De grootschalige cloudanalyse inrichten
Implementatieproces voor landingszones voor gegevensbeheer
Het operations-team van het gegevensplatform is verantwoordelijk voor het implementeren van een landingszone voor gegevensbeheer. De landingszone voor gegevensbeheer moet een eigen opslagplaats hebben die wordt onderhouden door het operations-team van het gegevensplatform.
Voorzichtigheid
Maak en implementeer een landingszone voor gegevensbeheer voordat een gegevenslandingszone wordt geïmplementeerd.
Implementatieproces voor gegevenslandingszones
Teams kunnen sjablonen van het gegevensplatform-operations-team gebruiken om te voorkomen dat ze elke asset helemaal opnieuw moeten opbouwen. We raden een forkingspatroon aan om de implementatie van een nieuwe landingszone te automatiseren.
Een operations-team voor gegevenslandingszones vraagt bijvoorbeeld een nieuwe gegevenslandingszone aan met behulp van een IT-beheertool of Power Apps. Start na goedkeuring van de aanvraag de volgende werkstroom met behulp van parameters uit de aanvraag:
- Implementeer een nieuw abonnement voor de nieuwe gegevenslandingszone.
- Maak een fork van de hoofdbranch van de sjabloon voor de gegevenslandingszone om een nieuwe repository te creëren.
- Maak een serviceverbinding in de nieuwe opslagplaats.
- Werk parameters in de nieuwe opslagplaats bij op basis van parameters uit de aanvraag.
- Maak een implementatiepijplijn om de services te implementeren, geactiveerd door het inchecken van de bijgewerkte parameters.
