Oplossingen voor bedrijfscontinuïteit en herstel na noodgevallen maken met Azure Data Explorer
In dit artikel wordt beschreven hoe u zich kunt voorbereiden op een regionale Azure-storing door uw Azure Data Explorer-resources, beheer en opname in verschillende Azure-regio's te repliceren. Er wordt een voorbeeld gegeven van gegevensopname met Azure Event Hubs. Kostenoptimalisatie wordt ook besproken voor verschillende architectuurconfiguraties. Zie het overzicht van bedrijfscontinuïteit voor meer informatie over architectuuroverwegingen en hersteloplossingen.
Voorbereiden op regionale Azure-storingen om uw gegevens te beveiligen
Azure Data Explorer biedt geen ondersteuning voor automatische beveiliging tegen storingen in een hele Azure-regio. Deze onderbreking kan optreden tijdens een natuurramp, zoals een aardbeving. Als u een oplossing nodig hebt voor een noodherstelsituatie, voert u de volgende stappen uit om de bedrijfscontinuïteit te waarborgen. In deze stappen repliceert u uw clusters, beheer en gegevensopname in twee gekoppelde Azure-regio's.
- Maak twee of meer onafhankelijke clusters in twee gekoppelde Azure-regio's.
- Repliceer alle beheeractiviteiten , zoals het maken van nieuwe tabellen of het beheren van gebruikersrollen in elk cluster.
- Gegevens parallel opnemen in elk cluster.
Meerdere onafhankelijke clusters maken
Maak meer dan één Azure Data Explorer-cluster in meer dan één regio. Zorg ervoor dat ten minste twee van deze clusters zijn gemaakt in gekoppelde Azure-regio's.
