensen geïnduceerde ramp. Een grote cloudservice zoals Azure bedient veel klanten en biedt ingebouwde bescherming tegen één fout. Een regio is bijvoorbeeld een groep gebouwen die zijn verbonden met verschillende energiebronnen om te garanderen dat één stroomverlies een regio niet afsluit. Fouten in de cloudregio kunnen echter optreden en de mate van onderbreking en de impact ervan op uw organisatie kunnen variëren.
Voordat u een plan voor herstel na noodgevallen implementeert, is het belangrijk om inzicht te hebben in het verschil tussen herstel na noodgevallen (DR) en hoge beschikbaarheid (HA).
Hoge beschikbaarheid is een tolerantiekenmerk van een systeem. Hoge beschikbaarheid zorgt voor een minimumniveau van operationele prestaties dat meestal wordt gedefinieerd in termen van consistente uptime of percentage van uptime. Hoge beschikbaarheid wordt geïmplementeerd (in dezelfde regio als uw primaire systeem) door deze te ontwerpen als een functie van het primaire systeem. Cloudservices zoals Azure hebben bijvoorbeeld services met hoge beschikbaarheid, zoals ADLS Gen2 (voor werkruimten die zijn gemaakt vóór 6 maart 2023, Azure Blob Storage). Hoge beschikbaarheid vereist geen aanzienlijke expliciete voorbereiding van de Azure Databricks-klant.
Een noodherstelplan vereist daarentegen beslissingen en oplossingen die voor uw specifieke organisatie werken om een grotere regionale storing voor kritieke systemen af te handelen. In dit artikel worden algemene terminologie voor herstel na noodgevallen, algemene oplossingen en enkele aanbevolen procedures voor noodherstelplannen met Azure Databricks besproken.
Terminologie
Regioterminologie
In dit artikel worden de volgende definities voor regio's gebruikt:
Primaire regio: de geografische regio waarin gebruikers typische dagelijkse interactieve en geautomatiseerde workloads voor gegevensanalyse uitvoeren.
Secundaire regio: de geografische regio waarin IT-teams gegevensanalyseworkloads tijdelijk verplaatsen tijdens een storing in de primaire regio.
Geografisch redundante opslag: Azure heeft geografisch redundante opslag in verschillende regio's voor permanente opslag met behulp van een asynchroon opslagreplicatieproces.
Belangrijk
Voor processen voor herstel na noodgevallen raadt Databricks aan dat u niet vertrouwt op geografisch redundante opslag voor duplicatie in meerdere regio's van gegevens, zoals uw ADLS Gen2 (voor werkruimten die zijn gemaakt vóór 6 maart 2023, Azure Blob Storage) die Azure Databricks voor elke werkruimte in uw Azure-abonnement maakt. Over het algemeen gebruikt u Deep Clone voor Delta-tabellen en converteert u gegevens naar Delta-indeling om indien mogelijk Deep Clone te gebruiken voor andere gegevensindelingen.
Terminologie voor implementatiestatus
In dit artikel worden de volgende definities van de implementatiestatus gebruikt:
Actieve implementatie: gebruikers kunnen verbinding maken met een actieve implementatie van een Azure Databricks-werkruimte en workloads uitvoeren. Taken worden periodiek gepland met behulp van Azure Databricks scheduler of een ander mechanisme. Gegevensstromen kunnen ook op deze implementatie worden uitgevoerd. Sommige documenten verwijzen mogelijk naar een actieve implementatie als een dynamische implementatie.
Passieve implementatie: processen worden niet uitgevoerd op een passieve implementatie. IT-teams kunnen geautomatiseerde procedures instellen voor het implementeren van code, configuratie en andere Azure Databricks-objecten voor de passieve implementatie. Een implementatie wordt alleen actief als een huidige actieve implementatie offline is. Sommige documenten verwijzen mogelijk naar een passieve implementatie als een koude implementatie.
Belangrijk
Een project kan eventueel meerdere passieve implementaties in verschillende regio's bevatten om extra opties te bieden voor het oplossen van regionale storingen.
Over het algemeen heeft een team slechts één actieve implementatie tegelijk, in wat een strategie voor actief-passief herstel na noodgevallen wordt genoemd. Er is een minder gangbare strategie voor herstel na noodgevallen genaamd actief-actief, waarbij er twee gelijktijdige actieve implementaties zijn.
Terminologie van de industrie voor herstel na noodgevallen
Er zijn twee belangrijke industrietermen die u moet begrijpen en definiëren voor uw team:
Herstelpuntdoelstelling: een RPO (Recovery Point Objective) is de maximale beoogde periode waarin gegevens (transacties) verloren kunnen gaan van een IT-service vanwege een groot incident. Uw Azure Databricks-implementatie slaat uw belangrijkste klantgegevens niet op. Dat wordt opgeslagen in afzonderlijke systemen, zoals ADLS Gen2 (voor werkruimten die zijn gemaakt vóór 6 maart 2023, Azure Blob Storage) of andere gegevensbronnen onder uw beheer. In het besturingsvlak van Azure Databricks worden bepaalde objecten gedeeltelijk of volledig opgeslagen, zoals taken en notebooks. Voor Azure Databricks wordt de RPO gedefinieerd als de maximale doelperiode waarin objecten, zoals taak- en notebookwijzigingen, verloren kunnen gaan. Daarnaast bent u verantwoordelijk voor het definiëren van de RPO voor uw eigen klantgegevens in ADLS Gen2 (voor werkruimten die zijn gemaakt vóór 6 maart 2023, Azure Blob Storage) of andere gegevensbronnen onder uw beheer.
