Serverloze rekenlaag voor Azure SQL Database
van toepassing op:![]() Azure SQL Database-
Azure SQL Database-
Serverless is een rekenlaag voor individuele databases in Azure SQL Database die automatisch schaalbaar is op basis van de vraag naar de workload en factureert voor de hoeveelheid rekenkracht die per seconde wordt gebruikt. De serverloze rekenlaag onderbreekt ook automatisch databases tijdens inactieve perioden wanneer alleen opslag wordt gefactureerd en hervat automatisch databases wanneer activiteit wordt geretourneerd. De serverloze rekenlaag is beschikbaar in de servicelaag Algemeen gebruik en de servicelaag Hyperscale.
Notitie
Automatisch onderbreken en automatisch hervatten wordt momenteel alleen ondersteund in de servicelaag Algemeen gebruik.
Overzicht
Een bereik voor automatisch schalen van berekeningen en een vertraging bij automatisch onderbreken zijn belangrijke parameters voor de serverloze rekenlaag. De configuratie van deze parameters vormen de prestaties van de database en de rekenkosten.
Prestatieconfiguratie
- De minimale vCores en maximale vCores zijn configureerbare parameters waarmee het beschikbare bereik van rekencapaciteit voor de database te bepalen. Geheugen- en IO-limieten zijn evenredig met het opgegeven vCore-bereik.
- De automatisch-pauze vertraging is een configureerbare parameter die de periode definieert waarin de database inactief moet zijn voordat deze automatisch wordt gepauzeerd. De database wordt automatisch hervat wanneer de volgende aanmelding of andere activiteit plaatsvindt. U kunt ook automatisch onderbreken uitschakelen.
Kosten
De kosten voor een serverloze database zijn de som van de rekenkosten en opslagkosten. De opslagkosten worden op dezelfde manier bepaald als in de ingerichte rekenlaag.
- Wanneer het rekengebruik ligt tussen de minimum- en maximumlimieten die zijn geconfigureerd, zijn de rekenkosten gebaseerd op vCore en het gebruikte geheugen.
- Wanneer het rekengebruik lager is dan de minimumlimieten die zijn geconfigureerd, zijn de rekenkosten gebaseerd op de minimale vCores en het minimumgeheugen dat is geconfigureerd.
- Wanneer de database is onderbroken, zijn de rekenkosten nul en worden alleen opslagkosten gemaakt.
Zie Billingvoor meer kostendetails.
Scenario's
Serverless is geoptimaliseerd voor prijs-prestatieverhouding van individuele databases met intermitterende, onvoorspelbare gebruikspatronen, die zich enige vertraging in het opwarmen van de rekenkracht kunnen veroorloven na perioden van niet-actief gebruik. De ingerichte rekenlaag is daarentegen geoptimaliseerd voor individuele databases of meerdere databases in elastische pools met een hoger gemiddeld gebruik dat geen vertraging kan bieden bij het opwarmen van rekenkracht.
Scenario's die geschikt zijn voor serverloze berekeningen
- Individuele databases met onregelmatige, onvoorspelbare gebruikspatronen tussen perioden van inactiviteit en een lager gemiddeld rekengebruik in de loop van de tijd.
- Individuele databases in de geconfigureerde rekenkrachtlaag die vaak opnieuw worden geschaald, en klanten die liever het herschalen van de rekenkracht aan de service delegeren.
- Nieuwe individuele databases zonder gebruiksgeschiedenis waarbij de grootte van berekeningen moeilijk of niet mogelijk is om te schatten vóór de implementatie in een Azure SQL Database.
Scenario's die geschikt zijn voor geconfigureerde computing
- Individuele databases met meer reguliere, voorspelbare gebruikspatronen en een hoger gemiddeld rekengebruik in de loop van de tijd.
- Databases die prestatieverlies niet kunnen tolereren als gevolg van frequentere geheugenbesnoeiingen of vertragingen bij het hervatten van een gepauzeerde toestand.
- Meerdere databases met onregelmatige, onvoorspelbare gebruikspatronen die kunnen worden samengevoegd in elastische pools voor betere optimalisatie van prijsprestaties.
