Overzicht van failovergroepen & best practices (Azure SQL Database)
van toepassing op:![]() Azure SQL Database-
Azure SQL Database-
Met de functie failovergroepen kunt u de replicatie en failover van sommige of alle databases op een logische server beheren naar een logische server in een andere regio. Dit artikel bevat een overzicht van de functie failovergroep met aanbevolen procedures en aanbevelingen voor het gebruik ervan met Azure SQL Database.
Raadpleeg Een failovergroep configureren voor Azure SQL Databaseom aan de slag te gaan met de functie.
Notitie
Dit artikel bevat informatie over failovergroepen voor Azure SQL Database. Zie Overzicht van failovergroepen - beste praktijken voor Azure SQL Managed Instance & - Azure SQL Managed Instance.
Bekijk deze video voor meer informatie over herstel na noodgevallen van Azure SQL Database:
Overzicht
Met de functie failovergroepen kunt u de replicatie en failover van databases naar een andere Azure-regio beheren. U kunt alle of een subset van gebruikersdatabases op een logische server kiezen die moet worden gerepliceerd naar een andere logische server. Het is een declaratieve abstractie bovenop de actieve geo-replicatie functie, ontworpen om de implementatie en het beheer van geo-gerepliceerde databases op schaal te vereenvoudigen.
Zie overzicht van bedrijfscontinuïteitvoor geografische failover-RPO en RTO.
Eindpuntdoorverwijzing
Failovergroepen bieden lees-/schrijf- en alleen-lezen-luistereindpunten die onveranderd blijven tijdens geo-failovers. U hoeft de verbindingsreeks voor uw toepassing niet te wijzigen na een geo-failover, omdat verbindingen automatisch worden gerouteerd naar de huidige primaire. Met een geo-failover worden alle secundaire databases in de groep overgeschakeld naar de primaire rol. Nadat geo-failover is voltooid, wordt de DNS-record automatisch bijgewerkt om de eindpunten om te leiden naar de nieuwe regio.
Verplaats alleen-lezen werkbelasting
Als u het verkeer naar uw primaire databases wilt verminderen, kunt u ook de secundaire databases in een failovergroep gebruiken om read-only workloads te offloaden. Gebruik de alleen-lezen-luisteraar om alleen-lezen-verkeer naar een leesbare secundaire database te sturen.
Een toepassing herstellen
Voor een volledige bedrijfscontinuïteit maakt het toevoegen van regionale databaseredundantie slechts deel uit van de oplossing. Als u een toepassing (service) end-to-end herstelt na een onherstelbare fout, moet u alle onderdelen herstellen die de service en afhankelijke services vormen. Voorbeelden van deze onderdelen zijn de clientsoftware (bijvoorbeeld een browser met een aangepast JavaScript), webfront-ends, opslag en DNS. Het is essentieel dat alle onderdelen bestand zijn tegen dezelfde fouten en beschikbaar zijn binnen de beoogde hersteltijd (RTO) van uw toepassing. Daarom moet u alle afhankelijke services identificeren en inzicht hebben in de garanties en mogelijkheden die ze bieden. Vervolgens moet u voldoende stappen ondernemen om ervoor te zorgen dat uw service functioneert tijdens de failover van de services waarvan deze afhankelijk is.
Failoverbeleid
Failovergroepen ondersteunen twee failoverbeleidsregels:
-
door de klant beheerde (aanbevolen) : klanten kunnen een failover van een groep uitvoeren wanneer ze een onverwachte storing merken die van invloed is op een of meer databases in de failovergroep. Wanneer u opdrachtregelprogramma's zoals PowerShell, de Azure CLI of de Rest API gebruikt, is de waarde voor het failoverbeleid voor door de klant beheerde
manual. -
door Microsoft beheerde - In het geval van een wijdverspreide storing die van invloed is op een primaire regio, start Microsoft de failover van alle betrokken failovergroepen waarvan het failoverbeleid zo is geconfigureerd dat ze door Microsoft beheerd worden. Door Microsoft beheerde failover wordt niet geïnitieerd voor afzonderlijke failovergroepen of een subset van failovergroepen in een regio. Wanneer u opdrachtregelprogramma's zoals PowerShell, de Azure CLI of de REST API gebruikt, is de waarde voor het failoverbeleid dat door Microsoft wordt beheerd
automatic.
