Een failovergroep configureren voor Azure SQL Managed Instance
Van toepassing op:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In dit artikel leert u hoe u een failovergroep voor Azure SQL Managed Instance configureert met behulp van Azure Portal en Azure PowerShell.
Voor een end-to-end PowerShell-script om beide exemplaren binnen een failovergroep te maken, raadpleegt u Exemplaar toevoegen aan een failovergroep.
Vereisten
Houd rekening met de volgende vereisten:
- Het secundaire beheerde exemplaar moet leeg zijn, dat wil gezegd geen gebruikersdatabases bevatten.
- De twee exemplaren van SQL Managed Instance moeten zich in dezelfde servicelaag bevinden en dezelfde opslaggrootte hebben. Hoewel dit niet vereist is, wordt ten zeerste aangeraden dat twee exemplaren een gelijke rekenkracht hebben, om ervoor te zorgen dat secundaire instanties de wijzigingen die worden gerepliceerd van het primaire exemplaar duurzaam kunnen verwerken, inclusief de perioden van piekactiviteit.
- Het IP-adresbereik voor het virtuele netwerk van het primaire exemplaar mag niet overlappen met het adresbereik van het virtuele netwerk voor het secundaire beheerde exemplaar of een ander virtueel netwerk dat is gekoppeld aan het primaire of secundaire virtuele netwerk.
- Wanneer u uw secundaire beheerde exemplaar maakt, moet u de DNS-zone-id van het primaire exemplaar opgeven als de waarde van de
DnsZonePartnerparameter. Als u geen waardeDnsZonePartneropgeeft, wordt de zone-id gegenereerd als een willekeurige tekenreeks wanneer het eerste exemplaar in elk virtueel netwerk wordt gemaakt en dezelfde id wordt toegewezen aan alle andere exemplaren in hetzelfde subnet. Zodra de DNS-zone is toegewezen, kan deze niet meer worden gewijzigd. - NSG-regels (Netwerkbeveiligingsgroepen) op het subnethostingexemplaren moeten poort 5022 (TCP) hebben en het poortbereik 11000-11999 (TCP) moet binnenkomend en uitgaand zijn voor verbindingen van en naar het subnet dat als host fungeert voor het andere beheerde exemplaar. Dit is van toepassing op zowel subnetten als het hosten van primaire en secundaire exemplaren.
- De sortering en tijdzone van het secundaire beheerde exemplaar moeten overeenkomen met die van het primaire beheerde exemplaar.
- Beheerde exemplaren moeten om prestatieredenen worden geïmplementeerd in gekoppelde regio's . Beheerde exemplaren die zich in geografisch gekoppelde regio's bevinden, profiteren van een aanzienlijk hogere geo-replicatiesnelheid in vergelijking met niet-gepaareerde regio's.
Adresruimtebereik
Als u de adresruimte van het primaire exemplaar wilt controleren, gaat u naar de resource van het virtuele netwerk voor het primaire exemplaar en selecteert u de adresruimte onder Instellingen. Controleer het bereik onder Adresbereik:
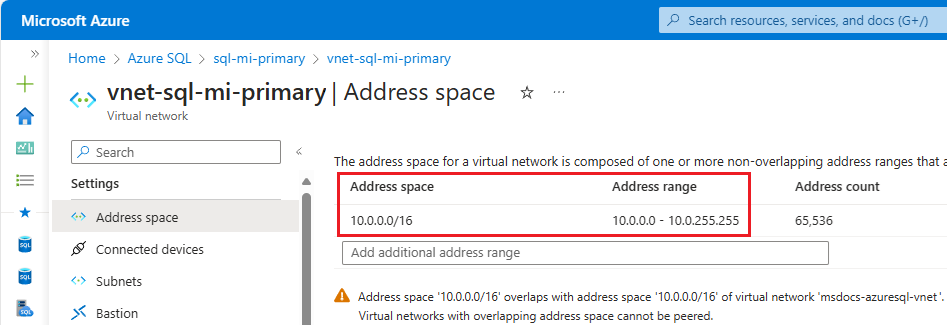
Geef de zone-id van het primaire exemplaar op
Wanneer u uw secundaire exemplaar maakt, moet u de zone-id van het primaire exemplaar opgeven als de DnsZonePartner.