- Informeer het operations-team van de gegevenslandingszone dat de nieuwe landingszone beschikbaar is.
Het operations-team voor gegevenslandingszones kan nu Azure Resource Manager-sjablonen wijzigen of toevoegen.
Deze werkstroom kan worden geautomatiseerd met behulp van meerdere servicesets op het Azure-platform. Voer enkele stappen uit, zoals het wijzigen van de naam van parameters in parameterbestanden, met behulp van CI/CD-pijplijnen. Andere stappen kunnen worden uitgevoerd met andere hulpprogramma's voor werkstroomindeling, zoals Logic Apps.
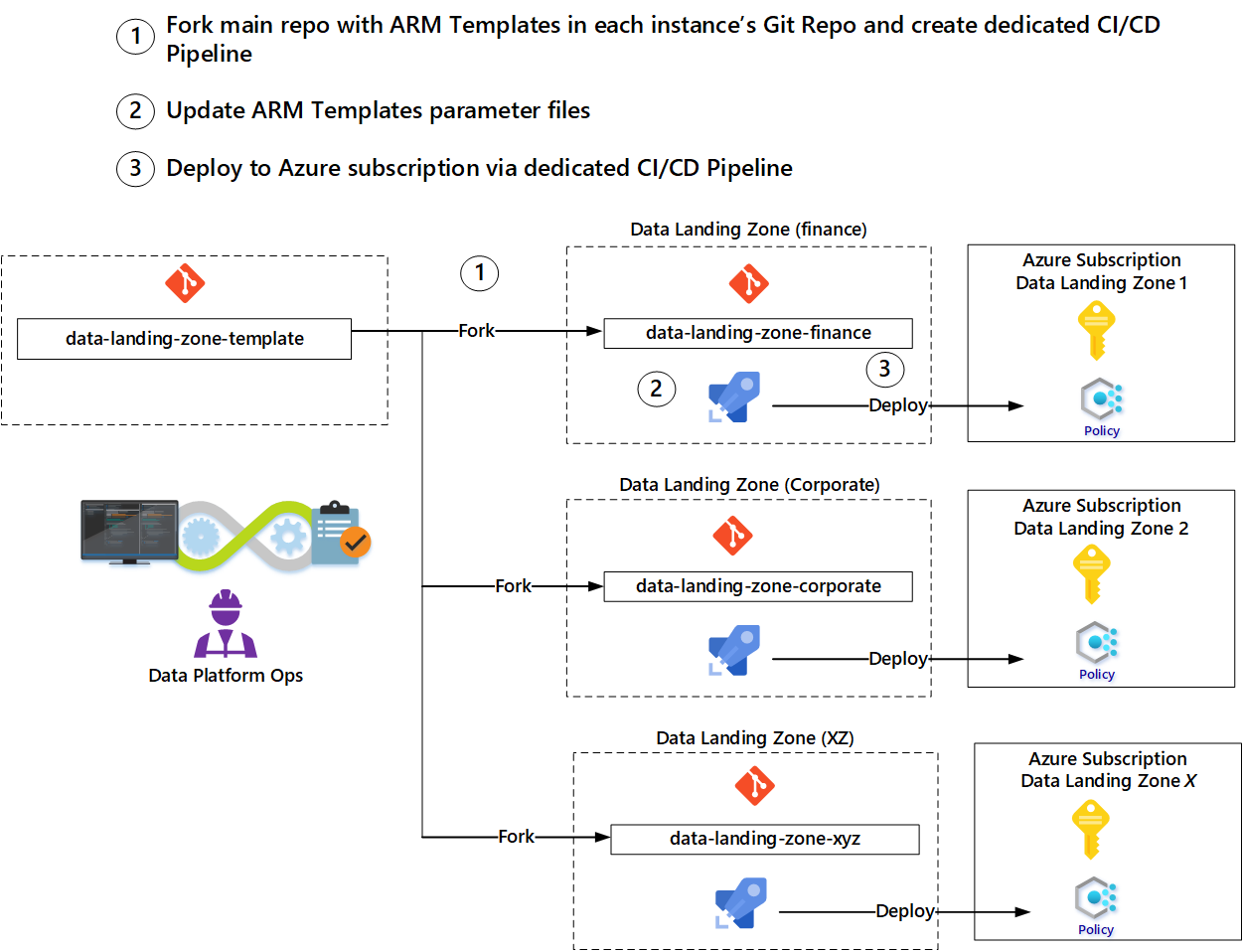
Het forking-patroon stelt teams in staat om hun sjablonen bij te werken vanuit de oorspronkelijke sjablonen die zijn gebruikt om ze te forken. Als er verbeteringen of nieuwe functies in de sjabloonopslagplaatsen worden geïmplementeerd, kunnen de operationsteams deze ook naar hun fork trekken.
Best practices gebruiken voor opslagplaatsen, zoals:
- Beveilig de hoofdbranch.
- Gebruik takken voor wijzigingen, updates en verbeteringen.
- Definieer de code-eigenaren die pull-aanvragen goedkeuren voordat wijzigingen worden samengevoegd in de hoofdbranch.
- Het valideren van vertakkingen door middel van geautomatiseerd testen.
- Beperk het aantal acties en personen in het team, zoals wie build- en release-pijplijnen kan activeren.
Fooi
Coördineer activiteiten tussen teams om ervoor te zorgen dat verbeteringen of nieuwe functies in de oorspronkelijke sjablonen worden gerepliceerd in alle exemplaren van de gegevenslandingszone. Operationele teams kunnen oorspronkelijke sjabloonwijzigingen in hun fork ophalen.
