Een Kubernetes-toepassing ontwikkelen voor Azure SQL Database
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
In deze zelfstudie leert u hoe u een moderne toepassing ontwikkelt met behulp van Python, Docker Containers, Kubernetes en Azure SQL Database.
De ontwikkeling van moderne toepassingen heeft verschillende uitdagingen. Als u een 'stack' van front-end selecteert via gegevensopslag en -verwerking van verschillende concurrerende standaarden, door ervoor te zorgen dat de hoogste beveiligings- en prestatiessniveaus worden gegarandeerd, moeten ontwikkelaars ervoor zorgen dat de toepassing wordt geschaald en goed presteert en kan worden ondersteund op meerdere platforms. Voor die laatste vereiste is het bundelen van de toepassing in containertechnologieën zoals Docker en het implementeren van meerdere containers op het Kubernetes-platform nu de rigueur in de ontwikkeling van toepassingen.
In dit voorbeeld verkennen we python, Docker Containers en Kubernetes, die allemaal worden uitgevoerd op het Microsoft Azure-platform. Het gebruik van Kubernetes betekent dat u ook de flexibiliteit hebt om lokale omgevingen of zelfs andere clouds te gebruiken voor een naadloze en consistente implementatie van uw toepassing en dat u implementaties met meerdere clouds voor nog hogere tolerantie mogelijk maakt. We gebruiken ook Microsoft Azure SQL Database voor een op services gebaseerde, schaalbare, zeer flexibele en veilige omgeving voor de gegevensopslag en -verwerking. In veel gevallen maken andere toepassingen vaak gebruik van Microsoft Azure SQL Database en kan deze voorbeeldtoepassing worden gebruikt om die gegevens verder te gebruiken en te verrijken.
Dit voorbeeld is redelijk uitgebreid binnen het bereik, maar maakt gebruik van de eenvoudigste toepassing, database en implementatie om het proces te illustreren. U kunt dit voorbeeld aanpassen om veel robuuster te zijn, zelfs als u de nieuwste technologieën voor de geretourneerde gegevens gebruikt. Het is een handig leerprogramma om een patroon te maken voor andere toepassingen.
Python, Docker Containers, Kubernetes en de AdventureWorksLT-voorbeelddatabase gebruiken in een praktisch voorbeeld
Het bedrijf AdventureWorks (fictief) maakt gebruik van een database waarin gegevens over verkoop en marketing, producten, klanten en productie worden opgeslagen. Het bevat ook weergaven en opgeslagen procedures waarmee informatie over de producten wordt samengevoegd, zoals de productnaam, categorie, prijs en een korte beschrijving.
Het AdventureWorks Development-team wil een proof-of-concept (PoC) maken die gegevens retourneert vanuit een weergave in de AdventureWorksLT database en deze beschikbaar maken als EEN REST API. Met behulp van deze PoC maakt het ontwikkelteam een schaalbare en multicloudklare toepassing voor het verkoopteam. Ze hebben het Microsoft Azure-platform geselecteerd voor alle aspecten van de implementatie. De PoC gebruikt de volgende elementen:
- Een Python-toepassing die gebruikmaakt van het Flask-pakket voor headless webimplementatie.
- Docker Containers voor code- en omgevingsisolatie, opgeslagen in een privéregister, zodat het hele bedrijf de toepassingscontainers in toekomstige projecten opnieuw kan gebruiken, waardoor tijd en geld bespaart.
- Kubernetes voor gemak van implementatie en schaal en om platformvergrendeling te voorkomen.
- Microsoft Azure SQL Database voor selectie van grootte, prestaties, schaal, automatisch beheer en back-up, naast relationele gegevensopslag en -verwerking op het hoogste beveiligingsniveau.