Als u uw secundaire exemplaar maakt in Azure Portal, kiest u op het tabblad Aanvullende instellingen onder Geo-replicatie ja als secundaire failover en selecteert u vervolgens het primaire exemplaar in de vervolgkeuzelijst:
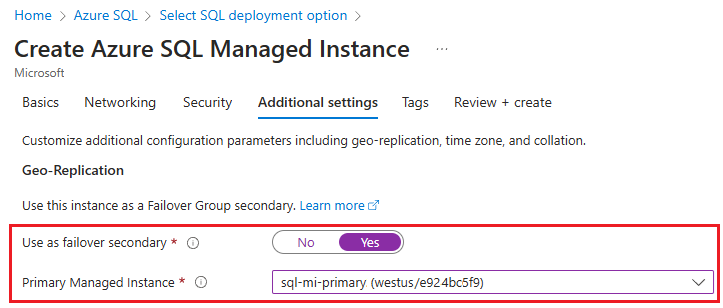
Connectiviteit tussen de exemplaren inschakelen
Verbinding maken iviteit tussen de subnetten van het virtuele netwerk die als host fungeren voor het primaire en secundaire exemplaar, moet worden ingesteld voor een ononderbroken verkeersstroom voor geo-replicatie. Er zijn meerdere manieren om connectiviteit tot stand te brengen tussen beheerde exemplaren in verschillende Azure-regio's, waaronder:
Wereldwijde peering van virtuele netwerken wordt aanbevolen als de meest presterende en robuuste manier om connectiviteit tussen exemplaren in een failovergroep tot stand te brengen. Wereldwijde peering van virtuele netwerken biedt een privéverbinding met lage latentie en hoge bandbreedte tussen de gekoppelde virtuele netwerken met behulp van de Microsoft-backbone-infrastructuur. Er is geen openbaar internet, gateways of extra versleuteling vereist in de communicatie tussen de gekoppelde virtuele netwerken.
Belangrijk
Alternatieve manieren om exemplaren te verbinden waarbij extra netwerkapparaten betrokken zijn, kunnen problemen met connectiviteit of replicatiesnelheid bemoeilijken, waardoor mogelijk actieve betrokkenheid van netwerkbeheerders nodig is en mogelijk aanzienlijk langere oplossingstijd.
Ongeacht het connectiviteitsmechanisme zijn er vereisten waaraan moet worden voldaan om geo-replicatieverkeer te laten stromen:
- Routetabel- en netwerkbeveiligingsgroepen die zijn toegewezen aan subnetten van beheerde exemplaren, worden niet gedeeld tussen de twee gekoppelde virtuele netwerken.
- De NSG-regels (Network Security Group) op het subnet dat als host fungeert voor het primaire exemplaar, staan het volgende toe:
- Binnenkomend verkeer op poort 5022 en poortbereik 11000-11999 van het subnet dat als host fungeert voor het secundaire exemplaar.
- Uitgaand verkeer op poort 5022 en poortbereik 11000-11999 naar het subnet dat als host fungeert voor het secundaire exemplaar.
- De NSG-regels (Network Security Group) op het subnet dat als host fungeert voor het secundaire exemplaar, staan het volgende toe:
- Binnenkomend verkeer op poort 5022 en poortbereik 11000-11999 van het subnet dat als host fungeert voor het primaire exemplaar.
- Uitgaand verkeer op poort 5022 en poortbereik 11000-11999 naar het subnet dat als host fungeert voor het primaire exemplaar.
- IP-adresbereiken van VNets die als primaire en secundaire instantie fungeren, mogen niet overlappen.
- Er is geen indirecte overlapping van IP-adresbereiken tussen de VNets die als host fungeren voor het primaire en secundaire exemplaar, of andere VNets waarmee ze zijn gekoppeld via peering van lokale virtuele netwerken of andere middelen.
Als u andere mechanismen gebruikt voor het bieden van connectiviteit tussen de exemplaren dan de aanbevolen globale peering voor virtuele netwerken, moet u er bovendien voor zorgen dat u het volgende doet:
- Elk netwerkapparaat dat wordt gebruikt, zoals firewalls of virtuele netwerkapparaten (NVA's), blokkeert geen verkeer op de eerder genoemde poorten.
- Routering is correct geconfigureerd en asymmetrische routering wordt vermeden.
