Bestandsruimte voor databases beheren in Azure SQL Managed Instance
Van toepassing op:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In dit artikel wordt beschreven hoe u bestanden in databases in Azure SQL Managed Instance bewaakt en beheert. We bekijken hoe u de grootte van het databasebestand bewaakt, het transactielogboek verkleint, een transactielogboekbestand vergroot en de groei van een transactielogboekbestand bepaalt.
Dit artikel is van toepassing op Azure SQL Managed Instance. Hoewel dit vergelijkbaar is, raadpleegt u De grootte van het transactielogboekbestand beheren voor informatie over het beheren van de grootte van transactielogboekbestanden in SQL Server.
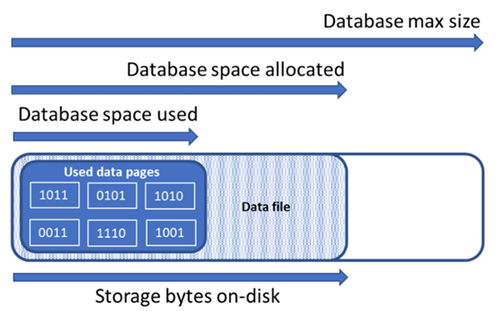
Inzicht in typen opslagruimte voor een database
Inzicht in de volgende hoeveelheden opslagruimte zijn belangrijk voor het beheren van de bestandsruimte van een database.
| Databasehoeveelheid | Definitie | Opmerkingen |
|---|---|---|
| Gebruikte gegevensruimte | De hoeveelheid ruimte die wordt gebruikt voor het opslaan van databasegegevens. | Over het algemeen neemt de gebruikte ruimte toe (neemt af) bij invoegingen (verwijderingen). In sommige gevallen verandert de gebruikte ruimte niet bij invoegingen of verwijderingen, afhankelijk van de hoeveelheid en het patroon van gegevens die betrokken zijn bij de bewerking en eventuele fragmentatie. Als u bijvoorbeeld één rij uit elke gegevenspagina verwijdert, wordt de gebruikte ruimte niet noodzakelijkerwijs verkleind. |
| Toegewezen gegevensruimte | De hoeveelheid opgemaakte bestandsruimte die beschikbaar is voor het opslaan van databasegegevens. | De hoeveelheid toegewezen ruimte groeit automatisch, maar neemt na verwijderen nooit af. Dit gedrag zorgt ervoor dat toekomstige invoegingen sneller zijn, omdat ruimte niet opnieuw hoeft te worden opgemaakt. |
| Toegewezen gegevensruimte, maar niet gebruikt | Het verschil tussen de hoeveelheid toegewezen gegevensruimte en de gebruikte gegevensruimte. | Deze hoeveelheid vertegenwoordigt de maximale hoeveelheid vrije ruimte die kan worden vrijgemaakt door databasegegevensbestanden te verkleinen. |
| Maximale grootte van gegevens | De maximale hoeveelheid ruimte die kan worden gebruikt voor het opslaan van databasegegevens. | De hoeveelheid toegewezen gegevensruimte kan niet groter worden dan de maximale grootte van de gegevens. |
In het volgende diagram ziet u de relatie tussen de verschillende typen opslagruimte voor een database.
Een query uitvoeren op één database voor informatie over de bestandsruimte
Gebruik de volgende query op sys.database_files om de hoeveelheid toegewezen databasebestandsruimte en de toegewezen hoeveelheid ongebruikte ruimte te retourneren. Eenheden van het queryresultaat zijn in MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Gebruik van logboekruimte bewaken
Bewaak het gebruik van logboekruimte met behulp van sys.dm_db_log_space_usage. Deze DMV retourneert informatie over de hoeveelheid gebruikte logboekruimte en geeft aan wanneer het transactielogboek moet worden afgekapt.
Voor informatie over de huidige logboekbestandsgrootte, de maximale grootte en de optie voor automatisch vergroten van het bestand, kunt u ook het size, max_sizeen growth de kolommen voor dat logboekbestand gebruiken in sys.database_files.
Metrische gegevens over opslagruimte die worden weergegeven in de op Azure Resource Manager gebaseerde API's voor metrische gegevens meten alleen de grootte van gebruikte gegevenspagina's. Zie PowerShell get-metrics voor voorbeelden.