Elk failoverbeleid heeft een unieke set gebruiksvoorbeelden en bijbehorende verwachtingen voor het failoverbereik en gegevensverlies, zoals in de volgende tabel wordt samengevat:
| Failoverbeleid | Failoverbereik | Gebruiksscenario | Potentieel gegevensverlies |
|---|---|---|---|
| Door de klant beheerd (aanbevolen) |
Failovergroep(en) | Een of meer databases in een failovergroep(en) worden beïnvloed door een storing en worden niet meer beschikbaar. U kunt ervoor kiezen om een failover uit te voeren. | Ja |
| Door Microsoft beheerd | Alle failovergroepen in de regio | Een wijdverspreide storing in een datacenter, beschikbaarheidszone of regio zorgt ervoor dat databases niet beschikbaar zijn en het Microsoft Azure SQL-serviceteam besluit om een geforceerde failover te activeren. Gebruik deze optie alleen als u de verantwoordelijkheid voor herstel na noodgevallen wilt delegeren aan Microsoft en de toepassing tolerant is voor RTO (downtime) van ten minste één uur of meer. |
Ja |
Door de klant beheerd
In zeldzame gevallen is de ingebouwde beschikbaarheid of hoge beschikbaarheid niet voldoende is om een storing te beperken en zijn uw databases in een failovergroep mogelijk niet beschikbaar gedurende een periode die niet acceptabel is voor de SERVICE Level Agreement (SLA) van de toepassingen die de databases gebruiken. Databases kunnen niet beschikbaar zijn vanwege een gelokaliseerd probleem dat van invloed is op slechts een paar databases, of het kan zich op datacenter-, beschikbaarheidszone- of regioniveau bevinden. In elk van deze gevallen kunt u een geforceerde failover initiëren om bedrijfscontinuïteit te herstellen.
Het instellen van een door de klant beheerd failoverbeleid wordt ten zeerste aanbevolen, omdat u zelf bepaalt wanneer u een failover start en bedrijfscontinuïteit herstelt. U kunt een failover initiëren wanneer er een onverwachte storing optreedt die van invloed is op een of meer databases in de failovergroep.
Door Microsoft beheerd
Met een door Microsoft beheerd failoverbeleid wordt de verantwoordelijkheid voor herstel na noodgevallen gedelegeerd aan de Azure SQL-service. Voordat de Azure SQL-service een geforceerde failover kan starten, moet aan de volgende voorwaarden worden voldaan:
- Storing op datacenter-, beschikbaarheidszone- of regioniveau veroorzaakt door een natuurramp, configuratiewijzigingen, softwarefouten of storingen in hardwareonderdelen en veel databases in de regio worden beïnvloed.
- Gratieperiode is verlopen. Omdat het bepalen van de omvang van en het beperken van de storing afhankelijk is van menselijk handelen, kan de gratieperiode niet onder één uur worden ingesteld.
Wanneer aan deze voorwaarden wordt voldaan, initieert de Azure SQL-service geforceerde failovers voor alle failovergroepen in de regio waarvoor het failoverbeleid is ingesteld op Door Microsoft beheerd.
Belangrijk
Gebruik door de klant beheerd failoverbeleid om uw noodherstelplan te testen en te implementeren. Vertrouw niet op door Microsoft beheerde failover, die alleen in extreme omstandigheden door Microsoft kan worden uitgevoerd. Een door Microsoft beheerde failover wordt geïnitieerd voor alle failovergroepen in de regio waarvoor failoverbeleid is ingesteld op Door Microsoft beheerd. Het kan niet worden gestart voor afzonderlijke failovergroepen. Als u de mogelijkheid nodig hebt om selectief een failover van uw failovergroep uit te voeren, gebruikt u het door de klant beheerde failoverbeleid.