In de volgende afbeelding ziet u replica's, drie clusters in drie verschillende regio's.

Beheeractiviteiten repliceren
Repliceer de beheeractiviteiten zodat elke replica dezelfde clusterconfiguratie heeft.
Maak op elke replica hetzelfde:
- Databases: U kunt de Azure Portal of een van onze SDK's gebruiken om een nieuwe database te maken.
- Tabellen
- Toewijzingen
- Beleidsregels
De verificatie en autorisatie op elke replica beheren.
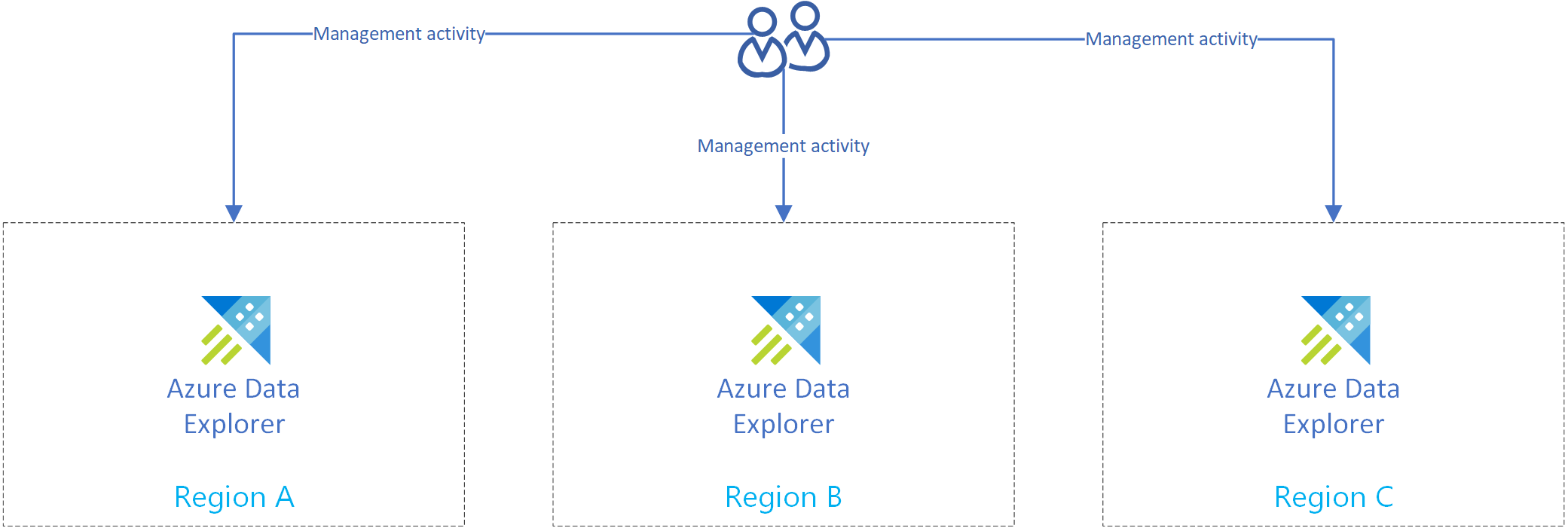
Oplossing voor herstel na noodgeval met behulp van Event Hub-opname
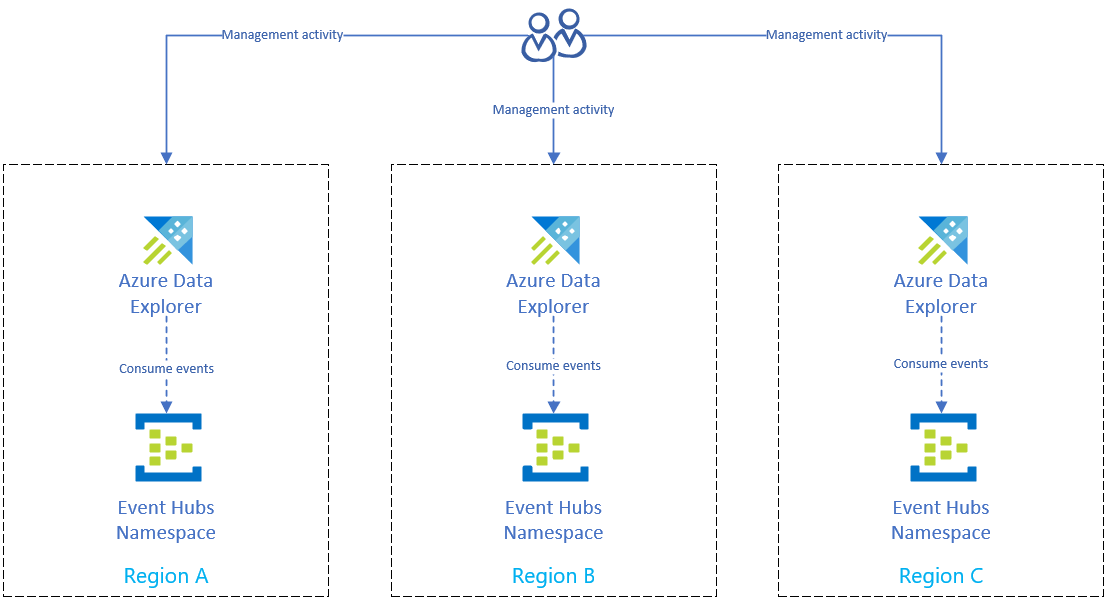
Zodra u Voorbereiden op regionale Azure-storing om uw gegevens te beveiligen hebt voltooid, worden uw gegevens en beheer gedistribueerd naar meerdere regio's. Als er een storing is in de ene regio, kunnen Azure Data Explorer de andere replica's gebruiken.
Opname instellen met behulp van een Event Hub
Als u gegevens van Azure Event Hubs wilt opnemen in het Azure Data Explorer-cluster van elke regio, repliceert u eerst uw Azure Event Hubs-installatie in elke regio. Configureer vervolgens de Azure Data Explorer-replica van elke regio om gegevens op te nemen uit de bijbehorende Event Hubs.
Notitie
Opname via Azure Event Hubs/IoT Hub/Storage is robuust. Als een cluster gedurende een bepaalde periode niet beschikbaar is, wordt het later ingehaald en worden eventuele in behandeling zijnde berichten of blobs ingevoegd. Dit proces is afhankelijk van controlepunten.
