Beschikbaarheid via redundantie - Azure SQL Database
van toepassing op:![]() Azure SQL Database
Azure SQL Database![]() SQL-database in Fabric
SQL-database in Fabric
In dit artikel wordt de architectuur van Azure SQL Database en SQL Database in Fabric beschreven die beschikbaarheid bereikt via lokale redundantie en hoge beschikbaarheid via zoneredundantie.
Overzicht
Azure SQL Database en SQL Database in Fabric worden beide uitgevoerd op de nieuwste stabiele versie van de SQL Server Database Engine op het Windows-besturingssysteem met alle toepasselijke patches. SQL Database verwerkt automatisch kritieke onderhoudstaken, zoals patching, back-ups, Windows- en SQL-engine-upgrades en niet-geplande gebeurtenissen, zoals onderliggende hardware, software of netwerkfouten. Wanneer een database of elastische pool in SQL Database is gepatcht of een failover-overschakeling uitvoert, is de downtime niet van invloed als u logica voor opnieuw proberen in uw app. SQL Database kan snel worden hersteld, zelfs in de meest kritieke omstandigheden, zodat uw gegevens altijd beschikbaar zijn. De meeste gebruikers merken niet dat upgrades continu worden uitgevoerd.
Azure SQL Database bereikt standaard beschikbaarheid via lokale redundantie, waardoor uw database beschikbaar is tijdens:
- Door de klant geïnitieerde beheerbewerkingen die resulteren in een korte downtime
- Serviceonderhoudsbewerkingen
- Problemen met:
- rack waarin de machines die uw service aandrijven draaien
- fysieke machine die als host fungeert voor de SQL-database-engine
- Andere problemen met de SQL-database-engine
- Andere potentiële niet-geplande lokale storingen
De standaardbeschikbaarheidsoplossing is ontworpen om ervoor te zorgen dat vastgelegde gegevens nooit verloren gaan vanwege fouten, dat onderhoudsbewerkingen geen invloed hebben op uw workload en dat de database geen single point of failure is in uw softwarearchitectuur.
Als u echter de impact op uw gegevens wilt minimaliseren in het geval van een storing in een hele zone, kunt u hoge beschikbaarheid bereiken door zoneredundantie in te schakelen. Zonder zoneredundantie worden failovers lokaal uitgevoerd binnen hetzelfde datacenter, waardoor uw database mogelijk niet beschikbaar is totdat de storing is opgelost. De enige manier om te herstellen is via een oplossing voor herstel na noodgevallen, zoals geo-failover via actieve geo-replicatie, failovergroepenof een geo-herstel van een geografisch redundante back-up. Raadpleeg het overzicht van bedrijfscontinuïteitvoor meer informatie.
Er zijn drie architectuurmodellen voor beschikbaarheid:
- Remote Storage-model dat is gebaseerd op een scheiding van rekenkracht en opslag. Het is afhankelijk van de beschikbaarheid en betrouwbaarheid van de externe opslaglaag. Deze architectuur is gericht op budgetgerichte zakelijke toepassingen die prestatievermindering kunnen verdragen tijdens onderhoudsactiviteiten.
- lokaal opslagmodel dat is gebaseerd op een cluster van database-engineprocessen. Het is afhankelijk van het feit dat er altijd een quorum is van beschikbare database-engineknooppunten. Deze architectuur is gericht op bedrijfskritieke toepassingen met hoge I/O-prestaties, hoge transactiesnelheid en garandeert minimale prestatie-impact op uw workload tijdens onderhoudsactiviteiten.
- Hyperscale-model dat gebruikmaakt van een gedistribueerd systeem met maximaal beschikbare onderdelen, zoals rekenknooppunten, paginaservers, logboekservice en permanente opslag. Elk onderdeel dat een Hyperscale-database ondersteunt, biedt een eigen redundantie en tolerantie voor fouten. Rekenknooppunten, paginaservers en logboekservice worden uitgevoerd in Azure Service Fabric, waarmee de status van elk onderdeel wordt beheerd en waar nodig failovers worden uitgevoerd naar beschikbare gezonde knooppunten. Permanente opslag maakt gebruik van Azure Storage met de systeemeigen mogelijkheden voor hoge beschikbaarheid en redundantie. Zie Hyperscale-architectuurvoor meer informatie.
