Gegevensagnostische verwerkingsmachine
In dit artikel wordt uitgelegd hoe u gegevensagnostische opname-enginescenario's kunt implementeren met behulp van een combinatie van PowerApps-, Azure Logic Apps- en metagegevensgestuurde kopieertaken binnen Azure Data Factory.
Scenario's voor data-agnostische invoerengine zijn doorgaans gericht op het laten publiceren van niet-technische (niet-data-engineer) gebruikers databronnen in een Data Lake voor verdere verwerking. Als u dit scenario wilt implementeren, moet u onboardingmogelijkheden hebben die het volgende inschakelen:
- Registratie van gegevensbestanden
- Werkstroominrichting en metagegevens vastleggen
- Gegevensinnameplanning
U kunt zien hoe deze mogelijkheden werken:
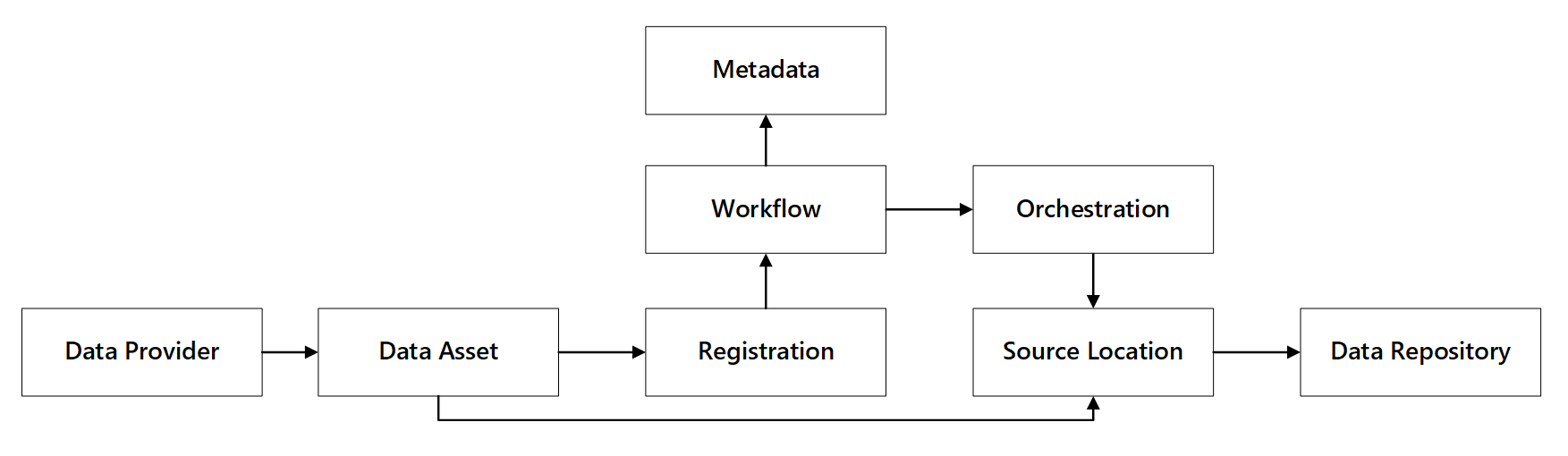
afbeelding 1: Interacties tussen gegevensregistratiemogelijkheden.