- Als u failovergroepen in een hub-and-spoke-netwerktopologie in meerdere regio's implementeert, moet replicatieverkeer rechtstreeks tussen de twee subnetten van het beheerde exemplaar gaan in plaats van omgeleid via de hubnetwerken. Dit helpt u problemen met connectiviteit en replicatiesnelheid te voorkomen.
- Ga in Azure Portal naar de resource van het virtuele netwerk voor uw primaire beheerde exemplaar.
- Selecteer Peerings onder Instellingen en selecteer vervolgens + Toevoegen.
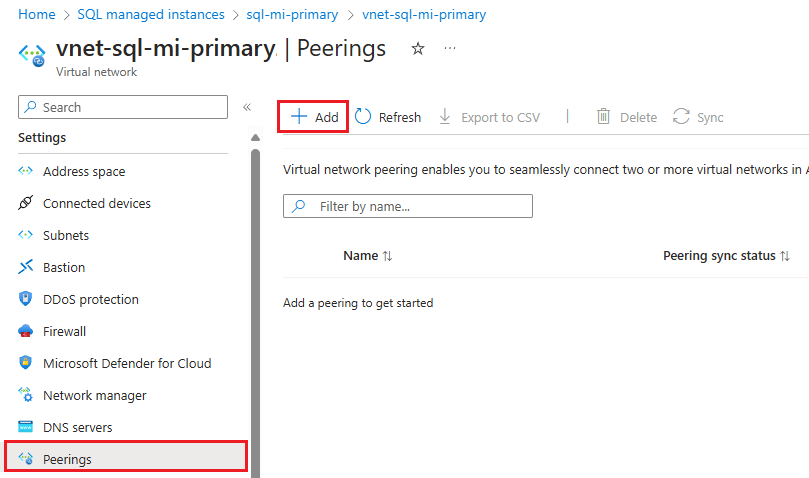
Voer waarden in of selecteer deze voor de volgende instellingen:
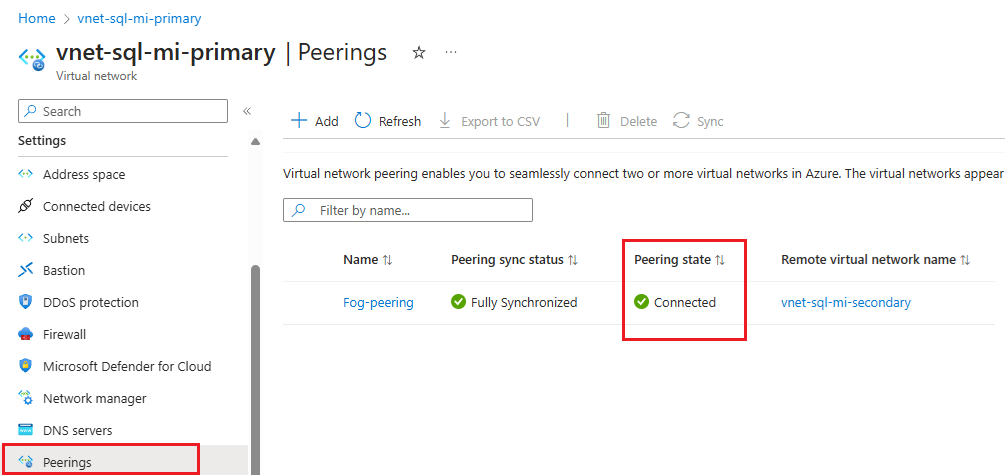
Instellingen Beschrijving Dit virtuele netwerk Naam van peeringkoppeling De naam voor de peering moet uniek zijn binnen het virtuele netwerk. Verkeer naar een extern virtueel netwerk Selecteer Toestaan (standaard) om communicatie tussen de twee virtuele netwerken via de standaardstroom VirtualNetworkin te schakelen. Als u communicatie tussen virtuele netwerken inschakelt, kunnen resources die zijn verbonden met een virtueel netwerk met elkaar communiceren met dezelfde bandbreedte en latentie alsof ze zijn verbonden met hetzelfde virtuele netwerk. Alle communicatie tussen resources in de twee virtuele netwerken vindt plaats via het privénetwerk van Azure.Verkeer dat wordt doorgestuurd vanuit een extern virtueel netwerk De optie Zowel Toegestaan (standaard) als Blokkeren werkt voor deze zelfstudie. Zie Een peering maken voor meer informatie Virtuele netwerkgateway of routeserver Selecteer Geen. Zie Een peering maken voor meer informatie over de andere beschikbare opties. Extern virtueel netwerk Naam van peeringkoppeling De naam van dezelfde peering die moet worden gebruikt in het virtuele netwerk dat als host fungeert voor het secundaire exemplaar. Implementatiemodel voor het virtuele netwerk Selecteer Resource Manager. Ik ken mijn resource-id Laat dit selectievakje uitgeschakeld. Abonnement Selecteer het Azure-abonnement van het virtuele netwerk dat als host fungeert voor het secundaire exemplaar waarmee u wilt peeren. Virtueel netwerk Selecteer het