Binnen elk van de drie beschikbaarheidsmodellen ondersteunt SQL Database lokale redundantie en zonegebonden redundantieopties. Lokale redundantie biedt tolerantie binnen een datacenter, terwijl zonegebonden redundantie de tolerantie verder verbetert door te beschermen tegen storingen in een beschikbaarheidszone binnen een regio.
In de volgende tabel ziet u de beschikbaarheidsopties op basis van servicelagen:
| Serviceniveau | Model voor hoge beschikbaarheid | lokaal redundante beschikbaarheid | Zone-redundante beschikbaarheid |
|---|---|---|---|
| Algemeen gebruik (vCore) | Externe opslag | Ja | Ja |
| Bedrijfskritiek (vCore) | Lokale opslag | Ja | Ja |
| Hyperscale (vCore) | Hyperscale | Ja | Ja |
| Basis (DTU) | Externe opslag | Ja | Nee |
| Standard (DTU) | Externe opslag | Ja | Nee |
| Premie (DTU) | Lokale opslag | Ja | Ja |
Raadpleeg SLA voor Azure SQL Databasevoor meer informatie over specifieke SLA's voor verschillende servicelagen.
Beschikbaarheid via lokale redundantie
Lokaal redundante beschikbaarheid is gebaseerd op het opslaan van uw database naar lokaal redundante opslag (LRS) waarmee uw gegevens drie keer worden gekopieerd binnen één datacenter in de primaire regio en uw gegevens worden beschermd in geval van lokale storingen, zoals een klein netwerk of stroomstoring. LRS is de laagst mogelijke redundantieoptie en biedt de minst duurzaamheid in vergelijking met andere opties. Als een grootschalige ramp, zoals brand of overstroming, zich in een regio voordoet, kunnen alle replica's van een opslagaccount met LRS verloren of onherstelbaar zijn. Als zodanig kunt u uw gegevens verder beveiligen wanneer u de lokaal redundante beschikbaarheidsoptie gebruikt, kunt u overwegen om een tolerantere opslagoptie te gebruiken voor uw databaseback-ups. Dit geldt niet voor Hyperscale-databases, waarbij dezelfde opslag wordt gebruikt voor zowel gegevensbestanden als back-ups.
Lokaal redundante beschikbaarheid is beschikbaar voor alle databases in alle servicelagen en RPO (Recovery Point Objective), wat aangeeft dat de hoeveelheid gegevensverlies nul is.
Servicelagen Basic, Standard en Algemeen gebruik
De Basic- en Standard-servicelagen van het aankoopmodel op basis van DTUen de servicelaag Algemeen gebruik van het aankoopmodel op basis van vCore het externe opslagbeschikbaarheidsmodel gebruiken voor zowel serverloze als ingerichte berekeningen. In de volgende afbeelding ziet u vier verschillende knooppunten met de gescheiden reken- en opslaglagen.
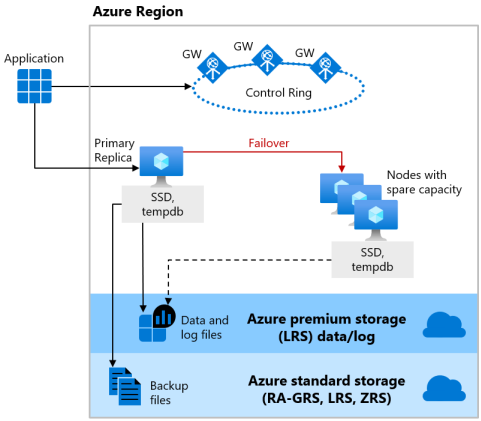
Het beschikbaarheidsmodel voor externe opslag bevat twee lagen:
- Een staatloze rekenlaag die het database-engineproces uitvoert en alleen tijdelijke en in de cache opgeslagen gegevens bevat, zoals de
tempdbenmodeldatabases op de gekoppelde SSD, en plan cache, buffergroep en columnstore-pool in het geheugen. Dit staatloze knooppunt wordt beheerd door Azure Service Fabric waarmee de database-engine wordt geïnitialiseerd, de status van het knooppunt wordt beheerd en indien nodig een failover naar een ander knooppunt wordt uitgevoerd. - Een stateful gegevenslaag met de databasebestanden (
.mdfen.ldf) die zijn opgeslagen in Azure Blob Storage. Azure Blob Storage heeft ingebouwde functies voor gegevensbeschikbaarheid en redundantie. Het garandeert dat elke record in het logboekbestand of de pagina in het gegevensbestand behouden blijft, zelfs als het proces van de database-engine vastloopt.