In het volgende diagram ziet u hoe u dit proces implementeert met behulp van een combinatie van Azure-services:
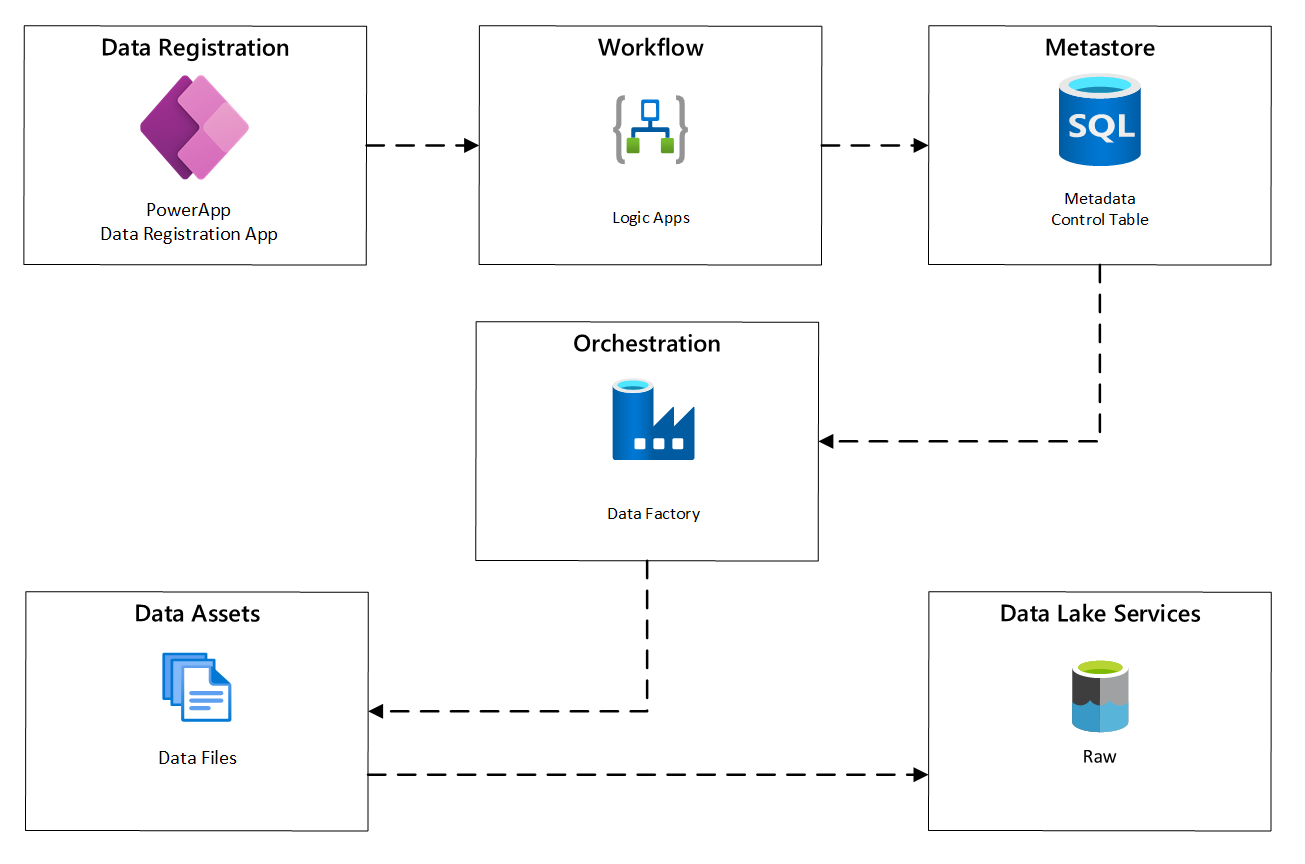
afbeelding 2: Geautomatiseerd opnameproces.
Registratie van gegevensbestanddelen
Als u de metagegevens wilt opgeven die worden gebruikt om geautomatiseerde opname te stimuleren, hebt u registratie van gegevensassets nodig. De gegevens die u vastlegt, bevatten:
- Technische informatie: Naam van de data asset, bronsysteem, type, formaat en frequentie.
- Governance-informatie: eigenaar, beheerders, zichtbaarheid (voor ontdekkingsdoeleinden) en gevoeligheid.
PowerApps wordt gebruikt om metagegevens vast te leggen die elke gegevensasset beschrijven. Gebruik een modelgestuurde app om de informatie in te voeren die wordt bewaard in een aangepaste Dataverse-tabel. Wanneer metagegevens worden gemaakt of bijgewerkt in Dataverse, wordt er een geautomatiseerde cloudstroom geactiveerd die verdere verwerkingsstappen aanroept.
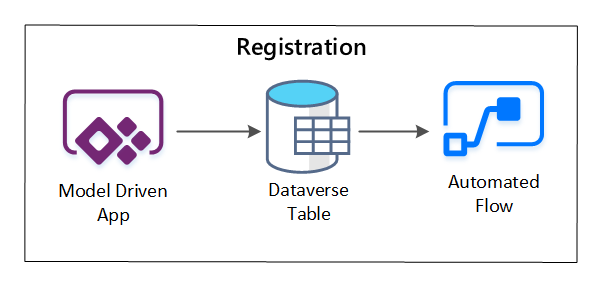
afbeelding 3: Registratie van gegevensassets.