virtuele netwerk dat als host fungeert voor het secundaire exemplaar waarmee u wilt peeren. Als het virtuele netwerk wordt weergegeven, maar grijs wordt weergegeven, kan dit komen doordat de adresruimte voor het virtuele netwerk overlapt met de adresruimte voor dit virtuele netwerk. Als adresruimten van virtuele netwerken elkaar overlappen, kunnen ze niet worden gekoppeld. Verkeer naar een extern virtueel netwerk Toestaan selecteren (standaard) Verkeer dat wordt doorgestuurd vanuit een extern virtueel netwerk De optie Zowel Toegestaan (standaard) als Blokkeren werkt voor deze zelfstudie. Zie Een peering maken voor meer informatie. Virtuele netwerkgateway of routeserver Selecteer Geen. Zie Een peering maken voor meer informatie over de andere beschikbare opties. Selecteer Toevoegen om peering te configureren met het virtuele netwerk dat u hebt geselecteerd. Na een paar seconden selecteert u de knop Vernieuwen en verandert de peeringstatus van Bijwerken naar Verbinding maken ed.
De failovergroep maken
Maak de failovergroep voor uw beheerde exemplaren met behulp van Azure Portal of PowerShell.
Maak de failovergroep voor uw SQL Managed Instances met behulp van Azure Portal.
Selecteer Azure SQL in het menu aan de linkerkant van de Azure-portal. Als Azure SQL niet in de lijst staat, selecteert u Alle services en typt u Azure SQL in het zoekvak. (Optioneel) Selecteer de ster naast Azure SQL om het toe te voegen als favoriet item aan de linkernavigatiebalk.
Selecteer het primaire beheerde exemplaar dat u wilt toevoegen aan de failovergroep.
Ga onder Instellingen naar Failovergroepen voor exemplaren en kies er vervolgens voor om een groep toe te voegen om de pagina voor het maken van de exemplaarfailovergroep te openen.
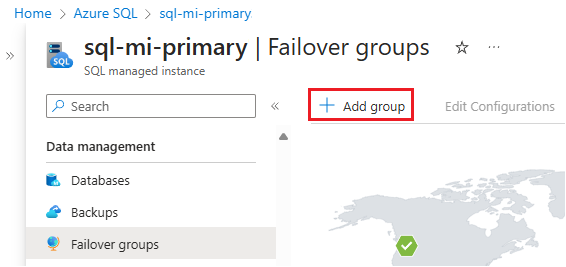
Typ op de pagina Exemplaarfailovergroep de naam van uw failovergroep en kies vervolgens het secundaire beheerde exemplaar in de vervolgkeuzelijst. Selecteer Maken om de failovergroep te maken.
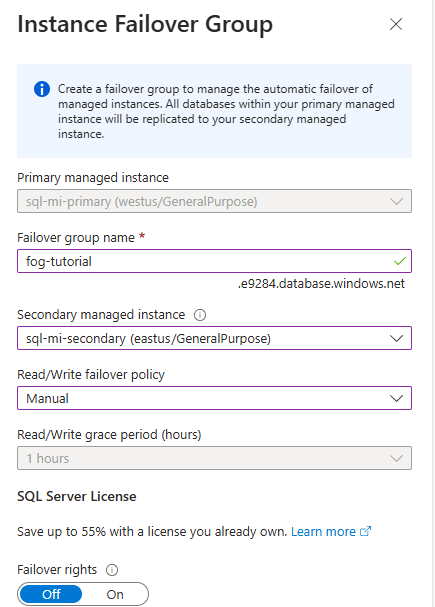
Zodra de implementatie van de failovergroep is voltooid, gaat u terug naar de pagina Failovergroep .
Testfailover
Test failover van uw failovergroep met behulp van Azure Portal of PowerShell.
Test de failover van uw failovergroep met behulp van de Azure-portal.
Ga naar uw secundaire beheerde exemplaar in de Azure-portal, en selecteer onder Instellingen de optie Exemplaarfailovergroepen.
Noteer beheerde exemplaren in de primaire en secundaire rol.
Selecteer Failover en selecteer vervolgens Ja bij de waarschuwing over het verbreken van de verbinding met TDS-sessies.
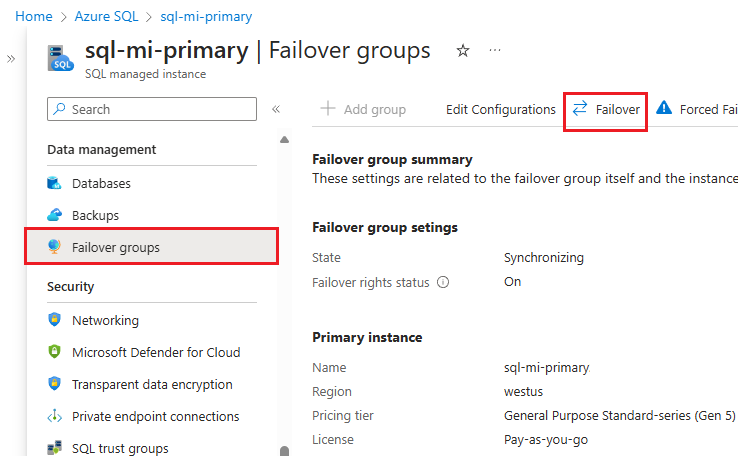
Noteer beheerde exemplaren in de primaire en secundaire rol. Als de failover is geslaagd, zijn de twee exemplaren van rol gewisseld.

Belangrijk
Als rollen niet zijn overgeschakeld, controleert u de connectiviteit tussen de exemplaren en gerelateerde NSG-regels en firewallregels. Ga door met de volgende stap pas nadat de rollen zijn overgeschakeld.
- Ga naar het nieuwe secundaire beheerde exemplaar, en selecteer Failover opnieuw om het primaire exemplaar weer terug te zetten naar de primaire rol.
Listener-eindpunt zoeken
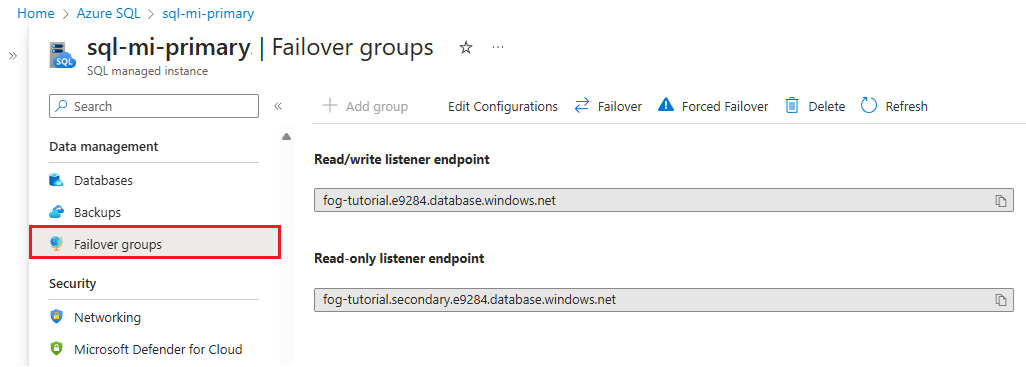
Zodra uw failovergroep is geconfigureerd, werkt u de verbindingsreeks voor uw toepassing bij naar het listener-eindpunt. Uw toepassing wordt verbonden met de listener van de failovergroep in plaats van de primaire database, elastische pool of exemplaardatabase. Op die manier hoeft u de verbindingsreeks niet handmatig bij te werken telkens wanneer uw database-entiteit een failover uitvoert en verkeer wordt doorgestuurd naar de entiteit die momenteel primair is.
Het listener-eindpunt heeft de vorm van fog-name.database.windows.neten is zichtbaar in Azure Portal bij het weergeven van de failovergroep:
Een groep maken tussen exemplaren in verschillende abonnementen
U kunt een failovergroep maken tussen SQL Managed Instances in twee verschillende abonnementen, zolang abonnementen zijn gekoppeld aan dezelfde Microsoft Entra-tenant.
- Wanneer u De PowerShell-API gebruikt, kunt u dit doen door de
PartnerSubscriptionIdparameter voor het secundaire met SQL beheerde exemplaar op te geven. - Wanneer u REST API gebruikt, kan elke exemplaar-id die in de
properties.managedInstancePairsparameter is opgenomen, een eigen abonnements-id hebben. - Azure Portal biedt geen ondersteuning voor het maken van failovergroepen in verschillende abonnementen.
Belangrijk
Azure Portal biedt geen ondersteuning voor het maken van failovergroepen in verschillende abonnementen. Voor failovergroepen in verschillende abonnementen en/of resourcegroepen kan failover niet handmatig worden gestart via Azure Portal vanuit het primaire met SQL beheerde exemplaar. Start deze vanuit het geo-secundaire exemplaar.
Verlies van kritieke gegevens voorkomen
Vanwege de hoge latentie van wide area networks maakt geo-replicatie gebruik van een asynchroon replicatiemechanisme. Asynchrone replicatie maakt de mogelijkheid van gegevensverlies onvermijdelijk als de primaire mislukt. Een toepassingsontwikkelaar kan de sp_wait_for_database_copy_sync opgeslagen procedure onmiddellijk na het doorvoeren van de transactie aanroepen om kritieke transacties te beschermen tegen gegevensverlies. Het aanroepen sp_wait_for_database_copy_sync blokkeert de aanroepende thread totdat de laatste doorgevoerde transactie is verzonden en beperkt in het transactielogboek van de secundaire database. Er wordt echter niet gewacht totdat de verzonden transacties opnieuw worden afgespeeld (opnieuw worden afgespeeld) op de secundaire. sp_wait_for_database_copy_sync is gericht op een specifieke geo-replicatiekoppeling. Elke gebruiker met de verbindingsrechten voor de primaire database kan deze procedure aanroepen.
Notitie
sp_wait_for_database_copy_sync voorkomt gegevensverlies na geo-failover voor specifieke transacties, maar garandeert geen volledige synchronisatie voor leestoegang. De vertraging die wordt veroorzaakt door een sp_wait_for_database_copy_sync procedure-aanroep kan aanzienlijk zijn en is afhankelijk van de grootte van het nog niet verzonden transactielogboek op de primaire op het moment van de oproep.
De secundaire regio wijzigen
Stel dat exemplaar A het primaire exemplaar is, exemplaar B het bestaande secundaire exemplaar is en exemplaar C het nieuwe secundaire exemplaar in de derde regio is. Voer de volgende stappen uit om de overgang te maken:
- Maak exemplaar C met dezelfde grootte als A en in dezelfde DNS-zone.
- Verwijder de failovergroep tussen exemplaren A en B. Op dit moment mislukken pogingen om zich aan te melden omdat de SQL-aliassen voor de listeners van de failovergroep zijn verwijderd en de gateway de naam van de failovergroep niet herkent. De secundaire databases worden losgekoppeld van de primaries en worden lees-/schrijfdatabases.
- Maak een failovergroep met dezelfde naam tussen exemplaar A en C. Volg de instructies in de handleiding failovergroep configureren. Dit is een grootte van de gegevensbewerking en wordt voltooid wanneer alle databases van exemplaar A worden geseed en gesynchroniseerd.
- Verwijder exemplaar B als dat niet nodig is om onnodige kosten te voorkomen.
Notitie
Na stap 2 en totdat stap 3 is voltooid, blijven de databases in exemplaar A onbeveiligd tegen een onherstelbare fout van exemplaar A.
De primaire regio wijzigen
Stel dat exemplaar A het primaire exemplaar is, exemplaar B het bestaande secundaire exemplaar is en exemplaar C het nieuwe primaire exemplaar in de derde regio is. Voer de volgende stappen uit om de overgang te maken:
- Maak exemplaar C met dezelfde grootte als B en in dezelfde DNS-zone.
- Verbinding maken naar exemplaar B en handmatig een failover om het primaire exemplaar over te zetten naar B. Exemplaar A wordt automatisch het nieuwe secundaire exemplaar.
- Verwijder de failovergroep tussen exemplaren A en B. Op dit moment mislukken aanmeldingspogingen met behulp van eindpunten van failovergroepen. De secundaire databases op A worden losgekoppeld van de primaries en worden lees-/schrijfdatabases.
- Maak een failovergroep met dezelfde naam tussen exemplaar B en C. Volg de instructies in de handleiding voor failovergroepen. Dit is een grootte van de gegevensbewerking en wordt voltooid wanneer alle databases van exemplaar A worden geseed en gesynchroniseerd. Op dit moment mislukken aanmeldingspogingen.
- Voer handmatig een failover uit om het C-exemplaar over te schakelen naar de primaire rol. Exemplaar B wordt automatisch het nieuwe secundaire exemplaar.
- Verwijder exemplaar A als dat niet nodig is om onnodige kosten te voorkomen.
Let op
Na stap 3 en totdat stap 4 is voltooid, blijven de databases in exemplaar A onbeveiligd tegen een onherstelbare fout van exemplaar A.
Belangrijk
Wanneer de failovergroep wordt verwijderd, worden de DNS-records voor de listener-eindpunten ook verwijderd. Op dat moment is er een niet-nul waarschijnlijkheid dat iemand anders een failovergroep met dezelfde naam maakt. Omdat namen van failovergroepen wereldwijd uniek moeten zijn, voorkomt u dat u dezelfde naam opnieuw gebruikt. Gebruik geen algemene namen van failovergroepen om dit risico te minimaliseren.
Scenario's inschakelen die afhankelijk zijn van objecten uit de systeemdatabases
Systeemdatabases worden niet gerepliceerd naar het secundaire exemplaar in een failovergroep. Als u scenario's wilt inschakelen die afhankelijk zijn van objecten uit de systeemdatabases, moet u ervoor zorgen dat u dezelfde objecten op het secundaire exemplaar maakt, en dat deze gesynchroniseerd blijven met het primaire exemplaar.
Als u bijvoorbeeld van plan bent om dezelfde aanmeldingen op het secundaire exemplaar te gebruiken, moet u deze maken met de identieke SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Zie Replicatie van aanmeldingen en agenttaken voor meer informatie.
Exemplaareigenschappen en bewaarbeleidexemplaren synchroniseren
Exemplaren in een failovergroep blijven afzonderlijke Azure-resources en er worden geen wijzigingen in de configuratie van het primaire exemplaar automatisch gerepliceerd naar het secundaire exemplaar. Zorg ervoor dat u alle relevante wijzigingen uitvoert op zowel het primaire als het secundaire exemplaar. Als u bijvoorbeeld redundantie van back-upopslag of bewaarbeleid voor langetermijnretentie voor back-ups op een primair exemplaar wijzigt, moet u deze ook wijzigen op het secundaire exemplaar.
Exemplaren schalen
U kunt het primaire en secundaire exemplaar omhoog of omlaag schalen naar een andere rekenkracht binnen dezelfde servicelaag of naar een andere servicelaag. Wanneer u omhoog schaalt binnen dezelfde servicelaag, raden we u aan eerst de geo-secundaire laag omhoog te schalen en vervolgens de primaire laag omhoog te schalen. Wanneer u omlaag schaalt binnen dezelfde servicelaag, keert u de volgorde om: schaal eerst de primaire laag omlaag en schaal vervolgens de secundaire laag omlaag. Wanneer u een exemplaar naar een andere servicelaag schaalt, wordt deze aanbeveling afgedwongen.
De volgorde wordt aangeraden om te voorkomen dat het geo-secundaire exemplaar bij een lagere SKU overbelast raakt en opnieuw moet worden geseed tijdens een upgrade- of downgradeproces.
Bevoegdheden
Machtigingen voor een failovergroep worden beheerd via op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC).
Schrijftoegang van Azure RBAC is nodig voor het maken en beheren van failovergroepen. De rol Inzender voor SQL Managed Instance heeft alle benodigde machtigingen voor het beheren van failovergroepen.
De volgende tabel bevat specifieke machtigingsbereiken voor Azure SQL Managed Instance:
| Actie | Machtiging | Scope |
|---|---|---|
| Failovergroep maken | Schrijftoegang van Azure RBAC | Primair beheerd exemplaar secundair beheerd exemplaar |
| Failovergroep bijwerken | Schrijftoegang van Azure RBAC | Failovergroep Alle databases in het beheerde exemplaar |
| Failovergroep | Schrijftoegang van Azure RBAC | Failovergroep op een nieuw primair beheerd exemplaar |
Beperkingen
Houd rekening met de volgende beperkingen:
- Failovergroepen kunnen niet worden gemaakt tussen twee exemplaren in dezelfde Azure-regio.
- Namen van failovergroepen kunnen niet worden gewijzigd. U moet de groep verwijderen en opnieuw maken met een andere naam.
- Een failovergroep bevat precies twee beheerde exemplaren. Het toevoegen van extra exemplaren aan de failovergroep wordt niet ondersteund.
- Een exemplaar kan op elk moment slechts deelnemen aan één failovergroep.
- Er kan geen failovergroep worden gemaakt tussen twee exemplaren die behoren tot verschillende Azure-tenants.
- Een failovergroep tussen twee exemplaren die behoren tot verschillende Azure-abonnementen, kan niet worden gemaakt met behulp van Azure Portal of Azure CLI. Gebruik in plaats daarvan Azure PowerShell of REST API om een dergelijke failovergroep te maken. Zodra de failovergroep voor meerdere abonnementen is gemaakt, is deze regelmatig zichtbaar in Azure Portal en kunnen alle volgende bewerkingen, waaronder failovers, worden gestart vanuit Azure Portal of Azure CLI.
- De naam van de database wordt niet ondersteund voor databases in een failovergroep. U moet de failovergroep tijdelijk verwijderen om de naam van een database te kunnen wijzigen.
- Systeemdatabases worden niet gerepliceerd naar het secundaire exemplaar in een failovergroep. Daarom moeten voor scenario's die afhankelijk zijn van objecten van de systeemdatabases, zoals serveraanmeldings- en agenttaken, objecten handmatig worden gemaakt op de secundaire exemplaren en ook handmatig gesynchroniseerd blijven nadat er wijzigingen zijn aangebracht in het primaire exemplaar. De enige uitzondering is Service master Key (SMK) voor SQL Managed Instance die automatisch wordt gerepliceerd naar een secundair exemplaar tijdens het maken van een failovergroep. Eventuele volgende wijzigingen van SMK op het primaire exemplaar worden echter niet gerepliceerd naar een secundair exemplaar. Zie Scenario's inschakelen die afhankelijk zijn van objecten uit de systeemdatabases voor meer informatie.
- Failovergroepen kunnen niet worden gemaakt tussen exemplaren als een van deze zich in een exemplaargroep bevindt.
Failovergroepen programmatisch beheren
Failovergroepen kunnen ook programmatisch worden beheerd met behulp van Azure PowerShell, Azure CLI en REST API. In de volgende tabellen wordt de set opdrachten beschreven die beschikbaar zijn. Failovergroepen bevatten een set Azure Resource Manager-API's voor beheer, waaronder de Azure SQL Database REST API en Azure PowerShell-cmdlets. Deze API's vereisen het gebruik van resourcegroepen en ondersteunen op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC). Zie Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) voor meer informatie over het implementeren van toegangsrollen.
| Cmdlet | Beschrijving |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | Met deze opdracht maakt u een failovergroep en registreert u deze op zowel primaire als secundaire exemplaren |
| Set-AzSqlDatabaseInstanceFailoverGroup | Wijzigt de configuratie van een failovergroep |
| Get-AzSqlDatabaseInstanceFailoverGroup | Hiermee wordt de configuratie van een failovergroep opgehaald |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Hiermee wordt een failover van een failovergroep naar het secundaire exemplaar geactiveerd |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Hiermee verwijdert u een failovergroep |
Volgende stappen
Zie de handleiding Een beheerd exemplaar toevoegen aan een failovergroep voor stappen voor het configureren van een failovergroep .
Zie Failover-groepen voor een overzicht van de functie. Zie Stand-byreplica configureren voor meer informatie over het besparen op licentiekosten.