Grootte van logboekbestand verkleinen
Als u de fysieke grootte van een fysiek logboekbestand wilt verkleinen door ongebruikte ruimte te verwijderen, verkleint u het logboekbestand. Een verkleining maakt alleen een verschil wanneer een transactielogboekbestand ongebruikte ruimte bevat. Als het logboekbestand vol is, waarschijnlijk vanwege geopende transacties, onderzoekt u wat verhindert dat transactielogboeken worden afgekapt.
Let op
Verkleiningsbewerkingen mogen niet worden beschouwd als een normale onderhoudsbewerking. Voor gegevens- en logboekbestanden die groeien als gevolg van regelmatige, terugkerende bedrijfsbewerkingen zijn geen verkleiningsbewerkingen vereist. Verkleiningsopdrachten hebben invloed op de prestaties van de database tijdens het uitvoeren en moeten, indien mogelijk, worden uitgevoerd om momenten dat de database niet of weinig wordt gebruikt. Het is niet raadzaam om gegevensbestanden te verkleinen als de normale workload van de toepassing ervoor zorgt dat de bestanden weer groter worden dan de toegewezen grootte.
Houd rekening met de mogelijke negatieve invloed op de prestaties van het verkleinen van databasebestanden. Zie Indexonderhoud na het verkleinen. In zeldzame gevallen kunnen verkleiningsbewerkingen worden beïnvloed door geautomatiseerde databaseback-ups. Voer indien nodig de verkleiningsbewerking opnieuw uit.
Voordat u het transactielogboek verkleint, moet u rekening houden met factoren die het afkappen van logboeken kunnen vertragen. Als de opslagruimte opnieuw nodig is nadat een logboek is verkleind, neemt het transactielogboek opnieuw toe en leidt dit tot prestatie-overhead tijdens logboekgroeibewerkingen. Zie de Aanbevelingen voor meer informatie.
U kunt een logboekbestand alleen verkleinen terwijl de database online is en ten minste één virtueel logboekbestand (VLF) gratis is. In sommige gevallen is het verkleinen van het logboek mogelijk pas na de volgende afkapping van het logboek mogelijk.
Factoren, zoals een langlopende transactie, kunnen VLF's gedurende een langere periode actief houden, de verkleining van logboeken beperken of zelfs voorkomen dat het logboek helemaal wordt verkleind. Zie Factoren die het afkappen van logboeken kunnen vertragen voor meer informatie.
Als u een logboekbestand verkleint, worden een of meer VLF's verwijderd die geen deel uitmaken van het logische logboek (dat wil gezegd inactieve VLF's). Wanneer u een transactielogboekbestand verkleint, worden inactieve VLF's verwijderd aan het einde van het logboekbestand om het logboek te verminderen tot ongeveer de doelgrootte.
Raadpleeg het volgende voor meer informatie over verkleiningsbewerkingen:
Een logboekbestand verkleinen (zonder databasebestanden te verkleinen)
Gebeurtenissen voor het verkleinen van logboekbestanden bewaken
- Gebeurtenisklasse voor automatisch verkleinen van logboekbestand.
Logboekruimte bewaken
sys.database_files (Transact-SQL) (Zie de
size,max_sizeengrowthkolommen voor het logboekbestand of de logboekbestanden.)
Indexonderhoud na verkleinen
Nadat een verkleiningsbewerking is voltooid voor gegevensbestanden, kunnen indexen worden gefragmenteerd. Dit vermindert de effectiviteit van de optimalisatie van prestaties voor bepaalde workloads, zoals query's met behulp van grote scans. Als prestatievermindering optreedt nadat de verkleiningsbewerking is voltooid, kunt u indexonderhoud overwegen om indexen opnieuw te bouwen. Houd er rekening mee dat voor het herbouwen van indexen vrije ruimte in de database is vereist, waardoor de toegewezen ruimte kan toenemen, waardoor het effect van de verkleining wordt tegengehouden.
Zie Indexonderhoud optimaliseren om de queryprestaties te verbeteren en het resourceverbruik te verminderen voor meer informatie over indexonderhoud.