Vergelijk computing niveaus
De volgende tabel bevat een overzicht van het onderscheid tussen de serverloze rekenlaag en de ingerichte rekenlaag:
| serverloze rekenkracht | Geconfigureerde rekeneenheid | |
|---|---|---|
| databasegebruikspatroon | Onregelmatig, onvoorspelbaar gebruik met een lager gemiddeld rekengebruik in de loop van de tijd. | Meer reguliere gebruikspatronen met een hoger gemiddeld rekengebruik in de loop van de tijd of meerdere databases met behulp van elastische pools. |
| inspanningen voor prestatiebeheer | Lagere | Hoger |
| Rekenkundige schaalaanpassing | Automatisch | Handmatig |
| compute-reactiesnelheid | Lager na inactieve perioden | Onmiddellijk |
| factureringsgranulariteit | Per seconde | Per uur |
Aankoopmodel en servicelaag
In de volgende tabel wordt serverloze ondersteuning beschreven op basis van aankoopmodel, servicelagen en hardware:
| categorie | Ondersteund | niet ondersteund |
|---|---|---|
| aankoopmodel | vCore- | DTU |
| Servicelaag |
Algemeen Gebruik Hyperscale- |
Zakelijk cruciaal |
| Hardware | Standard-series (Gen5) | Alle andere hardware |
Automatisch schalen
Reactiesnelheid schalen
Serverloze databases worden uitgevoerd op een machine met voldoende capaciteit om te voldoen aan de vraag naar resources zonder onderbreking voor een hoeveelheid aangevraagde rekenkracht, binnen de limieten die zijn ingesteld door de maximale vCores-waarde. Soms treedt belastingverdeling automatisch op als de machine binnen een paar minuten niet kan voldoen aan de vraag naar resources. Als de vraag naar resources bijvoorbeeld 4 vCores is, maar er slechts 2 vCores beschikbaar zijn, kan het enkele minuten duren voordat er 4 vCores worden geleverd. De database blijft online tijdens taakverdeling, met uitzondering van een korte periode aan het einde van de bewerking wanneer verbindingen worden verbroken.
Geheugenbeheer
In zowel de servicelagen Algemeen gebruik als Hyperscale wordt geheugen voor serverloze databases vaker vrijgemaakt dan voor ingerichte rekendatabases. Dit gedrag is belangrijk om de kosten in serverloos te beheren en kan van invloed zijn op de prestaties.
Cacheherstel
In tegenstelling tot ingerichte rekendatabases wordt geheugen uit de SQL-cache vrijgemaakt van een serverloze database wanneer het CPU- of actieve cachegebruik laag is.
- Actief cachegebruik wordt beschouwd als laag wanneer de totale grootte van de laatst gebruikte cachevermeldingen gedurende een bepaalde periode onder een drempelwaarde valt.
- Wanneer cacheherstel wordt geactiveerd, wordt de grootte van de doelcache stapsgewijs verkleind tot een fractie van de vorige grootte en wordt het vrijmaken alleen voortgezet als het gebruik laag blijft.
- Wanneer cacheherstel plaatsvindt, is het beleid voor het selecteren van cachevermeldingen die moeten worden verwijderd hetzelfde selectiebeleid als voor ingerichte rekendatabases wanneer de geheugendruk hoog is.
- De cachegrootte wordt nooit lager dan de minimale geheugenlimiet, zoals gedefinieerd door minimale vCores.
In zowel serverloze als ingerichte rekendatabases kunnen cachevermeldingen worden verwijderd als al het beschikbare geheugen wordt gebruikt.
Wanneer het CPU-gebruik laag is, kan het actieve cachegebruik hoog blijven, afhankelijk van het gebruikspatroon en geheugenherstel voorkomen. Er kunnen ook andere vertragingen optreden nadat de gebruikersactiviteit stopt voordat geheugenherstel plaatsvindt als gevolg van periodieke achtergrondprocessen die reageren op eerdere gebruikersactiviteit. Verwijderbewerkingen en opschoningstaken van Query Store genereren bijvoorbeeld ghostrecords die zijn gemarkeerd voor verwijdering, maar die niet fysiek worden verwijderd totdat het ghost-opschoonproces wordt uitgevoerd. Het opschonen van "ghost" gegevens kan inhouden dat gegevenspagina's in de cache worden gelezen.
Cachehydratatie
De SQL-geheugencache groeit naarmate gegevens op dezelfde manier van schijf worden opgehaald en met dezelfde snelheid als voor ingerichte databases. Wanneer de database druk is, mag de cache ongehinderd groeien zolang er geheugen beschikbaar is.
Beheer van schijfcache
In de Hyperscale-servicelaag voor zowel serverloze als ingerichte rekenlagen maakt elke rekenreplica gebruik van een RBPEX-cache (Resilient Buffer Pool Extension), waarin gegevenspagina's op lokale SSD worden opgeslagen om io-prestaties te verbeteren. In de serverloze rekenlaag voor Hyperscale groeit de RBPEX-cache voor elke rekenreplica automatisch en verkleint deze als reactie op toenemende en afnemende workloadvraag. De maximale grootte van de RBPEX-cache kan toenemen tot drie keer het maximale geheugen dat voor de database is geconfigureerd. Voor informatie over maximale geheugen- en RBPEX-limieten bij automatisch schalen in serverloze omgevingen, zie serverloze Hyperscale-resourcelimieten.