Zoals in het onderstaande diagram wordt weergegeven, produceren uw gegevensbronnen gebeurtenissen naar Event Hubs in alle regio's en gebruikt elke Azure Data Explorer-replica de gebeurtenissen. Onderdelen van gegevensvisualisatie, zoals Power BI, Grafana of web-apps met SDK, kunnen query's uitvoeren op een van de replica's.
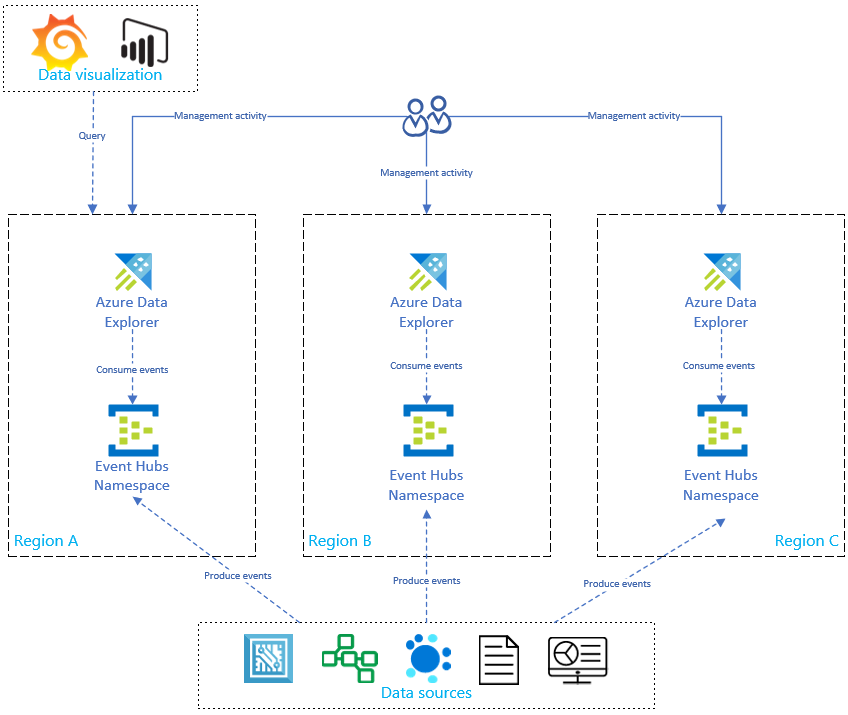
Kosten optimaliseren
U bent nu klaar om uw replica's te optimaliseren met behulp van een aantal van de volgende methoden:
- Een configuratie voor gegevensherstel op aanvraag maken
- De replica's starten en stoppen
- Een maximaal beschikbare toepassingsservice implementeren
- Kosten optimaliseren in een actief-actief-configuratie
Een configuratie voor gegevensherstel op aanvraag maken
Het repliceren en bijwerken van de Installatie van Azure Data Explorer verhoogt de kosten lineair met het aantal replica's. Als u de kosten wilt optimaliseren, kunt u een architectuurvariant implementeren om tijd, failover en kosten in balans te brengen. In een configuratie voor gegevensherstel op aanvraag is kostenoptimalisatie geïmplementeerd door passieve Azure Data Explorer-replica's te introduceren. Deze replica's worden alleen ingeschakeld als er een noodgeval is in de primaire regio (bijvoorbeeld regio A). De replica's in regio's B en C hoeven niet 24/7 actief te zijn, waardoor de kosten aanzienlijk afnemen. In de meeste gevallen zijn de prestaties van deze replica's echter niet zo goed als het primaire cluster. Zie Configuratie voor gegevensherstel op aanvraag voor meer informatie.
In de onderstaande afbeelding neemt slechts één cluster gegevens op uit de Event Hub. Het primaire cluster in regio A voert continue gegevensexport van alle gegevens naar een opslagaccount uit. De secundaire replica's hebben toegang tot de gegevens met behulp van externe tabellen.