Wanneer de database-engine of het besturingssysteem wordt bijgewerkt of er een fout wordt gedetecteerd, verplaatst Azure Service Fabric het stateless database-engineproces naar een ander staatloos rekenknooppunt met voldoende vrije capaciteit. Gegevens in Azure Blob Storage worden niet beïnvloed door de verplaatsing en de gegevens/logboekbestanden worden gekoppeld aan het zojuist geïnitialiseerde database-engineproces. Dit proces garandeert hoge beschikbaarheid, maar een zware workload kan tijdens de overgang enige prestatievermindering ervaren omdat het nieuwe database-engineproces begint met koude cache.
Servicelaag Premium en Bedrijfskritiek
De Premium-servicelaag van het aankoopmodel op basis van DTU en de servicelaag Bedrijfskritiek van het aankoopmodel op basis van vCore het lokale opslagbeschikbaarheidsmodel gebruiken, waarmee rekenresources (database-engineproces) en opslag (lokaal gekoppelde SSD) op één knooppunt worden geïntegreerd. Hoge beschikbaarheid wordt bereikt door zowel rekenkracht als opslag te repliceren naar extra knooppunten.
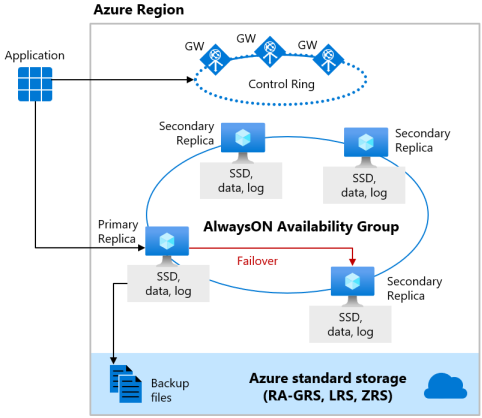
De onderliggende databasebestanden (.mdf/.ldf) worden op de gekoppelde SSD-opslag geplaatst om I/O met een zeer lage latentie voor uw workload te leveren. Hoge beschikbaarheid wordt geïmplementeerd met behulp van een technologie die vergelijkbaar is met SQL Server AlwaysOn-beschikbaarheidsgroepen. Het cluster bevat één primaire replica die toegankelijk is voor lees-/schrijfwerkbelastingen van klanten en maximaal drie secundaire replica's (compute en opslag) die kopieën van gegevens bevatten. De primaire replica pusht voortdurend wijzigingen naar de secundaire replica's op volgorde en zorgt ervoor dat de gegevens op een voldoende aantal secundaire replica's worden bewaard voordat elke transactie wordt doorgevoerd. Dit proces garandeert dat als de primaire replica of een leesbare secundaire replica om welke reden dan ook vastloopt, er altijd een volledig gesynchroniseerde replica is om een failover naar uit te voeren. De failover wordt gestart door Azure Service Fabric. Zodra een secundaire replica de nieuwe primaire replica wordt, wordt er een andere secundaire replica gemaakt om ervoor te zorgen dat het cluster voldoende replica's heeft om quorum te behouden. Zodra een failover is voltooid, worden Azure SQL-verbindingen automatisch omgeleid naar de nieuwe primaire replica of leesbare secundaire replica.
Als extra voordeel biedt het opslagbeschikbaarheidsmodel lokaal de mogelijkheid om Azure SQL-verbindingen voor alleen-lezen om te leiden naar een van de secundaire replica's. Deze functie wordt uitschalenlezen genoemd. Het biedt 100% extra rekencapaciteit zonder extra kosten voor off-load alleen-lezen bewerkingen, zoals analytische workloads, van de primaire replica.
Hyperscale-serviceniveau
De architectuur van de Hyperscale-servicelaag wordt beschreven in architectuur voor gedistribueerde functies.