In dit artikel leggen we het proces uit voor het maken van het volledige proof-of-concept-project. De algemene stappen voor het maken van de toepassing zijn:
- Vereisten instellen
- De toepassing maken
- Een Docker-container maken om de toepassing te implementeren en te testen
- Een ACS-register (Azure Container Service) maken en de container laden in het ACS-register
- De AKS-omgeving (Azure Kubernetes Service) maken
- De toepassingscontainer vanuit het ACS-register implementeren in AKS
- De toepassing testen
- Opschonen
Vereisten
In dit artikel zijn er verschillende waarden die u moet vervangen. Zorg ervoor dat u deze waarden consistent vervangt voor elke stap. U kunt een teksteditor openen en deze waarden neerzetten om de juiste waarden in te stellen terwijl u het proof-of-concept-project doorloopt:
ReplaceWith_AzureSubscriptionName: Vervang deze waarde door de naam van het Azure-abonnement dat u hebt.ReplaceWith_PoCResourceGroupName: Vervang deze waarde door de naam van de resourcegroep die u wilt maken.ReplaceWith_AzureSQLDBServerName: Vervang deze waarde door de naam van de logische Azure SQL Database-server die u maakt met behulp van Azure Portal.ReplaceWith_AzureSQLDBSQLServerLoginName: Vervang deze waarde door de waarde van de SQL Server-gebruikersnaam die u in Azure Portal maakt.ReplaceWith_AzureSQLDBSQLServerLoginPassword: Vervang deze waarde door de waarde van het SQL Server-gebruikerswachtwoord dat u in Azure Portal maakt.ReplaceWith_AzureSQLDBDatabaseName: Vervang deze waarde door de naam van de Azure SQL Database die u maakt met behulp van Azure Portal.ReplaceWith_AzureContainerRegistryName: Vervang deze waarde door de naam van het Azure Container Registry dat u wilt maken.ReplaceWith_AzureKubernetesServiceName: Vervang deze waarde door de naam van de Azure Kubernetes Service die u wilt maken.
De ontwikkelaars van AdventureWorks gebruiken een combinatie van Windows-, Linux- en Apple-systemen voor ontwikkeling, dus ze gebruiken Visual Studio Code als hun omgeving en git voor broncodebeheer, die beide platformoverschrijdend worden uitgevoerd.
Voor de PoC vereist het team de volgende vereisten:
Python, pip en pakketten : het ontwikkelteam kiest de programmeertaal Python als standaard voor deze webtoepassing. Momenteel gebruiken ze versie 3.9, maar elke versie die de vereiste PoC-pakketten ondersteunt, is acceptabel.
- U kunt Python-versie 3.9 downloaden van python.org.
Het team gebruikt het
pyodbcpakket voor databasetoegang.- U kunt het pyodbc-pakket installeren met pip-opdrachten.
- Mogelijk hebt u ook de Microsoft ODBC-stuurprogrammasoftware nodig als u deze nog niet hebt geïnstalleerd.
Het team gebruikt het pakket voor het
ConfigParserbeheren en instellen van configuratievariabelen.Het team gebruikt het Flask-pakket voor een webinterface voor de toepassing.
- U kunt de Python-versie van de Flask-bibliotheek installeren.
Vervolgens heeft het team het Azure CLI-hulpprogramma geïnstalleerd, eenvoudig geïdentificeerd met
azsyntaxis. Met dit platformoverschrijdende hulpprogramma kunt u een opdrachtregel- en scriptbenadering voor de PoC uitvoeren, zodat ze de stappen kunnen herhalen wanneer ze wijzigingen en verbeteringen aanbrengen.- U kunt het Azure CLI-hulpprogramma downloaden en installeren.
Als Azure CLI is ingesteld, meldt het team zich aan bij het Azure-abonnement en stelt het de abonnementsnaam in die ze voor de PoC hebben gebruikt. Vervolgens hebben ze ervoor gezorgd dat de Azure SQL Database-server en -database toegankelijk zijn voor het abonnement:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameEen Microsoft Azure-resourcegroep is een logische container die gerelateerde resources voor een Azure-oplossing bevat. Over het algemeen worden resources die dezelfde levenscyclus delen, toegevoegd aan dezelfde resourcegroep, zodat u ze eenvoudig als groep kunt implementeren, bijwerken en verwijderen. De resourcegroep slaat metagegevens over de resources op en u kunt een locatie voor de resourcegroep opgeven.
Resourcegroepen kunnen worden gemaakt en beheerd met behulp van Azure Portal of Azure CLI. Ze kunnen ook worden gebruikt om gerelateerde resources voor een toepassing te groeperen en ze te verdelen in groepen voor productie en niet-productie, of een andere organisatiestructuur die u wilt.

In het volgende codefragment ziet u de
azopdracht die wordt gebruikt om een resourcegroep te maken. In ons voorbeeld gebruiken we de regio Eastusvan Azure.az group create --name ReplaceWith_PoCResourceGroupName --location eastusHet ontwikkelteam maakt een Azure SQL Database waarop de
AdventureWorksLTvoorbeelddatabase is geïnstalleerd, met behulp van een geverifieerde SQL-aanmelding.AdventureWorks is gestandaardiseerd op het Relational Database Management System-platform van Microsoft SQL Server en het ontwikkelingsteam wil een beheerde service voor de database gebruiken in plaats van lokaal te installeren. Met Behulp van Azure SQL Database kan deze beheerde service volledig code-compatibel zijn, ongeacht waar ze de SQL Server-engine uitvoeren: on-premises, in een container, in Linux of Windows, of zelfs in een IoT-omgeving (Internet of Things).
Tijdens het maken hebben ze de Azure-beheerportal gebruikt om de firewall voor de toepassing in te stellen op de lokale ontwikkelcomputer en de standaardinstelling gewijzigd die u hier ziet om alle Azure-services in te schakelen en ook de verbindingsreferenties op te halen.
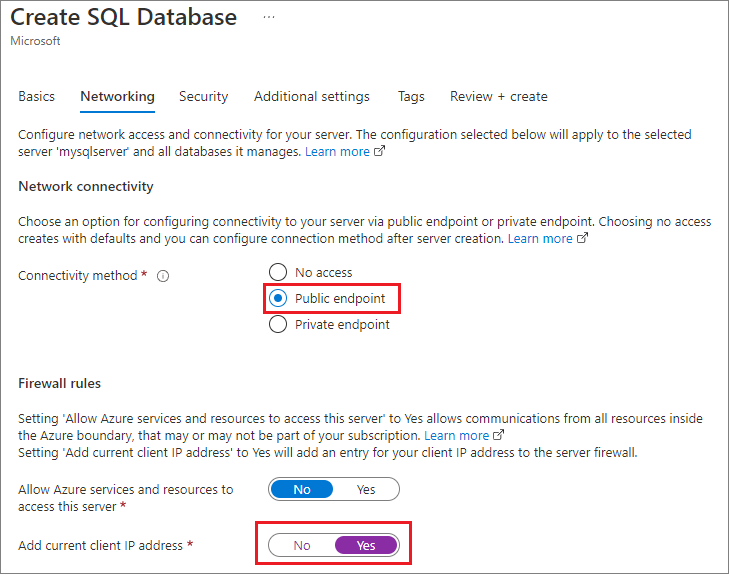
Met deze methode kan de database toegankelijk zijn in een andere regio of zelfs een ander abonnement.
Het team heeft een geverifieerde SQL-aanmelding ingesteld voor testen, maar zal deze beslissing opnieuw bekijken in een beveiligingsbeoordeling.
Het team heeft de voorbeelddatabase
AdventureWorksLTvoor de PoC gebruikt met dezelfde PoC-resourcegroep. Maak u zich geen zorgen, aan het einde van deze zelfstudie gaan we alle resources in deze nieuwe PoC-resourcegroep opschonen.U kunt Azure Portal gebruiken om de Azure SQL Database te implementeren. Wanneer u de Azure SQL Database maakt, selecteert u voorbeeld op het tabblad Aanvullende instellingen voor de optie Bestaande gegevens gebruiken.