Stel het failoverbeleid alleen in op Door Microsoft beheerd wanneer:
- U wilt de verantwoordelijkheid voor herstel na noodgevallen delegeren aan de Azure SQL-service.
- De toepassing is tolerant voor het feit dat uw database ten minste één uur of langer niet beschikbaar is.
- Het is acceptabel om geforceerde failovers enige tijd te activeren nadat de respijtperiode is verlopen, omdat de werkelijke tijd voor de geforceerde failover aanzienlijk kan variëren.
- Het is acceptabel dat alle databases binnen de failovergroep een failover-overschakeling uitvoeren, ongeacht hun zoneredundantieconfiguratie of beschikbaarheidsstatus. Hoewel databases die zijn geconfigureerd voor zoneredundantie bestand zijn tegen zonefouten en mogelijk niet worden beïnvloed door een storing, zullen ze nog steeds een failover uitgevoerd krijgen als ze deel uitmaken van een failovergroep met een failoverbeleid beheerd door Microsoft.
- Het is acceptabel om geforceerde failovers van databases in de failovergroep te hebben zonder rekening te houden met de afhankelijkheid van de toepassing op andere Azure-services of -onderdelen die door de toepassing worden gebruikt, wat kan leiden tot prestatievermindering of niet-beschikbaarheid van de toepassing.
- Het is acceptabel om een onbekende hoeveelheid gegevensverlies te veroorzaken, omdat de exacte tijd van geforceerde failover niet kan worden beheerd en de synchronisatiestatus van de secundaire databases wordt genegeerd.
- Alle primaire en secundaire databases in de failovergroep en geo-replicatierelaties hebben dezelfde servicelaag, rekenlaag (ingericht of serverloos) en dezelfde rekenkracht (DTU's of vCores). Als de serviceniveaudoelstelling (SLO) van alle databases niet overeenkomt, wordt het failoverbeleid uiteindelijk bijgewerkt van Microsoft Managed to Customer Managed by Azure SQL Service.
Wanneer een failover wordt geactiveerd door Microsoft, wordt een vermelding voor de naam van de bewerking Failover Azure SQL-failovergroep toegevoegd aan het Azure Monitor-activiteitenlogboek. De vermelding bevat de naam van de failovergroep onder Resource, en bij toont de gebeurtenis die door is geïnitieerd één afbreekstreepje (-) om aan te geven dat de failover door Microsoft is gestart. Deze informatie vindt u ook op de -activiteitenlogboekpagina van de nieuwe primaire server of het nieuwe exemplaar in de Azure-portal.
Terminologie en mogelijkheden
Failovergroep (FOG)
Een failovergroep is een benoemde groep databases die worden beheerd door één logische server in Azure die een failover als eenheid naar een andere Azure-regio kunnen uitvoeren voor het geval alle of sommige primaire databases niet beschikbaar zijn vanwege een storing in de primaire regio.
Belangrijk
De naam van de failovergroep moet wereldwijd uniek zijn binnen het
.database.windows.netdomein.Servers
Sommige of alle gebruikersdatabases op een logische server kunnen in een failovergroep worden geplaatst. Een server ondersteunt ook meerdere failovergroepen op één server.
primaire
De logische server die als host fungeert voor de primaire databases in de failovergroep.