Werkstroom inrichten/metagegevens vastleggen
Tijdens de inrichtingsfase valideert en slaat u gegevens op die zijn verzameld in de registratiefase in de metastore. Zowel technische als bedrijfsvalidatiestappen worden uitgevoerd, waaronder:
- Validatie van invoergegevensfeed
- Goedkeuringswerkstroom activeren
- Logische verwerking om persistentie van metagegevens naar het metagegevensarchief te activeren
- Activiteitscontrole
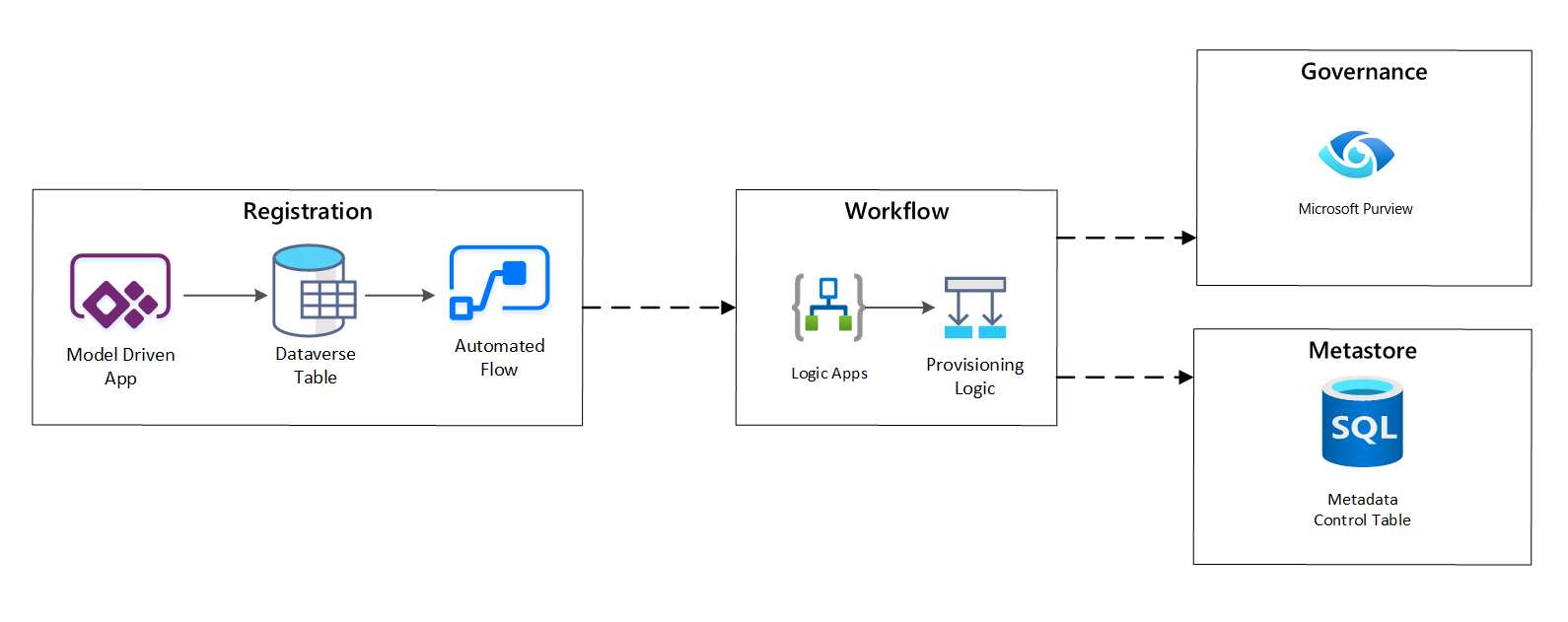
afbeelding 4: Registratiewerkstroom.
Nadat opnameaanvragen zijn goedgekeurd, gebruikt de werkstroom de Microsoft Purview REST API om de bronnen in Microsoft Purview in te voegen.
Gedetailleerde werkstroom voor de introductie van dataproducten
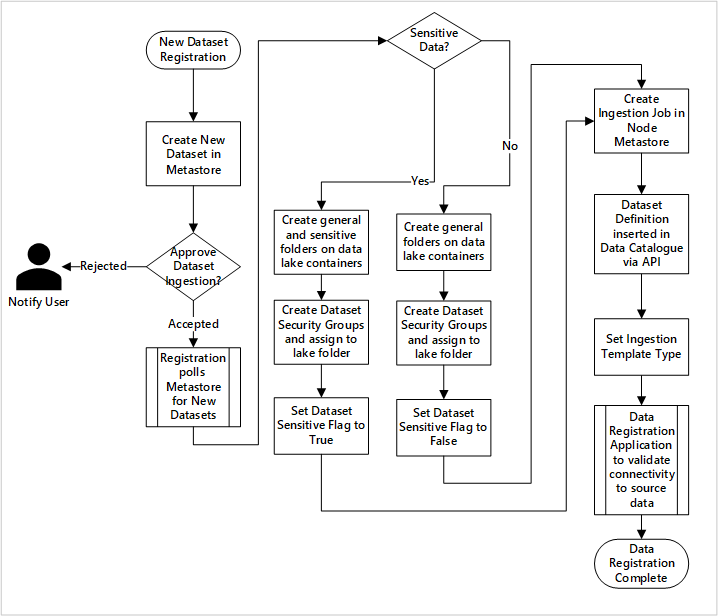
afbeelding 5: Hoe nieuwe gegevenssets worden opgenomen (geautomatiseerd).
Afbeelding 5 toont het gedetailleerde registratieproces voor het automatiseren van de opname van nieuwe gegevensbronnen:
- Brondetails worden geregistreerd, inclusief productie- en data factory-omgevingen.
- Beperkingen voor gegevensvormen, formaat en kwaliteit worden vastgelegd.
- Gegevenstoepassingenteams moeten aangeven of gegevens gevoelige (persoonlijke gegevens) zijn. Deze classificatie bepaalt het proces waarin data lake-mappen worden gemaakt om onbewerkte, verrijkte en gecureerde gegevens op te nemen. De bronnen noemen onbewerkte en verrijkte gegevens en de gegevensproducten noemen deze gecureerde gegevens.
- Service-principal- en beveiligingsgroepen worden gemaakt voor opname en toegang tot een gegevensset.
- Er wordt een opnametaak gemaakt in de datalandingszone van de Data Factory-metastore.
- Met een API wordt de gegevensdefinitie ingevoegd in Microsoft Purview.
- Afhankelijk van de validatie van de gegevensbron en goedkeuring door het ops-team, worden details gepubliceerd naar een Data Factory-metastore.
Verwerkingsplanning
Binnen Azure Data Factory bieden metagegevensgestuurde kopieertaken functionaliteit waarmee indelingspijplijnen kunnen worden aangestuurd door rijen in een besturingstabel die is opgeslagen in Azure SQL Database. U kunt het hulpprogramma Copy Data gebruiken om vooraf metagegevensgestuurde pijplijnen te maken.
Nadat een pijplijn is gemaakt, voegt uw voorzieningsworkflow vermeldingen toe aan de besturingstabel om het inladen te ondersteunen van gegevensbronnen die zijn geïdentificeerd door de metagegevens van de gegevensassetregistratie. De Azure Data Factory-pijplijnen en de Azure SQL Database met uw metastore voor besturingstabellen kunnen beide bestaan binnen elke gegevenslandingszone om nieuwe gegevensbronnen te maken en ze op te nemen in landingszones voor gegevens.
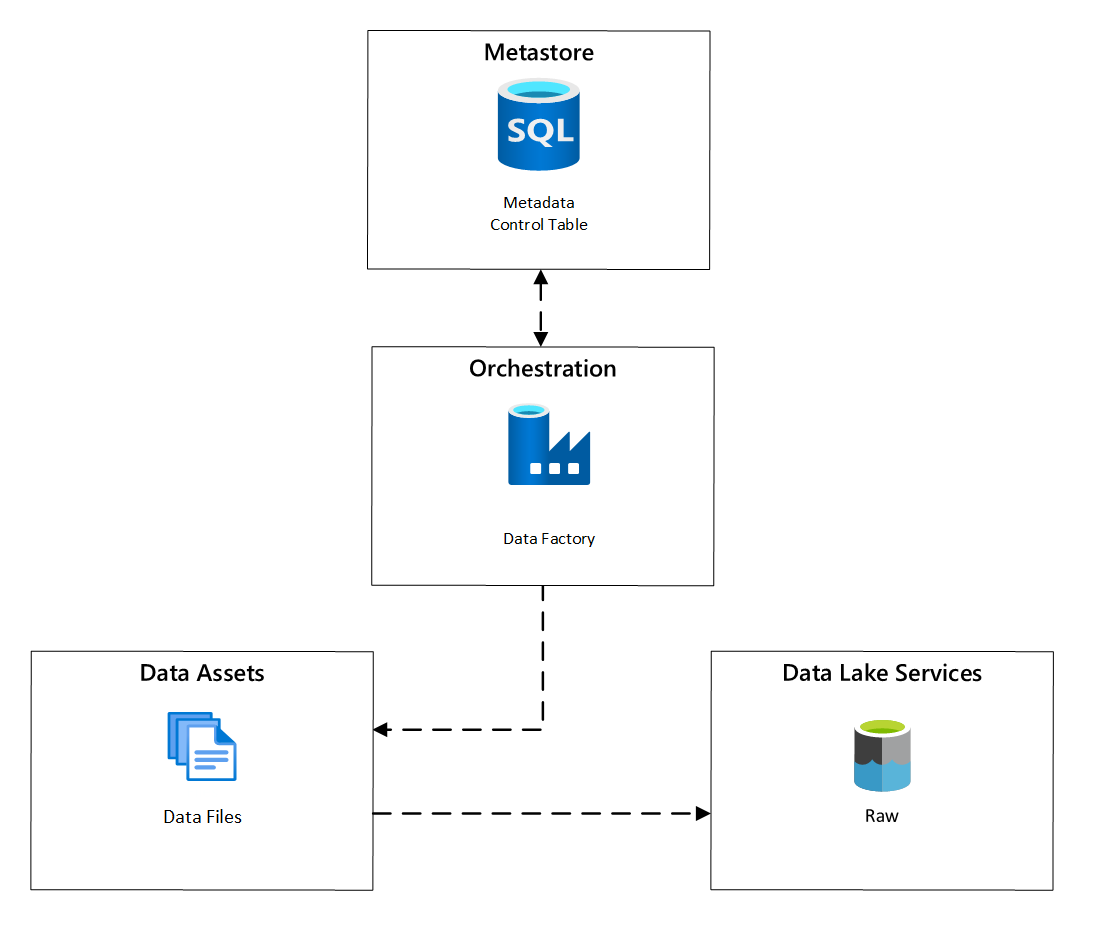
Afbeelding 6: Planning van opname van data-assets.
Gedetailleerde werkstroom voor het opnemen van nieuwe gegevensbronnen
In het volgende diagram ziet u hoe u geregistreerde gegevensbronnen ophaalt in een Data Factory SQL Database-metastore en hoe gegevens voor het eerst worden opgenomen:
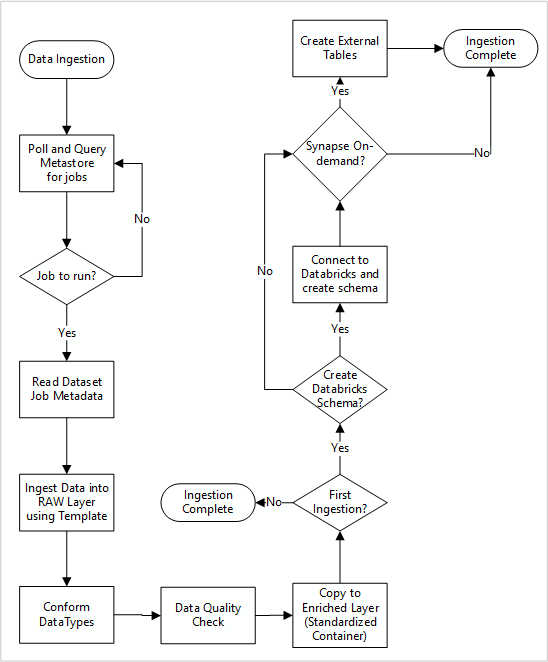
Uw Data Factory-opnamehoofdpijplijn leest configuraties uit een Data Factory SQL Database-metastore en wordt vervolgens iteratief uitgevoerd met de juiste parameters. Gegevens worden van de bron naar de onbewerkte laag in Azure Data Lake verzonden met weinig tot geen wijzigingen. De data-structuur wordt gevalideerd op basis van uw Data Factory metastore. Bestandsindelingen worden omgezet naar Apache Parquet of Avro en vervolgens gekopieerd naar de verrijkte laag.
Gegevens die worden opgenomen, maken verbinding met een Azure Databricks-werkruimte voor gegevenswetenschap en engineering en er wordt een gegevensdefinitie gemaakt in de Apache Hive-metastore voor gegevenslandingszone.
Als u een serverloze SQL-pool van Azure Synapse moet gebruiken om gegevens beschikbaar te maken, moet uw aangepaste oplossing weergaven maken over de gegevens in de lake.
Als u versleuteling op rij- of kolomniveau nodig hebt, moet uw aangepaste oplossing gegevens in uw data lake landen en gegevens rechtstreeks opnemen in interne tabellen in de SQL-pools en de juiste beveiliging instellen voor de berekening van de SQL-pools.
Vastgelegde metagegevens
Wanneer u geautomatiseerde gegevensopname gebruikt, kunt u een query uitvoeren op de bijbehorende metagegevens en dashboards maken om:
- Taken en de meest recente tijdstempels voor het laden van gegevens bijhouden voor gegevensproducten die betrekking hebben op hun functies.
- Beschikbare gegevensproducten bijhouden.
- Gegevensvolumes vergroten.
- Ontvang realtime updates over taakfouten.
Operationele metagegevens kunnen worden gebruikt om het volgende bij te houden:
- Taken, taakstappen en hun afhankelijkheden.
- Taakprestaties en prestatiegeschiedenis.
- Groei van gegevensvolume.
- Taakmislukkingen.
- Wijzigingen in bronmetagegevens.
- Bedrijfsfuncties die afhankelijk zijn van gegevensproducten.
De Microsoft Purview REST API gebruiken om gegevens te detecteren
Microsoft Purview REST API's moeten worden gebruikt om gegevens te registreren tijdens de eerste opname. U kunt de API's gebruiken om gegevens snel na opname naar uw gegevenscatalogus te verzenden.
Zie voor meer informatie het gebruik van Microsoft Purview REST API's.
Gegevensbronnen registreren
Gebruik de volgende API-aanroep om nieuwe gegevensbronnen te registreren:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
URI-parameters voor de gegevensbron:
| Naam | Vereist | Type | Beschrijving |
|---|---|---|---|
accountName |
Waar | Snaar | Naam van het Microsoft Purview-account |
dataSourceName |
Waar | Snaar | Naam van de gegevensbron |
De Microsoft Purview REST API gebruiken voor registratie
In de volgende voorbeelden ziet u hoe u de Microsoft Purview REST API gebruikt om gegevensbronnen te registreren met behulp van gegevenspayloads.
Een Azure Data Lake Storage Gen2-gegevensbron registreren:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Een SQL Database-gegevensbron registreren:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Notitie
Het <collection-name>is een actuele verzameling die zich bevindt in een Microsoft Purview-account.
Een scan maken
Ontdek hoe u referenties kunt maken om bronnen in Microsoft Purview te verifiëren voordat u een scan instelt en uitvoert.
Gebruik de volgende API-aanroep om gegevensbronnen te scannen:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
URI-parameters voor een scan:
| Naam | Vereist | Soort | Beschrijving |
|---|---|---|---|
accountName |
Waar | Snaar | Naam van het Microsoft Purview-account |
dataSourceName |
Waar | Snaar | Naam van de gegevensbron |
newScanName |
Waar | Snaar | Naam van de nieuwe scan |
De Microsoft Purview REST API gebruiken voor scannen
In de volgende voorbeelden ziet u hoe u de Microsoft Purview REST API kunt gebruiken om gegevensbronnen met payloads te scannen:
Een Azure Data Lake Storage Gen2-gegevensbron scannen:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
een SQL Database-gegevensbron scannen:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Gebruik de volgende API-aanroep om gegevensbronnen te scannen:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run