Azure Machine Learning als gegevensproduct voor analyses op cloudschaal
Azure Machine Learning is een geïntegreerd platform voor het beheren van de machine learning-levenscyclus van begin tot eind, inclusief hulp bij het maken, gebruiken en gebruiken van machine learning-modellen en -werkstromen. Enkele voordelen van de service zijn:
Mogelijkheden ondersteunen makers om hun productiviteit te verhogen door ze te helpen experimenten te beheren, gegevens te openen, taken bij te houden, hyperparameters af te stemmen en werkstromen te automatiseren.
De capaciteit van het model dat moet worden uitgelegd, gereproduceerd, gecontroleerd en geïntegreerd met DevOps, plus een uitgebreid beveiligingsbeheermodel, kan operators ondersteunen om te voldoen aan governance- en nalevingsvereisten.
Beheerde deductiemogelijkheden en robuuste integratie met Azure-reken- en gegevensservices kunnen helpen om te vereenvoudigen hoe de service wordt gebruikt.
Azure Machine Learning behandelt alle aspecten van de levenscyclus van data science. Het omvat gegevensopslag en registratie van gegevenssets voor modelimplementatie. Het kan worden gebruikt voor elk soort machine learning, van klassieke machine learning tot deep learning. Het omvat leren onder supervisie en zonder supervisie. Of u nu liever Python-, R-code schrijft of zero-code of low-code-opties zoals de ontwerpfunctie gebruikt, u kunt nauwkeurige machine learning- en Deep Learning-modellen bouwen, trainen en bijhouden in een Azure Machine Learning-werkruimte.
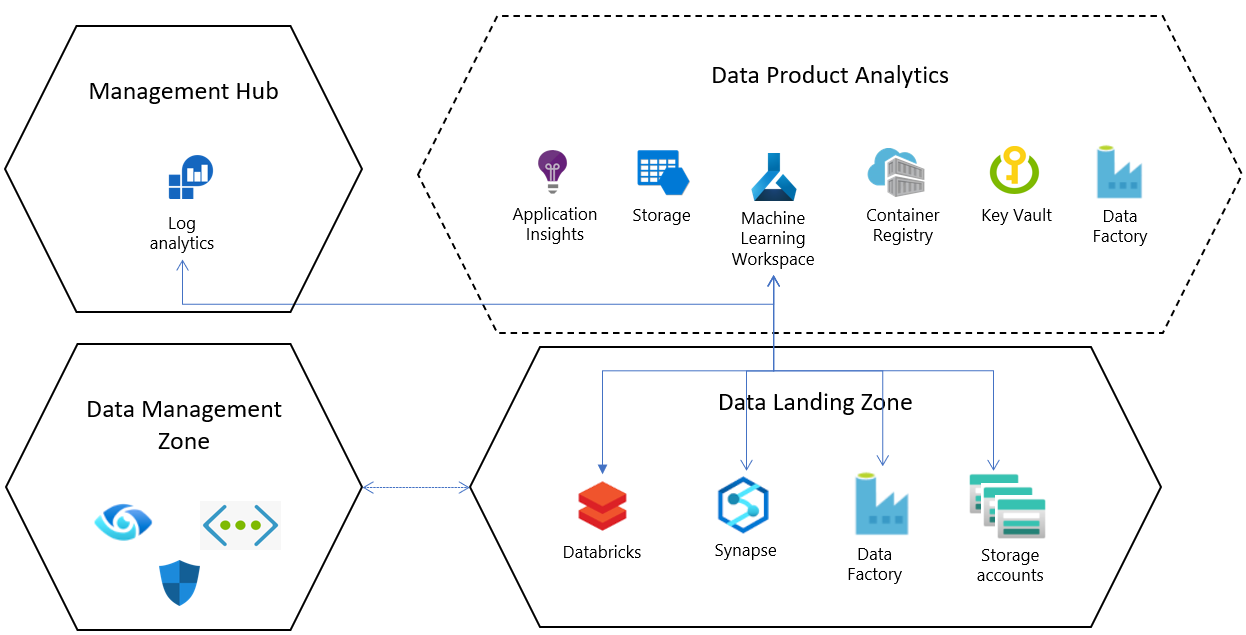
Azure Machine Learning, het Azure-platform en Azure AI-services kunnen samenwerken om de levenscyclus van machine learning te beheren. Een machine learning-arts kan Azure Synapse Analytics, Azure SQL Database of Microsoft Power BI gebruiken om gegevens te analyseren en over te stappen naar Azure Machine Learning voor prototypen, het beheren van experimenten en operationalisatie. In Azure-landingszones kan Azure Machine Learning worden beschouwd als een gegevensproduct.
Azure Machine Learning in analyses op cloudschaal
Een CAF-landingszonebasis (Cloud Adoption Framework), landingszones voor analysegegevens op cloudschaal en de configuratie van Azure Machine Learning stelt machine learning-professionals in met een vooraf geconfigureerde omgeving waarnaar ze herhaaldelijk nieuwe machine learning-workloads kunnen implementeren of bestaande workloads kunnen migreren. Deze mogelijkheden kunnen machine learning-professionals helpen om meer flexibiliteit en waarde te krijgen voor hun tijd.
De volgende ontwerpprincipes kunnen de implementatie van Azure Machine Learning Azure-landingszones begeleiden:
Versnelde toegang tot gegevens: vooraf configuratie van opslagonderdelen voor landingszones als gegevensarchieven in de Azure Machine Learning-werkruimte.
Mogelijkheden voor samenwerking inschakelen: Organiseer werkruimten per project en centraliseer het toegangsbeheer voor bronnen in de landingszone ter ondersteuning van data-engineering-, data-science- en machine-learningprofessionals om samen te werken.
Veilige implementatie: Als standaardinstelling voor elke implementatie volgt u aanbevolen procedures en gebruikt u netwerkisolatie, identiteit en toegangsbeheer om gegevensassets te beveiligen.
Selfservice: Machine Learning-professionals kunnen meer flexibiliteit en organisatie krijgen door opties te verkennen om nieuwe projectresources te implementeren.
Scheiding van problemen tussen gegevensbeheer en gegevensverbruik: Identiteitspassthrough is het standaardverificatietype voor Azure Machine Learning en opslag.
Snellere gegevenstoepassing (bron uitgelijnd): Azure Data Factory, Azure Synapse Analytics en Databricks-landingszones kunnen vooraf worden geconfigureerd om een koppeling naar Azure Machine Learning te maken.
Waarneembaarheid: Centrale logboekregistratie en referentieconfiguraties kunnen helpen bij het bewaken van de omgeving.
Implementatieoverzicht
Notitie
In deze sectie worden configuraties aanbevolen die specifiek zijn voor analyses op cloudschaal. Het vormt een aanvulling op de azure Machine Learning-documentatie en best practices voor Cloud Adoption Framework.
Organisatie en installatie van werkruimte
U kunt het aantal machine learning-werkruimten implementeren dat uw workloads nodig hebben en voor elke landingszone die u implementeert. De volgende aanbevelingen kunnen u helpen bij het instellen:
Implementeer ten minste één machine learning-werkruimte per project.
Afhankelijk van de levenscyclus van uw Machine Learning-project implementeert u één ontwikkelwerkruimte (dev) om gebruiksvoorbeelden voor prototypen te maken en gegevens vroeg te verkennen. Voor werk waarvoor continue experimenten, tests en implementaties zijn vereist, implementeert u een faserings- en productiewerkruimte.
Wanneer er meerdere omgevingen nodig zijn voor ontwikkel-, faserings- en productiewerkruimten in een gegevenslandingszone, raden we u aan gegevensduplicatie te voorkomen door elke omgeving in dezelfde landingszone voor productiegegevens te laten landen.
Zie Azure Machine Learning-omgevingen organiseren en instellen voor meer informatie over het organiseren en instellen van Azure Machine Learning-resources.
Voor elke standaardresourceconfiguratie in een gegevenslandingszone wordt een Azure Machine Learning-service geïmplementeerd in een toegewezen resourcegroep met de volgende configuraties en afhankelijke resources:
- Azure Key Vault
- Application Insights
- Azure Container Registry
- Gebruik Azure Machine Learning om verbinding te maken met een Azure Storage-account en verificatie op basis van microsoft Entra-identiteiten om gebruikers te helpen verbinding te maken met het account.
- Diagnostische logging wordt ingesteld voor elke werkruimte en geconfigureerd voor een centrale Log Analytics-resource op ondernemingsniveau; Hierdoor kan de status van Azure Machine Learning-taken en resourcestatussen gecentraliseerd worden geanalyseerd binnen en tussen landingszones.
- Zie Wat is een Azure Machine Learning-werkruimte? voor meer informatie over Azure Machine Learning-resources en -afhankelijkheden.
Integratie met kernservices van gegevenslandingszone
De gegevenslandingszone wordt geleverd met een standaardset services die zijn geïmplementeerd in de platformserviceslaag. Deze kernservices kunnen worden geconfigureerd wanneer Azure Machine Learning wordt geïmplementeerd in de gegevenslandingszone.
Verbind Azure Synapse Analytics- of Databricks-werkruimten als gekoppelde services om gegevens te integreren en big data te verwerken.
Data Lake-services worden standaard ingericht in de datalandingszone en azure Machine Learning-productimplementaties worden geleverd met verbindingen (gegevensarchieven) die vooraf zijn geconfigureerd voor deze opslagaccounts.
Netwerkverbinding
Netwerken voor het implementeren van Azure Machine Learning in Azure-landingszones zijn ingesteld volgens beveiligingsbest practices voor Azure Machine Learning en CAF netwerk best practices. Deze aanbevolen procedures omvatten de volgende configuraties:
- Azure Machine Learning en afhankelijke resources zijn geconfigureerd voor het gebruik van Private Link-eindpunten.
- Beheerde rekenresources worden alleen geïmplementeerd met privé-IP-adressen.
- Netwerkconnectiviteit met de openbare basisimage-opslagplaats en de partnerdiensten van Azure Machine Learning, zoals Azure Artifacts, kan op netwerkniveau worden geconfigureerd.
Identiteits- en toegangsbeheer
Bekijk de volgende aanbevelingen voor het beheren van gebruikersidentiteiten en toegang met Azure Machine Learning:
Gegevensarchieven in Azure Machine Learning kunnen worden geconfigureerd voor het gebruik van verificatie op basis van referenties of identiteiten. Wanneer u toegangsbeheer en data lake-configuraties gebruikt in Azure Data Lake Storage Gen2, configureert u gegevensarchieven voor het gebruik van verificatie op basis van identiteit; Hierdoor kan Azure Machine Learning gebruikerstoegangsmachtigingen voor opslag optimaliseren.
Gebruik Microsoft Entra-groepen om gebruikersmachtigingen voor opslag- en machine learning-resources te beheren.
Azure Machine Learning kan door de gebruiker toegewezen beheerde identiteiten gebruiken voor toegangsbeheer en het bereik van toegang tot Azure Container Registry, Key Vault, Azure Storage en Application Insights beperken.
Door de gebruiker toegewezen beheerde identiteiten maken voor beheerde rekenclusters die zijn gemaakt in Azure Machine Learning.
Infrastructuur inrichten via selfservice
Met -beleid kan selfservice voor Azure Machine Learningworden ingeschakeld en beheerd. De volgende tabel bevat een set standaardbeleidsregels wanneer u Azure Machine Learning implementeert. Voor meer informatie, zie de ingebouwde Azure Policy-beleidsdefinities voor Azure Machine Learning.
| Beleid | Type | Referentie |
|---|---|---|
| Azure Machine Learning-werkruimten moeten Gebruikmaken van Azure Private Link. | Ingebouwd | weergeven in azure Portal |
| Azure Machine Learning-werkruimten moeten door de gebruiker toegewezen beheerde identiteiten gebruiken. | Ingebouwd | weergeven in Azure portal |
| [Preview]: Toegestane registers configureren voor opgegeven Azure Machine Learning-berekeningen. | Ingebouwd | weergeven in azure Portal |
| Configureer Azure Machine Learning-werkruimten met privé-eindpunten. | Ingebouwd | weergeven in Azure portal |
| Configureer machine learning-berekeningen om lokale verificatiemethoden uit te schakelen. | Ingebouwd | weergeven in azure Portal |
| Append-script voor machine learning compute-instellingen setup-scripts aanmaaken | Aangepast (CAF-landingszones) | weergeven op GitHub |
| Verleenmachinelearning-hbiwerkruimte | Aangepast (CAF-landingszones) | weergeven op GitHub |
| Toegang-voor-machinelearning-weigeren-achter-vnet | Gepersonaliseerd (CAF-landingszones) | Weergeven op GitHub |
| Deny-machinelearning-AKS | Op maat (CAF-landingszones) | weergeven op GitHub |
| Deny-machinelearningcompute-subnetid | Aangepast (CAF-landingszones) | Bekijk op GitHub |
| Deny-machinelearningcompute-vmsize | Aangepast (CAF-landingszones) | Weergeven op GitHub |
| Weiger-machiinelearningrekengroep-afstandsaanmeldpoortopenbaartoegang | Aangepast (CAF-landingszones) | Bekijk op GitHub |
| Weigeren-machinelearningrekencluster-schaal | Aangepast (CAF landingszones) | Weergeven op GitHub |
Aanbevelingen voor het beheren van uw omgeving
Cloudgebaseerde analysegegevenslandingszones geven een overzicht van de referentie-implementatie voor herhaalbare implementaties, waarmee u beheerbare en beheerbare omgevingen kunt instellen. Bekijk de volgende aanbevelingen voor het gebruik van Azure Machine Learning om uw omgeving te beheren:
Gebruik Microsoft Entra-groepen om de toegang tot machine learning-resources te beheren.
Publiceer een centraal bewakingsdashboard om de pijplijnstatus, het rekengebruik en het quotumbeheer voor machine learning te bewaken.
Als u traditioneel ingebouwde Azure-beleidsregels gebruikt en moet voldoen aan aanvullende nalevingsvereisten, kunt u aangepaste Azure-beleidsregels bouwen om governance en selfservice te verbeteren.
Als u de kosten voor onderzoek en ontwikkeling wilt bijhouden, implementeert u één machine learning-werkruimte in de landingszone als een gedeelde resource tijdens de vroege fasen van het verkennen van uw use-case.
Belangrijk
Gebruik Azure Machine Learning-clusters voor modeltraining op productieniveau en Azure Kubernetes Service (AKS) voor implementaties op productieniveau.
Fooi
Azure Machine Learning gebruiken voor data science-projecten. Het omvat de end-to-end werkstroom met subservices en functies en maakt het mogelijk om het proces volledig te automatiseren.
Volgende stappen
Gebruik de Data Product Analytics sjabloon en richtlijnen voor het implementeren van Azure Machine Learning, en raadpleeg Documentatie en zelfstudies voor Azure Machine Learning om aan de slag te gaan met het bouwen van uw oplossingen.
Ga verder met de volgende vier artikelen over Cloud Adoption Framework voor meer informatie over de best practices voor implementatie en beheer van Azure Machine Learning voor ondernemingen:
Azure Machine Learning-omgevingen organiseren en instellen: Hoe beïnvloeden teamstructuren, omgevingen, of de geografie van resources, de manier waarop werkruimten worden ingericht bij het plannen van een Azure Machine Learning-implementatie?
Best practices voor Azure Machine Learning bij bedrijfsbeveiliging: Leer hoe u uw omgeving en middelen kunt beveiligen met Azure Machine Learning.
Budgetten, kosten en quota beheren voor Azure Machine Learning op organisatieschaal: organisaties hebben te maken met veel beheer- en optimalisatieproblemen bij het beheren van workload- en team- en gebruikerskosten die zijn gemaakt op basis van Azure Machine Learning.
Machine learning DevOps-handleiding: Machine learning DevOps is een organisatiewijziging die afhankelijk is van een combinatie van mensen, processen en technologie voor het leveren van machine learning-oplossingen op een robuuste, schaalbare, betrouwbare en geautomatiseerde manier. Deze handleiding bevat een overzicht van aanbevolen procedures en informatie voor ondernemingen voor het gebruik van Azure Machine Learning om machine learning DevOps te gebruiken.