Honderden terabytes aan gegevens migreren naar Azure Cosmos DB
VAN TOEPASSING OP: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tafel
Tafel
Azure Cosmos DB kan terabytes aan gegevens opslaan. U kunt een grootschalige gegevensmigratie uitvoeren om de werkbelasting van uw productie naar Azure Cosmos DB te verplaatsen. In dit artikel worden de uitdagingen beschreven van het verplaatsen van grootschalige gegevens naar Azure Cosmos DB en wordt u voorgesteld aan het hulpprogramma dat u helpt bij deze uitdagingen en dat gegevens naar Azure Cosmos DB migreert. In deze casestudy heeft de klant de Azure Cosmos DB-API voor NoSQL gebruikt.
Voordat u de volledige workload naar Azure Cosmos DB migreert, kunt u een subset met gegevens migreren om enkele aspecten te valideren, zoals de keuze van partitiesleutels, queryprestaties en gegevensmodellering. Nadat u het proof-of-concept hebt gevalideerd, kunt u de hele workload verplaatsen naar Azure Cosmos DB.
Hulpprogramma's voor gegevensmigratie
Migratiestrategieën van Azure Cosmos DB verschillen momenteel op basis van de API-keuze en de grootte van de gegevens. Als u kleinere gegevenssets wilt migreren, kunt u de Azure Cosmos DB-connector van Azure Data Factory gebruiken om gegevensmodellering, queryprestaties, partitiesleutelkeuze, enzovoort te valideren. Als u bekend bent met Spark, kunt u er ook voor kiezen om de Azure Cosmos DB Spark-connector te gebruiken om gegevens te migreren.
Uitdagingen voor grootschalige migraties
De bestaande hulpprogramma's voor het migreren van gegevens naar Azure Cosmos DB hebben enkele beperkingen die vooral op grote schaal zichtbaar worden:
Beperkte uitschaalmogelijkheden: om terabytes aan gegevens zo snel mogelijk te migreren naar Azure Cosmos DB en de volledige ingerichte doorvoer effectief te kunnen gebruiken, moeten de migratieclients de mogelijkheid hebben om voor onbepaalde tijd uit te schalen.
Gebrek aan voortgangstracering en controlepunt: het is belangrijk om de voortgang van de migratie bij te houden en controlepunten te hebben tijdens het migreren van grote gegevenssets. Anders stopt elke fout die tijdens de migratie optreedt de migratie en moet u het proces helemaal opnieuw starten. Het zou niet productief zijn om het hele migratieproces opnieuw op te starten wanneer 99% van het migratieproces al is voltooid.
Gebrek aan wachtrij met dode letters: in grote gegevenssets kunnen er in sommige gevallen problemen zijn met delen van de brongegevens. Daarnaast kunnen er tijdelijke problemen zijn met de client of het netwerk. Een van deze gevallen mag er niet toe leiden dat de volledige migratie mislukt. Hoewel de meeste migratiehulpprogramma's robuuste mogelijkheden voor opnieuw proberen hebben die bescherming bieden tegen onregelmatige problemen, is dit niet altijd voldoende. Als bijvoorbeeld minder dan 0,01% van de brongegevensdocumenten groter is dan 2 MB, mislukt de schrijfbewerking van het document in Azure Cosmos DB. Idealiter is het handig voor het migratieprogramma om deze 'mislukte' documenten vast te leggen in een andere wachtrij met dode letters, die na de migratie kunnen worden verwerkt.
Veel van deze beperkingen worden opgelost voor hulpprogramma's zoals Azure Data Factory, Azure Data Migration-services.
Aangepast hulpprogramma met bulkexecutorbibliotheek
De uitdagingen die in de bovenstaande sectie worden beschreven, kunnen worden opgelost met behulp van een aangepast hulpprogramma dat eenvoudig kan worden uitgeschaald over meerdere exemplaren en het bestand is tegen tijdelijke fouten. Daarnaast kan het aangepaste hulpprogramma de migratie onderbreken en hervatten op verschillende controlepunten. Azure Cosmos DB biedt al de bulkexecutorbibliotheek die enkele van deze functies bevat. De bulkexecutorbibliotheek heeft bijvoorbeeld al de functionaliteit voor het afhandelen van tijdelijke fouten en kan threads in één knooppunt uitschalen om ongeveer 500 K RU's per knooppunt te verbruiken. De bulkexecutorbibliotheek partitioneert ook de brongegevensset in microbatches die onafhankelijk worden beheerd als een vorm van controlepunten.