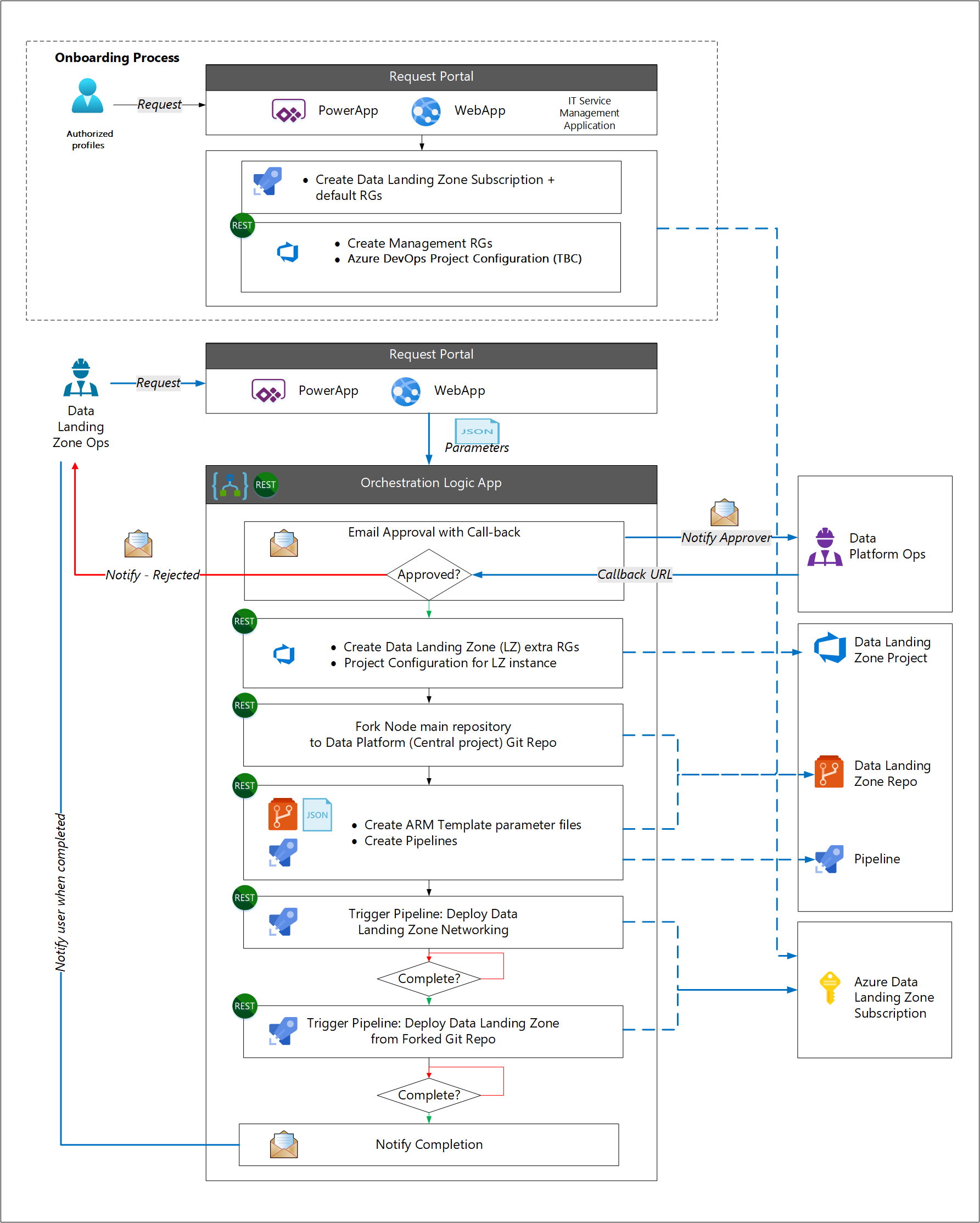
Het onboardingproces is gescheiden van het implementatieproces van de gegevenslandingszone. Deze scheiding is gebaseerd op de veronderstelling dat de meeste organisaties een standaardimplementatieproces voor Azure-abonnementen hebben als onderdeel van hun cloudbedrijfsmodel. Het onboardingproces implementeert standaard bedrijfsonderdelen (zoals een hulpprogramma voor IT-servicebeheer van derden). Onderdelen specifiek voor datalandingszones worden vervolgens geïmplementeerd.
Er zijn geen Git-API's beschikbaar voor het klonen/bijwerken/doorvoeren/pushen van de voorgestelde automatiseringsoplossing. Onze aanpak is dus het gebruik van een Azure Automation-account met PowerShell-runbooks die:
- Een gegevenslandingszone instellen
- Fork de hoofdopslagplaats naar een Git-opslagplaats van een gegevensplatform
- De subnetconfiguraties instellen voor de gegevenslandingszone
- Microsoft Entra-id instellen
De runbooks gebruiken Git-functies uit de GitAutomation PowerShell-module voor het werken met Git-opslagplaatsen. Door deze module in een Azure Automation-account te installeren, kunnen gebruikers bewerkingen maken, klonen, query's uitvoeren, pushen, pullen en doorvoeren in Git-opslagplaatsen. In de volgende afbeelding ziet u de GitAutomation module die is geïnstalleerd in een Azure Automation-account:

Gebruik de Copy-GitRepository-functie uit de GitAutomation-module om de hoofdopslagplaats van Git te klonen van de URL die is opgegeven door URL naar het Git-pad van het gegevensplatform dat is opgegeven door DestinationPath.