Secundaire
De logische server die als host fungeert voor de secundaire databases in de failovergroep. De secundaire kan zich niet in dezelfde Azure-regio bevinden als de primaire regio.
failover (geen gegevensverlies)
Failover voert volledige gegevenssynchronisatie uit tussen primaire en secundaire databases voordat de secundaire overschakelt naar de primaire rol. Dit garandeert geen gegevensverlies. Failover is alleen mogelijk als de hoofdserver toegankelijk is. Failover wordt gebruikt in de volgende scenario's:
- Noodhersteloefeningen uitvoeren binnen productie, wanneer gegevensverlies niet acceptabel is
- De workload verplaatsen naar een andere regio
- De workload terugbrengen naar de primaire regio nadat de storing is opgelost (failback)
geforceerde failover (mogelijk gegevensverlies)
Geforceerde failover schakelt onmiddellijk de secundaire rol naar de primaire rol zonder te wachten tot recente wijzigingen van de primaire zijn overgebracht. Deze bewerking kan leiden tot mogelijk gegevensverlies. Geforceerde failover wordt gebruikt als herstelmethode tijdens storingen wanneer de primaire niet toegankelijk is. Wanneer de storing wordt verzacht, wordt de oude primaire verbinding automatisch opnieuw gemaakt en wordt het een nieuwe secundaire. Een failover kan worden uitgevoerd om een failback uit te voeren, waarmee de replica's terugkeren naar hun oorspronkelijke primaire en secundaire rollen.
respijtperiode met gegevensverlies
Omdat gegevens worden gerepliceerd naar de secundaire met behulp van asynchrone replicatie, kan geforceerde failover van groepen met door Microsoft beheerde failoverbeleid leiden tot gegevensverlies. U kunt het failoverbeleid aanpassen aan de tolerantie van uw toepassing voor gegevensverlies. Door
GracePeriodWithDataLossHourste configureren, kunt u bepalen hoe lang de Azure SQL-service wacht voordat een geforceerde failover wordt gestart, wat kan leiden tot gegevensverlies.
Individuele databases toevoegen aan failovergroep
U kunt meerdere individuele databases op dezelfde logische server in dezelfde failovergroep plaatsen. Als u één database toevoegt aan de failovergroep, wordt automatisch een secundaire database gemaakt met dezelfde editie en rekenkracht op de secundaire server die u hebt opgegeven toen de failovergroep werd gemaakt. Als u een database toevoegt die al een secundaire database op de secundaire server heeft, wordt die geo-replicatiekoppeling overgenomen door de groep. Wanneer u een database toevoegt die al een secundaire database bevat op een server die geen deel uitmaakt van de failovergroep, wordt er een nieuwe secundaire database gemaakt op de secundaire server.
Belangrijk
- Zorg ervoor dat de secundaire logische server geen database met dezelfde naam heeft, tenzij het een bestaande secundaire database is.
- Als een database OLTP-objecten in het geheugen bevat, moeten de primaire database en de secundaire geo-replicadatabase overeenkomende servicelagen hebben, omdat OLTP-objecten in het geheugen aanwezig zijn. Een lagere servicelaag in de database met geo-replica's kan leiden tot problemen met onvoldoende geheugen. Als dit gebeurt, kan de geo-replica de database niet herstellen, waardoor de secundaire database niet beschikbaar is, samen met OLTP-objecten in het geheugen op de geo-secundaire database. Dit kan op zijn beurt ertoe leiden dat failovers ook niet succesvol zijn. Om dit te voorkomen, moet u ervoor zorgen dat de servicelaag van de geo-secundaire database overeenkomt met die van de primaire database. Upgrades van de servicelaag kunnen omvangrijke gegevensbewerkingen zijn en het kan even duren voordat ze zijn voltooid.
Databases toevoegen aan een elastische pool voor failovergroep
U kunt alle of meerdere databases in een elastische pool in dezelfde failovergroep plaatsen. Als de primaire database zich in een elastische pool bevindt, wordt de secundaire automatisch gemaakt in de elastische pool met dezelfde naam (secundaire pool). U moet ervoor zorgen dat de secundaire server een elastische pool bevat met dezelfde exacte naam en voldoende vrije capaciteit om de secundaire databases te hosten die door de failovergroep worden gemaakt. Als u een database toevoegt in de pool die al een secundaire database in de secundaire pool heeft, wordt die geo-replicatiekoppeling overgenomen door de groep. Wanneer u een database toevoegt die al een secundaire database bevat op een server die geen deel uitmaakt van de failovergroep, wordt er een nieuwe secundaire database gemaakt in de secundaire pool.