Beoogde hersteltijd: de beoogde beoogde hersteltijd (RTO) is de beoogde duur van de tijd en een serviceniveau waarin een bedrijfsproces na een noodgeval moet worden hersteld.
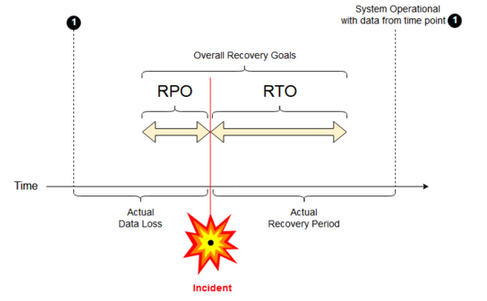
Herstel na noodgevallen en beschadiging van gegevens
Een oplossing voor herstel na noodgevallen beperkt gegevensbeschadiging niet . Beschadigde gegevens in de primaire regio worden gerepliceerd van de primaire regio naar een secundaire regio en zijn beschadigd in beide regio's. Er zijn andere manieren om dit soort fouten te beperken, bijvoorbeeld Delta-tijdreizen.
Typische herstelwerkstroom
Een scenario voor herstel na noodgevallen van Azure Databricks wordt doorgaans op de volgende manier uitgespeeld:
Er treedt een fout op in een kritieke service die u in uw primaire regio gebruikt. Dit kan een gegevensbronservice of een netwerk zijn dat van invloed is op de Azure Databricks-implementatie.
U onderzoekt de situatie met de cloudprovider.
Als u besluit dat uw bedrijf niet kan wachten tot het probleem is opgelost in de primaire regio, kunt u besluiten dat u een failover naar een secundaire regio moet uitvoeren.
Controleer of hetzelfde probleem niet van invloed is op uw secundaire regio.
Failover naar een secundaire regio.
- Stop alle activiteiten in de werkruimte. Gebruikers stoppen werkbelastingen. Gebruikers of beheerders krijgen de instructie om indien mogelijk een back-up te maken van de recente wijzigingen. Taken worden afgesloten als ze nog niet zijn mislukt vanwege de storing.
- Start de herstelprocedure in de secundaire regio. De herstelprocedure werkt routering en hernoeming van de verbindingen en het netwerkverkeer naar de secundaire regio bij.
- Declareer na het testen de secundaire regio die operationeel is. Productieworkloads kunnen nu worden hervat. Gebruikers kunnen zich aanmelden bij de nu actieve implementatie. U kunt geplande of vertraagde taken opnieuw inriggeren.
Zie Testfailover voor gedetailleerde stappen in een Azure Databricks-context.
Op een bepaald moment wordt het probleem in de primaire regio verholpen en bevestigt u dit feit.
Herstel (failback) naar uw primaire regio.
- Stop alle werkzaamheden in de secundaire regio.
- Start de herstelprocedure in de primaire regio. De herstelprocedure verwerkt routering en hernoeming van de verbinding en het netwerkverkeer terug naar de primaire regio.
- Repliceer gegevens zo nodig terug naar de primaire regio. Om de complexiteit te verminderen, minimaliseert u mogelijk hoeveel gegevens moeten worden gerepliceerd. Als sommige taken bijvoorbeeld alleen-lezen zijn wanneer ze worden uitgevoerd in de secundaire implementatie, hoeft u die gegevens mogelijk niet terug te repliceren naar uw primaire implementatie in de primaire regio. Mogelijk hebt u echter één productietaak die moet worden uitgevoerd en mogelijk gegevensreplicatie terug naar de primaire regio nodig heeft.
- Test de implementatie in de primaire regio.
- Declareer uw primaire regio operationeel en dat het uw actieve implementatie is. Productieworkloads hervatten.
Zie Herstel testen (failback) voor meer informatie over het herstellen naar uw primaire regio.
Belangrijk
Tijdens deze stappen kan er gegevensverlies optreden. Uw organisatie moet definiëren hoeveel gegevensverlies acceptabel is en wat u kunt doen om dit verlies te beperken.
Stap 1: Inzicht in uw bedrijfsbehoeften
Uw eerste stap is het definiëren en begrijpen van uw bedrijfsbehoeften. Definieer welke gegevensservices essentieel zijn en wat hun verwachte RPO en RTO zijn.
Onderzoek de echte tolerantie van elk systeem en onthoud dat failover na noodgevallen en failback kostbaar kunnen zijn en andere risico's met zich meebrengt. Andere risico's zijn mogelijk beschadiging van gegevens, gegevens die worden gedupliceerd als u naar de verkeerde opslaglocatie schrijft en gebruikers die zich aanmelden en wijzigingen aanbrengen op de verkeerde plaatsen.
Wijs alle Azure Databricks-integratiepunten toe die van invloed zijn op uw bedrijf:
- Moet uw oplossing voor herstel na noodgevallen voldoen aan interactieve processen, geautomatiseerde processen of beide?
- Welke gegevensservices gebruikt u? Sommige zijn mogelijk on-premises.
- Hoe worden invoergegevens naar de cloud verzonden?
- Wie gebruikt deze gegevens? Welke processen verbruiken het downstream?
- Zijn er integraties van derden die rekening moeten houden met wijzigingen in herstel na noodgevallen?
Bepaal de hulpprogramma's of communicatiestrategieën die ondersteuning kunnen bieden voor uw noodherstelplan:
- Welke hulpprogramma's gebruikt u om snel netwerkconfiguraties te wijzigen?
- Kunt u uw configuratie vooraf gedefinieerd en modulair maken om oplossingen voor herstel na noodgevallen op een natuurlijke en onderhoudbare manier mogelijk te maken?
- Welke communicatiehulpprogramma's en kanalen stellen interne teams en derden (integraties, downstreamgebruikers) op de hoogte van failover- en failbackwijzigingen voor noodherstel? En hoe bevestig je hun bevestiging?