Indexpaginadichtheid evalueren
Als het afkappen van gegevensbestanden niet resulteert in een voldoende vermindering van de toegewezen ruimte, kunt u besluiten om databasegegevensbestanden te verkleinen om ongebruikte ruimte van die bestanden vrij te maken. Als optionele maar aanbevolen stap moet u echter eerst de gemiddelde paginadichtheid voor indexen in de database bepalen. Voor dezelfde hoeveelheid gegevens wordt de verkleining sneller voltooid als de paginadichtheid hoog is, omdat deze minder pagina's moet verplaatsen. Als de paginadichtheid laag is voor sommige indexen, kunt u overwegen om onderhoud uit te voeren op deze indexen om de paginadichtheid te verhogen voordat u gegevensbestanden verkleint. Hierdoor kan er ook een grotere vermindering van de toegewezen opslagruimte worden bereikt.
Gebruik de volgende query om de paginadichtheid voor alle indexen in de database te bepalen. Paginadichtheid wordt gerapporteerd in de avg_page_space_used_in_percent kolom.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Als er indexen zijn met een hoog aantal pagina's met een paginadichtheid die lager is dan 60-70%, kunt u overwegen deze indexen opnieuw te bouwen of te herstructureren voordat u gegevensbestanden verkleint.
Notitie
Voor grotere databases kan het lang duren voordat de query de paginadichtheid bepaalt( uren). Daarnaast vereist het opnieuw opbouwen of opnieuw ordenen van grote indexen ook aanzienlijke tijd en resourcegebruik. Er is een compromis tussen het besteden van extra tijd aan het vergroten van de paginadichtheid aan de ene kant, en het verminderen van de duur van de verkleining en het bereiken van hogere ruimtebesparingen op een andere.
Als er meerdere indexen met lage paginadichtheid zijn, kunt u deze mogelijk parallel opnieuw bouwen op meerdere databasesessies om het proces te versnellen. Zorg er echter voor dat u de limieten voor databaseresources niet nadert door dit te doen en zorg ervoor dat er voldoende ruimte voor resources is voor toepassingsworkloads die mogelijk worden uitgevoerd. Bewaak het resourceverbruik (CPU, Data IO, Log IO) in azure Portal of gebruik de sys.dm_db_resource_stats weergave en start extra parallelle herbouwen alleen als het resourcegebruik voor elk van deze dimensies aanzienlijk lager blijft dan 100%. Als het CPU-, gegevens-IO- of logboek-IO-gebruik 100% is, kunt u de database omhoog schalen om meer CPU-kernen te hebben en de IO-doorvoer te verhogen. Hierdoor kunnen extra parallelle herbouwbewerkingen worden ingeschakeld om het proces sneller te voltooien.
Voorbeeld van opdracht voor opnieuw samenstellen van index
Hieronder volgt een voorbeeldopdracht voor het opnieuw samenstellen van een index en het verhogen van de paginadichtheid, met behulp van de INSTRUCTIE ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Met deze opdracht wordt een online en hervatbare index opnieuw opgebouwd. Hierdoor kunnen gelijktijdige workloads de tabel blijven gebruiken terwijl de herbouw wordt uitgevoerd en kunt u de herbouw hervatten als deze om welke reden dan ook wordt onderbroken. Dit type herbouw is echter langzamer dan een offline herbouwing, waardoor de toegang tot de tabel wordt geblokkeerd. Als er geen andere workloads toegang nodig hebben tot de tabel tijdens het opnieuw opbouwen, stelt u de ONLINE en RESUMABLE opties OFF in en verwijdert u de WAIT_AT_LOW_PRIORITY component.
Zie Indexonderhoud optimaliseren om de queryprestaties te verbeteren en het resourceverbruik te verminderen voor meer informatie over indexonderhoud.
Meerdere gegevensbestanden verkleinen
Zoals eerder vermeld, is verkleinen met gegevensverplaatsing een langlopend proces. Als de database meerdere gegevensbestanden heeft, kunt u het proces versnellen door meerdere gegevensbestanden parallel te verkleinen. U doet dit door meerdere databasesessies te openen en voor elke sessie met een andere file_id waarde te gebruikenDBCC SHRINKFILE. Net als bij het opnieuw opbouwen van indexen moet u ervoor zorgen dat u voldoende ruimte hebt voor resources (CPU, Data IO, Log IO) voordat u elke nieuwe parallelle verkleiningsopdracht start.