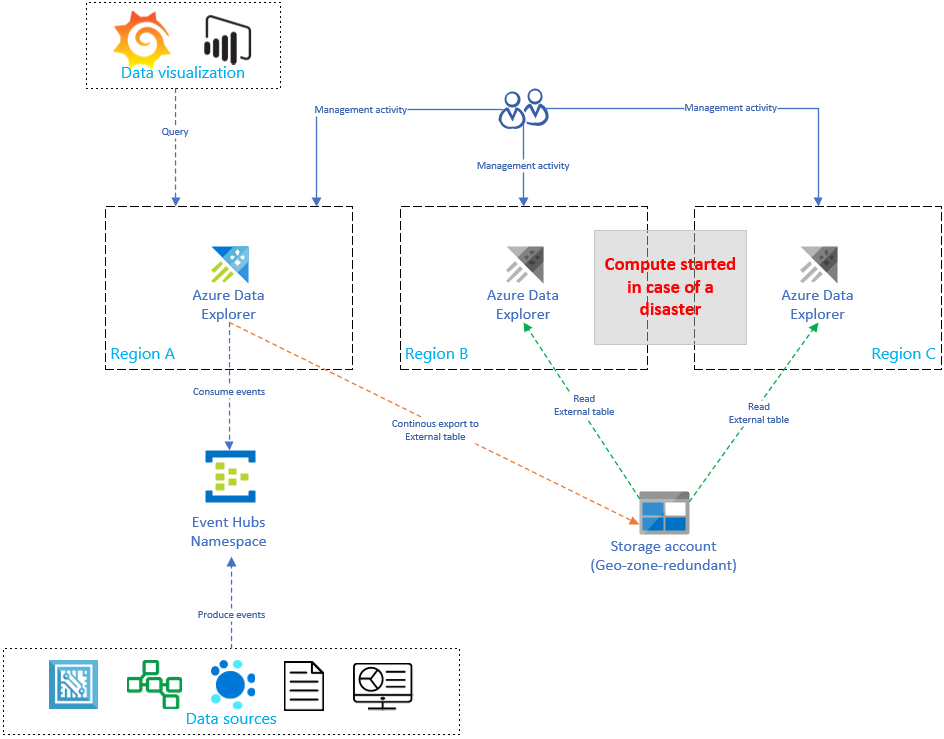
De replica's starten en stoppen
U kunt de secundaire replica's op een van de volgende manieren starten en stoppen:
De knop Stoppen op het tabblad Overzicht in de Azure Portal. Zie Het cluster stoppen en opnieuw starten voor meer informatie.
Azure CLI:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>”
Een maximaal beschikbare toepassingsservice implementeren
De Azure App Service BCDR-client maken
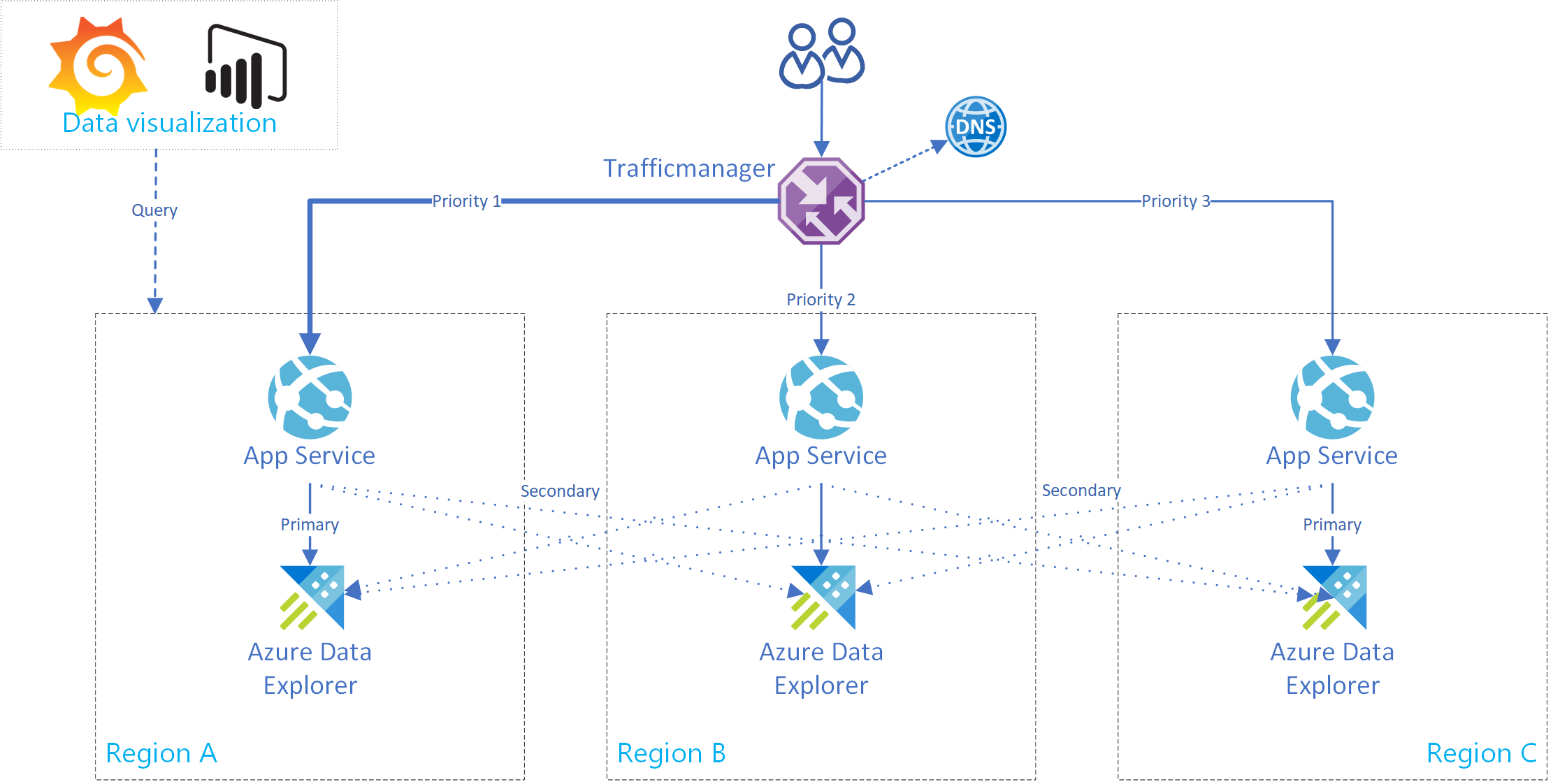
In deze sectie wordt beschreven hoe u een Azure App Service maakt die ondersteuning biedt voor een verbinding met één primaire en meerdere secundaire Azure Data Explorer-clusters. In de volgende afbeelding ziet u de Azure App Service setup.
Tip
Als u meerdere verbindingen tussen replica's in dezelfde service hebt, krijgt u meer beschikbaarheid. Deze installatie is niet alleen nuttig in gevallen van regionale storingen.
Gebruik deze standaardcode voor een app-service. Voor het implementeren van een client met meerdere clusters is de klasse AdxBcdrClient gemaakt. Elke query die met deze client wordt uitgevoerd, wordt eerst verzonden naar het primaire cluster. Als er een fout optreedt, wordt de query verzonden naar secundaire replica's.