Deze benadering voor de implementatie van gegevenslandingszones is flexibel en zorgt ervoor dat acties voldoen aan de vereisten van de organisatie. Levenscyclusbeheer wordt ingeschakeld door nieuwe functies of optimalisaties toe te passen op basis van de oorspronkelijke sjablonen.
Implementatieproces voor gegevenstoepassingen
Nadat een gegevenslandingszone is gemaakt, kan onboarding worden gestart voor de datatoepassingsteams. Het dataplatformteam of de operationsteams voor de datalandingszone verlenen goedkeuring voor implementatie.
Implementatie wordt rechtstreeks uitgevoerd met behulp van DevOps-hulpprogramma's of aangeroepen via pijplijnen/werkstromen die als API's worden weergegeven. Net als bij de landingszone voor gegevens begint de implementatie met het splitsen van de oorspronkelijke opslagplaats voor gegevenstoepassingen.
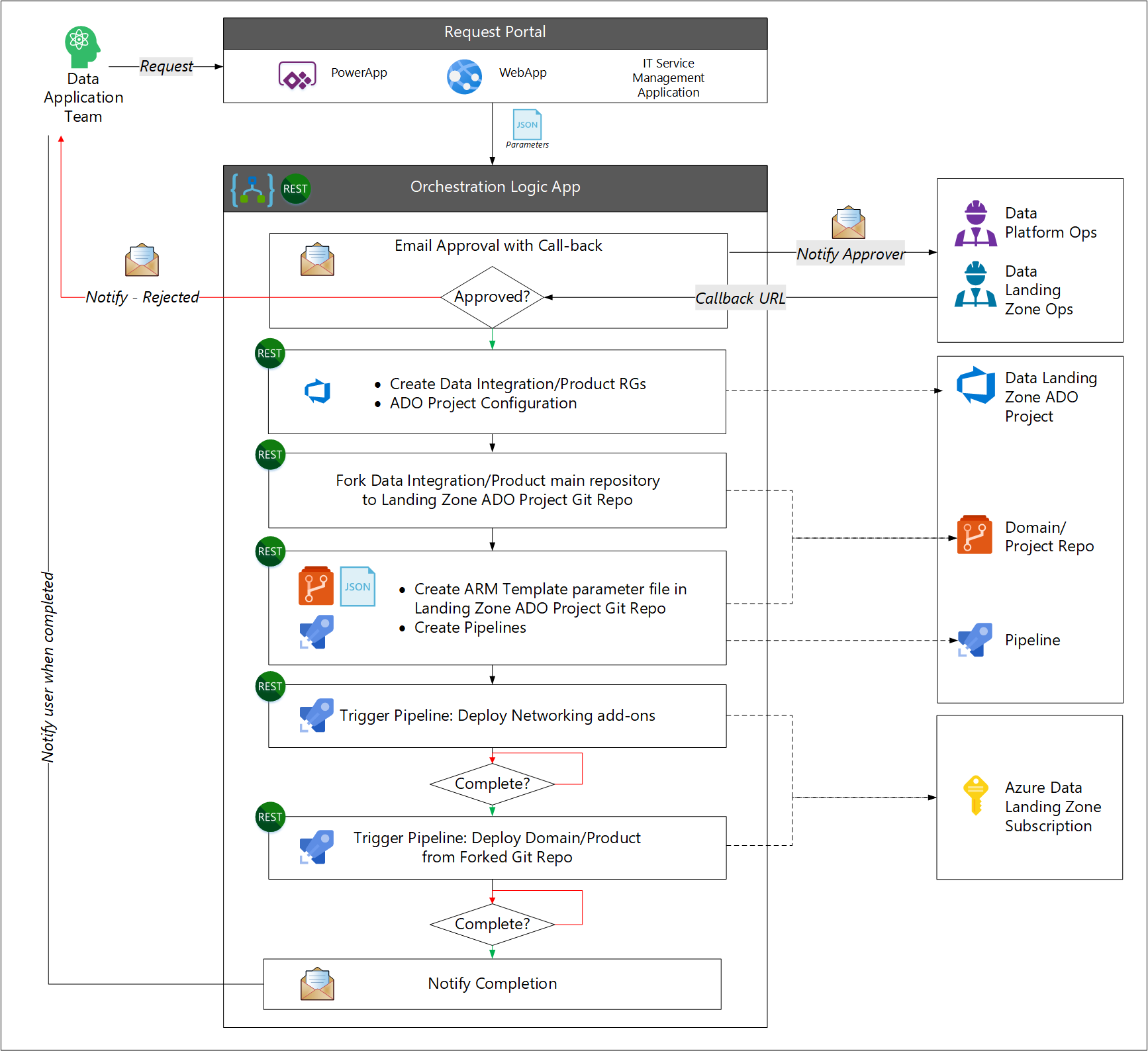
- De gebruiker doet een aanvraag voor nieuwe gegevenstoepassingsservices.
- Het werkstroomproces vraagt goedkeuring aan van het bewerkingsteam van het gegevensplatform of het operations-team van de gegevenslandingszone.
- De werkstroom roept de API voor IT-servicebeheer aan om vereiste resourcegroepen te maken en een Azure DevOps-serviceverbinding te maken. Met de werkstroom wordt een team toegewezen aan het Azure DevOps-project.
- De werkstroom forks de oorspronkelijke opslagplaats voor gegevenstoepassingen om het Azure DevOps-doelproject te maken.
- De werkstroom maakt een parameterbestand en pijplijnen voor een Azure Resource Manager-sjabloon.
- De werkstroom start vervolgens een Azure-pijplijn om de netwerkvereisten te maken en een andere Azure-pijplijn om de gegevenstoepassingsservices te implementeren.
- De werkstroom meldt de gebruiker bij voltooiing.
Tip
Als u nieuw bent in DataOps, kunt u het DataOps voor het moderne data-warehouse praktische lab bekijken in het Azure Architecture Center. In het scenario van het lab wordt een fictief kantoor voor stadsplanning beschreven dat deze implementatieoplossing kan gebruiken. De implementatieoplossing biedt een end-to-end gegevenspijplijn die het moderne architectuurpatroon van het datawarehouse volgt, samen met de bijbehorende DevOps- en DataOps-processen, om parkeren te beoordelen en weloverwogen zakelijke beslissingen te nemen.
Samenvatting
De bovenstaande patronen bieden beheer, flexibiliteit, selfservice en levenscyclusbeheer van beleidsregels.
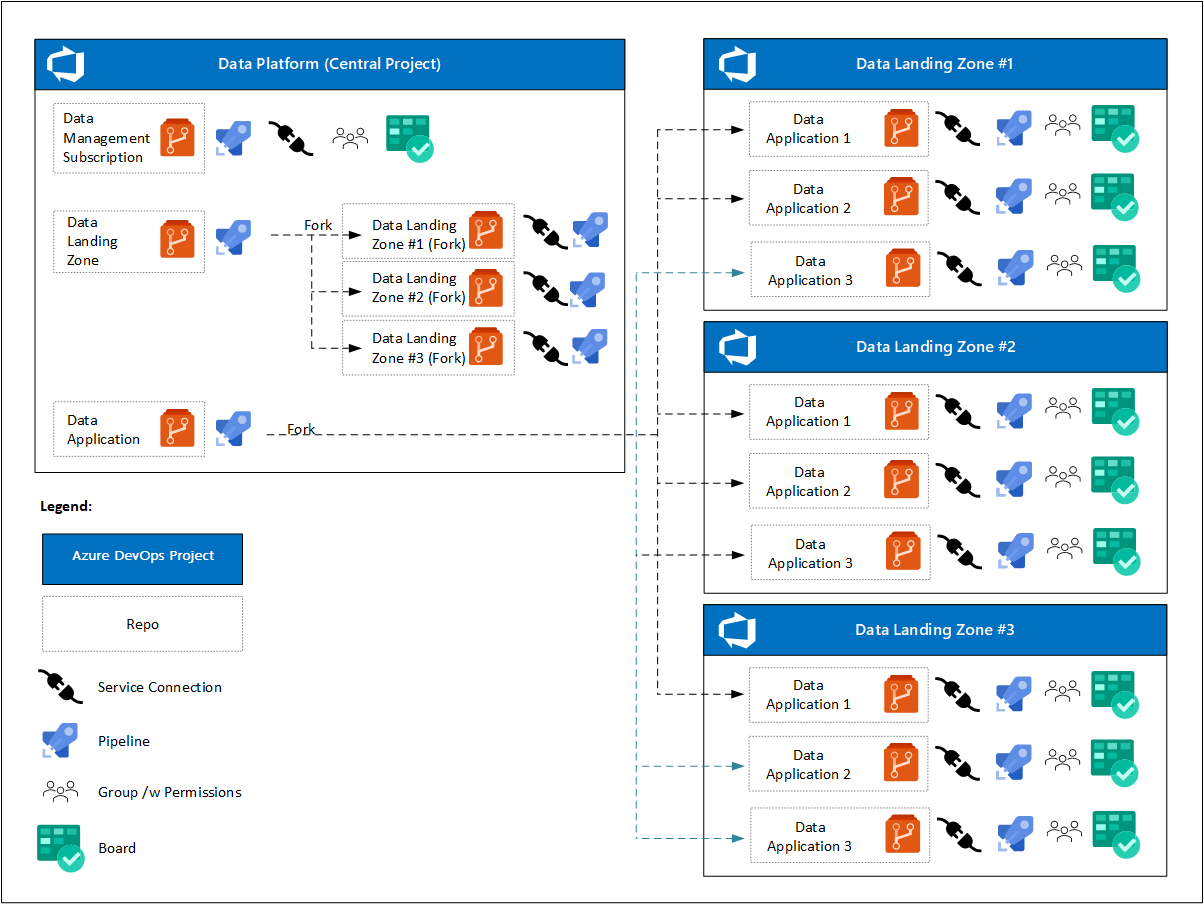
Aan het begin van het project heeft het gegevensplatform één Azure DevOps-project met een of meer Azure Boards. Afzonderlijke DevOps-teams richten zich op:
- Eén opslagplaats voor de datamanagement-landingszone, datapijplijnen en een serviceverbinding met de cloudomgeving.