Het aangepaste hulpprogramma maakt gebruik van de bibliotheek voor bulkexecutor en biedt ondersteuning voor uitschalen op meerdere clients en voor het bijhouden van fouten tijdens het opnameproces. Als u dit hulpprogramma wilt gebruiken, moeten de brongegevens worden gepartitioneerd in afzonderlijke bestanden in Azure Data Lake Storage (ADLS), zodat verschillende migratiemedewerkers elk bestand kunnen ophalen en opnemen in Azure Cosmos DB. Het aangepaste hulpprogramma maakt gebruik van een afzonderlijke verzameling, waarin metagegevens over de migratievoortgang voor elk afzonderlijk bronbestand in ADLS worden opgeslagen en eventuele fouten worden bijgehouden die eraan zijn gekoppeld.
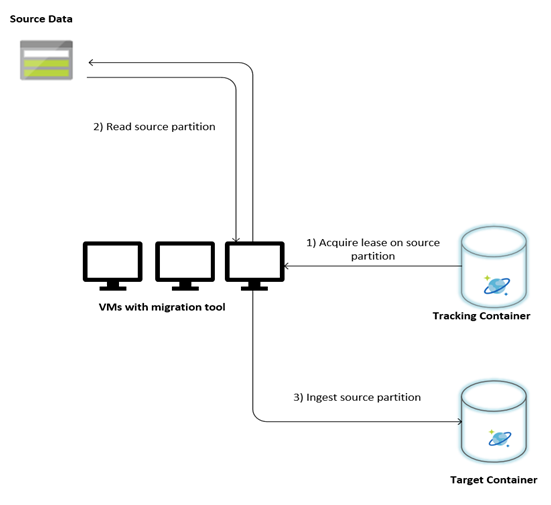
In de volgende afbeelding wordt het migratieproces beschreven met behulp van dit aangepaste hulpprogramma. Het hulpprogramma wordt uitgevoerd op een set virtuele machines en elke virtuele machine voert een query uit op de verzameling tracering in Azure Cosmos DB om een lease te verkrijgen op een van de brongegevenspartities. Zodra dit is gebeurd, wordt de brongegevenspartitie gelezen door het hulpprogramma en opgenomen in Azure Cosmos DB met behulp van de bulkexecutorbibliotheek. Vervolgens wordt de verzameling bijhouden bijgewerkt om de voortgang van gegevensopname en eventuele fouten vast te leggen. Nadat een gegevenspartitie is verwerkt, probeert het hulpprogramma een query uit te voeren op de volgende beschikbare bronpartitie. De volgende bronpartitie wordt nog steeds verwerkt totdat alle gegevens worden gemigreerd. De broncode voor het hulpprogramma is beschikbaar in de Azure Cosmos DB-opslagplaats voor bulkopname .
De verzameling bijhouden bevat documenten, zoals wordt weergegeven in het volgende voorbeeld. U ziet dergelijke documenten één voor elke partitie in de brongegevens. Elk document bevat de metagegevens voor de brongegevenspartitie, zoals de locatie, migratiestatus en fouten (indien aanwezig):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Vereisten voor gegevensmigratie
Voordat de gegevensmigratie wordt gestart, zijn er enkele vereisten om rekening mee te houden:
Maak een schatting van de gegevensgrootte:
De grootte van de brongegevens kan niet exact worden toegewezen aan de gegevensgrootte in Azure Cosmos DB. Enkele voorbeelddocumenten uit de bron kunnen worden ingevoegd om de gegevensgrootte in Azure Cosmos DB te controleren. Afhankelijk van de grootte van het voorbeelddocument kan de totale gegevensgrootte in Azure Cosmos DB na de migratie worden geschat.
Als elk document na de migratie in Azure Cosmos DB bijvoorbeeld ongeveer 1 KB is en er ongeveer 60 miljard documenten in de brongegevensset staan, betekent dit dat de geschatte grootte in Azure Cosmos DB bijna 60 TB is.
Containers vooraf maken met voldoende RU's:
Hoewel Azure Cosmos DB automatisch opslagruimte uitschaalt, is het niet raadzaam om te beginnen met de kleinste containergrootte. Kleinere containers hebben een lagere doorvoer, wat betekent dat de migratie veel langer duurt om te voltooien. In plaats daarvan is het handig om de containers te maken met de uiteindelijke gegevensgrootte (zoals geschat in de vorige stap) en ervoor te zorgen dat de migratieworkload de ingerichte doorvoer volledig verbruikt.
In de vorige stap. omdat de gegevensgrootte naar schatting ongeveer 60 TB is, is een container van ten minste 2,4 M RU's vereist om de volledige gegevensset te kunnen gebruiken.
De migratiesnelheid schatten:
Ervan uitgaande dat de migratieworkload de volledige ingerichte doorvoer kan verbruiken, geeft de ingerichte workload een schatting van de migratiesnelheid. Als u verdergaat met het vorige voorbeeld, zijn vijf RU's vereist voor het schrijven van een document van 1 KB naar de Azure Cosmos DB-API voor NoSQL-account. 2,4 miljoen RU's zouden een overdracht van 480.000 documenten per seconde (of 480 MB/s) mogelijk maken. Dit betekent dat de volledige migratie van 60 TB 125.000 seconden of ongeveer 34 uur duurt.
Als u wilt dat de migratie binnen een dag wordt voltooid, moet u de ingerichte doorvoer verhogen naar 5 miljoen RU's.
Schakel de indexering uit:
Aangezien de migratie zo snel mogelijk moet worden voltooid, is het raadzaam om de tijd en RU's die zijn besteed aan het maken van indexen voor elk van de opgenomen documenten te minimaliseren. Azure Cosmos DB indexeert automatisch alle eigenschappen. Het is de moeite waard om indexering naar een aantal geselecteerde termen te minimaliseren of deze volledig uit te schakelen voor de loop van de migratie. U kunt het indexeringsbeleid van de container uitschakelen door de indexingMode te wijzigen in geen, zoals hieronder wordt weergegeven:
{
"indexingMode": "none"
}
Nadat de migratie is voltooid, kunt u de indexering bijwerken.
Migratieproces
Nadat de vereisten zijn voltooid, kunt u gegevens migreren met de volgende stappen:
Importeer eerst de gegevens uit de bron naar Azure Blob Storage. Als u de migratiesnelheid wilt verhogen, is het handig om afzonderlijke bronpartities te parallelliseren. Voordat u de migratie start, moet de brongegevensset worden gepartitioneerd in bestanden met een grootte van ongeveer 200 MB.
De bulkexecutorbibliotheek kan omhoog worden geschaald om 500.000 RU's in één client-VM te verbruiken. Omdat de beschikbare doorvoer 5 miljoen RU's is, moeten 10 Virtuele Machines van Ubuntu 16.04 (Standard_D32_v3) worden ingericht in dezelfde regio waar uw Azure Cosmos DB-database zich bevindt. U moet deze VM's voorbereiden met het hulpprogramma voor migratie en het bijbehorende instellingenbestand.
Voer de wachtrijstap uit op een van de virtuele clientmachines. Met deze stap maakt u de verzameling tracering, waarmee de ADLS-container wordt gescand en een document voor voortgangstracering wordt gemaakt voor elke partitiebestanden van de brongegevensset.
Voer vervolgens de importstap uit op alle client-VM's. Elk van de clients kan eigenaar worden van een bronpartitie en de gegevens opnemen in Azure Cosmos DB. Zodra deze is voltooid en de status ervan is bijgewerkt in de traceringsverzameling, kunnen de clients vervolgens een query uitvoeren op de volgende beschikbare bronpartitie in de traceringsverzameling.
Dit proces wordt voortgezet totdat de volledige set bronpartities is opgenomen. Zodra alle bronpartities zijn verwerkt, moet het hulpprogramma opnieuw worden uitgevoerd op de foutcorrectiemodus in dezelfde traceringsverzameling. Deze stap is vereist om de bronpartities te identificeren die opnieuw moeten worden verwerkt vanwege fouten.
Sommige van deze fouten kunnen worden veroorzaakt door onjuiste documenten in de brongegevens. Deze moeten worden geïdentificeerd en opgelost. Vervolgens moet u de importstap op de mislukte partities opnieuw uitvoeren om ze opnieuw op te nemen.
Zodra de migratie is voltooid, kunt u controleren of het aantal documenten in Azure Cosmos DB hetzelfde is als het aantal documenten in de brondatabase. In dit voorbeeld is de totale grootte in Azure Cosmos DB gebleken tot 65 terabytes. Na de migratie kan indexering selectief worden ingeschakeld en kunnen de RU's worden verlaagd tot het niveau dat vereist is voor de bewerkingen van de workload.
Volgende stappen
- Meer informatie door de voorbeeldtoepassingen uit te proberen die gebruikmaken van de bulkexecutorbibliotheek in .NET en Java.
- De bulkexecutorbibliotheek is geïntegreerd in de Azure Cosmos DB Spark-connector. Zie het artikel over de Azure Cosmos DB Spark-connector voor meer informatie.
- Neem contact op met het Azure Cosmos DB-productteam door een ondersteuningsticket te openen onder het probleemtype Algemeen advies en het subtype 'Grote (TB+) migraties' voor aanvullende hulp bij grootschalige migraties.
- Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB? U kunt informatie over uw bestaande databasecluster gebruiken voor capaciteitsplanning.
- Als alles wat u weet het aantal vcores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner