Overzicht van bedrijfscontinuïteit met Azure SQL Managed Instance
Van toepassing op:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dit artikel bevat een overzicht van de mogelijkheden voor bedrijfscontinuïteit en herstel na noodgevallen van Azure SQL Managed Instance, waarin de opties en aanbevelingen worden beschreven voor het herstellen van verstorende gebeurtenissen die kunnen leiden tot gegevensverlies of waardoor uw exemplaar en toepassing niet meer beschikbaar zijn. Meer informatie over wat u moet doen wanneer een gebruiker of toepassingsfout van invloed is op de gegevensintegriteit, een Azure-beschikbaarheidszone of -regio heeft een storing of dat uw toepassing onderhoud vereist.
Overzicht
Bedrijfscontinuïteit in Azure SQL Managed Instance verwijst naar de mechanismen, beleidsregels en procedures waarmee uw bedrijf kan blijven werken in het geval van onderbrekingen door beschikbaarheid, hoge beschikbaarheid en herstel na noodgevallen te bieden.
In de meeste gevallen verwerkt SQL Managed Instance verstorende gebeurtenissen die zich in een cloudomgeving kunnen voordoen en blijven uw toepassingen en bedrijfsprocessen actief. Er zijn echter enkele verstorende gebeurtenissen waarbij het beperken enige tijd kan duren, zoals:
- Gebruiker verwijdert of werkt per ongeluk een rij in een tabel bij.
- Kwaadwillende aanvaller verwijdert gegevens of verwijdert een database.
- Een catastrofale natuurramp neemt een datacenter of beschikbaarheidszone of regio uit.
- Zeldzame datacenter-, beschikbaarheidszone- of regiobrede storing veroorzaakt door een configuratiewijziging, softwarefout of hardwareonderdeelfout.
Beschikbaarheid
Azure SQL Managed Instance wordt geleverd met een kerntolerantie en betrouwbaarheidsbelofte die deze beschermt tegen software- of hardwarefouten. Databaseback-ups worden geautomatiseerd om uw gegevens te beschermen tegen beschadiging of onbedoeld verwijderen. Als PaaS (Platform-as-a-Service) biedt de Azure SQL Managed Instance-service beschikbaarheid als een off-the-shelf-functie met een toonaangevende SLA voor beschikbaarheid van 99,99%.
Hoge beschikbaarheid
Als u hoge beschikbaarheid wilt bereiken in de Azure-cloudomgeving, schakelt u zoneredundantie in, zodat het exemplaar beschikbaarheidszones gebruikt om tolerantie voor zonefouten te garanderen. Veel Azure-regio's bieden beschikbaarheidszones, die gescheiden groepen datacenters zijn binnen een regio met onafhankelijke energie-, koelings- en netwerkinfrastructuur. Beschikbaarheidszones zijn ontworpen om regionale services, capaciteit en hoge beschikbaarheid in de resterende zones te bieden als één zone een storing ondervindt. Door zoneredundantie in te schakelen, is het exemplaar bestand tegen zonegebonden hardware- en softwarefouten en is het herstel transparant voor toepassingen. Wanneer hoge beschikbaarheid is ingeschakeld, kan de Azure SQL Managed Instance-service een SLA met een hogere beschikbaarheid van 99,995% bieden.
Herstel na noodgeval
Als u een hogere beschikbaarheid en redundantie in verschillende regio's wilt bereiken, kunt u mogelijkheden voor herstel na noodgevallen inschakelen om het exemplaar snel te herstellen na een catastrofale regionale storing. Opties voor herstel na noodgevallen met Azure SQL Managed Instance zijn:
- Failovergroepen maken continue synchronisatie mogelijk tussen een primaire en secundaire instantie. Failovergroepen bieden alleen-lezen en alleen-lezen-listener-eindpunten die ongewijzigd blijven, zodat het bijwerken van de toepassing verbindingsreeks s na failover niet nodig is.
- Met geo-herstel kunt u herstellen na een regionale storing door back-ups met geo-replicatie te herstellen wanneer u geen toegang hebt tot uw database in de primaire regio door een nieuwe database te maken op een bestaand exemplaar in een Azure-regio.
Functies die bedrijfscontinuïteit bieden
Er zijn bijvoorbeeld vier belangrijke scenario's voor potentiële onderbrekingen. De volgende tabel bevat functies voor bedrijfscontinuïteit van SQL Managed Instance die u kunt gebruiken om een mogelijk scenario voor bedrijfsonderbreking te beperken:
| Scenario voor bedrijfsonderbreking | Bedrijfscontinuïteitsfunctie |
|---|---|
| Lokale hardware- of softwarefouten die van invloed zijn op het databaseknooppunt. | Om lokale hardware- en softwarefouten te beperken, bevat SQL Managed Instance een beschikbaarheidsarchitectuur, die automatisch herstel van deze fouten garandeert met een SLA van maximaal 99,99%. |
| Gegevensbeschadiging of -verwijdering, meestal veroorzaakt door een fout of menselijke fout in de toepassing. Dergelijke fouten zijn toepassingsspecifiek en kunnen doorgaans niet worden gedetecteerd door de service. | Om uw bedrijf te beschermen tegen gegevensverlies, maakt SQL Managed Instance elke 12 of 24 uur automatisch volledige databaseback-ups, differentiële databaseback-ups en elke 5 tot 10 minuten back-ups van transactielogboeken. Back-ups worden standaard gedurende zeven dagen opgeslagen in geografisch redundante opslag en ondersteunen een configureerbare bewaarperiode voor back-ups voor herstel naar een bepaald tijdstip van maximaal 35 dagen. U kunt een verwijderde database herstellen naar het punt waarop deze is verwijderd als het exemplaar niet is verwijderd of als u langetermijnretentie hebt geconfigureerd. |
| Zeldzame storingen in datacenters of beschikbaarheidszones, mogelijk veroorzaakt door een natuurramp, configuratiewijziging, softwarefout of storing van hardwareonderdelen. | Als u de storing op datacenter- of beschikbaarheidszoneniveau wilt beperken, schakelt u zoneredundantie in voor het SQL Managed Instance om Azure Beschikbaarheidszones te gebruiken en redundantie te bieden voor meerdere fysieke zones binnen een Azure-regio. Door zoneredundantie in te schakelen, zorgt u ervoor dat het beheerde exemplaar bestand is tegen zonefouten met een SLA met maximaal 99,995% hoge beschikbaarheid. |
| Zeldzame regiostoring die van invloed is op alle beschikbaarheidszones en de datacenters die deze omvatten, mogelijk veroorzaakt door een catastrofale natuurramp. | Als u een storing in de hele regio wilt beperken, schakelt u herstel na noodgevallen in met behulp van een van de volgende opties: - Continue gegevenssynchronisatie met failovergroepen naar replica's in een secundaire regio die wordt gebruikt voor failover. - Back-upopslagredundantie instellen op geografisch redundante back-upopslag om geo-herstel te gebruiken. |
Beoogde hersteltijd en beoogd herstelpunt
Wanneer u uw bedrijfscontinuïteitsplan ontwikkelt, begrijpt u de maximaal acceptabele tijd voordat de toepassing volledig wordt hersteld na de verstorende gebeurtenis. De tijd die nodig is voor een toepassing om volledig te herstellen, wordt de RTO (Recovery Time Objective) genoemd. Begrijp ook de maximale periode van recente gegevensupdates (tijdsinterval) die de toepassing kan verdragen bij het herstellen van een niet-geplande verstorende gebeurtenis. Het potentiële gegevensverlies wordt RPO (Recovery Point Objective) genoemd.
In de volgende tabel worden RPO en RTO van elke optie voor bedrijfscontinuïteit vergeleken:
| Optie voor bedrijfscontinuïteit | RTO (downtime) | RPO (gegevensverlies) |
|---|---|---|
| Hoge beschikbaarheid (zoneredundantie inschakelen) |
Doorgaans minder dan 30 seconden | 0 |
| Herstel na noodgevallen (failovergroepen inschakelen) |
1 uur | 5 seconden (afhankelijk van gegevenswijzigingen vóór de verstorende gebeurtenis die niet zijn gerepliceerd) |
| Herstel na noodgevallen (met geo-herstel) |
12 uur | 1 uur |
Een database binnen dezelfde Azure-regio herstellen
U kunt automatische databaseback-ups gebruiken om een database te herstellen naar een bepaald tijdstip in het verleden. Op deze manier kunt u gegevensbeschadigingen herstellen die worden veroorzaakt door menselijke fouten. Met herstel naar een bepaald tijdstip (PITR) kunt u een nieuwe database maken naar hetzelfde exemplaar, of een ander exemplaar, dat de status van gegevens vertegenwoordigt vóór de beschadigde gebeurtenis. De herstelbewerking is een grootte van de gegevensbewerking die ook afhankelijk is van de huidige werkbelasting van het doelexemplaren. Het kan langer duren om een zeer grote of zeer actieve database te herstellen. Zie de hersteltijd van de database voor meer informatie over hersteltijd.
Als de maximaal ondersteunde bewaarperiode voor back-ups voor herstel naar een bepaald tijdstip (PITR) niet voldoende is voor uw toepassing, kunt u deze uitbreiden door een langetermijnretentiebeleid (LTR) voor de database(s) te configureren. Zie Langetermijnretentie van back-ups voor meer informatie.
Een database herstellen naar een bestaand exemplaar
Hoewel dit zelden voorkomt, kan een Azure-datacenter een storing hebben. Wanneer er een storing optreedt, veroorzaakt deze een bedrijfsonderbreking die mogelijk slechts een paar minuten maar ook enkele uren kan duren.
- Een optie is om te wachten totdat uw exemplaar weer online komt wanneer de storing in het datacenter voorbij is. Dit werkt voor toepassingen die hun database offline kunnen hebben. Bijvoorbeeld een ontwikkelingsproject of een gratis proefversie waaraan u niet voortdurend hoeft te werken. Wanneer een datacenter een storing heeft, weet u niet hoe lang de storing kan duren. Deze optie werkt dus alleen als u uw database enige tijd niet nodig hebt.
- Als u geografisch redundante opslag (GRS) of geografisch zone-redundante opslag (GZRS) gebruikt, is een andere optie om een database te herstellen naar een met SQL beheerd exemplaar in elke Azure-regio met behulp van geografisch redundante databaseback-ups (geo-herstel). Geo-herstel maakt gebruik van een geografisch redundante back-up als bron en kan worden gebruikt om een database te herstellen naar het laatst beschikbare tijdstip, zelfs als de database of het datacenter niet toegankelijk is vanwege een storing. De beschikbare back-up vindt u in de gekoppelde regio.
- Ten slotte kunt u snel herstellen na een storing als u een geo-secundaire omgeving hebt geconfigureerd met behulp van een failovergroep voor uw exemplaar, met behulp van klant (aanbevolen) of door Microsoft beheerde failover. Hoewel de failover zelf slechts een paar seconden duurt, duurt het minstens 1 uur voordat de service een door Microsoft beheerde geo-failover activeert, indien geconfigureerd. Dit is nodig om ervoor te zorgen dat de failover wordt gerechtvaardigd door de schaal van de storing. De failover kan ook leiden tot het verlies van onlangs gewijzigde gegevens vanwege de aard van asynchrone replicatie tussen de gekoppelde regio's.
Tijdens het ontwikkelen van uw plan voor bedrijfscontinuïteit moet u weten wat de maximaal acceptabele tijd is voordat de toepassing volledig is hersteld na de verstorende gebeurtenis. De tijd die nodig is om de toepassing volledig te herstellen, wordt RTO (Recovery Time Objective) genoemd. U moet ook inzicht krijgen in de maximale periode van recente gegevensupdates (tijdsinterval) die de toepassing kan verdragen bij het herstellen van een niet-geplande verstorende gebeurtenis. Het potentiële gegevensverlies wordt RPO (Recovery Point Objective) genoemd.
Verschillende herstelmethoden bieden verschillende niveaus van RPO en RTO. U kunt een specifieke herstelmethode kiezen of een combinatie van methoden gebruiken om volledig toepassingsherstel te bereiken.
Gebruik failovergroepen als uw toepassing voldoet aan een van deze criteria:
- Is bedrijfskritiek.
- Heeft een SLA (Service Level Agreement) die 12 uur of meer downtime niet toestaat.
- Downtime kan leiden tot financiële aansprakelijkheid.
- Heeft een hoge snelheid van gegevenswijziging en 1 uur aan gegevensverlies is niet acceptabel.
- De extra kosten van actieve geo-replicatie zijn lager dan de mogelijke financiële verplichting en het bijbehorende bedrijfsverlies.
U kunt ervoor kiezen om een combinatie van databaseback-ups en failovergroepen te gebruiken, afhankelijk van uw toepassingsvereisten.
De volgende secties bevatten een overzicht van de stappen voor het herstellen met behulp van databaseback-ups of failovergroepen.
Voorbereiden op een storing
Ongeacht de functie voor bedrijfscontinuïteit die u gebruikt, moet u:
- Identificeer en bereid het doelexemplaren voor, waaronder firewallregels voor het netwerk, aanmeldingen en
mastermachtigingen op databaseniveau. - Bepalen hoe u clients en clienttoepassingen omleidt naar het nieuwe exemplaar
- Andere afhankelijkheden documenteren, zoals controle-instellingen en waarschuwingen.
Als u zich niet goed voorbereidt, neemt het online brengen van uw toepassingen na een failover of een databaseherstel extra tijd in beslag en vereist waarschijnlijk ook probleemoplossing op een moment van stress: een slechte combinatie.
Failover uitvoeren naar een secundair exemplaar met geo-replicatie
Als u failovergroepen als herstelmechanisme gebruikt, kunt u een beleid voor automatische failover configureren. Nadat de failover is gestart, wordt het secundaire exemplaar de nieuwe primaire instantie, klaar om nieuwe transacties vast te leggen en te reageren op query's, met minimaal gegevensverlies voor de gegevens die nog niet zijn gerepliceerd.
Notitie
Wanneer het datacenter weer online komt, wordt de oude primaire automatisch opnieuw verbonden met de nieuwe primaire om het secundaire exemplaar te worden. Als u de primaire terug wilt verplaatsen naar de oorspronkelijke regio, kunt u een geplande failover handmatig initiëren (failback).
Geo-herstel uitvoeren
Als u geautomatiseerde back-ups gebruikt met geografisch redundante opslag (de standaardopslagoptie wanneer u uw exemplaar maakt), kunt u de database herstellen met geo-herstel. Herstel vindt meestal plaats binnen 12 uur, met gegevensverlies van maximaal één uur, bepaald door het moment waarop de laatste back-up van het logboek is gemaakt en gerepliceerd. Totdat het herstellen is voltooid, kan de database geen transacties registreren en niet reageren op query's. Met geo-herstel wordt de database alleen hersteld naar het laatst beschikbare tijdstip.
Notitie
Als het datacenter weer online komt voordat u uw toepassing overschakelt naar de herstelde database, kunt u het herstel annuleren.
Taken na failover/hersteltaken uitvoeren
Na herstel via een van beide herstelmechanismen moet u de volgende aanvullende taken uitvoeren voordat uw gebruikers en toepassingen opnieuw actief zijn:
- Leid clients en clienttoepassingen om naar het nieuwe exemplaar en de herstelde database.
- Zorg ervoor dat de juiste netwerk-IP-firewallregels zijn ingesteld om gebruikers verbinding te laten maken.
- Zorg ervoor dat de juiste aanmeldingen en
mastermachtigingen op databaseniveau aanwezig zijn (of gebruik ingesloten gebruikers). - Configureer controles, indien van toepassing.
- Configureer waarschuwingen, indien van toepassing.
Notitie
Als u een failovergroep gebruikt en verbinding maakt met het exemplaar met behulp van de listener voor lezen/schrijven, vindt de omleiding na een failover automatisch en transparant plaats voor de toepassing.
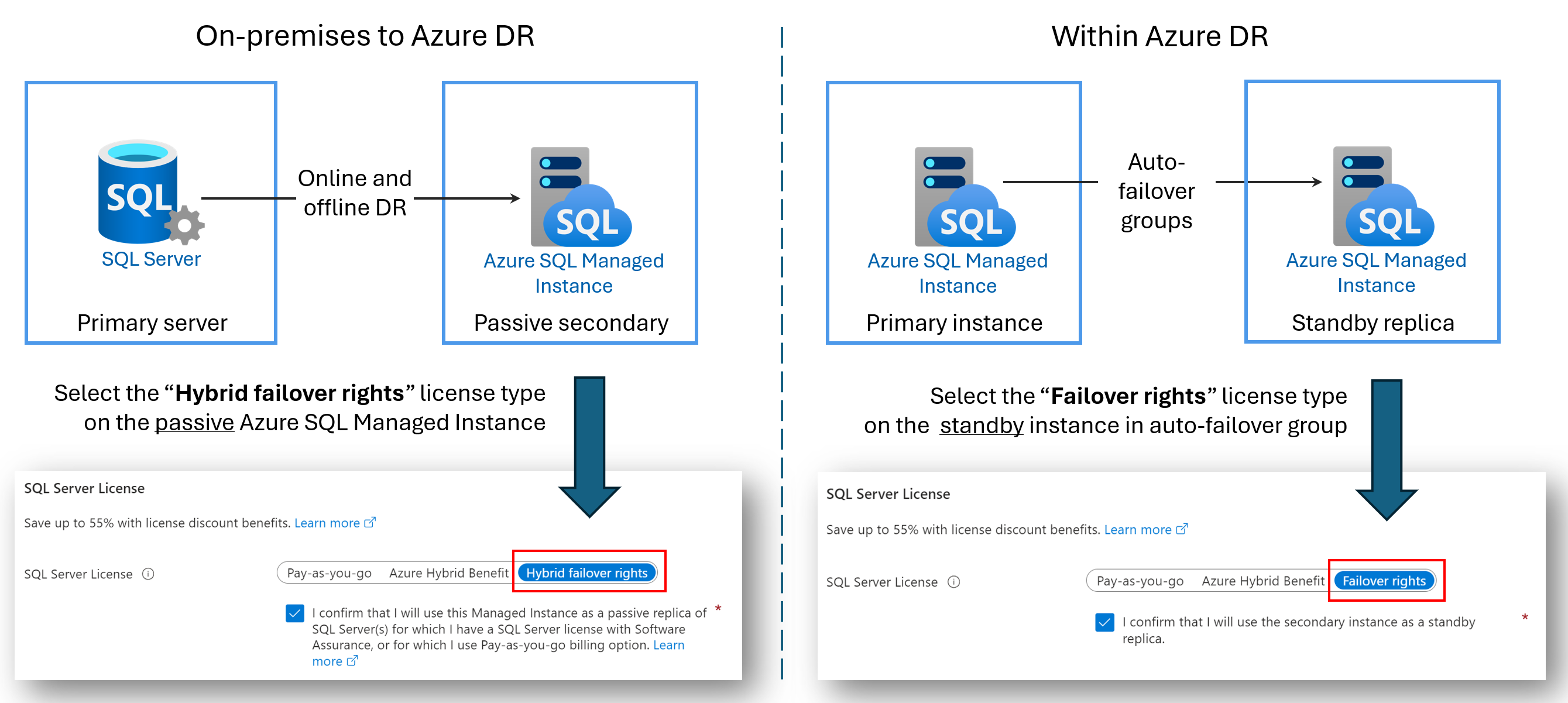
Licentievrije DR-replica's
U kunt besparen op licentiekosten door een secundair Azure SQL Managed Instance te configureren voor herstel na noodgevallen (DR). Dit voordeel is beschikbaar als u een failovergroep gebruikt tussen twee met SQL beheerde exemplaren of als u een hybride koppeling tussen SQL Server en Azure SQL Managed Instance hebt geconfigureerd. Zolang het secundaire exemplaar geen lees- of schrijfworkloads heeft en alleen een passieve stand-by-herstel na noodgeval is, worden er geen kosten in rekening gebracht voor de vCore-licentiekosten die door het secundaire exemplaar worden gebruikt.
Wanneer u een secundair exemplaar aanwijst voor alleen herstel na noodgevallen en er geen lees- of schrijfworkloads worden uitgevoerd op het exemplaar, biedt Microsoft u het aantal vCores waarvoor een licentie is verleend aan het primaire exemplaar zonder extra kosten onder het voordeel van failoverrechten. U wordt nog steeds gefactureerd voor de berekening en opslag die door het secundaire exemplaar wordt gebruikt. Zie de licentievoorwaarden voor SQL Server online in de sectie 'SQL Server - Failover-rechten' voor nauwkeurige voorwaarden van het voordeel van hybride failoverrechten.
De naam van het voordeel is afhankelijk van uw scenario:
- Hybride failoverrechten voor een passieve replica: wanneer u een koppeling configureert tussen SQL Server en Azure SQL Managed Instance, kunt u het voordeel van hybride failoverrechten gebruiken om te besparen op vCore-licentiekosten voor de passieve secundaire replica.
- Failoverrechten voor een stand-byreplica: wanneer u een failovergroep tussen twee beheerde exemplaren configureert, kunt u het voordeel failoverrechten gebruiken om te besparen op vCore-licentiekosten voor de secundaire stand-byreplica.
In het volgende diagram ziet u het voordeel voor elk scenario:
Volgende stappen
Zie Automatische back-ups en failovergroepen voor meer informatie over functies voor bedrijfscontinuïteit. In het geval van een noodgeval raadpleegt u een database herstellen.