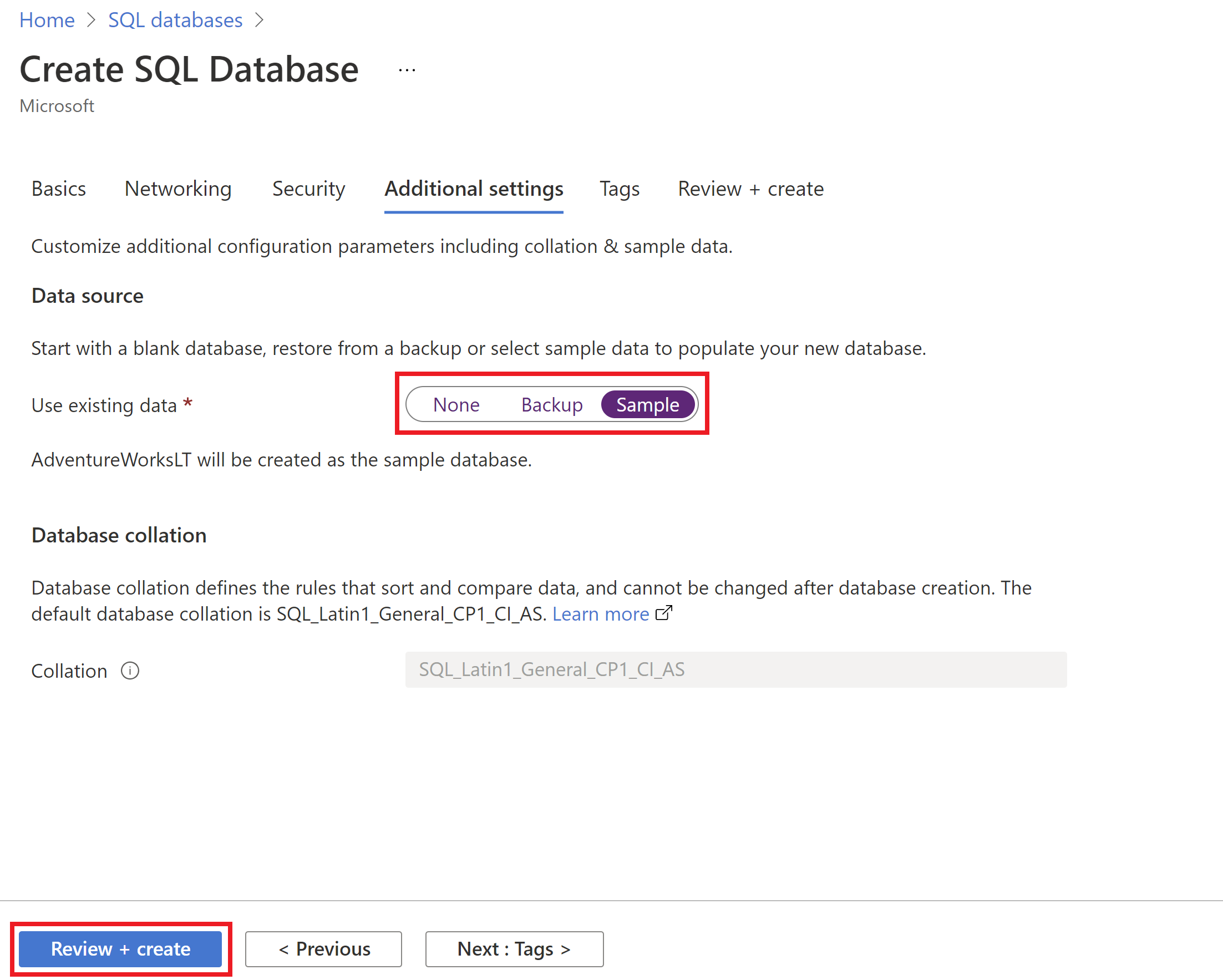
Ten slotte heeft het ontwikkelingsteam op het tabblad Tags van de nieuwe Azure SQL Database tagsmetagegevens verstrekt voor deze Azure-resource, zoals Eigenaar of ServiceClass of WorkloadName.

De toepassing maken
Vervolgens heeft het ontwikkelteam een eenvoudige Python-toepassing gemaakt waarmee een verbinding met Azure SQL Database wordt geopend en een lijst met producten wordt geretourneerd. Deze code wordt vervangen door complexere functies en kan ook meer dan één toepassing bevatten die is geïmplementeerd in de Kubernetes Pods in productie voor een robuuste, manifestgestuurde benadering van toepassingsoplossingen.
