Realtime analyse-apps modelleren in Azure Cosmos DB for PostgreSQL
VAN TOEPASSING OP: ![]() Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
Grote tabellen met shardsleutel colocate
Volg deze richtlijnen om de shardsleutel voor een realtime operationele analysetoepassing te kiezen:
- Een kolom kiezen die gebruikelijk is voor grote tabellen
- Kies een kolom die een natuurlijke dimensie is in de gegevens of een centraal onderdeel van de toepassing. Enkele voorbeelden:
- In de financiële wereld zou een toepassing die beveiligingstrends analyseert waarschijnlijk worden gebruikt
security_id. - In een workload voor gebruikersanalyse waarin u metrische gegevens over het gebruik van websites wilt analyseren,
user_idis dit een goede distributiekolom
- In de financiële wereld zou een toepassing die beveiligingstrends analyseert waarschijnlijk worden gebruikt
Door grote tabellen te verplaatsen, kunt u SQL-query's parallel naar werkknooppunten pushen. Door query's omlaag te pushen, worden er geen gegevens tussen knooppunten via het netwerk geschoven. Bewerkingen zoals JOIN's, aggregaties, rollups, filters, LIMITs kunnen efficiënt worden uitgevoerd.
Bekijk dit diagram om parallelle gedistribueerde query's op tabellen met een punt te visualiseren:
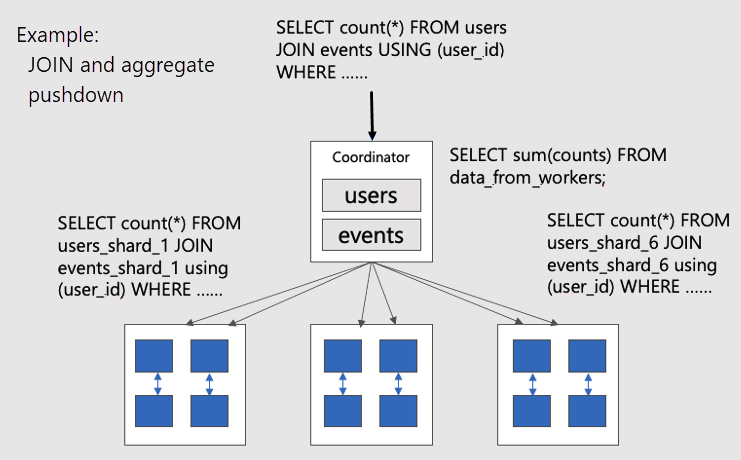
De users tabellen en events tabellen zijn beide sharded door user_id, dus gerelateerde rijen voor dezelfde gebruikers-id worden op hetzelfde werkknooppunt geplaatst. De SQL-JOIN's kunnen plaatsvinden zonder informatie tussen werkrollen op te halen.
Optimaal gegevensmodel voor realtime-apps
Laten we doorgaan met het voorbeeld van een toepassing waarmee bezoeken en metrische gegevens van gebruikerswebsites worden geanalyseerd. Er zijn twee feitentabellen: gebruikers en gebeurtenissen, en andere kleinere dimensietabellen.
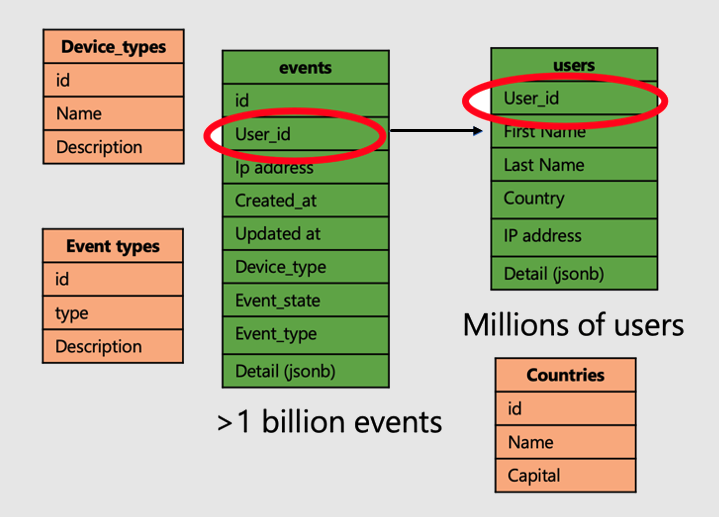
Volg de volgende stappen om de superkracht van gedistribueerde tabellen toe te passen in Azure Cosmos DB for PostgreSQL:
- Distribueer grote feitentabellen in een gemeenschappelijke kolom. In ons geval worden gebruikers en gebeurtenissen gedistribueerd op
user_id. - Markeer de tabellen met kleine dimensies (
device_typesencountries'event_types) als referentietabellen. - Zorg ervoor dat u de distributiekolom opneemt in beperkingen voor primaire, unieke en refererende sleutels voor gedistribueerde tabellen. Als u de kolom op wilt opnemen, moet u mogelijk de sleutels samengesteld maken. Er moet sleutels worden bijgewerkt voor referentietabellen.
- Wanneer u grote gedistribueerde tabellen koppelt, moet u zich samenvoegen met behulp van de shardsleutel.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Volgende stappen
Nu zijn we klaar met het verkennen van gegevensmodellering voor schaalbare apps. De volgende stap is het verbinden en opvragen van de database met de programmeertaal van uw keuze.