Het beschikbaarheidsmodel in Hyperscale bevat vier lagen:
- Een staatloze rekenlaag die de database-engine uitvoert en alleen vluchtige en in de cache opgeslagen gegevens bevat, zoals niet-overlappende RBPEX-cache,
tempdbenmodeldatabases, enzovoort op de gekoppelde SSD en plancache, bufferpool en columnstorepool in het geheugen. Deze staatloze laag bevat de primaire rekenreplica en eventueel een aantal secundaire rekenreplica's die als failoverdoelen kunnen fungeren. - Een staatloze opslaglaag gevormd door paginaservers. Deze laag is de gedistribueerde opslagengine voor de database-engineprocessen die worden uitgevoerd op de rekenreplica's. Elke paginaserver bevat alleen tijdelijke en in de cache opgeslagen gegevens, zoals het dekken van de RBPEX-cache op de gekoppelde SSD en gegevenspagina's die in het geheugen zijn opgeslagen. Elke paginaserver heeft een gekoppelde paginaserver in een actief-actief-configuratie om taakverdeling, redundantie en hoge beschikbaarheid te bieden.
- Een stateful opslaglaag voor transactielogboeken die wordt gevormd door het rekenknooppunt waarop het logserviceproces, de landingszone van het transactielogboek en de langetermijnopslag van het transactielogboek worden uitgevoerd. Landingszone en langetermijnopslag maken gebruik van Azure Storage, dat beschikbaarheid en redundantie biedt voor transactielogboeken, waardoor de duurzaamheid van gegevens voor vastgelegde transacties wordt gegarandeerd.
- Een stateful gegevensopslaglaag met de databasebestanden (.mdf/.ndf) die zijn opgeslagen in Azure Storage en worden bijgewerkt door paginaservers. Deze laag maakt gebruik van beschikbaarheid van gegevens en redundantie functies van Azure Storage. Het garandeert dat elke pagina in een gegevensbestand behouden blijft, zelfs als processen in andere lagen van de Hyperscale-architectuur vastlopen of als rekenknooppunten mislukken.
Rekenknooppunten in alle Hyperscale-lagen worden uitgevoerd in Azure Service Fabric, waarmee de status van elk knooppunt wordt beheerd en waar nodig failovers worden uitgevoerd naar beschikbare gezonde knooppunten.
Zie Hoge beschikbaarheid van databases in Hyperscalevoor meer informatie over hoge beschikbaarheid in Hyperscale.
Hoge beschikbaarheid via zoneredundantie
Zone-redundante beschikbaarheid zorgt ervoor dat uw gegevens worden verdeeld over drie Azure-beschikbaarheidszones in de primaire regio. Elke beschikbaarheidszone is een afzonderlijke fysieke locatie met onafhankelijke voeding, koeling en netwerken.
Zone-redundante beschikbaarheid is beschikbaar voor databases in de servicelagen Bedrijfskritiek, Algemeen gebruik en Hyperscale van het aankoopmodel op basis van vCore, en alleen de Premium-servicelaag van het aankoopmodel op basis van DTU: de servicelagen Basic en Standard bieden geen ondersteuning voor zoneredundantie.
Hoewel elke servicelaag zoneredundantie anders implementeert, zorgen alle implementaties voor een RPO (Recovery Point Objective) met geen verlies van vastgelegde gegevens bij failover.
Algemeen gebruik servicelaag
Zone-redundante configuratie voor de servicelaag Algemeen gebruik wordt aangeboden voor zowel serverloze als ingerichte rekenkracht voor databases in het vCore-aankoopmodel. Deze configuratie maakt gebruik van Azure-beschikbaarheidszones om databases te repliceren op meerdere fysieke locaties binnen een Azure-regio. Door zoneredundantie te selecteren, kunt u uw nieuwe en bestaande serverloze en ingerichte individuele databases voor algemeen gebruik en elastische pools tolerant maken voor een veel grotere set storingen, inclusief catastrofale datacenterstoringen, zonder wijzigingen in de toepassingslogica.
Zone-redundante configuratie voor de laag Algemeen gebruik heeft twee lagen:
- Een stateful gegevenslaag met de databasebestanden (.mdf/.ldf) die zijn opgeslagen in ZRS(zone-redundante opslag). Met gebruik van ZRS worden de gegevens en logboekbestanden synchroon gekopieerd over drie fysiek geïsoleerde beschikbaarheidszones van Azure.