Automatisch onderbreken en automatisch hervatten
Op dit moment worden serverloze automatische onderbrekingen en automatisch hervatten alleen ondersteund in de laag Algemeen gebruik.
Automatisch onderbreken
Automatisch onderbreken wordt geactiveerd als aan alle volgende voorwaarden wordt voldaan tijdens de vertraging voor automatisch onderbreken:
- Aantal sessies = 0
- CPU = 0 voor gebruikersworkload die wordt uitgevoerd in de resourcegroep van de gebruiker
Er is een optie beschikbaar om het automatisch pauzeren indien gewenst uit te schakelen.
De volgende functies bieden geen ondersteuning voor automatisch onderbreken, maar bieden wel ondersteuning voor automatisch schalen. Als een van de volgende functies wordt gebruikt, moet automatisch onderbreken worden uitgeschakeld en blijft de database online, ongeacht de duur van inactiviteit van de database:
- Geo-replicatie (actieve geo-replicatie en failovergroepen).
- Langetermijnbewaring van back-ups (LTR).
- De synchronisatiedatabase die wordt gebruikt in SQL Data Sync. In tegenstelling tot synchronisatiedatabases ondersteunen de hub- en liddatabases automatisch pauzeren.
- DNS-alias gemaakt voor de logische server die een serverloze database bevat.
- Elastic Jobs, serverloze database met automatische pauze ingeschakeld wordt niet ondersteund als Job Database. Serverloze databases waarop elastische taken zijn gericht, ondersteunen automatisch onderbreken. Taakverbindingen hervatten een database.
Automatisch onderbreken wordt tijdelijk voorkomen tijdens de implementatie van sommige service-updates, waarvoor de database online moet zijn. In dergelijke gevallen wordt automatisch onderbreken opnieuw toegestaan zodra de service-update is voltooid.
Problemen met automatisch pauzeren oplossen
Als automatisch onderbreken is ingeschakeld en functies die automatisch onderbreken blokkeren niet worden gebruikt, maar een database na de vertragingsperiode niet automatisch onderbreekt, kunnen toepassings- of gebruikerssessies mogelijk automatisch onderbreken verhinderen.
Als u wilt zien of er momenteel toepassings- of gebruikerssessies zijn verbonden met de database, maakt u verbinding met de database met behulp van een clienthulpprogramma en voert u de volgende query uit:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Fooi
Nadat u de query hebt uitgevoerd, moet u de verbinding met de database verbreken. Anders voorkomt de geopende sessie die door de query wordt gebruikt het automatisch pauzeren.
- Als de resultaatset niet-leeg is, geeft dit aan dat er momenteel sessies zijn die automatische pauzering verhinderen.
- Als de resultatenset leeg is, is het nog steeds mogelijk dat sessies zijn geopend, wellicht voor een korte tijd, op een bepaald moment eerder tijdens de automatische pauzeperiode. Als u wilt controleren op activiteit tijdens de vertragingsperiode, kunt u Controle voor Azure SQL Database en Azure Synapse Analytics gebruiken en controlegegevens voor de relevante periode onderzoeken.
Belangrijk
De aanwezigheid van geopende sessies, met of zonder gelijktijdig CPU-gebruik in de gebruikersresourcegroep, is de meest voorkomende reden voor een serverloze database om niet automatisch te onderbreken zoals verwacht.