De volgende voorbeeldopdracht verkleint het gegevensbestand met file_id 4 en probeert de toegewezen grootte te verkleinen tot 52.000 MB door pagina's in het bestand te verplaatsen:
DBCC SHRINKFILE (4, 52000);
Als u de toegewezen ruimte voor het bestand zo min mogelijk wilt beperken, voert u de instructie uit zonder de doelgrootte op te geven:
DBCC SHRINKFILE (4);
Als een workload gelijktijdig met verkleinen wordt uitgevoerd, kan deze de opslagruimte gebruiken die is vrijgemaakt door te verkleinen voordat het verkleinen is voltooid en het bestand wordt afgekapt. In dit geval kan verkleinen de toegewezen ruimte voor het opgegeven doel niet verminderen.
U kunt dit beperken door elk bestand in kleinere stappen te verkleinen. Dit betekent dat u in de DBCC SHRINKFILE opdracht het doel instelt dat iets kleiner is dan de huidige toegewezen ruimte voor het bestand. Als bijvoorbeeld toegewezen ruimte voor bestand met file_id 4 200.000 MB is en u deze wilt verkleinen tot 100.000 MB, kunt u het doel eerst instellen op 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Zodra deze opdracht is voltooid, is het bestand afgekapt en is de toegewezen grootte verkleind tot 170.000 MB. Vervolgens kunt u deze opdracht herhalen, het doel eerst instellen op 140.000 MB, vervolgens op 110.000 MB, enzovoort, totdat het bestand is verkleind tot de gewenste grootte. Als de opdracht is voltooid, maar het bestand niet is afgekapt, gebruikt u kleinere stappen, bijvoorbeeld 15.000 MB in plaats van 30.000 MB.
Als u de voortgang van de verkleining wilt controleren voor alle gelijktijdig uitgevoerde verkleinde sessies, kunt u de volgende query gebruiken:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Notitie
De voortgang van de verkleining kan niet-lineair zijn en de waarde in de percent_complete kolom blijft mogelijk gedurende lange perioden ongewijzigd, ook al wordt de daling nog steeds uitgevoerd.
Zodra het verkleinen is voltooid voor alle gegevensbestanden, gebruikt u de query voor ruimtegebruik om de resulterende vermindering van de toegewezen opslaggrootte te bepalen. Als er nog steeds een groot verschil is tussen de gebruikte ruimte en de toegewezen ruimte, kunt u indexen opnieuw opbouwen. Dit kan tijdelijk de toegewezen ruimte vergroten, maar het opnieuw verkleinen van gegevensbestanden na het herbouwen van indexen moet resulteren in een diepere vermindering van de toegewezen ruimte.
Een logboekbestand vergroten
Voeg in Azure SQL Managed Instance ruimte toe aan een logboekbestand door het bestaande logboekbestand te vergroten (als schijfruimte toestaat). Het toevoegen van een logboekbestand aan de database wordt niet ondersteund. Eén transactielogboekbestand is voldoende, tenzij de logboekruimte opraakt en schijfruimte ook op het volume met het logboekbestand opraakt.
Als u het logboekbestand wilt vergroten, gebruikt u de MODIFY FILE component van de ALTER DATABASE instructie, waarbij u de SIZE en MAXSIZE syntaxis opgeeft. Zie de opties ALTER DATABASE (Transact-SQL) File and Filegroup voor meer informatie.
Zie de Aanbevelingen voor meer informatie.
Groei van transactielogboekbestanden beheren
Gebruik de instructie ALTER DATABASE (Transact-SQL) File and Filegroup options statement om de groei van een transactielogboekbestand te beheren. Let op het volgende:
- Gebruik
SIZEde optie om de huidige bestandsgrootte in kB-, MB-, GB- en TB-eenheden te wijzigen. - Als u de toename van de groei wilt wijzigen, gebruikt u de
FILEGROWTHoptie. Een waarde van 0 geeft aan dat automatische groei wordt uitgeschakeld en dat er geen extra ruimte is toegestaan. - Gebruik
MAXSIZEde optie om de maximale grootte van een logboekbestand in kB-, MB-, GB- en TB-eenheden te bepalen of om groei in te stellen op ONBEPERKT.