Het team heeft een eenvoudig tekstbestand gemaakt
.envdat variabelen bevat voor de serververbindingen en andere informatie. Met behulp van depython-dotenvbibliotheek kunnen ze de variabelen vervolgens scheiden van de Python-code. Dit is een algemene benadering voor het bewaren van geheimen en andere informatie uit de code zelf.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameLet op
Voor duidelijkheid en eenvoud gebruikt deze toepassing een configuratiebestand dat uit Python wordt gelezen. Omdat de code wordt geïmplementeerd met de container, kan de verbindingsgegevens mogelijk worden afgeleid van de inhoud. Houd zorgvuldig rekening met de verschillende methoden voor het werken met beveiliging, verbindingen en geheimen en bepaal het beste niveau en mechanisme dat u voor onze toepassing moet gebruiken. Kies altijd het hoogste beveiligingsniveau en zelfs meerdere niveaus om ervoor te zorgen dat uw toepassing veilig is. U hebt meerdere opties voor het werken met geheime informatie, zoals verbindingsreeks s en dergelijke, en in de volgende lijst ziet u een aantal van deze opties.
Zie Azure SQL Database-beveiliging voor meer informatie.
- Een andere methode voor het werken met geheimen in Python is het gebruik van de python-secrets-bibliotheek.
- Controleer de beveiliging en geheimen van Docker.
- Kubernetes-geheimen controleren.
- U kunt ook meer informatie vinden over Microsoft Entra-verificatie (voorheen Azure Active Directory).
Het team schreef vervolgens de PoC-toepassing en noemde het
app.py.Met het volgende script worden deze stappen uitgevoerd:
- Stel de bibliotheken in voor de configuratie en basiswebinterfaces.
- Laad de variabelen uit het
.envbestand. - Maak de Flask-RESTful-toepassing.
- Ga naar azure SQL Database-verbindingsgegevens met behulp van de
config.inibestandswaarden. - Maak verbinding met Azure SQL Database met behulp van de
config.inibestandswaarden. - Verbinding maken met behulp van het
pyodbcpakket naar Azure SQL Database. - Maak de SQL-query die moet worden uitgevoerd op de database.
- Maak de klasse die wordt gebruikt om de gegevens van de API te retourneren.
- Stel het API-eindpunt in op de
Productsklasse. - Start ten slotte de app op de standaard Flask-poort 5000.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)Ze hebben gecontroleerd of deze toepassing lokaal wordt uitgevoerd en een pagina retourneert naar
http://localhost:5000/products.
Belangrijk
Gebruik bij het bouwen van productietoepassingen niet het beheerdersaccount om toegang te krijgen tot de database. Lees meer over het instellen van een account voor uw toepassing voor meer informatie. De code in dit artikel is vereenvoudigd, zodat u snel aan de slag kunt met toepassingen met behulp van Python en Kubernetes in Azure.
U kunt realistischer een ingesloten databasegebruiker gebruiken met alleen-lezenmachtigingen, of een aanmeldings- of ingesloten databasegebruiker die is verbonden met een door de gebruiker toegewezen beheerde identiteit met alleen-lezenmachtigingen.
Raadpleeg een volledig voorbeeld over het maken van API met Python en Azure SQL Database voor meer informatie.

De toepassing implementeren in een Docker-container
Een container is een gereserveerde, beveiligde ruimte in een computersysteem dat isolatie en inkapseling biedt. Als u een container wilt maken, gebruikt u een manifestbestand. Dit is gewoon een tekstbestand met een beschrijving van de binaire bestanden en code die u wilt bevatten. Met behulp van een Container Runtime (zoals Docker) kunt u vervolgens een binaire installatiekopieën maken met alle bestanden die u wilt uitvoeren en ernaar verwijzen. Van daaruit kunt u de binaire installatiekopieën uitvoeren en dat wordt een container genoemd, waarnaar u kunt verwijzen alsof het een volledig computersysteem is. Het is een kleinere, eenvoudigere manier om uw toepassingsruntimes en -omgeving te abstraheren dan het gebruik van een volledige virtuele machine. Zie Containers en Docker voor meer informatie.