lees-/schrijflistener voor failovergroepen
Een DNS CNAME-record die verwijst naar de huidige primaire record. Deze wordt automatisch aangemaakt wanneer de failovergroep wordt gemaakt en stelt de lees- en schrijfworkload in staat om transparant opnieuw verbinding te maken met de primaire server wanneer de primaire server verandert na een failover. Wanneer de failovergroep op een server wordt gemaakt, wordt de DNS CNAME-record voor de listener-URL gevormd als
<fog-name>.database.windows.net. Na een failover wordt de DNS-record automatisch bijgewerkt om de listener om te leiden naar de nieuwe primaire.alleen-lezen listener voor failovergroepen
Een DNS CNAME-record die verwijst naar de huidige secundaire record. Deze wordt automatisch gemaakt wanneer de failovergroep wordt aangemaakt en stelt de alleen-lezen SQL-workload in staat om transparant verbinding te maken met de secundaire server wanneer deze na een failover verandert. Wanneer de failovergroep op een server wordt gemaakt, wordt de DNS CNAME-record voor de listener-URL gevormd als
<fog-name>.secondary.database.windows.net. De failover van de read-only listener is standaard uitgeschakeld omdat dit ervoor zorgt dat de prestaties van de primaire niet worden beïnvloed wanneer de secundaire offline is. Dit betekent echter ook dat de alleen-lezensessies pas verbinding kunnen maken als de secundaire sessie is hersteld. Als u geen downtime voor de alleen-lezensessies kunt tolereren en de primaire kunt gebruiken voor zowel alleen-lezen- als lezen-schrijfverkeer ten koste van de mogelijke prestatievermindering van de primaire, kunt u failover inschakelen voor de alleen-lezenlistener door de eigenschapAllowReadOnlyFailoverToPrimaryte configureren. In dat geval wordt het alleen-lezen-verkeer automatisch omgeleid naar de primaire server als de secundaire server niet beschikbaar is.Notitie
De eigenschap
AllowReadOnlyFailoverToPrimaryheeft alleen effect als het door Microsoft beheerde failoverbeleid is ingeschakeld en er een geforceerde failover is geactiveerd. Als de eigenschap in dat geval is ingesteld op True, zal de nieuwe primaire server zowel lees- en schrijfsessies als alleen-leessessies verwerken.meerdere failovergroepen
U kunt meerdere failovergroepen configureren voor hetzelfde paar servers om het bereik van geo-failovers te beheren. Elke groep voert onafhankelijk een failover uit. Als uw tenant-per-databasetoepassing wordt geïmplementeerd in meerdere regio's en elastische pools gebruikt, kunt u deze mogelijkheid gebruiken om primaire en secundaire databases in elke pool te combineren. Op deze manier kunt u mogelijk de gevolgen van een storing beperken tot slechts enkele tenantdatabases.
Architectuur van failovergroep
Een failovergroep in Azure SQL Database kan een of meer databases bevatten, die doorgaans door dezelfde toepassing worden gebruikt. Een failovergroep moet worden geconfigureerd op de primaire server, die deze verbindt met de secundaire server in een andere Azure-regio. De failovergroep kan alle of sommige databases op de primaire server bevatten. In het volgende diagram ziet u een typische configuratie van een geografisch redundante cloudtoepassing met behulp van meerdere databases in een failovergroep:
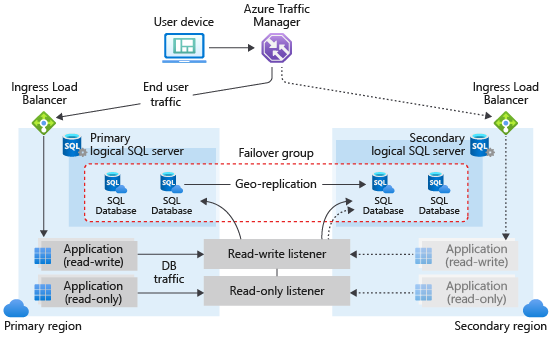
Wanneer u een service ontwerpt met bedrijfscontinuïteit, volgt u de algemene richtlijnen en aanbevolen procedures die in dit artikel worden beschreven. Wanneer u een failovergroep configureert, moet u ervoor zorgen dat verificatie en netwerktoegang op de secundaire groep correct functioneren na geo-failover, wanneer de geo-secundaire de nieuwe primaire wordt. Zie Azure SQL Database-beveiliging configureren en beheren voor geo-herstel of failover-voor meer informatie. Zie Wereldwijd beschikbare services ontwerpen met behulp van Azure SQL Database en geo-herstel voor Azure SQL Databasevoor meer informatie.
Gekoppelde regio's gebruiken
Wanneer u uw failovergroep tussen de primaire en secundaire server maakt, gebruikt u gekoppelde regio's als failovergroepen in gekoppelde regio's betere prestaties hebben in vergelijking met niet-gepaareerde regio's.
Na veilige implementatieprocedures worden in het algemeen gekoppelde regio's in Azure SQL Database niet tegelijkertijd bijgewerkt. Het is echter niet mogelijk om te voorspellen welke regio eerst wordt geüpgraded, dus de volgorde van de implementatie wordt niet gegarandeerd. Soms wordt de primaire server als eerste geüpdatet en soms als tweede keer.
Als u geo-replicatie of failovergroepen geconfigureerd hebt voor databases die niet overeenkomen met de Azure-regiokoppeling, moet u verschillende tijdstippen voor onderhoudsvensters gebruiken voor uw primaire en secundaire databases. U kunt bijvoorbeeld een onderhoudsvenster voor weekdagen selecteren voor uw secundaire database en een onderhoudsvenster voor het weekend voor uw primaire database.
Eerste zaaiing
Wanneer u databases of elastische pools toevoegt aan een failovergroep, is er een eerste seedingfase voordat de gegevensreplicatie wordt gestart. De eerste seedingfase is de langste en duurste bewerking. Zodra de eerste seeding is voltooid, worden gegevens gesynchroniseerd en worden alleen volgende gegevenswijzigingen gerepliceerd. De tijd die nodig is om de eerste seeding te voltooien, is afhankelijk van de grootte van uw gegevens, het aantal gerepliceerde databases, de belasting van de primaire databases en de snelheid van de netwerkkoppeling tussen de primaire en secundaire database. In normale omstandigheden is de mogelijke seedingsnelheid maximaal 500 GB per uur voor SQL Database. Seeding wordt parallel uitgevoerd voor alle databases.
Aantal databases in failovergroep
Het aantal databases binnen een failovergroep heeft rechtstreeks invloed op de duur van zowel failover- als geforceerde failoverbewerkingen.
- Tijdens een failover (ook wel geplande failover genoemd) zorgen we ervoor dat alle primaire databases volledig worden gesynchroniseerd met hun secundaire database en de status Gereed hebben. Om te voorkomen dat het besturingsvlak wordt overweldigd, worden databases in batches voorbereid. Daarom wordt het ten zeerste aanbevolen om het aantal databases in een failovergroep te beperken.
- In het geval van een geforceerde failover wordt de voorbereidingsfase versneld omdat gegevenssynchronisatie niet wordt gestart. Om sneller en voorspelbare failoverduur te bereiken, kan het handig zijn om het aantal databases in de failovergroep tot een kleiner aantal te houden.
Meerdere failovergroepen gebruiken om een failover uit te voeren voor meerdere databases
Een of veel failovergroepen kunnen worden gemaakt tussen twee servers in verschillende regio's (primaire en secundaire servers). Elke groep kan een of meer databases bevatten die als een eenheid worden hersteld voor het geval alle of sommige primaire databases niet meer beschikbaar zijn vanwege een storing in de primaire regio. Als u een failovergroep maakt, worden geo-secundaire databases gemaakt met dezelfde servicedoelstelling als de primaire database. Als u een bestaande geo-replicatierelatie toevoegt aan een failovergroep, moet u ervoor zorgen dat de geo-secundaire is geconfigureerd met dezelfde servicelaag en rekenkracht als de primaire.
De listener voor lezen/schrijven gebruiken (primair)
Gebruik voor lees-schrijfworkloads <fog-name>.database.windows.net als de servernaam in de verbindingsreeks. Verbindingen worden automatisch omgeleid naar de primaire server. Deze naam wordt niet gewijzigd na een failover. Houd er rekening mee dat de failover betrekking heeft op het bijwerken van de DNS-record, zodat de clientverbindingen pas worden omgeleid naar de nieuwe primaire nadat de DNS-cache van de client is vernieuwd. De TTL (time to live) van de DNS-records voor de primaire en secundaire listener is 30 seconden.
Gebruik de alleen-lezenmodusluisteraar (secundair)
Als u logisch geïsoleerde alleen-lezenworkloads hebt die tolerant zijn voor gegevenslatentie, kunt u deze uitvoeren op de geo-secundaire. Gebruik voor alleen-lezensessies <fog-name>.secondary.database.windows.net als de servernaam in de verbindingsreeks. Verbindingen worden automatisch omgeleid naar de geo-secundaire. Het wordt ook aanbevolen dat u de leesintentie in de verbindingsreeks aangeeft met behulp van ApplicationIntent=ReadOnly.
In de servicelagen Premium, Bedrijfskritiek en Hyperscale ondersteunt SQL Database het gebruik van alleen-lezen replica's om alleen-lezen query-werkbelastingen te verlichten met behulp van de parameter ApplicationIntent=ReadOnly in de connectiestring. Wanneer u een geo-secundaire locatie hebt geconfigureerd, kunt u deze mogelijkheid gebruiken om verbinding te maken met een alleen-lezen replica op de primaire locatie of op de geo-secundaire locatie:
Als u verbinding wilt maken met een alleen-lezen replica op de secundaire locatie, gebruikt u dan ApplicationIntent=ReadOnly en <fog-name>.secondary.database.windows.net.
Mogelijke prestatievermindering na failover
Een typische Azure-toepassing maakt gebruik van meerdere Azure-services en bestaat uit meerdere onderdelen. Failover van een groep wordt alleen geactiveerd op basis van de status van Azure SQL Database. Andere Azure-services in de primaire regio worden mogelijk niet beïnvloed door de storing en de bijbehorende onderdelen zijn mogelijk nog steeds beschikbaar in die regio. Zodra de primaire databases overschakelen naar de secundaire regio (DR), kan de latentie tussen afhankelijke onderdelen toenemen. Zorg ervoor dat alle onderdelen van de applicatie redundant zijn in de DR-regio om te voorkomen dat hogere latentie de prestaties van de applicatie beïnvloedt. Volg deze richtlijnen voor netwerkbeveiligingen plan de geo-failover van relevante applicatiecomponenten samen met de database.
Potentieel gegevensverlies na geforceerde failover
Als er een storing optreedt in de primaire regio, zijn recente transacties mogelijk niet gerepliceerd naar de geo-secundaire regio en kunnen er gegevensverlies optreden als er een geforceerde failover wordt uitgevoerd.
Belangrijk
Elastische pools met 800 of minder DTU's of 8 of minder vCores en meer dan 250 databases kunnen problemen ondervinden, waaronder langere geplande geo-failovers en verminderde prestaties. Deze problemen treden vaker op bij schrijfintensieve workloads wanneer geo-replica's ver van elkaar verwijderd zijn door de locatie, of wanneer meerdere secundaire geo-replica's per database worden gebruikt. Een symptoom van deze problemen is een toename van de vertraging van geo-replicatie in de loop van de tijd, wat mogelijk leidt tot een uitgebreider gegevensverlies in een storing. Deze vertraging kan worden bewaakt met behulp van sys.dm_geo_replication_link_status. Als deze problemen optreden, omvat risicobeperking het omhoog schalen van de pool om meer DTU's of vCores te hebben, of het aantal geo-gerepliceerde databases in de pool te verminderen.
terugval
Wanneer failovergroepen zijn geconfigureerd met een door Microsoft beheerd failoverbeleid, wordt geforceerde failover naar de geo-secundaire server gestart tijdens een noodscenario volgens de gedefinieerde respijtperiode. Failback naar de oude primaire server moet handmatig worden gestart.
Machtigingen en beperkingen
Raadpleeg de handleiding failovergroep configureren voor een lijst met machtigingen en beperkingen.
Failovergroepen programmatisch beheren
Failovergroepen kunnen ook programmatisch worden beheerd met behulp van Azure PowerShell, Azure CLI en REST API. Raadpleeg Een failovergroep configureren voor Azure SQL Databasevoor meer informatie.
Hoge beschikbaarheid inschakelen (zoneredundantie)
Beschikbaarheid via redundantie verbetert de tolerantie verder door te beschermen tegen storingen in een beschikbaarheidszone binnen een regio.
Wanneer u een failovergroep maakt die een of meer databases bevat, is er geen optie om hoge beschikbaarheid in te schakelen voor de secundaire databases, ongeacht de instellingen voor hoge beschikbaarheid van de primaire databases.
Zoneredundantie met niet-Hyperscale-databases
Secundaire databases die zijn gemaakt via de failovergroep hebben standaard geen hoge beschikbaarheid ingeschakeld. Nadat de failovergroep is gemaakt, schakelt u hoge beschikbaarheid in voor de databases in de groep. Dit gedrag is ook van toepassing als u eerst Actieve Geo-Replication maakt en vervolgens de databases optioneel toevoegt aan een failovergroep.
Zoneredundantie met Hyperscale
Secundaire databases die zijn gemaakt via de failovergroep nemen de instellingen voor hoge beschikbaarheid van hun respectieve primaire databases over. Als de primaire database daarom hoge beschikbaarheid heeft ingeschakeld, wordt deze ook ingeschakeld voor de secundaire database. Als de primaire database daarentegen geen hoge beschikbaarheid heeft ingeschakeld, heeft de secundaire database deze ook niet ingeschakeld.
Regionale ondersteuning voor beschikbaarheidszones
In een scenario waarin hoge beschikbaarheid is ingeschakeld voor de primaire database en de secundaire database die wordt toegevoegd zich in een regio bevindt die nog geen beschikbaarheidszones ondersteunt, mislukt de werkstroom met een foutbericht met code 45122: 'De bewerking Failovergroep maken of bijwerken is voltooid; Sommige databases kunnen echter niet worden toegevoegd aan of verwijderd uit de failovergroep. Het inrichten van zoneredundante database/pool wordt niet ondersteund voor uw huidige aanvraag. Als u dit probleem wilt omzeilen, gebruikt u actieve geo-replicatie waar u hoge beschikbaarheid inschakelt of uitschakelt tijdens het maken van de secundaire database. U kunt deze databases desgewenst toevoegen aan een failovergroep.
Verwante inhoud
- Zie voor voorbeeldscripts:
- Zie Overzicht van bedrijfscontinuïteit voor een overzicht van bedrijfscontinuïteit en scenario's
- Zie geautomatiseerde back-ups van Azure SQL Databasevoor meer informatie.
- Zie Een database herstellen vanuit de door de service geïnitieerde back-upsvoor meer informatie over het gebruik van geautomatiseerde back-ups voor herstel.
- Zie SQL Database-beveiliging na noodherstelvoor meer informatie over verificatievereisten voor een nieuwe primaire server en database.