Gegevens van Apache Kafka opnemen in Azure Data Explorer
Apache Kafka is een gedistribueerd streamingplatform voor het bouwen van pijplijnen voor realtime streaminggegevens waarmee gegevens betrouwbaar tussen systemen of toepassingen worden verplaatst. Kafka Connect is een hulpprogramma voor schaalbare en betrouwbare streaming van gegevens tussen Apache Kafka en andere gegevenssystemen. De Kusto Kafka-sink fungeert als de connector van Kafka en vereist geen code. Download het jar-bestand van de sinkconnector uit de Git-opslagplaats of Confluent Connector Hub.
In dit artikel wordt beschreven hoe u gegevens opneemt met Kafka met behulp van een zelfstandige Docker-installatie om de installatie van het Kafka-cluster en het Kafka-connectorcluster te vereenvoudigen.
Zie de Git-opslagplaats en versiedetails van de connector voor meer informatie.
Vereisten
- Een Azure-abonnement. Maak een gratis Azure-account.
- Een Azure Data Explorer-cluster en -database met het standaardcache- en bewaarbeleid of een KQL-database in Microsoft Fabric.
- Azure CLI.
- Docker en Docker Compose.
Een Microsoft Entra service-principal maken
De Microsoft Entra service-principal kan worden gemaakt via de Azure Portal of programmatisch, zoals in het volgende voorbeeld.
Deze service-principal is de identiteit die door de connector wordt gebruikt om gegevens te schrijven in uw tabel in Kusto. U verleent deze service-principal later machtigingen voor toegang tot Kusto-resources.
Meld u aan bij uw Azure-abonnement via Azure CLI. Verifieer vervolgens in de browser.
az loginKies het abonnement om de principal te hosten. Deze stap is nodig wanneer u meerdere abonnementen hebt.
az account set --subscription YOUR_SUBSCRIPTION_GUIDMaak de service-principal. In dit voorbeeld wordt de service-principal genoemd
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Kopieer vanuit de geretourneerde JSON-gegevens de
appId,password, entenantvoor toekomstig gebruik.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
U hebt uw Microsoft Entra toepassing en service-principal gemaakt.
Een doeltabel maken
Maak vanuit uw queryomgeving een tabel met de naam
Stormsmet behulp van de volgende opdracht:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Maak de bijbehorende tabeltoewijzing
Storms_CSV_Mappingvoor opgenomen gegevens met behulp van de volgende opdracht:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Maak een batchverwerkingsbeleid voor opname in de tabel voor configureerbare opnamelatentie in de wachtrij.
Tip
Het batchverwerkingsbeleid voor opname is een optimalisatieprogramma voor prestaties en bevat drie parameters. Als aan de eerste voorwaarde is voldaan, wordt de opname in de Azure Data Explorer-tabel geactiveerd.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Gebruik de service-principal uit Een Microsoft Entra service-principal maken om toestemming te verlenen om met de database te werken.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Het lab uitvoeren
Het volgende lab is ontworpen om u de ervaring te bieden om te beginnen met het maken van gegevens, het instellen van de Kafka-connector en het streamen van deze gegevens naar Azure Data Explorer met de connector. Vervolgens kunt u de opgenomen gegevens bekijken.
De Git-opslagplaats klonen
Kloon de Git-opslagplaats van het lab.
Maak een lokale map op uw computer.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holKloon de opslagplaats.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Inhoud van de gekloonde opslagplaats
Voer de volgende opdracht uit om de inhoud van de gekloonde opslagplaats weer te geven:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Dit resultaat van deze zoekopdracht is:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
De bestanden in de gekloonde opslagplaats controleren
In de volgende secties worden de belangrijke onderdelen van de bestanden in de bovenstaande bestandsstructuur uitgelegd.
adx-sink-config.json
Dit bestand bevat het eigenschappenbestand van de Kusto-sink waarin u specifieke configuratiedetails bijwerkt:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Vervang de waarden voor de volgende kenmerken volgens uw Azure Data Explorer-installatie: aad.auth.authority, aad.auth.appid, aad.auth.appkeykusto.tables.topics.mapping , (de databasenaam), kusto.ingestion.urlen kusto.query.url.
Connector - Dockerfile
Dit bestand bevat de opdrachten voor het genereren van de docker-installatiekopieën voor het connectorexemplaar. Het bevat het downloaden van de connector uit de releasemap van de Git-opslagplaats.
Storm-events-producer directory
Deze map heeft een Go-programma dat een lokaal 'StormEvents.csv'-bestand leest en de gegevens publiceert naar een Kafka-onderwerp.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
De containers starten
Start de containers in een terminal:
docker-compose upDe producenttoepassing begint met het verzenden van gebeurtenissen naar het
storm-eventsonderwerp. U ziet nu logboeken die vergelijkbaar zijn met de volgende logboeken:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Als u de logboeken wilt controleren, voert u de volgende opdracht uit in een afzonderlijke terminal:
docker-compose logs -f | grep kusto-connect
De connector starten
Gebruik een Kafka Connect REST-aanroep om de connector te starten.
Start de sink-taak in een afzonderlijke terminal met de volgende opdracht:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsVoer de volgende opdracht uit in een afzonderlijke terminal om de status te controleren:
curl http://localhost:8083/connectors/storm/status
De connector begint met het in de wachtrij plaatsen van opnameprocessen naar Azure Data Explorer.
Notitie
Als u problemen hebt met de logboekconnector, maakt u een probleem.
Gegevens opvragen en controleren
Gegevensopname bevestigen
Wacht totdat de gegevens in de
Stormstabel binnenkomen. Controleer het aantal rijen om de overdracht van gegevens te bevestigen:Storms | countControleer of er geen fouten zijn in het opnameproces:
.show ingestion failuresZodra u gegevens ziet, kunt u een paar query's proberen.
Query’s uitvoeren voor de gegevens
Voer de volgende query uit om alle records te zien:
StormsGebruik
whereenprojectom specifieke gegevens te filteren:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdGebruik de
summarizeoperator:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart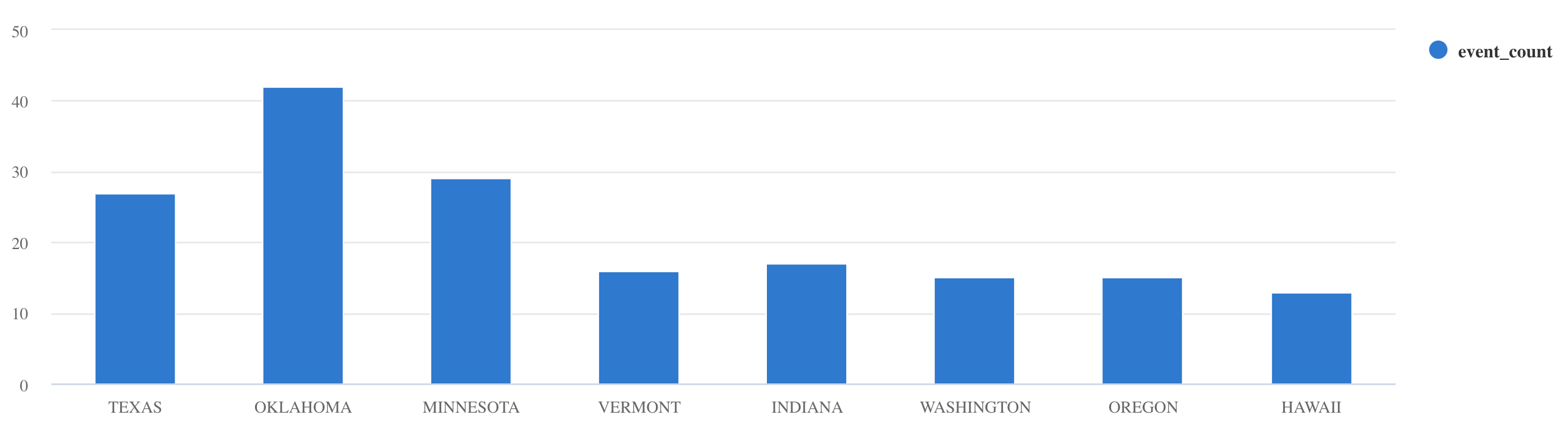
Zie Query's schrijven in KQL en documentatie over Kusto-querytaal voor meer queryvoorbeelden en richtlijnen.
Opnieuw instellen
Als u opnieuw wilt instellen, voert u de volgende stappen uit:
- De containers stoppen (
docker-compose down -v) - Verwijderen (
drop table Storms) - De tabel opnieuw maken
Storms - Tabeltoewijzing opnieuw maken
- Containers opnieuw starten (
docker-compose up)
Resources opschonen
Als u de Azure Data Explorer-resources wilt verwijderen, gebruikt u az cluster delete of az Kusto database delete:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
De Kafka Sink-connector afstemmen
Stem de Kafka Sink-connector af om te werken met het batchverwerkingsbeleid voor opname:
- Stem de groottelimiet van de Kafka-sink
flush.size.bytesaf vanaf 1 MB, oplopend met stappen van 10 MB of 100 MB. - Wanneer u Kafka Sink gebruikt, worden gegevens twee keer geaggregeerd. Aan de connectorzijde worden gegevens geaggregeerd volgens de instellingen voor leegmaken en aan de Azure Data Explorer-servicezijde volgens het batchverwerkingsbeleid. Als de batchtijd te kort is en er geen gegevens kunnen worden opgenomen door zowel de connector als de service, moet de batchverwerkingstijd worden verlengd. Stel de batchgrootte in op 1 GB en verhoog of verlaag zo nodig met stappen van 100 MB. Als de grootte van het leegmaken bijvoorbeeld 1 MB is en de batchbeleidsgrootte 100 MB is, wordt, nadat een batch van 100 MB is geaggregeerd door de Kafka Sink-connector, een batch van 100 MB opgenomen door de Azure Data Explorer-service. Als de batchverwerkingsbeleidstijd 20 seconden is en de Kafka Sink-connector 50 MB in een periode van 20 seconden leeg maakt, neemt de service een batch van 50 MB op.
- U kunt schalen door exemplaren en Kafka-partities toe te voegen. Verhoog
tasks.maxtot het aantal partities. Maak een partitie als u voldoende gegevens hebt om een blob te produceren met de grootte van deflush.size.bytesinstelling. Als de blob kleiner is, wordt de batch verwerkt wanneer deze de tijdslimiet bereikt, zodat de partitie onvoldoende doorvoer ontvangt. Een groot aantal partities betekent meer verwerkingsoverhead.
Gerelateerde inhoud
- Meer informatie over big data-architectuur.
- Meer informatie over het opnemen van voorbeeldgegevens in JSON-indeling in Azure Data Explorer.
- Voor aanvullende Kafka-labs: