Een-op-weinig relationele gegevens migreren naar een Azure Cosmos DB for NoSQL-account
VAN TOEPASSING OP: ![]() NoSQL
NoSQL
Als u wilt migreren van een relationele database naar Azure Cosmos DB for NoSQL, kan het nodig zijn om wijzigingen aan te brengen in het gegevensmodel voor optimalisatie.
Een veelvoorkomende transformatie is het denormaliseren van gegevens door gerelateerde subitems in te sluiten binnen één JSON-document. Hier kijken we naar een aantal opties hiervoor met behulp van Azure Data Factory of Azure Databricks. Zie gegevensmodellering in Azure Cosmos DB voor meer informatie over gegevensmodellering voor Azure Cosmos DB.
Voorbeeldscenario
Stel dat we de volgende twee tabellen hebben in onze SQL-database, Orders en OrderDetails.
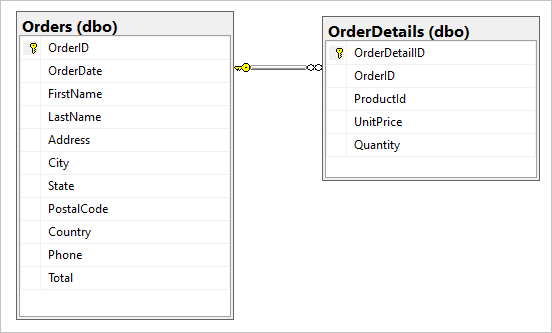
We willen deze een-op-weinig-relatie combineren tot één JSON-document tijdens de migratie. Als u één document wilt maken, maakt u een T-SQL-query met behulp van FOR JSON:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
De resultaten van deze query bevatten gegevens uit de tabel Orders :

In het ideale voorbeeld wilt u één ADF-kopieeractiviteit (Azure Data Factory) gebruiken om SQL-gegevens als bron op te vragen en de uitvoer rechtstreeks naar de Azure Cosmos DB-sink te schrijven als de juiste JSON-objecten. Momenteel is het niet mogelijk om de benodigde JSON-transformatie uit te voeren in één kopieeractiviteit. Als we de resultaten van de bovenstaande query proberen te kopiëren naar een Azure Cosmos DB for NoSQL-container, zien we het veld OrderDetails als een tekenreekseigenschap van ons document in plaats van de verwachte JSON-matrix.
We kunnen deze huidige beperking omzeilen op een van de volgende manieren:
- Azure Data Factory gebruiken met twee kopieeractiviteiten:
- JSON-geformatteerde gegevens ophalen van SQL naar een tekstbestand in een tussenliggende blobopslaglocatie
- Laad gegevens uit het JSON-tekstbestand naar een container in Azure Cosmos DB.
- Gebruik Azure Databricks om te lezen van SQL en schrijven naar Azure Cosmos DB . We presenteren hier twee opties.
Laten we deze benaderingen nader bekijken:
Azure Data Factory
Hoewel we OrderDetails niet kunnen insluiten als een JSON-matrix in het Azure Cosmos DB-doeldocument, kunnen we het probleem omzeilen door twee afzonderlijke kopieeractiviteiten te gebruiken.
Kopieeractiviteit 1: SqlJsonToBlobText
Voor de brongegevens gebruiken we een SQL-query om de resultatenset op te halen als één kolom met één JSON-object (die de volgorde vertegenwoordigt) per rij met behulp van de MOGELIJKHEDEN VAN SQL Server OPENJSON en FOR JSON PATH:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
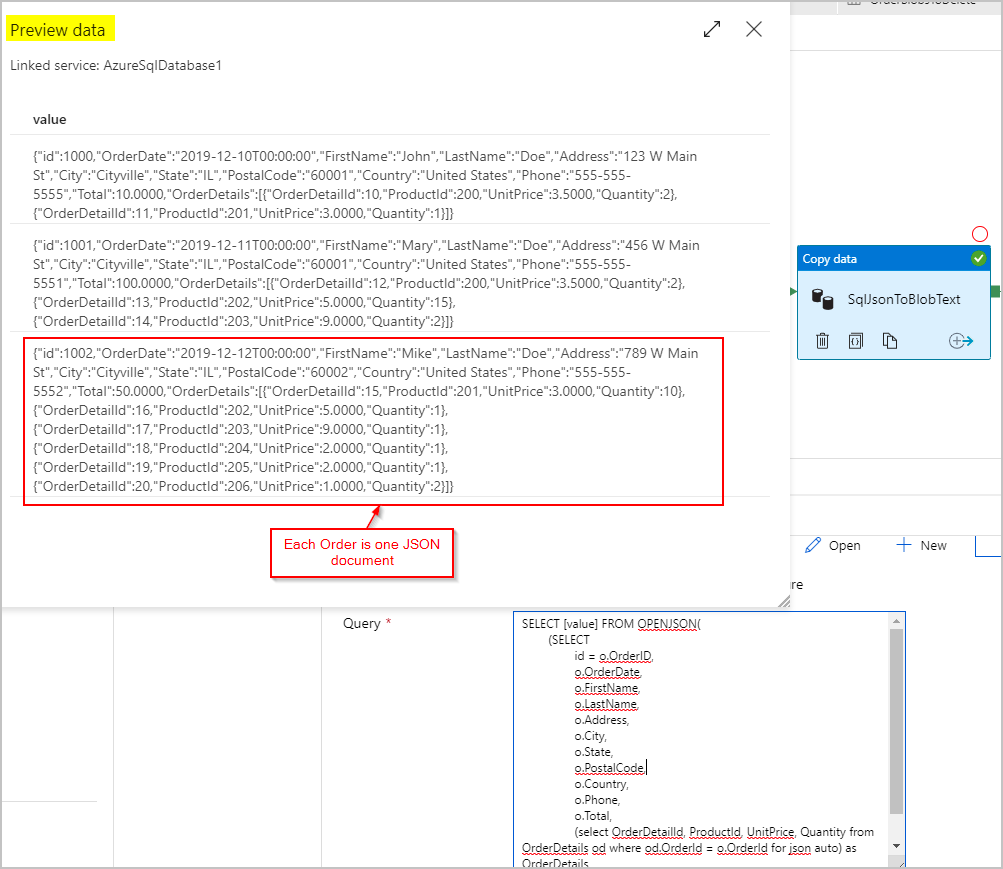
Voor de sink van de SqlJsonToBlobText kopieeractiviteit kiezen we 'Tekst met scheidingstekens' en wijzen we deze naar een specifieke map in Azure Blob Storage. Deze sink bevat een dynamisch gegenereerde unieke bestandsnaam (bijvoorbeeld @concat(pipeline().RunId,'.json').
Omdat ons tekstbestand niet echt 'gescheiden' is en we niet willen dat het in afzonderlijke kolommen wordt geparseerd met komma's. We willen ook de dubbele aanhalingstekens () behouden, 'Kolomscheidingsteken' instellen op een tab (\t) of een ander teken dat niet in de gegevens voorkomt en 'Aanhalingsteken' instellen op 'Geen aanhalingsteken'.
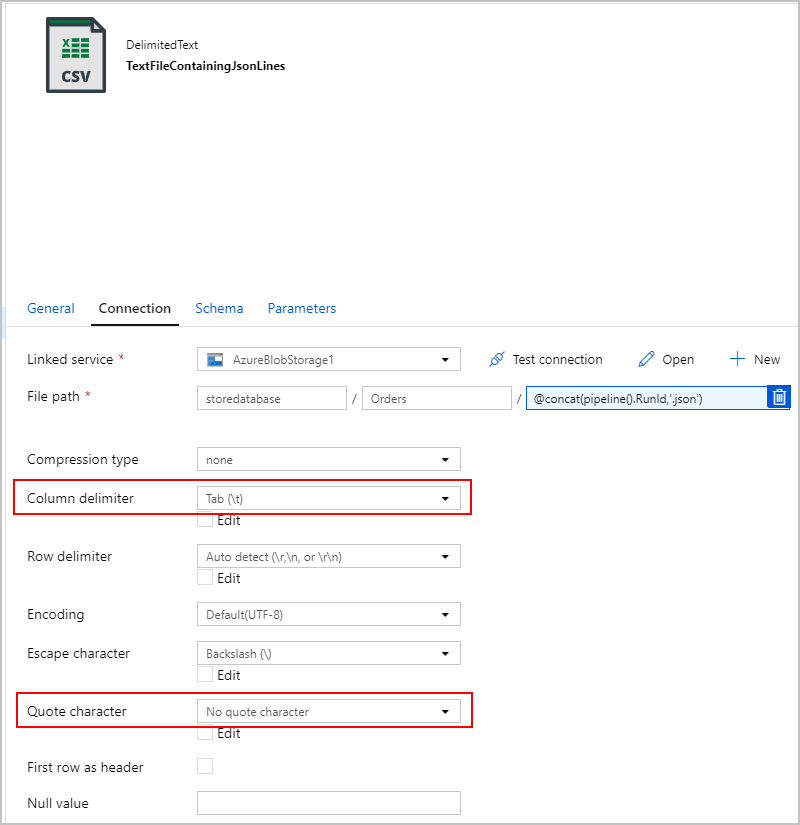
Kopieeractiviteit 2: BlobJsonToCosmos
Vervolgens wijzigen we onze ADF-pijplijn door de tweede kopieeractiviteit toe te voegen die in Azure Blob Storage zoekt naar het tekstbestand dat door de eerste activiteit is gemaakt. Het verwerkt deze als JSON-bron om in te voegen in de Azure Cosmos DB-sink als één document per JSON-rij in het tekstbestand.
Desgewenst voegen we ook een 'Delete'-activiteit toe aan de pijplijn, zodat alle vorige bestanden die nog in de map /Orders/ staan, worden verwijderd voordat elke uitvoering wordt uitgevoerd. Onze ADF-pijplijn ziet er nu ongeveer als volgt uit:
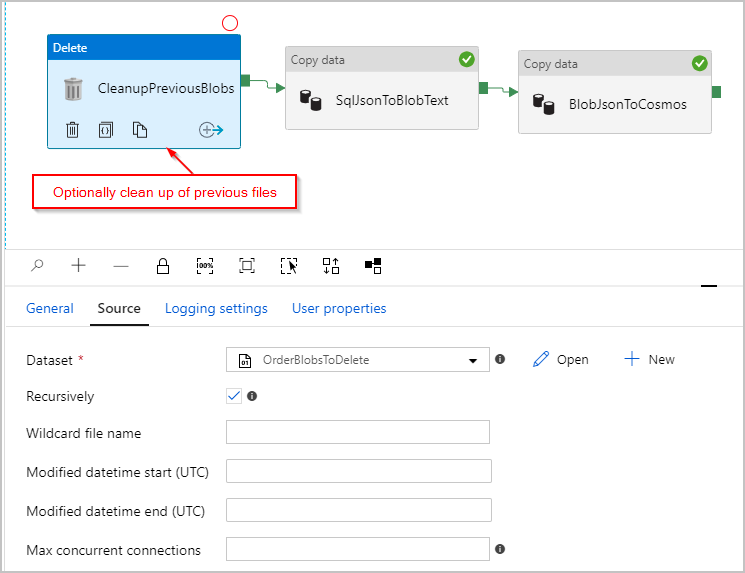
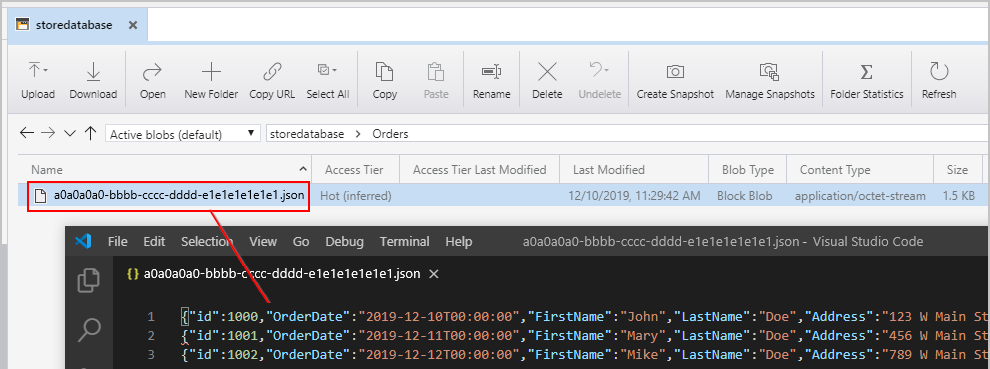
Nadat we de eerder genoemde pijplijn hebben geactiveerd, zien we een bestand dat is gemaakt in onze tussenliggende Azure Blob Storage-locatie met één JSON-object per rij:
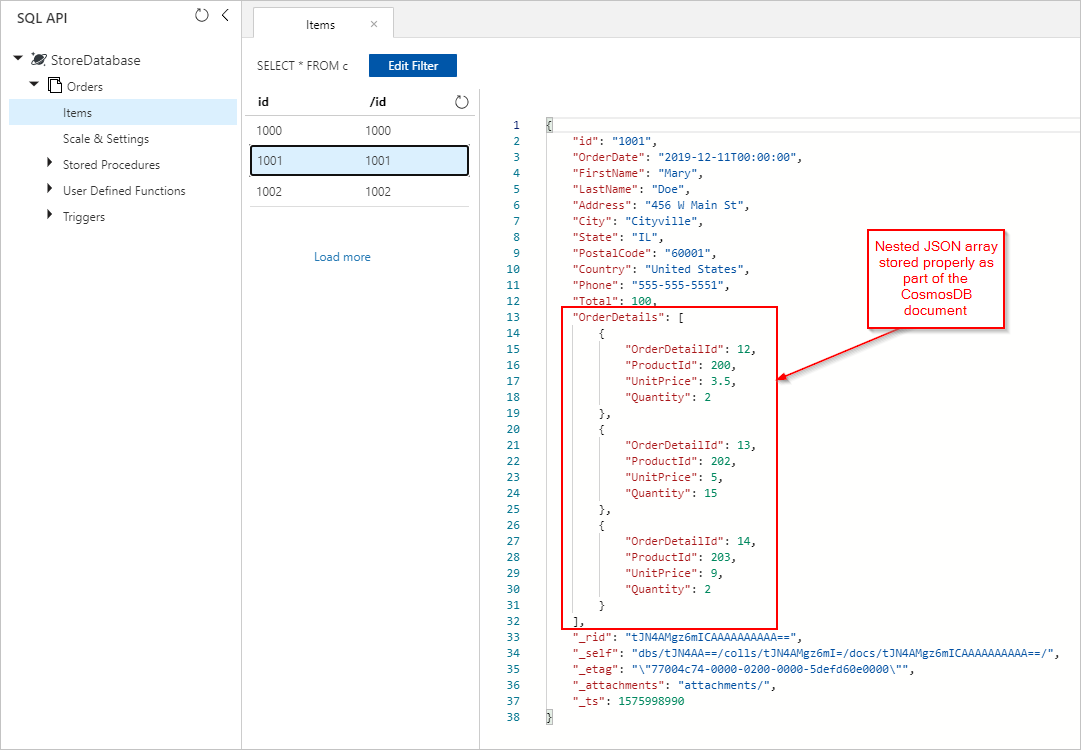
We zien ook ordersdocumenten met correct ingesloten OrderDetails die zijn ingevoegd in onze Azure Cosmos DB-verzameling:
Azure Databricks
We kunnen Spark in Azure Databricks ook gebruiken om de gegevens van onze SQL Database-bron naar de Azure Cosmos DB-bestemming te kopiëren zonder de tussenliggende tekst-/JSON-bestanden in Azure Blob Storage te maken.
Notitie
Ter duidelijkheid en eenvoud bevatten de codefragmenten dummy-databasewachtwoorden expliciet inline, maar u moet in het ideale geval Azure Databricks-geheimen gebruiken.
Eerst maken en koppelen we de vereiste SQL-connector - en Azure Cosmos DB-connectorbibliotheken aan ons Azure Databricks-cluster. Start het cluster opnieuw op om ervoor te zorgen dat bibliotheken zijn geladen.

Vervolgens presenteren we twee voorbeelden voor Scala en Python.
Scala
Hier krijgen we de resultaten van de SQL-query met 'FOR JSON'-uitvoer in een DataFrame:
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
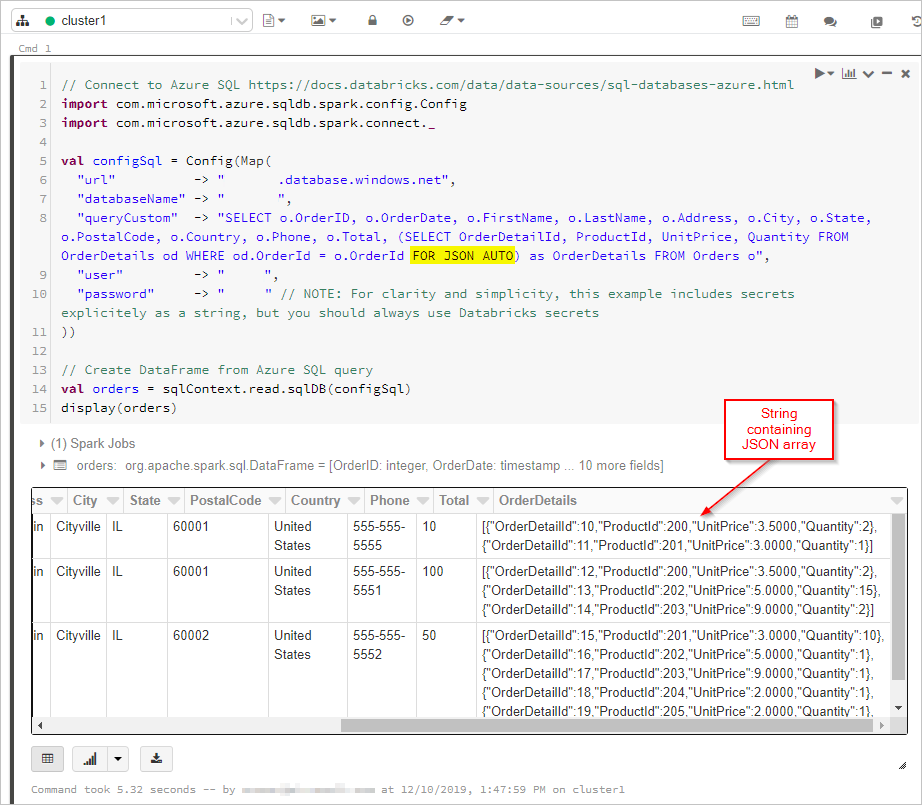
Vervolgens maken we verbinding met onze Azure Cosmos DB-database en -verzameling:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
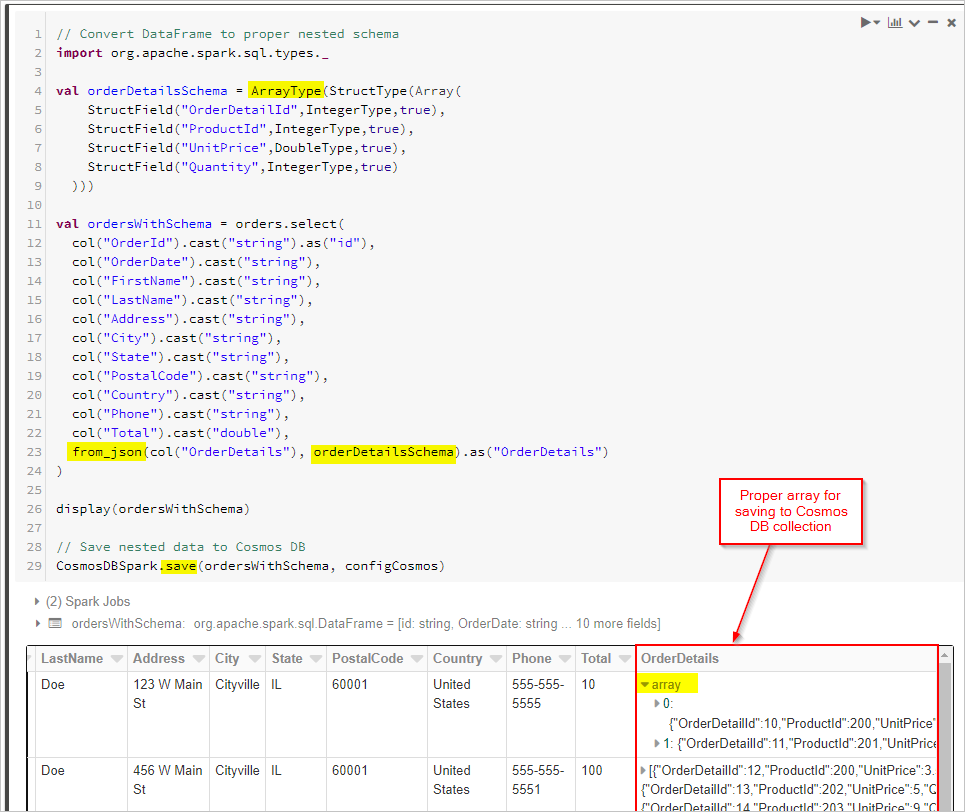
Ten slotte definiëren we ons schema en gebruiken we from_json om het DataFrame toe te passen voordat we het opslaan in de Cosmos DB-verzameling.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
Als alternatief moet u mogelijk JSON-transformaties uitvoeren in Spark als de brondatabase geen ondersteuning biedt FOR JSON voor of een vergelijkbare bewerking. U kunt ook parallelle bewerkingen gebruiken voor een grote gegevensset. Hier presenteren we een PySpark-voorbeeld. Begin met het configureren van de bron- en doeldatabaseverbindingen in de eerste cel:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Vervolgens voeren we een query uit op de brondatabase (in dit geval SQL Server) voor zowel de order- als orderdetailrecords, waarbij de resultaten in Spark Dataframes worden geplaatst. We maken ook een lijst met alle order-id's en een threadpool voor parallelle bewerkingen:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Maak vervolgens een functie voor het schrijven van orders in de doel-API voor noSQL-verzameling. Met deze functie worden alle ordergegevens voor de opgegeven order-id gefilterd, geconverteerd naar een JSON-matrix en wordt de matrix ingevoegd in een JSON-document. Het JSON-document wordt vervolgens voor die volgorde naar de doel-API voor NoSQL-container geschreven:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Ten slotte roepen we de Python-functie writeOrder aan met behulp van een kaartfunctie in de thread-pool om parallel uit te voeren, waarbij de lijst met volgorde-id's wordt doorgegeven die we eerder hebben gemaakt:
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
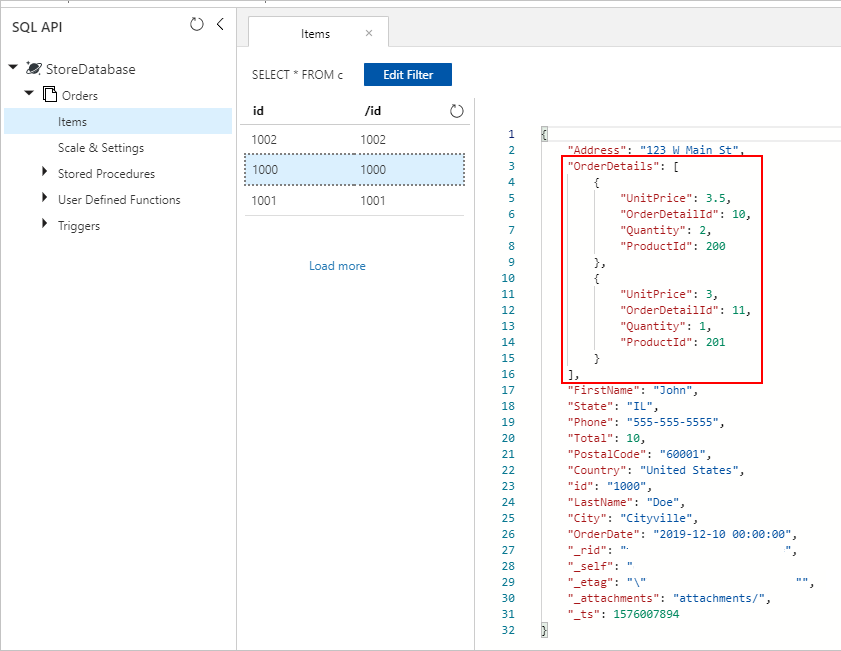
Aan het einde van beide benaderingen moeten we ingesloten orderdetails in elk orderdocument in de Azure Cosmos DB-verzameling op de juiste manier opslaan:
Volgende stappen
- Meer informatie over gegevensmodellering in Azure Cosmos DB
- Meer informatie over het modelleren en partitioneren van gegevens in Azure Cosmos DB