Het team is gestart met een DockerFile (het manifest) waarin de elementen worden gelaagd van wat het team wil gebruiken. Ze beginnen met een python-basisinstallatiekopieën waarop de pyodbc bibliotheken al zijn geïnstalleerd en vervolgens voeren ze alle opdrachten uit die nodig zijn om het programma en het configuratiebestand in de vorige stap te bevatten.
De volgende Dockerfile heeft de volgende stappen:
- Begin met een container binair bestand waarop Python al is geïnstalleerd.
pyodbc - Maak een werkmap voor de toepassing.
- Kopieer alle code uit de huidige map naar de
WORKDIRmap. - Installeer de bibliotheken die vereist zijn.
- Nadat de container is gestart, voert u de toepassing uit en opent u alle TCP/IP-poorten.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Met dat bestand is het team naar een opdrachtprompt in de coderingsmap verwijderd en de volgende code uitgevoerd om de binaire installatiekopieën te maken vanuit het manifest en vervolgens een andere opdracht om de container te starten:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
Opnieuw test het team de http://localhost:5000/products koppeling om ervoor te zorgen dat de container toegang heeft tot de database en zien ze de volgende retour:

De installatiekopieën implementeren in een Docker-register
De container werkt nu, maar is alleen beschikbaar op de computer van de ontwikkelaar. Het ontwikkelingsteam wil deze toepassingsinstallatiekopieën beschikbaar maken voor de rest van het bedrijf en vervolgens naar Kubernetes voor productie-implementatie.
Het opslaggebied voor containerinstallatiekopieën wordt een opslagplaats genoemd en er kunnen zowel openbare als persoonlijke opslagplaatsen zijn voor containerinstallatiekopieën. AdvenureWorks heeft in feite een openbare installatiekopie gebruikt voor de Python-omgeving in hun Dockerfile.
Het team wil de toegang tot de installatiekopie beheren en in plaats van de installatiekopie op internet te plaatsen, besluiten ze deze zelf te hosten, maar in Microsoft Azure waar ze volledige controle hebben over beveiliging en toegang. Meer informatie over Microsoft Azure Container Registry vindt u hier.
Als u terugkeert naar de opdrachtregel, gebruikt az CLI het ontwikkelteam om een containerregisterservice toe te voegen, een beheeraccount in te schakelen, dit in te stellen op anonieme pulls tijdens de testfase en een aanmeldingscontext in te stellen op het register:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Deze context wordt gebruikt in de volgende stappen.
De lokale Docker-installatiekopieën taggen om deze voor te bereiden voor het uploaden
De volgende stap is het verzenden van de containerinstallatiekopieën van de lokale toepassing naar de ACR-service (Azure Container Registry), zodat deze beschikbaar is in de cloud.
- In het volgende voorbeeldscript gebruikt het team de Docker-opdrachten om de installatiekopieën op de computer weer te geven.
- Ze gebruiken het
az CLIhulpprogramma om de installatiekopieën in de ACR-service weer te geven. - Ze gebruiken de Docker-opdracht om de installatiekopieën te taggen met de doelnaam van de ACR die ze in de vorige stap hebben gemaakt en om een versienummer in te stellen voor de juiste DevOps.
- Ten slotte vermelden ze de lokale afbeeldingsgegevens opnieuw om ervoor te zorgen dat de tag correct is toegepast.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
Wanneer de code is geschreven en getest, kunnen de Dockerfile, installatiekopieën en containers worden uitgevoerd en getest, de ACR-service is ingesteld en alle toegepaste tags, het team de installatiekopieën uploaden naar de ACR-service.
Ze gebruiken de Docker-opdracht 'push' om het bestand te verzenden en vervolgens het az CLI hulpprogramma om ervoor te zorgen dat de installatiekopieën zijn geladen:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Implementeren naar Kubernetes
Het team kan eenvoudig containers uitvoeren en de toepassing implementeren in on-premises en in-cloudomgevingen. Ze willen echter meerdere kopieën van de toepassing toevoegen voor schaal en beschikbaarheid, andere containers toevoegen die verschillende taken uitvoeren en bewaking en instrumentatie toevoegen aan de hele oplossing.