- Een staatloze rekenlaag die het sqlservr.exe-proces uitvoert en alleen tijdelijke en in de cache opgeslagen gegevens bevat, zoals de
tempdbenmodeldatabases op de gekoppelde SSD, en plan cache, buffergroep en columnstore-pool in het geheugen. Dit staatloze knooppunt wordt beheerd door Azure Service Fabric die sqlservr.exeinitialiseert, de status van het knooppunt beheert en indien nodig een failover naar een ander knooppunt uitvoert. Voor zoneredundante serverloze en ingerichte algemene databases zijn knooppunten met reservecapaciteit direct beschikbaar in andere beschikbaarheidszones voor failover.
De zone-redundante versie van de architectuur voor hoge beschikbaarheid voor de servicelaag Algemeen gebruik wordt geïllustreerd in het volgende diagram:
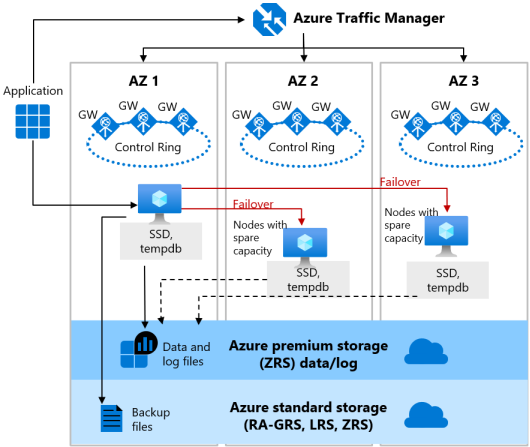
Houd rekening met het volgende bij het configureren van uw algemene databases met zoneredundantie:
- Voor de laag Algemeen gebruik is de zone-redundante configuratie algemeen beschikbaar in de volgende regio's:
- (Afrika) Zuid-Afrika - noord
- (Azië en Stille Oceaan) Australië - oost
- (Azië en Stille Oceaan) Oost-Azië
- (Azië en Stille Oceaan) Japan - oost
- (Azië en Stille Oceaan) Korea - centraal
- (Azië en Stille Oceaan) Zuidoost-Azië
- (Azië en Stille Oceaan) India - centraal
- (Azië en Stille Oceaan) China - noord 3
- (Azië en Stille Oceaan) UAE - noord
- (Europa) Frankrijk - centraal
- (Europa) Duitsland - west-centraal
- (Europa) Italië - noord
- (Europa) Europa - noord
- (Europa) Noorwegen - oost
- (Europa) Polen - centraal
- (Europa) West-Europa
- (Europa) VK Zuid
- (Europa) Zwitserland - noord
- (Europa) Zweden - centraal
- (Midden-Oosten) Israël - centraal
- (Midden-Oosten) Qatar - centraal
- (Noord-Amerika) Canada - centraal
- (Noord-Amerika) VS - centraal
- (Noord-Amerika) Oost-VS
- (Noord-Amerika) Oost VS 2
- (Noord-Amerika) VS - zuid-centraal
- (Noord-Amerika) West US 2
- (Noord-Amerika) West-VS 3
- (Zuid-Amerika) Brazilië - zuid
- Voor zone-redundante beschikbaarheid is het kiezen van een onderhoudsvenster anders dan de standaard momenteel mogelijk in geselecteerde regio's.
- Zone-redundante configuratie is alleen beschikbaar in SQL Database wanneer standaardreekshardware (Gen5) is geselecteerd.
- Zoneredundantie is niet beschikbaar voor Basic- en Standard-servicelagen in het DTU-aankoopmodel.
Premium- en Bedrijfskritieke servicelagen
Wanneer zoneredundantie is ingeschakeld voor de servicelaag Premium of Bedrijfskritiek, worden de replica's in verschillende beschikbaarheidszones in dezelfde regio geplaatst. Om een single point of failure te elimineren, wordt de besturingsring ook gerepliceerd in meerdere zones als drie gateway-ringen (GW). De routering naar een specifieke gatewayring wordt beheerd door Azure Traffic Manager-. Omdat de zone-redundante configuratie in de Premium- of Bedrijfskritieke servicelagen de bestaande replica's gebruikt om in verschillende beschikbaarheidszones te plaatsen, kunt u deze zonder extra kosten inschakelen. Door een zone-redundante configuratie te selecteren, kunt u uw Premium- of Bedrijfskritieke databases en elastische pools tolerant maken voor een veel grotere set fouten, waaronder catastrofale datacenterstoringen, zonder wijzigingen in de toepassingslogica. U kunt ook bestaande Premium- of Bedrijfskritieke databases of elastische pools converteren naar zone-redundante configuratie.
