Indexeringsbeleid in Azure Cosmos DB beheren
In Azure Cosmos DB worden gegevens geïndexeerd volgens indexeringsbeleidsregels die zijn gedefinieerd voor elke container. Het standaardindexeringsbeleid voor nieuw gemaakte containers dwingt bereikindexen af voor een willekeurige tekenreeks of een willekeurig getal. U kunt dit beleid overschrijven met uw eigen aangepast indexeringsbeleid.
Notitie
De methode voor het bijwerken van indexeringsbeleid dat in dit artikel wordt beschreven, is alleen van toepassing op Azure Cosmos DB voor NoSQL. Meer informatie over indexering in Azure Cosmos DB voor MongoDB en secundaire indexering in Azure Cosmos DB voor Apache Cassandra.
Voorbeelden van indexeringsbeleid
Hier volgen enkele voorbeelden van indexeringsbeleid dat wordt weergegeven in de JSON-indeling. Ze worden weergegeven in Azure Portal in JSON-indeling. Dezelfde parameters kunnen worden ingesteld via de Azure CLI of elke SDK.
Opt-outbeleid om selectief bepaalde eigenschapspaden uit te sluiten
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Opt-in-beleid om selectief bepaalde eigenschapspaden op te nemen
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Notitie
Over het algemeen wordt u aangeraden een opt-out-indexeringsbeleid te gebruiken. Azure Cosmos DB indexeert proactief alle nieuwe eigenschappen die kunnen worden toegevoegd aan uw gegevensmodel.
Alleen een ruimtelijke index gebruiken op een specifiek eigenschapspad
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Voorbeelden van vectorindexeringsbeleid
Naast het opnemen of uitsluiten van paden voor afzonderlijke eigenschappen, kunt u ook een vectorindex opgeven. In het algemeen moeten vectorindexen worden opgegeven wanneer de VectorDistance systeemfunctie wordt gebruikt om overeenkomsten tussen een queryvector en een vectoreigenschap te meten.
Notitie
Voordat u doorgaat, moet u azure Cosmos DB NoSQL Vector Indexering en Search inschakelen.
Belangrijk
Een vectorindexeringsbeleid moet zich op hetzelfde pad bevinden dat is gedefinieerd in het vectorbeleid van de container. Meer informatie over containervectorbeleid.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Belangrijk
Het vectorpad is toegevoegd aan de sectie 'excludedPaths' van het indexeringsbeleid om te zorgen voor geoptimaliseerde prestaties voor invoeging. Als u het vectorpad niet toevoegt aan 'excludedPaths', leidt dit tot hogere RU-kosten en latentie voor vectorinvoegingen.
Belangrijk
Op dit moment zijn vectorbeleid en vectorindexen onveranderbaar na het maken. Als u wijzigingen wilt aanbrengen, maakt u een nieuwe verzameling.
U kunt de volgende typen vectorindexbeleid definiëren:
| Type | Description | Maximumdimensies |
|---|---|---|
flat |
Slaat vectoren op dezelfde index op als andere geïndexeerde eigenschappen. | 505 |
quantizedFlat |
Kwantificeert vectoren (comprimeert) voordat deze op de index worden opgeslagen. Dit kan de latentie en doorvoer verbeteren ten koste van een kleine hoeveelheid nauwkeurigheid. | 4096 |
diskANN |
Hiermee maakt u een index op basis van DiskANN voor snelle en efficiënte zoekopdrachten. | 4096 |
De flat indextypen en quantizedFlat indextypen maken gebruik van de index van Azure Cosmos DB om elke vector op te slaan en te lezen bij het uitvoeren van een vectorzoekopdracht. Vectorzoekopdrachten met een flat index zijn brute-force zoekopdrachten en produceren 100% nauwkeurigheid. Er is echter een beperking van 505 dimensies voor vectoren op een platte index.
De quantizedFlat index slaat gekwantiseerde of gecomprimeerde vectoren op de index op. Vectorzoekopdrachten met quantizedFlat indexen zijn ook brute-force zoekopdrachten, maar hun nauwkeurigheid kan iets minder zijn dan 100% omdat de vectoren worden gekwantiseerd voordat ze aan de index worden toegevoegd. Vectorzoekopdrachten met quantized flat moeten echter lagere latentie, hogere doorvoer en lagere RU-kosten hebben dan vectorzoekopdrachten in een flat index. Dit is een goede optie voor scenario's waarbij u queryfilters gebruikt om de vectorzoekopdracht te beperken tot een relatief kleine set vectoren.
De diskANN index is een afzonderlijke index die specifiek is gedefinieerd voor vectoren die gebruikmaken van DiskANN, een suite met zeer presterende vectorindexeringsalgoritmen die zijn ontwikkeld door Microsoft Research. DiskANN-indexen kunnen een aantal van de laagste latentie, hoogste query per seconde (QPS) en laagste RU-kostenquery's met hoge nauwkeurigheid bieden. Omdat DiskANN echter een dichtstbijzijnde burenindex (ANN) is, kan de nauwkeurigheid lager zijn dan quantizedFlat of flat.
De diskANN en quantizedFlat indexen kunnen optionele indexbuildparameters aannemen die kunnen worden gebruikt om de nauwkeurigheid en latentie af te stemmen die van toepassing zijn op elke geschatte vectorindex dichtstbijzijnde buren.
quantizationByteSize: Hiermee stelt u de grootte (in bytes) in voor product kwantisatie. Min=1, Standaard=dynamisch (systeem bepaalt), Max=512. Als u deze grotere instelling instelt, kan dit leiden tot zoekopdrachten met een hogere nauwkeurigheidsvector ten koste van hogere RU-kosten en hogere latentie. Dit geldt voor zowelquantizedFlatalsDiskANNindextypen.indexingSearchListSize: Hiermee stelt u het aantal vectoren in dat moet worden doorzocht tijdens de bouw van de index. Min=10, Default=100, Max=500. Als u deze grotere instelling instelt, kan dit leiden tot zoekopdrachten met een hogere nauwkeurigheidsvector ten koste van langere opbouwtijden van indexen en hogere latenties voor vectoropnamen. Dit geldt alleen voorDiskANNindexen.
Voorbeelden van tuple-indexeringsbeleid
Dit voorbeeld van indexeringsbeleid definieert een tuple-index op events.name en events.category
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
De bovenstaande index wordt gebruikt voor de onderstaande query.
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
Voorbeelden van samengesteld indexeringsbeleid
Naast het opnemen of uitsluiten van paden voor afzonderlijke eigenschappen, kunt u ook een samengestelde index opgeven. Als u een query met een ORDER BY component voor meerdere eigenschappen wilt uitvoeren, is een samengestelde index vereist voor deze eigenschappen. Als de query filters bevat, samen met sorteren op meerdere eigenschappen, hebt u mogelijk meer dan één samengestelde index nodig.
Samengestelde indexen hebben ook een prestatievoordeel voor query's met meerdere filters of zowel een filter als een ORDER BY-component.
Notitie
Samengestelde paden hebben een impliciete /? waarde omdat alleen de scalaire waarde op dat pad wordt geïndexeerd. Het /* jokerteken wordt niet ondersteund in samengestelde paden. U moet geen samengesteld pad opgeven /? of /* opnemen. Samengestelde paden zijn ook hoofdlettergevoelig.
Samengestelde index gedefinieerd voor (naam asc, leeftijdsdesc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
De samengestelde index op naam en leeftijd is vereist voor de volgende query's:
Query 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Query 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Deze samengestelde index profiteert van de volgende query's en optimaliseert de filters:
Query 3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Query 4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Samengestelde index gedefinieerd voor (naam ASC, leeftijd ASC) en (naam ASC, leeftijd DESC)
U kunt meerdere samengestelde indexen definiëren binnen hetzelfde indexeringsbeleid.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Samengestelde index gedefinieerd voor (naam ASC, leeftijd ASC)
Het is optioneel om de bestelling op te geven. Als dit niet is opgegeven, wordt de volgorde oplopend.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Alle eigenschapspaden uitsluiten, maar indexering actief houden
U kunt dit beleid gebruiken waarbij de TTL-functie (Time-to-Live) actief is, maar er geen andere indexen nodig zijn om Azure Cosmos DB te gebruiken als een puur sleutel-waardearchief.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Geen indexering
Met dit beleid wordt indexering uitgeschakeld. Als indexingMode dit is ingesteld noneop, kunt u geen TTL instellen voor de container.
{
"indexingMode": "none"
}
Indexeringsbeleid bijwerken
In Azure Cosmos DB kan het indexeringsbeleid worden bijgewerkt met een van de volgende methoden:
- Vanuit Azure Portal
- Met gebruik van de Azure CLI
- PowerShell gebruiken
- Een van de SDK's gebruiken
Een indexeringsbeleidsupdate activeert een indextransformatie. De voortgang van deze transformatie kan ook worden bijgehouden vanuit de SDK's.
Notitie
Wanneer u het indexeringsbeleid bijwerkt, worden schrijfbewerkingen naar Azure Cosmos DB ononderbroken uitgevoerd. Meer informatie over indexeringstransformaties.
Belangrijk
Het verwijderen van een index wordt onmiddellijk van kracht, terwijl het toevoegen van een nieuwe index enige tijd in beslag neemt omdat er een indexeringstransformatie nodig is. Wanneer u de ene index vervangt door een andere index (bijvoorbeeld door één eigenschapsindex te vervangen door een samengestelde index), moet u eerst de nieuwe index toevoegen en vervolgens wachten tot de indextransformatie is voltooid voordat u de vorige index verwijdert uit het indexeringsbeleid. Anders heeft dit een negatieve invloed op de mogelijkheid om een query uit te voeren op de vorige index en kunnen actieve workloads die naar de vorige index verwijzen, worden verbroken.
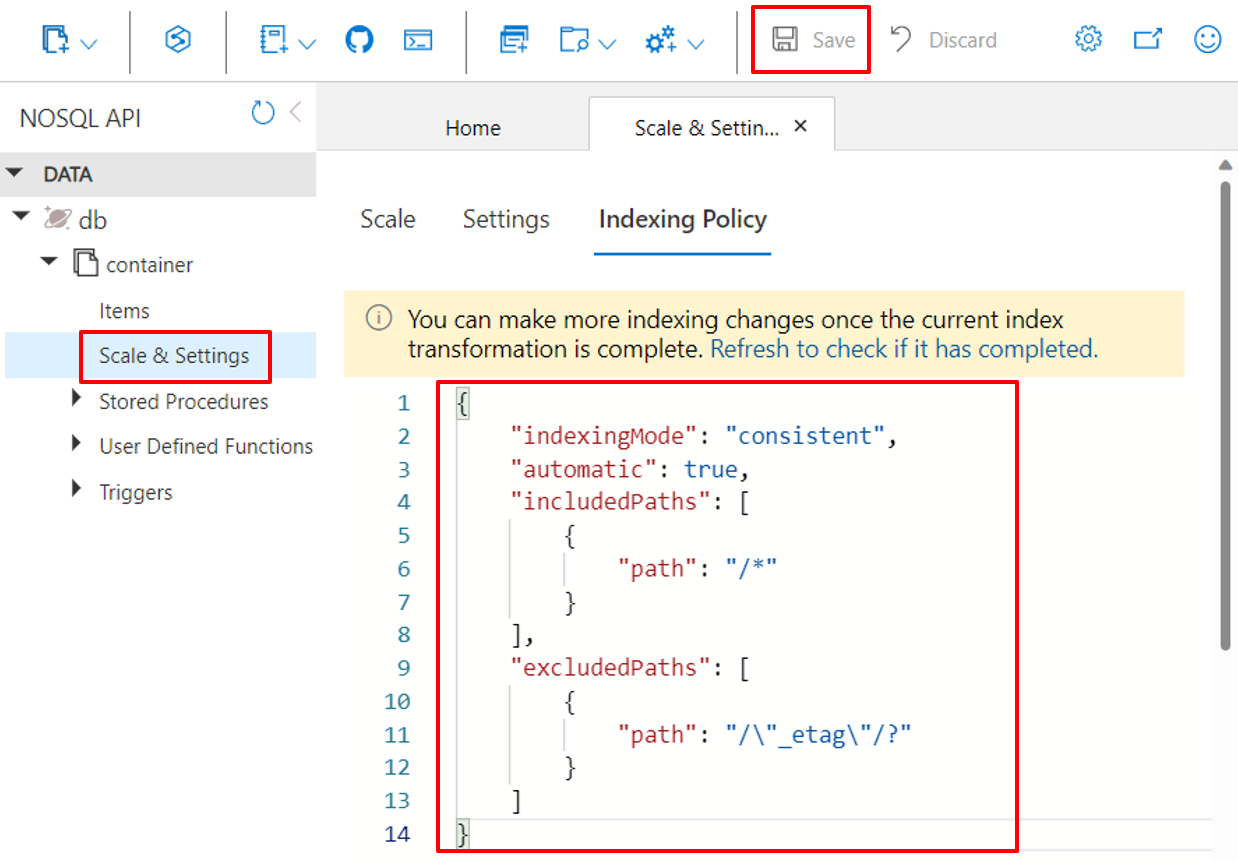
De Azure-portal gebruiken
Azure Cosmos DB-containers slaan hun indexeringsbeleid op als een JSON-document waarmee u rechtstreeks kunt bewerken in Azure Portal.
Meld u aan bij het Azure-portaal.
Maak een nieuw Azure Cosmos DB-account of selecteer een bestaand account.
Open het deelvenster Data Explorer en selecteer de container waaraan u wilt werken.
Selecteer Schalen en instellingen.
Wijzig het JSON-document voor indexeringsbeleid, zoals wordt weergegeven in deze voorbeelden.
Kies Opslaan wanneer u klaar bent.
De Azure CLI gebruiken
Zie Een container met een aangepast indexeringsbeleid maken met een aangepast indexeringsbeleid met behulp van CLI om een container te maken.
PowerShell gebruiken
Zie Een container maken met een aangepast indexeringsbeleid met behulp van PowerShell om een container te maken met een aangepast indexbeleid.
.NET-SDK gebruiken
Het ContainerProperties object van de .NET SDK v3 maakt een IndexingPolicy eigenschap beschikbaar waarmee u de IndexingMode eigenschap kunt wijzigen en toevoegen of verwijderen IncludedPaths en ExcludedPaths. Zie quickstart: Azure Cosmos DB for NoSQL-clientbibliotheek voor .NET voor meer informatie.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Als u de voortgang van de indextransformatie wilt bijhouden, geeft u een RequestOptions object door waarop de PopulateQuotaInfo eigenschap truewordt ingesteld. Haal de waarde op uit de x-ms-documentdb-collection-index-transformation-progress antwoordheader.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Met de SDK V3 fluent-API kunt u deze definitie op een beknopte en efficiënte manier schrijven bij het definiëren van een aangepast indexeringsbeleid tijdens het maken van een nieuwe container:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
De Java SDK gebruiken
Het DocumentCollection object van de Java SDK maakt de getIndexingPolicy() en setIndexingPolicy() methoden beschikbaar. Met IndexingPolicy het object dat ze bewerken, kunt u de indexeringsmodus wijzigen en opgenomen en uitgesloten paden toevoegen of verwijderen. Zie quickstart: Een Java-app bouwen om Azure Cosmos DB for NoSQL-gegevens te beheren voor meer informatie.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Als u de voortgang van de indextransformatie voor een container wilt bijhouden, geeft u een RequestOptions object door dat de quotumgegevens aanvraagt om te worden ingevuld. Haal de waarde op uit de x-ms-documentdb-collection-index-transformation-progress antwoordheader.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
De Node.js SDK gebruiken
De ContainerDefinition interface van Node.js SDK bevat een indexingPolicy eigenschap waarmee u de indexingMode eigenschap kunt wijzigen en toevoegen of verwijderen includedPaths en excludedPaths. Zie Quickstart : Azure Cosmos DB for NoSQL-clientbibliotheek voor Node.js voor meer informatie.
De details van de container ophalen:
const containerResponse = await client.database('database').container('container').read();
Stel de indexeringsmodus in op consistent:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Opgenomen pad toevoegen, inclusief een ruimtelijke index:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Uitgesloten pad toevoegen:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Werk de container bij met wijzigingen:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Als u de voortgang van de indextransformatie voor een container wilt bijhouden, geeft u een RequestOptions object door waarop de populateQuotaInfo eigenschap trueis ingesteld. Haal de waarde op uit de x-ms-documentdb-collection-index-transformation-progress antwoordheader.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Een samengestelde index toevoegen:
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
De Python-SDK gebruiken
Wanneer u de Python SDK V3 gebruikt, wordt de containerconfiguratie beheerd als een woordenlijst. Vanuit deze woordenlijst hebt u toegang tot het indexeringsbeleid en alle bijbehorende kenmerken. Zie quickstart: Azure Cosmos DB for NoSQL-clientbibliotheek voor Python voor meer informatie.
De details van de container ophalen:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Stel de indexeringsmodus in op consistent:
container['indexingPolicy']['indexingMode'] = 'consistent'
Definieer een indexeringsbeleid met een opgenomen pad en een ruimtelijke index:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Een indexeringsbeleid definiëren met een uitgesloten pad:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Een samengestelde index toevoegen:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Werk de container bij met wijzigingen:
response = client.ReplaceContainer(containerPath, container)