Om containers samen te groeperen in een volledige oplossing, besloot het team Kubernetes te gebruiken. Kubernetes wordt on-premises en in alle belangrijke cloudplatforms uitgevoerd. Microsoft Azure heeft een volledige beheerde omgeving voor Kubernetes, de Azure Kubernetes Service (AKS). Meer informatie over AKS met de inleiding tot Kubernetes in azure-trainingstraject.
Met behulp van het az CLI hulpprogramma voegt het team AKS toe aan dezelfde resourcegroep die ze eerder hebben gemaakt. Met één az opdracht voert het ontwikkelteam de volgende stappen uit:
- Twee 'knooppunten' of rekenomgevingen toevoegen voor tolerantie in de testfase
- Automatisch SSH-sleutels genereren voor toegang tot de omgeving
- Koppel de ACR-service die ze in de vorige stappen hebben gemaakt, zodat het AKS-cluster de installatiekopieën kan vinden die ze voor de implementatie willen gebruiken
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Kubernetes maakt gebruik van een opdrachtregelprogramma voor toegang tot en beheer van een cluster, genaamd kubectl. Het team gebruikt het hulpprogramma om het az CLI kubectl hulpprogramma te downloaden en te installeren:
az aks install-cli
Omdat ze op dit moment verbinding hebben met AKS, kunnen ze het vragen om de SSH-sleutels te verzenden om verbinding te gebruiken wanneer ze het kubectl hulpprogramma uitvoeren:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Deze sleutels worden opgeslagen in een bestand met de naam .config in de map van de gebruiker. Als deze beveiligingscontext is ingesteld, gebruikt kubectl get nodes het team om de knooppunten in het cluster weer te geven:
kubectl get nodes
Nu gebruikt het team het az CLI hulpprogramma om de afbeeldingen in de ACR-service weer te geven:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Nu kunnen ze het manifest bouwen dat Kubernetes gebruikt om de implementatie te beheren. Dit is een tekstbestand dat is opgeslagen in een YAML-indeling . Dit is de geannoteerde tekst in het flask2sql.yaml bestand:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
Als het flask2sql.yaml bestand is gedefinieerd, kan het team de toepassing implementeren in het actieve AKS-cluster. Dit wordt gedaan met de kubectl apply opdracht, die, zoals u zich herinnert, nog steeds een beveiligingscontext voor het cluster heeft. Vervolgens wordt de kubectl get service opdracht verzonden om het cluster te bekijken terwijl het wordt gebouwd.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Na enkele ogenblikpen retourneert de opdracht 'watch' een extern IP-adres. Op dat moment drukt het team op Ctrl-C om de controleopdracht te verbreken en registreert het externe IP-adres van de load balancer.
De toepassing testen
Met behulp van het IP-adres (eindpunt) dat ze in de laatste stap hebben verkregen, controleert het team om dezelfde uitvoer te garanderen als de lokale toepassing en de Docker-container:
Opschonen
Nu de toepassing is gemaakt, bewerkt, gedocumenteerd en getest, kan het team de toepassing nu 'afbreken'. Door alles in één resourcegroep in Microsoft Azure te bewaren, is het eenvoudig om de PoC-resourcegroep te verwijderen met behulp van het az CLI hulpprogramma:
az group delete -n ReplaceWith_PoCResourceGroupName -y
Notitie
Als u uw Azure SQL Database in een andere resourcegroep hebt gemaakt en u deze niet meer nodig hebt, kunt u de Azure-portal gebruiken om deze te verwijderen.
Het teamlid dat het PoC-project leidt, gebruikt Microsoft Windows als werkstation en wil het geheimenbestand van Kubernetes behouden, maar het uit het systeem verwijderen als de actieve locatie. Ze kunnen het bestand gewoon naar een config.old tekstbestand kopiëren en vervolgens verwijderen:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
Gerelateerde inhoud
- Overzicht van toepassingsontwikkeling - SQL Database & SQL Managed Instance
- Verbinding maken azure SQL Database doorzoeken en er query's op uitvoeren met behulp van Python en het pyodbc-stuurprogramma
- Een databaseproject voor Azure SQL Database publiceren naar de lokale emulator
- Door codevoorbeelden bladeren voor Azure SQL Database