Automatisch hervatten
Automatisch hervatten wordt geactiveerd als er op enig moment aan een van de volgende voorwaarden is voldaan:
| Kenmerk | Trigger voor automatisch hervatten |
|---|---|
| Verificatie en autorisatie | Inloggen |
| Detectie van bedreigingen | Instellingen voor detectie van bedreigingen in- of uitschakelen op database- of serverniveau. Instellingen voor detectie van bedreigingen wijzigen op database- of serverniveau. |
| Gegevensdetectie en -classificatie | Vertrouwelijkheidslabels toevoegen, wijzigen, verwijderen of weergeven |
| Controle | Controlerecords weergeven. Controlebeleid bijwerken of weergeven. |
| Gegevensmaskering | Regels voor gegevensmaskering toevoegen, wijzigen, verwijderen of weergeven |
| Transparante gegevensversleuteling | De staat of status van transparante gegevensversleuteling bekijken |
| Evaluatie van beveiligingsproblemen | Handmatig geïnitieerde scans en periodieke scans indien ingeschakeld |
| Query (prestatie) gegevensopslag | Query Store-instellingen wijzigen of weergeven |
| Aanbevelingen voor prestaties | Prestatieaanaanvelingen weergeven of toepassen |
| Automatisch afstemmen | Toepassing en verificatie van aanbevelingen voor automatisch afstemmen, zoals automatisch indexeren |
| Database kopiëren | Maak een database als kopie. Exporteren naar een BACPAC-bestand. |
| SQL-gegevenssynchronisatie | Synchronisatie tussen hub- en liddatabases die worden uitgevoerd volgens een configureerbaar schema of handmatig worden uitgevoerd |
| Bepaalde databasemetagegevens wijzigen | Nieuwe databasetags toevoegen. Wijzigen van de maximale vCores, minimale vCores, of de automatische pauzevertraging. |
| SQL Server Management Studio (SSMS) | Wanneer u SSMS-versies eerder dan 18.1 gebruikt en een nieuw queryvenster opent voor een database op de server, wordt elke automatisch onderbroken database op dezelfde server hervat. Dit gedrag treedt niet op als u SSMS versie 18.1 of hoger gebruikt. |
Bewakings-, beheer- of andere oplossingen die een van deze bewerkingen uitvoeren, activeren automatisch hervatting. Automatisch hervatten wordt ook geactiveerd tijdens de implementatie van sommige service-updates waarvoor de database online moet zijn.
Connectiviteit
Als een serverloze database is onderbroken, wordt de database hervat met de eerste verbindingspoging en wordt een fout geretourneerd waarin wordt aangegeven dat de database niet beschikbaar is met foutcode 40613. Zodra de database is hervat, probeert u de aanmelding opnieuw om verbinding te maken. Databaseclients die de aanbevelingen voor de logica van opnieuw proberen verbindingen volgen, hoeven niet te worden gewijzigd. Voor opties en aanbevelingen voor opnieuw proberen van verbindingen raadpleegt u:
- Logica voor herconnectie in SqlClient
- Logica voor opnieuw verbinden in SQL Database met behulp van Entity Framework Core
- Logica voor het opnieuw proberen van verbindingen in SQL Database met behulp van Entity Framework 6
- Opnieuw verbindingslogica in de SQL Database met behulp van ADO.NET
Wachttijd
De latentie voor automatisch hervatten en automatisch onderbreken van een serverloze database is doorgaans 1 minuut tot automatisch hervatten en 1-10 minuten na het verstrijken van de vertragingsperiode voor automatisch onderbreken.
Door de klant beheerde transparante gegevensversleuteling (BYOK)
Sleutelverwijdering of intrekking
Als u klantbeheerde transparante gegevensversleuteling (BYOK) gebruikt en de serverloze database automatisch wordt onderbroken wanneer sleutelverwijdering of intrekking plaatsvindt, blijft de database in de automatisch onderbroken toestand. In dit geval wordt de database binnen ongeveer 10 minuten na hervatting ontoegankelijk. Zodra de database niet toegankelijk is, is het herstelproces hetzelfde als voor ingerichte rekendatabases. Als de serverloze database online is wanneer de sleutel wordt verwijderd of ingetrokken, is de database ook binnen ongeveer 10 minuten ontoegankelijk op dezelfde manier als bij ingerichte rekendatabases.
Sleutelrotatie
Als u door de klant beheerde transparante data-encryptie (BYOK) gebruikt en serverloze automatische pauzering is ingeschakeld, wordt de database automatisch hervat wanneer sleutels worden gewijzigd. De database wordt vervolgens automatisch onderbroken wanneer aan voorwaarden voor automatisch onderbreken wordt voldaan.
Een nieuwe serverloze database maken
Het maken van een nieuwe database of het verplaatsen van een bestaande database naar een serverloze rekenlaag volgt hetzelfde patroon als het maken van een nieuwe database in de ingerichte rekenlaag en omvat de volgende twee stappen:
Geef de servicedoelstelling op. De servicedoelstelling schrijft de servicelaag, hardwareconfiguratie en maximale vCores voor. Zie serverloze resourcelimieten voor opties voor servicedoelstelling
Specificeer eventueel de minimale vCores en de automatische onderbrekingsvertraging om hun standaardwaarden te wijzigen. In de volgende tabel ziet u de beschikbare waarden voor deze parameters.
Parameter Keuzes op basis van waarden Standaardwaarde Minimale vCores Is afhankelijk van de maximaal geconfigureerde vCores: zie resourcelimieten. 0.5 vCores Vertraging bij automatisch pauzeren Minimaal: 15 minuten
Maximum: 10.080 minuten (zeven dagen)
Stappen: 1 minuut
Automatisch onderbreken uitschakelen: -160 minuten
In de volgende voorbeelden wordt een nieuwe database gemaakt in de serverloze rekenlaag.
Azure Portal gebruiken
Zie quickstart: Een individuele database maken in Azure SQL Database met behulp van azure Portal.
PowerShell gebruiken
Maak een nieuwe serverloze database voor algemeen gebruik met het volgende PowerShell-voorbeeld:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Azure CLI gebruiken
Maak een nieuwe serverloze database voor algemeen gebruik met het volgende Azure CLI-voorbeeld:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Transact-SQL (T-SQL) gebruiken
Wanneer u T-SQL gebruikt om een nieuwe serverloze database te maken, worden standaardwaarden toegepast voor de minimale vCores en vertraging bij automatisch onderbreken. Hun waarden kunnen later worden gewijzigd vanuit Azure Portal of via API, waaronder PowerShell, Azure CLI en REST.
Zie CREATE DATABASEvoor meer informatie.
Maak een nieuwe serverloze database voor algemeen gebruik met het volgende T-SQL-voorbeeld:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Een database verplaatsen tussen rekenlagen of servicelagen
Een database kan worden verplaatst tussen de ingerichte rekenlaag en de serverloze rekenlaag.
Een serverloze database kan ook worden verplaatst van de servicelaag Algemeen gebruik naar de Hyperscale-servicelaag. Raadpleeg Hyperscale-databases beheren voor meer informatie.
Wanneer u een database verplaatst tussen rekenlagen, geeft u het rekenmodel parameter op als Serverless of Provisioned bij het gebruik van PowerShell of Azure CLI, of de SERVICE_OBJECTIVE bij het gebruik van T-SQL. Bekijk resourcelimieten om de juiste servicedoelstelling te identificeren.
In de volgende voorbeelden wordt een bestaande database verplaatst van ingerichte rekenkracht naar serverloos.
PowerShell gebruiken
Verplaats een ingerichte rekendatabase algemeen gebruik naar de serverloze rekenlaag met het volgende PowerShell-voorbeeld:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Azure CLI gebruiken
Verplaats een ingerichte database voor algemeen gebruik naar de serverloze rekenlaag met het volgende Azure CLI-voorbeeld:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Transact-SQL (T-SQL) gebruiken
Wanneer u T-SQL gebruikt om een database tussen rekenlagen te verplaatsen, worden standaardwaarden toegepast voor de minimale vCores en vertraging bij automatisch onderbreken. Hun waarden kunnen vervolgens worden gewijzigd vanuit Azure Portal of via API, waaronder PowerShell, Azure CLI en REST. Zie ALTER DATABASEvoor meer informatie.
Verplaats een ingerichte rekendatabase algemeen gebruik naar de serverloze rekenlaag met het volgende T-SQL-voorbeeld:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Serverloze configuratie wijzigen
PowerShell gebruiken
Gebruik Set-AzSqlDatabase om de maximale of minimale vCores te wijzigen en vertraging automatisch te onderbreken. Gebruik de argumenten MaxVcore, MinVcoreen AutoPauseDelayInMinutes. Serverloze automatische onderbreking wordt momenteel niet ondersteund in de Hyperscale-laag, dus het argument vertraging automatisch onderbreken is alleen van toepassing op de laag Algemeen gebruik.
Azure CLI gebruiken
Gebruik az sql db update om de maximale of minimale vCores te wijzigen en de autopause-vertraging aan te passen. Gebruik de argumenten capacity, min-capacityen auto-pause-delay. Serverloze automatische onderbreking wordt momenteel niet ondersteund in de Hyperscale-laag, dus het argument vertraging automatisch onderbreken is alleen van toepassing op de laag Algemeen gebruik.
Monitor
Gebruikte en gefactureerde resources
De resources van een serverloze database omvatten het app-pakket, het SQL-exemplaar en de entiteiten van de gebruikersresourcegroep.
App-pakket
Het app-pakket is de buitenste grens voor resourcebeheer voor een database, ongeacht of de database zich in een serverloze of ingerichte rekenlaag bevindt. Het app-pakket bevat het SQL-exemplaar en externe services, zoals Zoeken in volledige tekst, die samen alle gebruikers- en systeembronnen die door een database in SQL Database worden gebruikt, omvatten. Het SQL-exemplaar overheerst over het algemeen de totale hulpbronnenbenutting binnen het app-pakket.
Gebruikersresourcepool
De gebruikersresourcegroep is een binnenste resourcebeheergrens voor een database, ongeacht of de database zich in een serverloze of ingerichte rekenlaag bevindt. De gebruikersresourcegroep beheert CPU en IO voor gebruikersworkloads gegenereerd door DDL-query's (CREATE en ALTER) en DML-query's (INSERT, UPDATE, DELETE, MERGE, en SELECT). Deze query's vertegenwoordigen over het algemeen het grootste deel van het gebruik binnen het app-pakket.
Statistieken
De volgende tabel bevat metrische gegevens voor het bewaken van het resourcegebruik van het app-pakket en de gebruikersresourcegroep van een serverloze database, inclusief geo-replica's:
| Entiteit | Metriek | Beschrijving | Eenheden |
|---|---|---|---|
| App-pakket | app_cpu_verbruik_percentage | Het percentage vCores dat door de app wordt gebruikt ten opzichte van het maximum aantal vCores dat is toegestaan voor de app. Voor serverloze Hyperscale wordt deze metrische waarde weergegeven voor alle primaire replica's, benoemde replica's en geo-replica's. | Percentage |
| App-pakket | applicatie_cpu_in_rekening_gebracht | Het rekenbedrag dat tijdens de rapportageperiode wordt gefactureerd voor de app. Het bedrag dat tijdens deze periode wordt betaald, is het product van deze metrische waarde en de prijs van de vCore-eenheid. De waarden van deze metrische waarde worden bepaald door het maximum aantal gebruikte CPU's en het geheugen dat elke seconde wordt gebruikt. Als de gebruikte hoeveelheid kleiner is dan de minimale hoeveelheid die is ingericht op basis van de minimale vCores en het minimale geheugen, wordt het ingerichte minimumbedrag gefactureerd. Om CPU te vergelijken met geheugen voor factureringsdoeleinden, wordt het geheugen genormaliseerd in eenheden van vCores door de grootte van het geheugen in GB met 3 GB per vCore te wijzigen. Voor serverloze Hyperscale wordt deze metrische waarde weergegeven voor de primaire replica en eventuele benoemde replica's. |
vCore seconden |
| App-pakket | app_cpu_aangerekende_HA_replica's | Alleen van toepassing op serverloze Hyperscale. De som van de rekencapaciteit die in rekening wordt gebracht voor alle apps met HA-replica's tijdens de rapportageperiode. Deze som is van toepassing op de HA-replica's die behoren tot de primaire replica of de HA-replica's die behoren tot een bepaalde benoemde replica. Voordat de som over HA-replica's wordt berekend, wordt de hoeveelheid rekentijd die wordt gefactureerd voor een afzonderlijke HA-replica op dezelfde manier bepaald als voor de primaire replica of een benoemde replica. Voor serverloze Hyperscale wordt deze metrische waarde weergegeven voor alle primaire replica's, benoemde replica's en geo-replica's. Het bedrag dat tijdens de rapportageperiode is betaald, is het product van deze metrische waarde en de prijs van de vCore-eenheid. | vCore-seconden |
| App-pakket | app_geheugen_percentage | Percentage geheugen dat door de app wordt gebruikt ten opzichte van het maximale geheugen dat is toegestaan voor de app. Voor serverloze Hyperscale wordt deze metrische waarde weergegeven voor alle primaire replica's, benoemde replica's en geo-replica's. | Percentage |
| Gebruikersresourcepool | CPU-percentage | Percentage vCores dat wordt gebruikt door de gebruikersworkload ten opzichte van het maximum aantal vCores dat is toegestaan voor de gebruikersworkload. | Percentage |
| Gebruikersresourcepool | data_IO_percent | Percentage gegevens-IOPS dat wordt gebruikt door gebruikersworkload ten opzichte van de maximale gegevens-IOPS die zijn toegestaan voor de gebruikersworkload. | Percentage |
| Gebruikersresourcepool | log_IO_percent | Percentage log MB/s dat wordt gebruikt door gebruikersbelasting relatief aan het maximale log MB/s dat is toegestaan voor de gebruikersbelasting. | Percentage |
| Gebruikersresourcepool | percentage werknemers | Percentage werknemers dat wordt gebruikt door de gebruikersworkload ten opzichte van het maximum aantal werknemers dat is toegestaan voor de gebruikersworkload. | Percentage |
| Gebruikersresourcepool | sessies_procent | Percentage sessies dat wordt gebruikt door gebruikersworkload ten opzichte van het maximum aantal sessies dat is toegestaan voor de gebruikersworkload. | Percentage |
Onderbreek en hervat status
In het geval van een serverloze database waarvoor automatisch onderbreken is ingeschakeld, bevat de status die wordt gerapporteerd de volgende waarden:
| Status | Beschrijving |
|---|---|
| Online | De database is online. |
| Onderbreken | De database gaat van online naar gepauzeerd. |
| Onderbroken | De database is gepauzeerd. |
| Hervatten | De database wordt overgezet van onderbroken naar online. |
Azure Portal gebruiken
In Azure Portal wordt de databasestatus weergegeven op de overzichtspagina van de database en op de overzichtspagina van de server. Ook in Azure Portal kan de geschiedenis van gebeurtenissen onderbreken en hervatten van een serverloze database worden weergegeven in het activiteitenlogboek.
PowerShell gebruiken
Bekijk de huidige databasestatus met behulp van het volgende PowerShell-voorbeeld:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Azure CLI gebruiken
Bekijk de huidige databasestatus met behulp van het volgende Azure CLI-voorbeeld:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Resourcelimieten
Zie serverloze rekenlaagvoor resourcelimieten.
Facturering
De hoeveelheid rekenkracht die wordt gefactureerd voor een serverloze database is het maximum van de GEBRUIKTE CPU en het geheugen dat elke seconde wordt gebruikt. Als de gebruikte hoeveelheid CPU en geheugen kleiner is dan de minimale hoeveelheid die voor elke resource is ingericht, wordt het ingerichte bedrag gefactureerd. Om cpu te vergelijken met geheugen voor factureringsdoeleinden, wordt het geheugen genormaliseerd in eenheden van vCores door het aantal GB met 3 GB per vCore te vergroten.
- gefactureerde: CPU en geheugen
- Bedrag gefactureerd: vCore-eenheidprijs * maximum (minimum vCores, gebruikte vCores, minimumgeheugen GB * 1/3, gebruikte geheugen GB * 1/3)
- factureringsfrequentie: per seconde
De prijs van de vCore-eenheid zijn de kosten per vCore per seconde.
Raadpleeg de pagina met prijzen van Azure SQL Database voor specifieke eenheidsprijzen in een bepaalde regio.
De hoeveelheid rekenkracht die bij serverloze omgevingen wordt gefactureerd voor een algemene database, of een primaire of benoemde Hyperscale-replica, wordt weergegeven door de volgende metriek:
- Metrische: app_cpu_billed (vCore seconden)
- Definitie: maximum (minimale vCores, gebruikte vCores, minimumgeheugen GB * 1/3, geheugen GB gebruikt * 1/3)
- rapportagefrequentie: per minuut op basis van metingen per seconde die over 1 minuut zijn geaggregeerd.
De hoeveelheid computerkracht die wordt gefactureerd voor serverloze diensten voor Hyperscale HA-replica's die behoren tot de primaire replica of een benoemde replica, wordt weergegeven door de volgende metriek:
- Metrische: app_cpu_billed_HA_replicas (vCore seconden)
- Definitie: De som van het maximum (minimale vCores, gebruikte vCores, minimumgeheugen GB * 1/3, gebruikt geheugen GB * 1/3) voor alle HA-replica's die behoren tot hun ouderresource.
- Bovenliggende bron en meetgegevens-eindpunt: de primaire replica en elke benoemde replica geven elk afzonderlijk deze metriek weer, die het verbruik meet dat in rekening wordt gebracht voor gekoppelde HA-replica's.
- rapportagefrequentie: per minuut op basis van metingen per seconde die zijn geaggregeerd over 1 minuut.
Minimale rekenfactuur
Als een serverloze database is onderbroken, is de rekenfactuur nul. Als een serverloze database niet gepauzeerd is, is de minimale factuur voor rekenkracht ten minste gelijk aan de hoeveelheid vCores, gebaseerd op het maximum (minimale vCores, minimaal geheugen in GB * 1/3).
Voorbeelden:
- Stel dat een serverloze database in de laag Algemeen gebruik niet wordt onderbroken en geconfigureerd met 8 maximale vCores en 1 minimale vCore die overeenkomt met minimaal 3,0 GB geheugen. Vervolgens wordt de minimale rekencapaciteitsfactuur bepaald door het maximum te nemen van (1 vCore, 3,0 GB * 1 vCore / 3 GB) = 1 vCore.
- Stel dat een serverloze database in de laag Algemeen gebruik niet is onderbroken en geconfigureerd met 4 maximale vCores en 0,5 minimale vCores die overeenkomen met minimaal 2,1 GB geheugen. De minimale rekenfactuur is gebaseerd op het maximum (0,5 vCores, (2,1 GB * 1 vCore / 3 GB)) = 0,7 vCores.
- Stel dat een serverloze database in de Hyperscale-laag een primaire replica heeft met één HA-replica en één benoemde replica zonder HA-replica's. Stel dat elke replica is geconfigureerd met 8 maximale vCores en 1 minimale vCore die overeenkomt met minimaal 3 GB geheugen. Vervolgens zijn de minimale rekenkosten voor de primaire replica, HA-replica en aangewezen replica elk gebaseerd op maximum (1 vCore, 3 GB * 1 vCore / 3 GB) = 1 vCore.
De prijscalculator van Azure SQL Database voor serverloos kan worden gebruikt om het minimale geheugen te bepalen dat kan worden geconfigureerd op basis van het aantal maximaal en minimaal geconfigureerde vCores. In de regel, als de minimaal geconfigureerde vCores groter zijn dan 0,5 vCores, dan is de minimale rekenfactuur onafhankelijk van het geconfigureerde minimumgeheugen en uitsluitend gebaseerd op het aantal geconfigureerde minimale vCores.
Scenariovoorbeelden
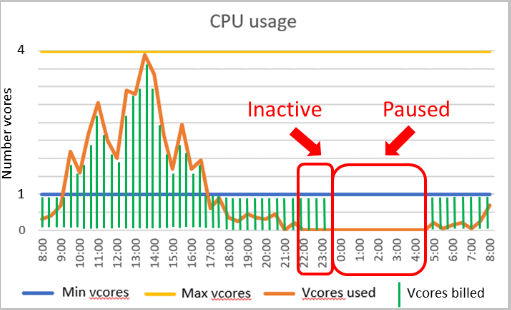
Overweeg een serverloze database in de laag Algemeen gebruik die is geconfigureerd met minimaal 1 vCore en 4 maximale vCores. Deze configuratie komt overeen met ongeveer 3 GB minimumgeheugen en 12 GB maximumgeheugen. Stel dat de vertraging voor automatisch onderbreken is ingesteld op 6 uur en dat de databaseworkload actief is gedurende de eerste 2 uur van een periode van 24 uur en anders inactief is.
In dit geval wordt de database gefactureerd voor rekenkracht en opslag gedurende de eerste 8 uur. Hoewel de database na het tweede uur inactief is, wordt deze nog steeds gefactureerd voor berekening in de volgende 6 uur op basis van de minimale rekenkracht die is ingericht terwijl de database online is. Alleen opslag wordt gefactureerd tijdens de rest van de periode van 24 uur terwijl de database is onderbroken.
Meer precies wordt de rekenfactuur in dit voorbeeld als volgt berekend:
| Tijdsinterval | Aantal gebruikte vCores per seconde | GB gebruikt elke seconde | Gefactureerde berekeningsdimensie | vCore seconden gefactureerd na verloop van tijdsinterval |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | gebruikte vCores | 4 vCores * 3.600 seconden = 14.400 vCore seconden |
| 1:00-2:00 | 1 | 12 | Gebruikte geheugen | 12 GB * 1/3 * 3.600 seconden = 14.400 vCore seconden |
| 2:00-8:00 | 0 | 0 | Minimaal geheugen voorzien | 3 GB * 1/3 * 21.600 seconden = 21.600 vCore seconden |
| 8:00-24:00 | 0 | 0 | Er wordt geen rekenkracht in rekening gebracht terwijl deze is gepauzeerd | 0 vCore seconden |
| Totale vCore-seconden in rekening gebracht over een periode van 24 uur | 50.400 vCore seconden |
Stel dat de prijs van de rekeneenheid $ 0,000145/vCore/seconde is. De berekening die voor deze periode van 24 uur wordt gefactureerd, is het product van de prijs van de rekeneenheid en vCore-seconden die worden gefactureerd: $0,000145/vCore/seconde * 50.400 vCore-seconden ~ $7,31.
Azure Hybrid Benefit en reserveringen
Kortingen voor Azure Hybrid Benefit (AHB) en Azure-reserveringen zijn niet van toepassing op de serverloze rekenlaag.
Beschikbare regio's
Zie Serverloze beschikbaarheid per regio voor Azure SQL Databasevoor regionale beschikbaarheid.
Verwante inhoud
- Zie quickstart: Een individuele database maken - Azure SQL Databaseom aan de slag te gaan.
- Zie voor serverloze servicelaagkeuzes General Purpose en Hyperscale.