SaaS-apps met meerdere tenants modelleren in Azure Cosmos DB for PostgreSQL
VAN TOEPASSING OP: ![]() Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
Tenant-id als de shardsleutel
De tenant-id is de kolom in de hoofdmap van de workload of de bovenkant van de hiërarchie in uw gegevensmodel. In dit SaaS-e-commerceschema zou dit bijvoorbeeld de winkel-id zijn:
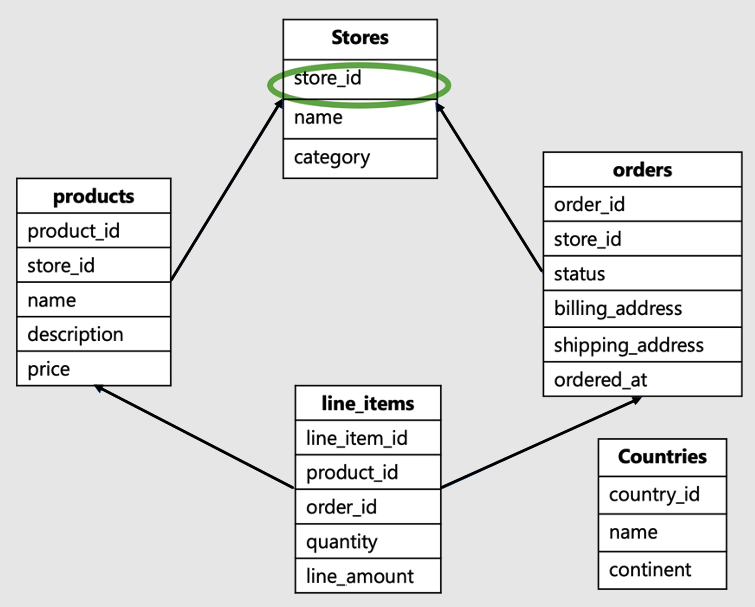
Dit gegevensmodel zou typisch zijn voor een bedrijf zoals Shopify. Het host sites voor meerdere online winkels, waar elke winkel communiceert met zijn eigen gegevens.
- Dit gegevensmodel bevat een aantal tabellen: winkels, producten, orders, regelitems en landen.
- De tabel Stores bevindt zich boven aan de hiërarchie. Producten, orders en regelitems zijn allemaal gekoppeld aan winkels, dus lager in de hiërarchie.
- De landentabel is niet gerelateerd aan afzonderlijke winkels, deze bevindt zich in alle winkels.
In dit voorbeeld, store_iddat zich boven aan de hiërarchie bevindt, is de id voor de tenant. Het is de juiste shardsleutel. Als u store_id kiest als de shardsleutel, kunnen gegevens in alle tabellen voor één opslag op één werkrol worden gebruikt.
Het coloceren van tabellen per archief heeft voordelen:
- Biedt SQL-dekking, zoals refererende sleutels, JOIN's. Transacties voor één tenant worden gelokaliseerd op één werkknooppunt waar elke tenant bestaat.
- Realiseert prestaties van één milliseconde. Query's voor één tenant worden gerouteerd naar één knooppunt in plaats van geparallelliseerd te worden, waardoor netwerkhops kunnen worden geoptimaliseerd en reken-/geheugenschaal nog steeds worden geschaald.
- Het schaalt. Naarmate het aantal tenants groeit, kunt u knooppunten toevoegen en de tenants opnieuw verdelen over nieuwe knooppunten, of zelfs grote tenants isoleren naar hun eigen knooppunten. Met tenantisolatie kunt u toegewezen resources leveren.
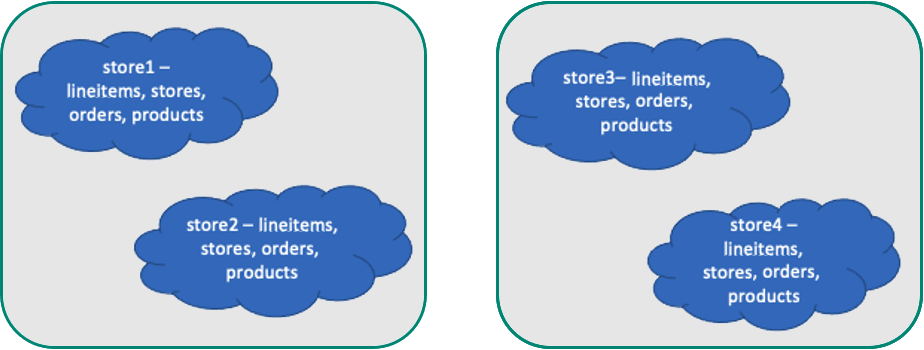
Optimaal gegevensmodel voor apps met meerdere tenants
In dit voorbeeld moeten we de winkelspecifieke tabellen distribueren op winkel-id en een referentietabel maken countries .
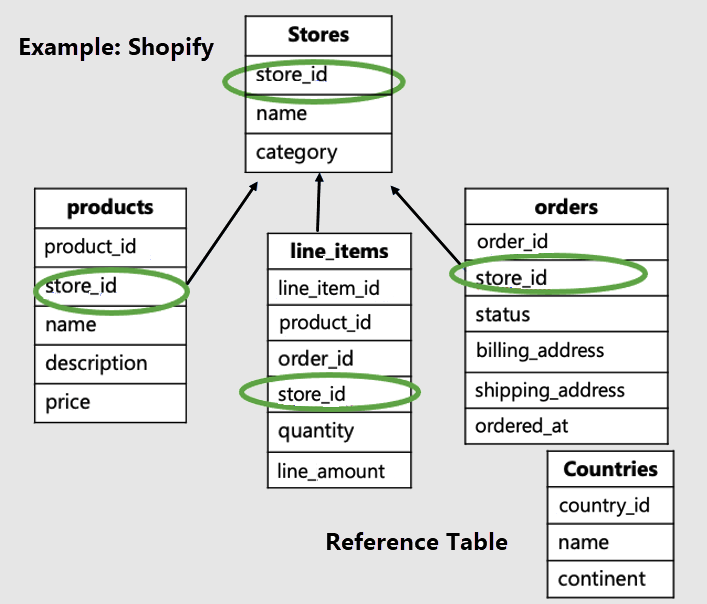
U ziet dat tenantspecifieke tabellen de tenant-id hebben en worden gedistribueerd. In ons voorbeeld worden winkels, producten en line_items gedistribueerd. De rest van de tabellen zijn referentietabellen. In ons voorbeeld is de tabel Landen een referentietabel.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Grote tabellen moeten allemaal de tenant-id hebben.
- Als u een bestaande app met meerdere tenants migreert naar Azure Cosmos DB for PostgreSQL, moet u mogelijk een beetje denormaliseren en de kolom tenant-id toevoegen aan grote tabellen als deze ontbreekt en de ontbrekende waarden van de kolom opnieuw doorvoeren.
- Zorg ervoor dat de tenant-id aanwezig is in alle tenantspecifieke tabellen voor nieuwe apps in Azure Cosmos DB for PostgreSQL.
Zorg ervoor dat u de tenant-id opneemt in beperkingen voor primaire, unieke en refererende sleutels voor gedistribueerde tabellen in de vorm van een samengestelde sleutel. Als een tabel bijvoorbeeld een primaire sleutel idheeft, kunt u deze omzetten in de samengestelde sleutel (tenant_id,id).
U hoeft geen sleutels voor referentietabellen te wijzigen.
Queryoverwegingen voor de beste prestaties
Gedistribueerde query's die op de tenant-id filteren, worden het efficiëntst uitgevoerd in apps met meerdere tenants. Zorg ervoor dat uw query's altijd zijn afgestemd op één tenant.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
Het is nodig om het tenant-id-filter toe te voegen, zelfs als de oorspronkelijke filtervoorwaarden de gewenste rijen ondubbelzinnig identificeren. Het tenant-id-filter, terwijl het schijnbaar redundant is, vertelt Azure Cosmos DB for PostgreSQL hoe de query naar één werkknooppunt moet worden gerouteerd.
Als u twee gedistribueerde tabellen samenvoegt, moet u er ook voor zorgen dat beide tabellen zijn afgestemd op één tenant. Het bereik kan worden uitgevoerd door ervoor te zorgen dat joinvoorwaarden de tenant-id bevatten.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
Er zijn helperbibliotheken voor verschillende populaire toepassingsframeworks waarmee u eenvoudig een tenant-id in query's kunt opnemen. Hier volgen instructies:
Volgende stappen
Nu zijn we klaar met het verkennen van gegevensmodellering voor schaalbare apps. De volgende stap is het verbinden en opvragen van de database met de programmeertaal van uw keuze.