Ai-verbeterde advertentiegeneratie met behulp van Azure Cosmos DB voor MongoDB vCore
In deze handleiding laten we zien hoe u dynamische advertentie-inhoud maakt die resoneert met uw publiek, met behulp van onze persoonlijke AI-assistent, Heelie. Door gebruik te maken van Azure Cosmos DB voor MongoDB vCore gebruiken we de zoekfunctionaliteit voor vectorovereenkomsten om semantisch te analyseren en inventarisbeschrijvingen te vergelijken met advertentieonderwerpen. Het proces wordt mogelijk gemaakt door vectoren te genereren voor inventarisbeschrijvingen met behulp van OpenAI-insluitingen, waardoor hun semantische diepte aanzienlijk wordt verbeterd. Deze vectoren worden vervolgens opgeslagen en geïndexeerd in de Cosmos DB voor MongoDB vCore-resource. Bij het genereren van inhoud voor advertenties, vectoriseren we het advertentieonderwerp om de best overeenkomende voorraaditems te vinden. Dit wordt gevolgd door een ophaalproces van augmented generation (RAG), waarbij de topovereenkomsten naar OpenAI worden verzonden om een aantrekkelijke advertentie te maken. De volledige codebasis voor de toepassing is beschikbaar in een GitHub-opslagplaats voor uw referentie.
Functies
- Vector Similarity Search: maakt gebruik van Azure Cosmos DB voor de krachtige vector-overeenkomstenzoekfunctie van MongoDB vCore om semantische zoekmogelijkheden te verbeteren, zodat u gemakkelijker relevante inventarisitems kunt vinden op basis van de inhoud van advertenties.
- OpenAI Embeddings: maakt gebruik van de geavanceerde insluitingen van OpenAI om vectoren te genereren voor inventarisbeschrijvingen. Deze benadering maakt genuanceerde en semantisch rijke overeenkomsten mogelijk tussen de inventaris en de advertentie-inhoud.
- Inhoudsgeneratie: maakt gebruik van de geavanceerde taalmodellen van OpenAI om aantrekkelijke, trendgerichte advertenties te genereren. Deze methode zorgt ervoor dat de inhoud niet alleen relevant is, maar ook interessant is voor de doelgroep.
Vereisten
- Azure OpenAI: We gaan de Azure OpenAI-resource instellen. Toegang tot deze service is momenteel alleen beschikbaar per toepassing. U kunt toegang tot Azure OpenAI aanvragen door het formulier in te vullen op https://aka.ms/oai/access. Nadat u toegang hebt, voert u de volgende stappen uit:
- Maak een Azure OpenAI-resource volgens deze quickstart.
completionsEen en eenembeddingsmodel implementeren.- Noteer uw eindpunt-, sleutel- en implementatienamen.
- Cosmos DB voor MongoDB vCore-resource: Laten we beginnen met het maken van een Azure Cosmos DB voor MongoDB vCore-resource gratis aan de hand van deze snelstartgids .
- Noteer de verbindingsgegevens.
- Python-omgeving (>= 3.9-versie) met pakketten zoals
numpy, ,pymongoopenai,python-dotenv,azure-core, ,azure-cosmosentenacitygradio. - Download het gegevensbestand en sla het op in een aangewezen gegevensmap.
Het script uitvoeren
Voordat we ingaan op het spannende deel van het genereren van ai-verbeterde advertenties, moeten we onze omgeving instellen. Deze installatie omvat het installeren van de benodigde pakketten om ervoor te zorgen dat ons script soepel verloopt. Hier volgt een stapsgewijze handleiding om alles voor te bereiden.
1.1 Vereiste pakketten installeren
Ten eerste moeten we enkele Python-pakketten installeren. Open de terminal en voer de volgende opdrachten uit:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 De OpenAI- en Azure-client instellen
Na de installatie van de benodigde pakketten moet u in de volgende stap onze OpenAI- en Azure-clients instellen voor het script. Dit is van cruciaal belang voor het verifiëren van onze aanvragen voor de OpenAI-API en Azure-services.
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
Architectuur voor de oplossing
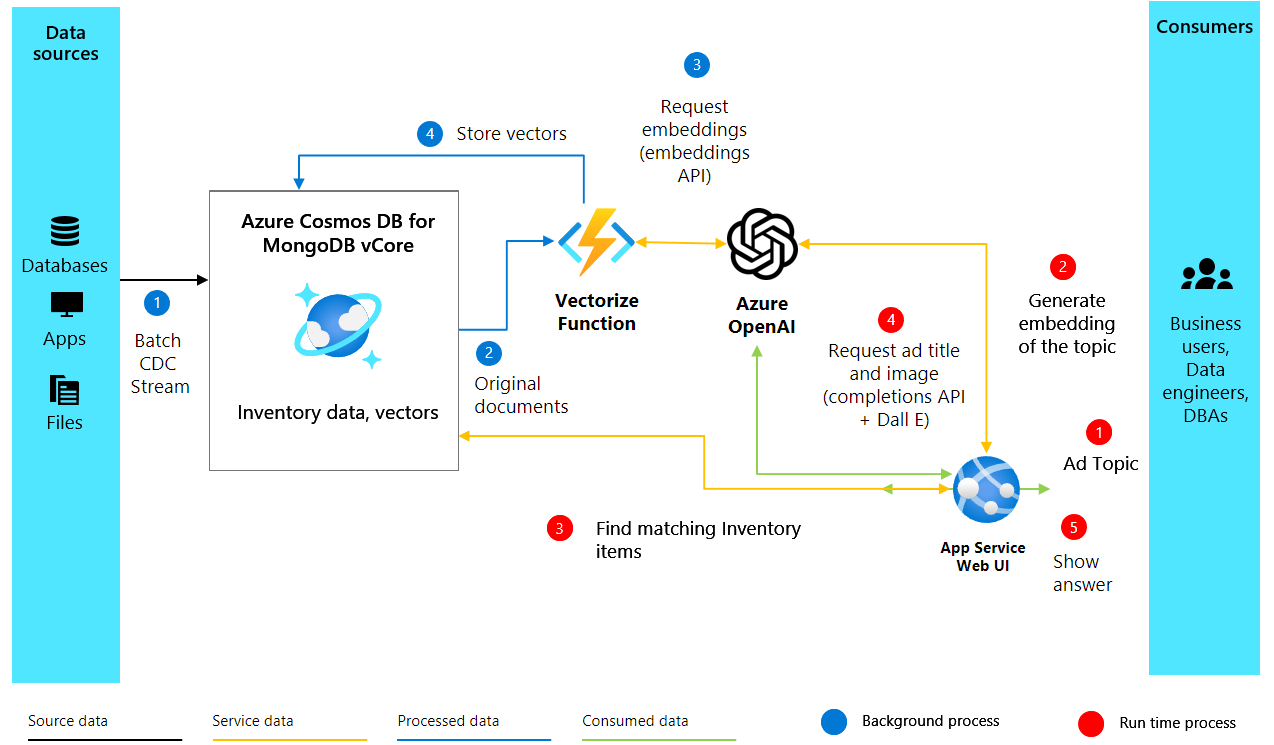
2. Insluitingen maken en Cosmos DB instellen
Na het instellen van onze omgeving en OpenAI-client gaan we over naar het kernonderdeel van ons ai-verbeterde advertentiegeneratieproject. Met de volgende code worden vector insluitingen gemaakt van tekstbeschrijvingen van producten en wordt onze database in Azure Cosmos DB voor MongoDB vCore ingesteld om deze insluitingen op te slaan en te doorzoeken.
2.1 Insluitingen maken
Om aantrekkelijke advertenties te genereren, moeten we eerst de artikelen in onze voorraad begrijpen. We doen dit door vector insluitingen te maken van beschrijvingen van onze items, zodat we hun semantische betekenis kunnen vastleggen in een vorm die machines kunnen begrijpen en verwerken. U kunt als volgt vector-insluitingen maken voor een beschrijving van een item met behulp van Azure OpenAI:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
De functie gebruikt een tekstinvoer, zoals een productbeschrijving, en gebruikt de client.embeddings.create methode van de OpenAI-API om een vector insluiten voor die tekst te genereren. We gebruiken het text-embedding-ada-002 model hier, maar u kunt andere modellen kiezen op basis van uw vereisten. Als het proces is geslaagd, worden de gegenereerde insluitingen afgedrukt; anders worden uitzonderingen verwerkt door een foutbericht af te drukken.
3. Verbinding maken en Cosmos DB instellen voor MongoDB vCore
Nu onze insluitingen klaar zijn, is de volgende stap het opslaan en indexeren ervan in een database die vector-overeenkomsten zoeken ondersteunt. Azure Cosmos DB voor MongoDB vCore is perfect geschikt voor deze taak, omdat het doel is gebouwd om uw transactionele gegevens op te slaan en vectorzoekopdrachten op één plaats uit te voeren.
3.1 De verbinding instellen
Om verbinding te maken met Cosmos DB, gebruiken we de pymongo-bibliotheek, waarmee we eenvoudig met MongoDB kunnen communiceren. Met het volgende codefragment wordt een verbinding tot stand gebracht met ons Cosmos DB for MongoDB vCore-exemplaar:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
Vervang , <PASSWORD>en <VCORE_CLUSTER_NAME> door <USERNAME>respectievelijk uw werkelijke MongoDB-gebruikersnaam, wachtwoord en vCore-clusternaam.
4. De database- en vectorindex instellen in Cosmos DB
Zodra u een verbinding met Azure Cosmos DB tot stand hebt gebracht, zijn de volgende stappen nodig om uw database en verzameling in te stellen en vervolgens een vectorindex te maken om efficiënte vectorkoppelingen mogelijk te maken. Laten we deze stappen doorlopen.
4.1 De database en verzameling instellen
Eerst maken we een database en een verzameling in ons Cosmos DB-exemplaar. U doet dit als volgt:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 De vectorindex maken
Voor het uitvoeren van efficiënte vector overeenkomsten zoekopdrachten binnen onze verzameling, moeten we een vectorindex maken. Cosmos DB ondersteunt verschillende typen vectorindexen, en hier bespreken we twee: IVF en HNSW.
IVF
IVF staat voor Inverted File Index, is het standaard algoritme voor vectorindexering, dat werkt op alle clusterlagen. Het is een benadering van dichtstbijzijnde buren (ANN) die gebruikmaakt van clustering om het zoeken naar vergelijkbare vectoren in een gegevensset te versnellen. Gebruik de volgende opdracht om een IVF-index te maken:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
Belangrijk
U kunt slechts één index per vectoreigenschap maken. Dat wil gezegd, u kunt niet meer dan één index maken die verwijst naar dezelfde vectoreigenschap. Als u het indextype (bijvoorbeeld van IVF naar HNSW) wilt wijzigen, moet u de index eerst verwijderen voordat u een nieuwe index maakt.
HNSW
HNSW staat voor Hierarchical Navigable Small World, een grafiekgebaseerde gegevensstructuur die vectoren partitioneert in clusters en subclusters. Met HNSW kunt u snel bij benadering dichtstbijzijnde buren zoeken met hogere snelheden met een grotere nauwkeurigheid. HNSW is een benaderingsmethode (ANN). U kunt het als volgt instellen:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Notitie
HNSW-indexering is alleen beschikbaar op M40-clusterlagen en hoger.
5. Gegevens invoegen in de verzameling
Voeg nu de inventarisgegevens in, inclusief beschrijvingen en de bijbehorende vectorinsluitingen, in de zojuist gemaakte verzameling. Om gegevens in te voegen in onze verzameling, gebruiken we de insert_many() methode van de pymongo bibliotheek. Met de methode kunnen meerdere documenten tegelijk in de verzameling worden ingevoegd. Onze gegevens worden opgeslagen in een JSON-bestand, dat we laden en vervolgens in de database invoegen.
Download het shoes_with_vectors.json-bestand uit de GitHub-opslagplaats en sla het op in een data map in uw projectmap.
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. Vector Search in Cosmos DB voor MongoDB vCore
Nu onze gegevens zijn geüpload, kunnen we nu de kracht van vectorzoekopdrachten toepassen om de meest relevante items te vinden op basis van een query. Met de vectorindex die we eerder hebben gemaakt, kunnen we semantische zoekopdrachten uitvoeren in onze gegevensset.
6.1 Het uitvoeren van een vectorzoekopdracht
Als u een vectorzoekopdracht wilt uitvoeren, definiëren we een functie vector_search die een query en het aantal resultaten dat moet worden geretourneerd. De functie genereert een vector voor de query met behulp van de generate_embeddings functie die we eerder hebben gedefinieerd, en gebruikt vervolgens de functionaliteit van $search Cosmos DB om de dichtstbijzijnde overeenkomende items te vinden op basis van hun vector-insluitingen.
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 Vectorzoekquery uitvoeren
Ten slotte voeren we onze vectorzoekfunctie uit met een specifieke query en verwerken we de resultaten om ze weer te geven:
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
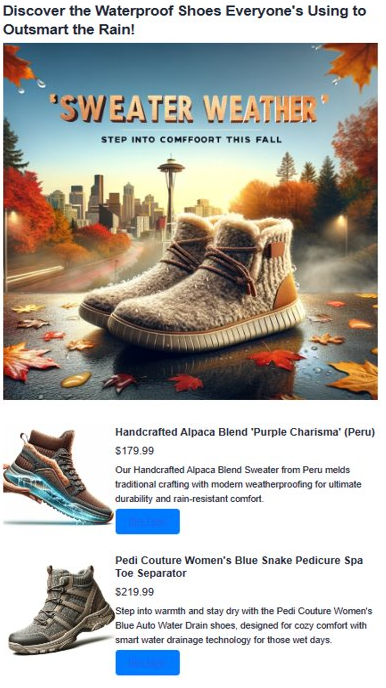
7. Advertentie-inhoud genereren met GPT-4 en DALL. E
We combineren alle ontwikkelde componenten om aantrekkelijke advertenties te maken, met de GPT-4 van OpenAI voor tekst en DALL· E 3 voor afbeeldingen. Samen met vectorzoekresultaten vormen ze een volledige advertentie. We introduceren ook Heelie, onze intelligente assistent, belast met het maken van aantrekkelijke advertentietaglijnen. Via de komende code ziet u Heelie in actie, waardoor het proces voor het maken van advertenties wordt verbeterd.
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. Alles samenbrengen
Om onze advertentiegeneratie interactief te maken, gebruiken we Gradio, een Python-bibliotheek voor het maken van eenvoudige web-UIS's. We definiëren een gebruikersinterface waarmee gebruikers advertentieonderwerpen kunnen invoeren en vervolgens dynamisch de resulterende advertentie kunnen genereren en weergeven.
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
Uitvoer