- Welke hulpprogramma's of speciale ondersteuning is nodig?
- Welke services worden afgesloten totdat het herstel volledig is voltooid?
Stap 2: Kies een proces dat voldoet aan de behoeften van uw bedrijf
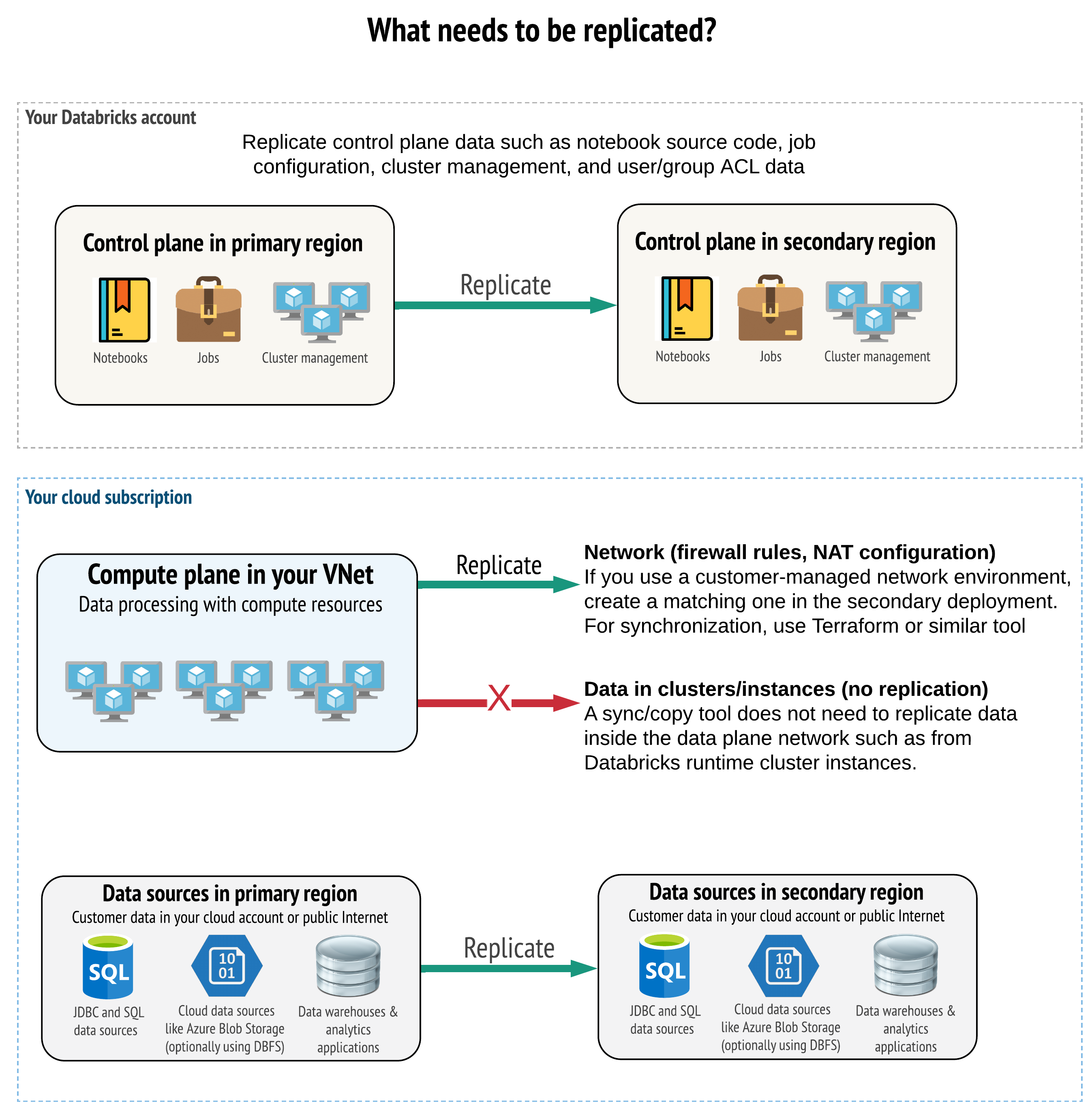
Uw oplossing moet de juiste gegevens in zowel het besturingsvlak, het rekenvlak als de gegevensbronnen repliceren. Redundante werkruimten voor herstel na noodgevallen moeten worden toegewezen aan verschillende besturingsvlakken in verschillende regio's. U moet deze gegevens periodiek gesynchroniseerd houden met behulp van een op scripts gebaseerde oplossing, ofwel een synchronisatieprogramma of een CI/CD-werkstroom. Het is niet nodig om gegevens vanuit het rekenvlaknetwerk zelf te synchroniseren, zoals van Databricks Runtime-werkrollen.
Als u de functie VNet-injectie gebruikt (niet beschikbaar voor alle abonnements- en implementatietypen), kunt u deze netwerken consistent implementeren in beide regio's met behulp van hulpprogramma's op basis van sjablonen, zoals Terraform.
Daarnaast moet u ervoor zorgen dat uw gegevensbronnen naar behoefte worden gerepliceerd in verschillende regio's.
Algemene aanbevolen procedures
Algemene aanbevolen procedures voor een succesvol plan voor herstel na noodgevallen zijn onder andere:
Begrijpen welke processen essentieel zijn voor het bedrijf en moeten worden uitgevoerd in herstel na noodgevallen.
Duidelijk bepalen welke services betrokken zijn, welke gegevens worden verwerkt, wat de gegevensstroom is en waar deze worden opgeslagen
De services en gegevens zoveel mogelijk isoleren. Maak bijvoorbeeld een speciale cloudopslagcontainer voor de gegevens voor herstel na noodgevallen of verplaats Azure Databricks-objecten die nodig zijn tijdens een noodgeval naar een afzonderlijke werkruimte.
Het is uw verantwoordelijkheid om integriteit te behouden tussen primaire en secundaire implementaties voor andere objecten die niet zijn opgeslagen in het Databricks-besturingsvlak.
Waarschuwing
Het is een best practice om geen gegevens op te slaan in de hoofdmap ADLS Gen2 (voor werkruimten die zijn gemaakt vóór 6 maart 2023, Azure Blob Storage) die wordt gebruikt voor DBFS-hoofdtoegang voor de werkruimte. Die DBFS-hoofdopslag wordt niet ondersteund voor productieklantgegevens. Databricks raadt ook aan om bibliotheken, configuratiebestanden of init-scripts op deze locatie niet op te slaan.
Voor gegevensbronnen wordt, indien mogelijk, aanbevolen om systeemeigen Azure-hulpprogramma's te gebruiken voor replicatie en redundantie om gegevens te repliceren naar de regio's voor herstel na noodgevallen.
Een strategie voor hersteloplossing kiezen
Typische oplossingen voor herstel na noodgevallen omvatten twee (of mogelijk meer) werkruimten. Er zijn verschillende strategieën die u kunt kiezen. Houd rekening met de mogelijke duur van de onderbreking (uren of misschien zelfs een dag), de inspanning om ervoor te zorgen dat de werkruimte volledig operationeel is en de inspanning om te herstellen (failback) naar de primaire regio.
Strategie voor actief-passieve oplossingen
Een actief-passieve oplossing is de meest voorkomende en de eenvoudigste oplossing, en dit type oplossing is de focus van dit artikel. Een actief-passieve oplossing synchroniseert gegevens- en objectwijzigingen van uw actieve implementatie naar uw passieve implementatie. Als u wilt, kunt u meerdere passieve implementaties in verschillende regio's hebben, maar dit artikel is gericht op de benadering voor één passieve implementatie. Tijdens een noodherstel-gebeurtenis wordt de passieve implementatie in de secundaire regio uw actieve implementatie.
Er zijn twee hoofdvarianten van deze strategie:
- Geïntegreerde (bedrijfsmatige) oplossing: Precies één set actieve en passieve implementaties die ondersteuning bieden voor de hele organisatie.
- Oplossing per afdeling of project: elke afdeling of elk projectdomein onderhoudt een afzonderlijke oplossing voor herstel na noodgevallen. Sommige organisaties willen details voor herstel na noodgevallen loskoppelen tussen afdelingen en verschillende primaire en secundaire regio's voor elk team gebruiken op basis van de unieke behoeften van elk team.
Er zijn andere varianten, zoals het gebruik van een passieve implementatie voor alleen-lezen gebruiksvoorbeelden. Als u workloads hebt die alleen-lezen zijn, bijvoorbeeld gebruikersquery's, kunnen ze op elk gewenst moment worden uitgevoerd op een passieve oplossing als ze geen gegevens of Azure Databricks-objecten zoals notebooks of taken wijzigen.
Strategie voor actief-actieve oplossingen
In een actief-actief-oplossing voert u alle gegevensprocessen in beide regio's tegelijkertijd uit. Uw operations-team moet ervoor zorgen dat een gegevensproces, zoals een taak, alleen als voltooid wordt gemarkeerd wanneer deze in beide regio's is voltooid. Objecten kunnen niet worden gewijzigd in productie en moeten een strikte CI/CD-promotie volgen van ontwikkeling/fasering naar productie.
Een actief-actief oplossing is de meest complexe strategie en omdat taken in beide regio's worden uitgevoerd, zijn er extra financiële kosten.
Net als bij de actief-passieve strategie kunt u dit implementeren als een geïntegreerde organisatieoplossing of per afdeling.
Mogelijk hebt u geen equivalente werkruimte in het secundaire systeem nodig voor alle werkruimten, afhankelijk van uw werkstroom. Een ontwikkel- of faseringswerkruimte heeft bijvoorbeeld mogelijk geen duplicaat nodig. Met een goed ontworpen ontwikkelingspijplijn kunt u deze werkruimten mogelijk eenvoudig reconstrueren als dat nodig is.
Uw hulpprogramma's kiezen
Er zijn twee belangrijkste methoden voor hulpprogramma's om gegevens zo vergelijkbaar mogelijk te houden tussen werkruimten in uw primaire en secundaire regio's:
- Synchronisatieclient die kopieert van primair naar secundair: een synchronisatieclient pusht productiegegevens en assets van de primaire regio naar de secundaire regio. Dit wordt doorgaans op geplande basis uitgevoerd.
- CI/CD-hulpprogramma's voor parallelle implementatie: voor productiecode en assets gebruikt u CI/CD-hulpprogramma's waarmee wijzigingen in productiesystemen tegelijkertijd naar beide regio's worden gepusht. Wanneer u bijvoorbeeld code en assets pusht van fasering/ontwikkeling naar productie, maakt een CI/CD-systeem het tegelijkertijd beschikbaar in beide regio's. Het belangrijkste idee is om alle artefacten in een Azure Databricks-werkruimte als infrastructuur als code te behandelen. De meeste artefacten kunnen worden geïmplementeerd in zowel primaire als secundaire werkruimten, terwijl sommige artefacten mogelijk pas na een noodherstelgebeurtenis moeten worden geïmplementeerd. Zie Automation-scripts, -voorbeelden en -prototypes voor hulpprogramma's.
Het volgende diagram contrasteert deze twee benaderingen.
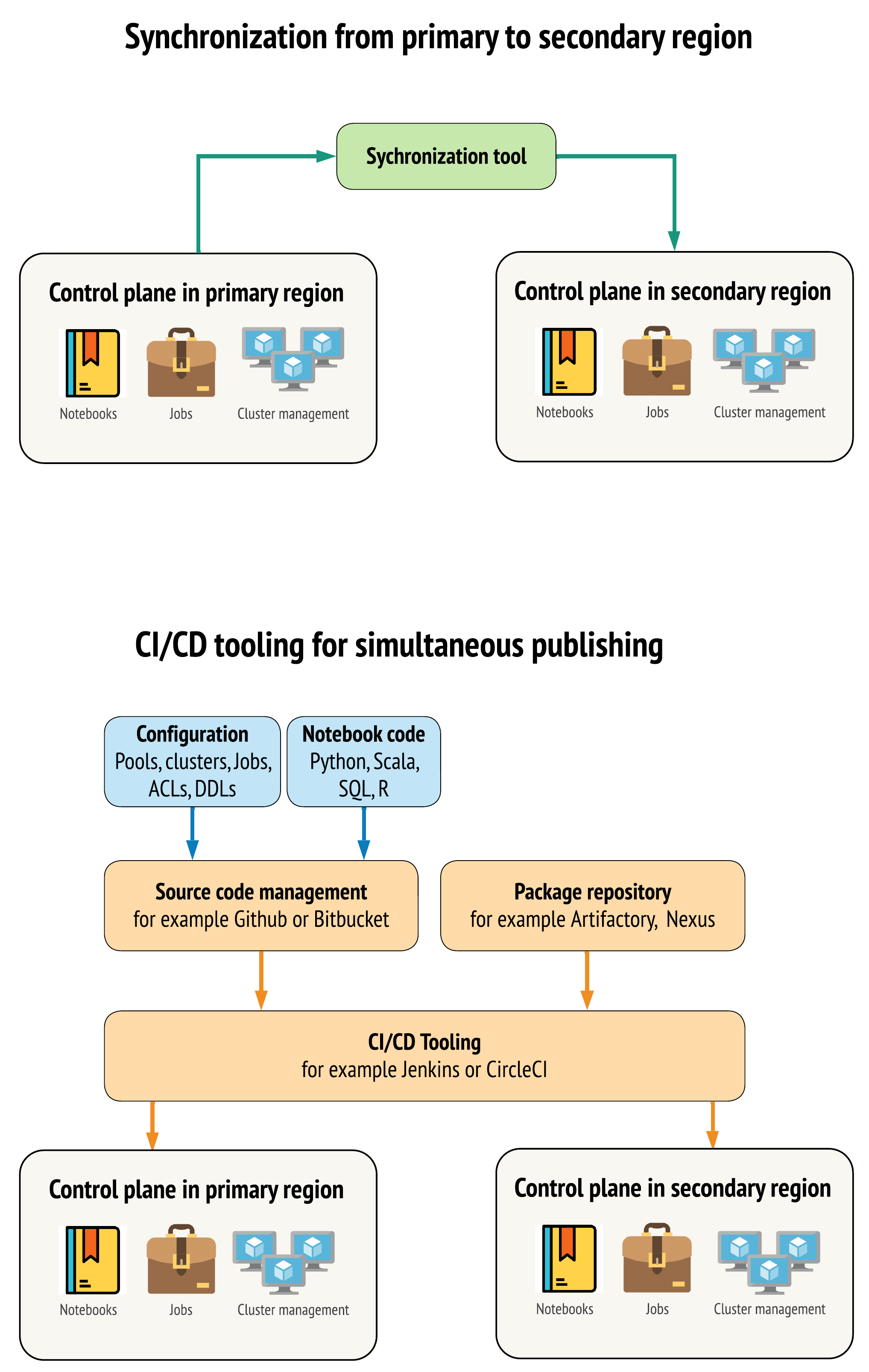
Afhankelijk van uw behoeften kunt u de benaderingen combineren. Gebruik bijvoorbeeld CI/CD voor broncode van notebooks, maar gebruik synchronisatie voor configuratie zoals pools en besturingselementen voor toegang.
In de volgende tabel wordt beschreven hoe u verschillende typen gegevens kunt verwerken met elke optie voor hulpprogramma's.
| Beschrijving | Omgaan met CI/CD-hulpprogramma's | Afhandelen met synchronisatieprogramma |
|---|---|---|
| Broncode: notebook source exports en broncode voor verpakte bibliotheken | Implementeer zowel op primair als secundair. | Synchroniseer de broncode van de primaire naar de secundaire. |
| Gebruikers en groepen | Metagegevens beheren als configuratie in Git. U kunt ook dezelfde id-provider (IdP) gebruiken voor beide werkruimten. Implementeer gebruikers- en groepsgegevens samen naar primaire en secundaire implementaties. | Gebruik SCIM of andere automatisering voor beide regio's. Handmatig maken wordt niet aanbevolen, maar als het gebruik moet worden uitgevoerd voor beide tegelijk. Als u een handmatige installatie gebruikt, maakt u een gepland geautomatiseerd proces om de lijst met gebruikers en groepen tussen de twee implementaties te vergelijken. |
| Poolconfiguraties | Dit kunnen sjablonen zijn in Git. Co-implementatie naar primaire en secundaire.
min_idle_instances In de secundaire moet echter nul zijn totdat de gebeurtenis voor herstel na noodgevallen is uitgevoerd. |
Pools die zijn gemaakt wanneer min_idle_instances ze worden gesynchroniseerd met een secundaire werkruimte met behulp van de API of CLI. |
| Taakconfiguraties | Dit kunnen sjablonen zijn in Git. Voor primaire implementatie implementeert u de taakdefinitie zoals deze is. Implementeer de taak voor secundaire implementatie en stel de valuta's in op nul. Hierdoor wordt de taak in deze implementatie uitgeschakeld en worden extra uitvoeringen voorkomen. Wijzig de waarde van de con currency nadat de secundaire implementatie actief wordt. | Als de taken om een of andere reden worden uitgevoerd op bestaande <interactive> clusters, moet de synchronisatieclient worden toegewezen aan de bijbehorende cluster_id in de secundaire werkruimte. |
| ACL’s (toegangsbeheerlijsten) | Dit kunnen sjablonen zijn in Git. Implementeer samen naar primaire en secundaire implementaties voor notebooks, mappen en clusters. Bewaar de gegevens voor taken echter totdat de gebeurtenis herstel na noodgevallen is uitgevoerd. | De Machtigingen-API kan toegangsbeheer instellen voor clusters, taken, pools, notebooks en mappen. Een synchronisatieclient moet worden toegewezen aan de bijbehorende object-id's voor elk object in de secundaire werkruimte. Databricks raadt u aan een kaart te maken van object-id's van primaire naar secundaire werkruimte tijdens het synchroniseren van deze objecten voordat u de toegangsbeheerreplicaties repliceert. |
| Bibliotheken | Opnemen in broncode- en cluster-/taaksjablonen. | Aangepaste bibliotheken synchroniseren vanuit gecentraliseerde opslagplaatsen, DBFS of cloudopslag (kan worden gekoppeld). |
| Cluster-init-scripts | Neem desgewenst de broncode op. | Voor eenvoudigere synchronisatie slaat u init-scripts op in de primaire werkruimte in een gemeenschappelijke map of in een kleine set mappen, indien mogelijk. |
| Koppelpunten | Opnemen in broncode als deze alleen wordt gemaakt via op notebooks gebaseerde taken of opdracht-API. | Gebruik taken die kunnen worden uitgevoerd als ADF-activiteiten (Azure Data Factory ). Houd er rekening mee dat de opslageindpunten kunnen veranderen, gezien de werkruimten zich in verschillende regio's bevinden. Dit hangt ook veel af van uw strategie voor herstel na noodgevallen van gegevens. |
| Metagegevens van tabel | Neem deze op met broncode als deze alleen is gemaakt via op notebooks gebaseerde taken of opdracht-API. Dit is van toepassing op zowel interne Azure Databricks-metastore als externe geconfigureerde metastore. | Vergelijk de metagegevensdefinities tussen de metastores met behulp van de Spark Catalog-API of Maak een tabel weergeven via een notebook of scripts. Houd er rekening mee dat de tabellen voor onderliggende opslag op regio's kunnen zijn gebaseerd en verschillen tussen metastore-exemplaren. |
| Geheimen | Opnemen in broncode als deze alleen is gemaakt via de Opdracht-API. Houd er rekening mee dat bepaalde geheime inhoud mogelijk moet worden gewijzigd tussen de primaire en secundaire inhoud. | Geheimen worden in beide werkruimten gemaakt via de API. Houd er rekening mee dat bepaalde geheime inhoud mogelijk moet worden gewijzigd tussen de primaire en secundaire inhoud. |
| Clusterconfiguraties | Dit kunnen sjablonen zijn in Git. Gezamenlijk implementeren naar primaire en secundaire implementaties, hoewel de implementaties in de secundaire implementatie moeten worden beëindigd totdat de noodherstelgebeurtenis plaatsvindt. | Clusters worden gemaakt nadat ze zijn gesynchroniseerd met de secundaire werkruimte met behulp van de API of CLI. Deze kunnen desgewenst expliciet worden beëindigd, afhankelijk van instellingen voor automatische beëindiging. |
| Machtigingen voor notitieblokken, taken en mappen | Dit kunnen sjablonen zijn in Git. Gezamenlijk implementeren naar primaire en secundaire implementaties. | Repliceren met behulp van de Machtigingen-API. |
Regio's en meerdere secundaire werkruimten kiezen
U hebt volledige controle nodig over de trigger voor herstel na noodgevallen. U kunt dit op elk gewenst moment of om welke reden dan ook activeren. U moet de verantwoordelijkheid nemen voor herstel na noodgevallen voordat u de failbackmodus van uw bewerking (normale productie) opnieuw kunt starten. Dit betekent meestal dat u meerdere Azure Databricks-werkruimten moet maken om te voldoen aan uw behoeften voor productie- en herstel na noodgevallen en dat u uw secundaire failoverregio moet kiezen.
Controleer in Azure de gegevensreplicatie en de beschikbaarheid van product- en VM-typen.
Stap 3: Werkruimten voorbereiden en eenmalig kopiëren
Als een werkruimte al in productie is, is het gebruikelijk om een eenmalige kopieerbewerking uit te voeren om uw passieve implementatie te synchroniseren met uw actieve implementatie. Deze eenmalige kopieerbewerking verwerkt het volgende:
- Gegevensreplicatie: Repliceren met behulp van een cloudreplicatieoplossing of Delta Deep Clone-bewerking.
- Tokengeneratie: gebruik tokengeneratie om de replicatie en toekomstige workloads te automatiseren.
- Werkruimtereplicatie: Gebruik werkruimtereplicatie met behulp van de methoden die worden beschreven in stap 4: Uw gegevensbronnen voorbereiden.
- Werkruimtevalidatie: test om ervoor te zorgen dat de werkruimte en het proces correct kunnen worden uitgevoerd en de verwachte resultaten kunnen leveren.
Na de eerste eenmalige kopieerbewerking zijn de volgende kopieer- en synchronisatieacties sneller en logboekregistratie vanuit uw hulpprogramma's is ook een logboek van wat er is gewijzigd en wanneer deze is gewijzigd.
Stap 4: Uw gegevensbronnen voorbereiden
Azure Databricks kan een grote verscheidenheid aan gegevensbronnen verwerken met behulp van batchverwerking of gegevensstromen.
Batchverwerking vanuit gegevensbronnen
Wanneer gegevens in batch worden verwerkt, bevinden deze zich meestal in een gegevensbron die eenvoudig kan worden gerepliceerd of in een andere regio kan worden geleverd.
Gegevens kunnen bijvoorbeeld regelmatig worden geüpload naar een cloudopslaglocatie. In de modus voor herstel na noodgevallen voor uw secundaire regio moet u ervoor zorgen dat de bestanden worden geüpload naar de opslag in uw secundaire regio. Workloads moeten de opslag van de secundaire regio lezen en schrijven naar de opslag van de secundaire regio.
Gegevensstromen
Het verwerken van een gegevensstroom is een grotere uitdaging. Streaminggegevens kunnen worden opgenomen uit verschillende bronnen en worden verwerkt en verzonden naar een streamingoplossing:
- Berichtenwachtrij zoals Kafka
- Gegevensopnamestroom voor databasewijziging
- Continue verwerking op basis van bestanden
- Geplande verwerking op basis van bestanden, ook wel bekend als trigger eenmaal
In al deze gevallen moet u uw gegevensbronnen configureren voor het afhandelen van de modus voor herstel na noodgevallen en voor het gebruik van uw secundaire implementatie in uw secundaire regio.
Een streamschrijver slaat een controlepunt op met informatie over de gegevens die zijn verwerkt. Dit controlepunt kan een gegevenslocatie (meestal cloudopslag) bevatten die moet worden gewijzigd in een nieuwe locatie om ervoor te zorgen dat de stream opnieuw wordt opgestart. De submap onder het controlepunt kan bijvoorbeeld source de cloudmap op basis van bestanden opslaan.
Dit controlepunt moet tijdig worden gerepliceerd. Overweeg synchronisatie van het controlepuntinterval met een nieuwe cloudreplicatieoplossing.
De controlepuntupdate is een functie van de schrijver en is daarom van toepassing op opname of verwerking van gegevensstromen en opslaan op een andere streamingbron.
Voor streamingworkloads moet u ervoor zorgen dat controlepunten zijn geconfigureerd in door de klant beheerde opslag, zodat ze kunnen worden gerepliceerd naar de secundaire regio voor het hervatten van workloads vanaf het punt van de laatste fout. U kunt er ook voor kiezen om het secundaire streamingproces parallel aan het primaire proces uit te voeren.
Stap 5: Uw oplossing implementeren en testen
Test regelmatig de installatie voor herstel na noodgevallen om ervoor te zorgen dat deze correct functioneert. Er is geen waarde voor het onderhouden van een noodhersteloplossing als u deze niet kunt gebruiken wanneer u deze nodig hebt. Sommige bedrijven schakelen om de paar maanden tussen regio's. Als u van regio wisselt volgens een regelmatig schema, worden uw veronderstellingen en processen getest en wordt ervoor gezorgd dat ze voldoen aan uw herstelbehoeften. Dit zorgt er ook voor dat uw organisatie bekend is met het beleid en de procedures voor noodgevallen.
Belangrijk
Test regelmatig uw oplossing voor herstel na noodgevallen in echte omstandigheden.
Als u ontdekt dat u een object of sjabloon mist en nog steeds moet vertrouwen op de gegevens die zijn opgeslagen in uw primaire werkruimte, wijzigt u uw plan om deze obstakels te verwijderen, repliceert u deze informatie in het secundaire systeem of maakt u deze op een andere manier beschikbaar.
Test eventuele vereiste organisatiewijzigingen in uw processen en configuratie in het algemeen. Uw plan voor herstel na noodgevallen heeft gevolgen voor uw implementatiepijplijn en het is belangrijk dat uw team weet wat er gesynchroniseerd moet worden gehouden. Nadat u uw werkruimten voor herstel na noodgevallen hebt ingesteld, moet u ervoor zorgen dat uw infrastructuur (handmatig of code), taken, notebooks, bibliotheken en andere werkruimteobjecten beschikbaar zijn in uw secundaire regio.
Neem contact op met uw team over het uitbreiden van standaardwerkprocessen en configuratiepijplijnen om wijzigingen in alle werkruimten te implementeren. Gebruikersidentiteiten beheren in alle werkruimten. Vergeet niet om hulpprogramma's zoals taakautomatisering en bewaking voor nieuwe werkruimten te configureren.
Wijzigingen in configuratiehulpprogramma's plannen en testen:
- Opname: inzicht krijgen in waar uw gegevensbronnen zich bevinden en waar deze bronnen hun gegevens ophalen. Indien mogelijk kunt u de bron parameteriseren en ervoor zorgen dat u een afzonderlijke configuratiesjabloon hebt voor het werken met uw secundaire implementaties en secundaire regio's. Bereid een plan voor failover voor en test alle veronderstellingen.
- Uitvoeringswijzigingen: Als u een planner hebt om taken of andere acties te activeren, moet u mogelijk een afzonderlijke planner configureren die werkt met de secundaire implementatie of de bijbehorende gegevensbronnen. Bereid een plan voor failover voor en test alle veronderstellingen.
- Interactieve connectiviteit: Overweeg hoe configuratie-, verificatie- en netwerkverbindingen kunnen worden beïnvloed door regionale onderbrekingen voor het gebruik van REST API's, CLI-hulpprogramma's of andere services, zoals JDBC/ODBC. Bereid een plan voor failover voor en test alle veronderstellingen.
- Automatiseringswijzigingen: Bereid voor alle automatiseringsprogramma's een plan voor failover voor en test alle veronderstellingen.
- Uitvoer: Voor alle hulpprogramma's die uitvoergegevens of logboeken genereren, bereidt u een plan voor failover voor en test u alle veronderstellingen.
Testfailover
Herstel na noodgevallen kan worden geactiveerd door veel verschillende scenario's. Deze kan worden geactiveerd door een onverwachte onderbreking. Sommige kernfunctionaliteit is mogelijk niet beschikbaar, waaronder het cloudnetwerk, cloudopslag of een andere kernservice. U hebt geen toegang om het systeem probleemloos af te sluiten en moet proberen te herstellen. Het proces kan echter worden geactiveerd door een uitschakeling of geplande storing, of zelfs door periodiek over te schakelen van uw actieve implementaties tussen twee regio's.
Wanneer u een failover test, maakt u verbinding met het systeem en voert u een afsluitproces uit. Zorg ervoor dat alle taken zijn voltooid en dat de clusters worden beëindigd.
Een synchronisatieclient (of CI/CD-hulpprogramma's) kan relevante Azure Databricks-objecten en -resources repliceren naar de secundaire werkruimte. Als u uw secundaire werkruimte wilt activeren, bevat uw proces mogelijk een of meer van de volgende opties:
- Voer tests uit om te controleren of het platform up-to-date is.
- Schakel pools en clusters in de primaire regio uit, zodat als de mislukte service online wordt geretourneerd, de primaire regio niet begint met het verwerken van nieuwe gegevens.
- Herstelproces:
- Controleer de datum van de meest recente gesynchroniseerde gegevens. Zie de terminologie van de branche voor herstel na noodgevallen. De details van deze stap variëren op basis van hoe u gegevens en uw unieke bedrijfsbehoeften synchroniseert.
- Stabiliseer uw gegevensbronnen en zorg ervoor dat ze allemaal beschikbaar zijn. Neem alle externe gegevensbronnen op, zoals Azure Cloud SQL, evenals uw Delta Lake, Parquet of andere bestanden.
- Zoek uw streaming-herstelpunt. Stel het proces in om van daaruit opnieuw op te starten en een proces gereed te hebben om potentiële duplicaten te identificeren en te elimineren (Delta Lake Lake maakt dit eenvoudiger).
- Voltooi het gegevensstroomproces en informeer de gebruikers.
- Start relevante pools (of verhoog het naar het
min_idle_instancesrelevante getal). - Start relevante clusters (indien niet beëindigd).
- Wijzig de gelijktijdige uitvoering voor taken en voer relevante taken uit. Dit kunnen eenmalige uitvoeringen of periodieke uitvoeringen zijn.
- Voor elk extern hulpprogramma dat gebruikmaakt van een URL of domeinnaam voor uw Azure Databricks-werkruimte, werkt u configuraties bij om rekening te houden met het nieuwe besturingsvlak. Werk bijvoorbeeld URL's voor REST API's en JDBC-/ODBC-verbindingen bij. De klantgerichte URL van de Azure Databricks-webtoepassing wordt gewijzigd wanneer het besturingsvlak wordt gewijzigd, dus informeer de gebruikers van uw organisatie over de nieuwe URL.
Herstel testen (failback)
Failback is eenvoudiger te beheren en kan worden uitgevoerd in een onderhoudsvenster. Dit plan kan enkele of alle volgende omvatten:
- Bevestiging ontvangen dat de primaire regio is hersteld.
- Schakel pools en clusters in de secundaire regio uit, zodat er geen nieuwe gegevens worden verwerkt.
- Synchroniseer nieuwe of gewijzigde assets in de secundaire werkruimte terug naar de primaire implementatie. Afhankelijk van het ontwerp van uw failoverscripts, kunt u mogelijk dezelfde scripts uitvoeren om de objecten van de secundaire regio (herstel na noodgeval) te synchroniseren met de primaire (productie) regio.
- Synchroniseer eventuele nieuwe gegevensupdates terug naar de primaire implementatie. U kunt de audittrails van logboeken en Delta-tabellen gebruiken om geen gegevensverlies te garanderen.
- Sluit alle workloads uit in de regio voor herstel na noodgevallen.
- Wijzig de taken en gebruikers-URL in de primaire regio.
- Voer tests uit om te controleren of het platform up-to-date is.
- Begin relevante pools (of verhoog het
min_idle_instancesnaar een relevant getal). - Start relevante clusters (indien niet beëindigd).
- Wijzig de gelijktijdige uitvoering voor taken en voer relevante taken uit. Dit kunnen eenmalige uitvoeringen of periodieke uitvoeringen zijn.
- Stel indien nodig uw secundaire regio opnieuw in voor toekomstig herstel na noodgevallen.
Automatiseringsscripts, voorbeelden en prototypen
Automatiseringsscripts voor uw noodherstelprojecten:
- Databricks raadt u aan de Databricks Terraform-provider te gebruiken om uw eigen synchronisatieproces te ontwikkelen.
- Zie ook Hulpprogramma's voor migratie van Databricks-werkruimten voor voorbeeldscripts en prototypescripts. Naast Azure Databricks-objecten repliceert u alle relevante Azure Data Factory-pijplijnen, zodat ze verwijzen naar een gekoppelde service die is toegewezen aan de secundaire werkruimte.
- Het Databricks Sync-project (DBSync) is een hulpprogramma voor objectsynchronisatie waarmee een back-up wordt gemaakt van Databricks-werkruimten, herstelt en synchroniseert.