- Eén sjabloonopslagplaats voor de gegevenslandingszone, pijplijnen voor het implementeren van een exemplaar van een gegevenslandingszone en serviceverbindingen met cloudomgevingen.
- Eén sjabloonopslagplaats voor gegevensproductservices, pijplijnen om een gegevensproductexemplaar te implementeren, en serviceverbindingen met cloudomgevingen. Deze verbindingen worden gesplitst vanuit de Azure DevOps-projecten voor de datalandingzone.
Nadat gegevenslandingszones zijn geïmplementeerd, schrijft analyses op cloudschaal voor dat:
- Elke gegevenslandingszone heeft een eigen Azure DevOps-project met een of meer Azure Boards.
- Voor elke gegevenstoepassing wordt de azure DevOps-projectfork van de gegevenslandingszone gemaakt na goedkeuring van de aanvraag.
- Elke gegevenstoepassing omvat:
- Een serviceverbinding.
- Een geregistreerde pijplijn.
- Een DevOps-team met toegang tot hun Azure-bord en -opslagplaats.
- Een andere set beleidsregels voor de geforkte opslagplaats.
Volg deze procedures om de implementatie van gegevenstoepassingen te beheren:
- Het operations-team voor de gegevenslandingszone is eigenaar van en beveiligt de hoofdbranch van de opslagplaats.
- Alleen de hoofdbranch wordt gebruikt om te implementeren voor test- en productieomgevingen.
- Functiebranches kunnen worden geïmplementeerd in ontwikkelomgevingen.
- Functiebranches zijn eigendom van de DataOps-teams. Ze worden gebruikt om nieuwe of gewijzigde functies te testen.
- DataOps-teams kunnen functiebranches zonder goedkeuring samenvoegen in andere functiebranches.
- DataOps-teams maken een pull-aanvraag voor het samenvoegen van functievertakkingen in de hoofdvertakking en het operations-team voor gegevenslandingszones biedt goedkeuring.
- Nieuwe functies of verbeteringen in de oorspronkelijke sjablonen worden samengevoegd in de geforkte opslagplaats om ze bijgewerkt te houden.