Aanbevelingen
Hier volgen enkele algemene aanbevelingen wanneer u met transactielogboekbestanden werkt:
De automatische groei (automatische groei) van het transactielogboek, zoals ingesteld door de
FILEGROWTHoptie, moet groot genoeg zijn om te voldoen aan de behoeften van de workloadtransacties. De toename van het bestand in een logboekbestand moet voldoende groot zijn om frequente uitbreiding te voorkomen. Een goede aanwijzer voor de juiste grootte van een transactielogboek is het controleren van de hoeveelheid logboek die wordt bezet tijdens:- De tijd die nodig is om een volledige back-up uit te voeren, omdat er geen logboekback-ups kunnen worden uitgevoerd totdat deze is voltooid.
- De tijd die nodig is voor de grootste indexonderhoudsbewerkingen.
- De tijd die nodig is om de grootste batch in een database uit te voeren.
Bij het instellen van automatische groei voor gegevens en logboekbestanden met behulp van de
FILEGROWTHoptie, is het misschien beter om deze in te stellen insizeplaats vanpercentage, om een betere controle over de groeiverhouding mogelijk te maken, omdat het percentage een steeds groeiende hoeveelheid is.- In Azure SQL Managed Instance kan direct initialisatie van bestanden profiteren van groei gebeurtenissen in transactielogboeken tot 64 MB. De standaardgrootte voor automatische groei voor nieuwe databases is 64 MB. Automatische groeigebeurtenissen van transactielogboekbestanden die groter zijn dan 64 MB, kunnen niet profiteren van de initialisatie van bestanden.
- Als best practice stelt u de
FILEGROWTHoptiewaarde niet in boven 1024 MB voor transactielogboeken.
Een kleine toename van automatische groei kan te veel kleine VLF's genereren en de prestaties verminderen. Als u de optimale VLF-distributie wilt bepalen voor de huidige grootte van het transactielogboek van alle databases in een bepaald exemplaar en de vereiste groeiverhogingen om de vereiste grootte te bereiken, raadpleegt u dit script voor het analyseren en herstellen van VLF's, geleverd door het SQL Tiger Team.
Een grote toename van automatische groei kan twee problemen veroorzaken:
- Een grote toename van automatische groei kan ertoe leiden dat de database wordt onderbroken terwijl de nieuwe ruimte wordt toegewezen, waardoor er mogelijk time-outs voor query's ontstaan.
- Een grote toename van automatische groei kan te weinig en grote VLF's genereren en kan ook van invloed zijn op de prestaties. Als u de optimale VLF-distributie wilt bepalen voor de huidige grootte van het transactielogboek van alle databases in een bepaald exemplaar en de vereiste groeiverhogingen om de vereiste grootte te bereiken, raadpleegt u dit script voor het analyseren en herstellen van VLF's, geleverd door het SQL Tiger Team.
Zelfs als automatische groei is ingeschakeld, kunt u een bericht ontvangen dat het transactielogboek vol is, als het niet snel genoeg kan groeien om aan de behoeften van uw query te voldoen. Zie DE opties ALTER DATABASE (Transact-SQL) File and Filegroup voor meer informatie over het wijzigen van de groeitoename.
Logboekbestanden kunnen automatisch worden verkleind. Dit wordt echter niet aanbevolen en de eigenschap auto_shrink database is standaard ingesteld op FALSE. Als auto_shrink is ingesteld op TRUE, vermindert automatisch verkleinen de grootte van een bestand alleen wanneer meer dan 25 procent van de ruimte niet wordt gebruikt.
- Het bestand is verkleind tot de grootte waarop slechts 25 procent van het bestand ongebruikte ruimte heeft of tot de oorspronkelijke grootte van het bestand, afhankelijk van wat groter is.
- Zie De eigenschappen van een database en ALTER DATABASE SET Options (Transact-SQL) weergeven of wijzigen voor informatie over het wijzigen van de instelling van de eigenschap auto_shrink.
Volgende stappen
- Geautomatiseerde back-ups in Azure SQL Managed Instance
- ALTER DATABASE (Transact-SQL) File and Filegroup options (Bestands- en bestandsgroepopties voor ALTER DATABASE (Transact-SQL))
- Overzicht van resourcelimieten voor Azure SQL Managed Instance
- Problemen met transactielogboeken met Azure SQL Managed Instance oplossen