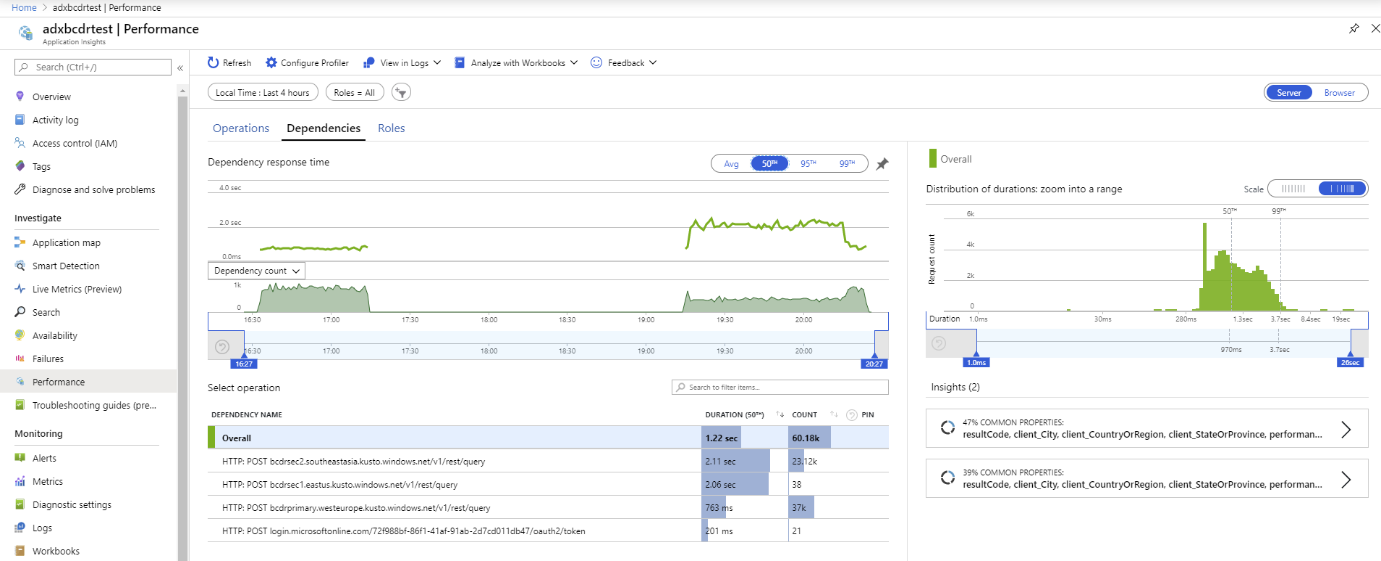
Gebruik metrische gegevens van aangepaste Application Insights om prestaties te meten en distributie naar primaire en secundaire clusters aan te vragen.
De Azure App Service BCDR-client testen
We hebben een test uitgevoerd met behulp van meerdere Azure Data Explorer-replica's. Na een gesimuleerde storing van primaire en secundaire clusters ziet u dat de BCDR-client van de app-service werkt zoals bedoeld.
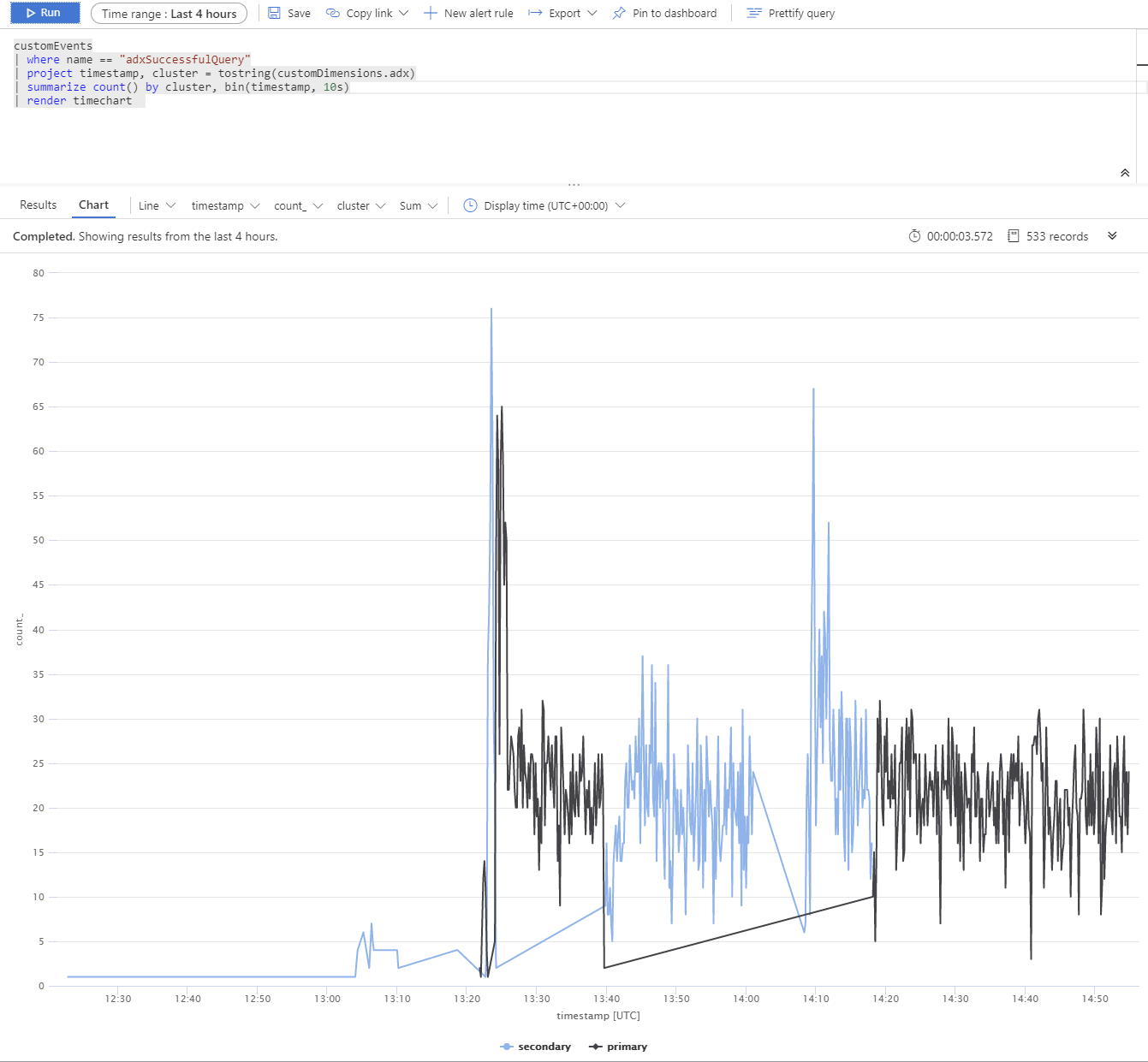
De Azure Data Explorer-clusters worden gedistribueerd over Europa - west (primair 2xD14v2), Azië - zuidoost en VS - oost (2xD11v2).
Notitie
Tragere reactietijden worden veroorzaakt door verschillende SKU's en query's tussen planeten.
Dynamische of statische routering uitvoeren
Gebruik Azure Traffic Manager-routeringsmethoden voor dynamische of statische routering van de aanvragen. Azure Traffic Manager is een load balancer op basis van DNS-verkeer waarmee u App Service-verkeer kunt distribueren. Dit verkeer wordt geoptimaliseerd voor services in wereldwijde Azure-regio's, terwijl hoge beschikbaarheid en reactiesnelheid worden geboden.
U kunt ook routering op basis van Azure Front Door gebruiken. Zie Taakverdeling met de toepassingsleveringssuite van Azure voor een vergelijking van deze twee methoden.
Kosten optimaliseren in een actief-actief-configuratie
Het gebruik van een actief-actief-configuratie voor herstel na noodgevallen verhoogt de kosten lineair. De kosten omvatten knooppunten, opslag, markeringen en hogere netwerkkosten voor bandbreedte.
Geoptimaliseerde automatische schaalaanpassing gebruiken om de kosten te optimaliseren
Gebruik de geoptimaliseerde functie voor automatisch schalen om horizontaal schalen te configureren voor de secundaire clusters. Ze moeten worden gedimensioneerd, zodat ze de opnamebelasting kunnen verwerken. Zodra het primaire cluster niet bereikbaar is, krijgen de secundaire clusters meer verkeer en worden ze geschaald op basis van de configuratie.
Het gebruik van geoptimaliseerde automatische schaalaanpassing in dit voorbeeld bespaart ongeveer 50% van de kosten in vergelijking met dezelfde horizontale en verticale schaal op alle replica's.