De zone-redundante versie van de architectuur voor hoge beschikbaarheid wordt geïllustreerd door het volgende diagram:
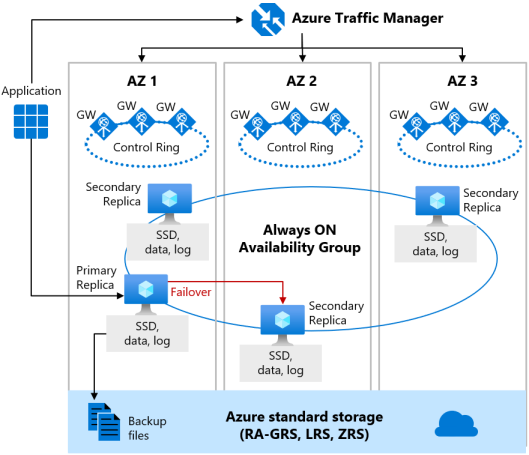
Houd rekening met het volgende bij het configureren van uw Premium- of Bedrijfskritieke databases met zoneredundantie:
- Zie Services-ondersteuning per regiovoor actuele informatie over de regio's die zone-redundante databases ondersteunen.
- Voor zone-redundante beschikbaarheid is het kiezen van een onderhoudsvenster anders dan de standaardinstelling momenteel beschikbaar in geselecteerde regio's.
Hyperscale-servicelaag
Het is mogelijk om zoneredundantie te configureren voor databases in de Hyperscale-servicelaag. Raadpleeg Zone-redundante Hyperscale-database makenvoor meer informatie.
Als u deze configuratie inschakelt, zorgt u voor tolerantie op zoneniveau via replicatie in beschikbaarheidszones voor alle Hyperscale-lagen. Door zoneredundantie te selecteren, kunt u uw Hyperscale-databases tolerant maken voor een veel grotere set fouten, waaronder catastrofale storingen in datacentrums, zonder wijzigingen in de toepassingslogica. Alle Azure-regio's met beschikbaarheidszones bieden ondersteuning voor zone-redundante Hyperscale-databases. Ondersteuning voor zoneredundantie voor Hyperscale PRMS- en MOPRMS-hardware is beschikbaar in regio's die hier worden vermeld .
Zone-redundante beschikbaarheid wordt ondersteund in zowel zelfstandige Hyperscale-databases als elastische Hyperscale-pools. Voor meer informatie, zie Hyperscale elastische pools.
In het volgende diagram ziet u de onderliggende architectuur voor zoneredundante Hyperscale-databases:

Houd rekening met de volgende beperkingen:
Zone-redundante configuratie kan alleen worden opgegeven tijdens het maken van de database. Deze instelling kan niet worden gewijzigd zodra de resource is ingericht. Gebruik databasekopie, herstel naar een bepaald tijdstipof maak een geo-replica om de zone-redundante configuratie voor een bestaande Hyperscale-database bij te werken. Wanneer u een van deze updateopties gebruikt, zal de kopieerbewerking een gegevensgroottetransactie zijn als de doeldatabase zich in een andere regio bevindt dan de bron. Dit geldt ook als de redundantie van de back-upopslag van het doel verschilt van die van de brondatabase.
Voor zone-redundante beschikbaarheid is het op dit moment mogelijk om een onderhoudsvenster anders dan de standaard te kiezen in geselecteerde regio's.
Er is momenteel geen optie om zoneredundantie op te geven bij het migreren van een database naar Hyperscale met behulp van Azure Portal. Zoneredundantie kan echter worden opgegeven met behulp van Azure PowerShell, Azure CLI of de REST API bij het migreren van een bestaande database van een andere Azure SQL Database-servicelaag naar Hyperscale. Hier volgt een voorbeeld met Azure CLI:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Ten minste 1 compute-replica met hoge beschikbaarheid en het gebruik van zone-redundante of geografisch zone-redundante back-upopslag is vereist om de zone-redundante configuratie voor Hyperscale in te schakelen.
Redundante beschikbaarheid van databasezone
In Azure SQL Database is een -server een logische constructie die fungeert als een centraal beheerpunt voor een verzameling databases. Op serverniveau kunt u aanmeldingen, verificatiemethode, firewallregels, controleregels, beleidsregels voor bedreigingsdetectie en failovergroepen beheren. Gegevens met betrekking tot sommige van deze functies, zoals aanmeldingen en firewallregels, worden opgeslagen in de master-database. Op dezelfde manier worden gegevens voor sommige DMV's, bijvoorbeeld sys.resource_stats, ook opgeslagen in de master-database.
Wanneer een database met een zone-redundante configuratie wordt gemaakt op een logische server, wordt de master database die aan de server is gekoppeld, ook automatisch zone-redundant gemaakt. Dit zorgt ervoor dat in een zonegebonden storing toepassingen die de database gebruiken, niet worden beïnvloed omdat functies die afhankelijk zijn van de master-database, zoals aanmeldingen en firewallregels, nog steeds beschikbaar zijn. Het redundant maken van de master databasezone is een asynchroon proces en duurt enige tijd om in de achtergrond te worden voltooid.
Wanneer geen van de databases op een server zone-redundant is of wanneer u een lege server maakt, wordt de master database die aan de server is gekoppeld, geen zone-redundante.
U kunt Azure PowerShell of de Azure CLI of de REST API- gebruiken om de eigenschap ZoneRedundant voor de master-database te controleren:
Gebruik de volgende voorbeeldopdracht om de waarde van de eigenschap ZoneRedundant voor master database te controleren.
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
Fouttolerantie van toepassing testen
Hoge beschikbaarheid is een fundamenteel onderdeel van het SQL Database-platform dat transparant werkt voor uw databasetoepassing. We erkennen echter dat u mogelijk wilt testen hoe de automatische failoverbewerkingen die zijn gestart tijdens geplande of ongeplande gebeurtenissen van invloed zijn op een toepassing voordat u deze implementeert in productie. U kunt een failover handmatig activeren door een speciale API aan te roepen om een database of een elastische pool opnieuw te starten. In het geval van een zone-redundante serverloze of ingerichte database voor algemeen gebruik of elastische pool, zou de API-aanroep ertoe leiden dat clientverbindingen naar de nieuwe primaire in een beschikbaarheidszone anders worden omgeleid dan de beschikbaarheidszone van de oude primaire. Naast het testen van hoe failover van invloed is op bestaande databasesessies, kunt u ook controleren of de end-to-end-prestaties worden gewijzigd vanwege wijzigingen in de netwerklatentie. Omdat de herstartbewerking intrusief is en een groot aantal ervan het platform kan belasten, wordt er elke 15 minuten slechts één failover-aanroep toegestaan voor elke database of elastische pool.
Raadpleeg de controlelijst voor hoge beschikbaarheid en herstel na noodgevallen van Azure SQL Databasevoor meer informatie over hoge beschikbaarheid en herstel na noodgevallen in Azure SQL Database.
Een failover kan worden gestart met behulp van PowerShell, REST API of Azure CLI:
| Implementatietype | PowerShell | REST API | Azure CLI |
|---|---|---|---|
| Databank | Invoke-AzSqlDatabaseFailover | database failover | az rest kan worden gebruikt om een REST API-aanroep vanuit Azure CLI aan te roepen |
| Elastische capaciteitspool | Invoke-AzSqlElasticPoolFailover | Failover van Elastische Pools | az rest kan worden gebruikt om een REST API-aanroep vanuit Azure CLI aan te roepen |
Belangrijk
De opdracht Failover is niet beschikbaar voor leesbare secundaire replica's van Hyperscale-databases.
Conclusie
Azure SQL Database biedt een ingebouwde oplossing voor hoge beschikbaarheid die diep is geïntegreerd met het Azure-platform. Het is afhankelijk van Service Fabric voor foutdetectie en -herstel, in Azure Blob-opslag voor gegevensbeveiliging en voor beschikbaarheidszones voor hogere fouttolerantie. Daarnaast maakt SQL Database gebruik van de AlwaysOn-beschikbaarheidsgroeptechnologie van SQL Server voor gegevenssynchronisatie en failover. Dankzij de combinatie van deze technologieën kunnen toepassingen de voordelen van een gemengd opslagmodel volledig realiseren en de meest veeleisende SLA's ondersteunen.
Verwante inhoud
Raadpleeg voor meer informatie: