Zelfstudie: Afwijkingen detecteren en analyseren met behulp van KQL-mogelijkheden voor machine learning in Azure Monitor
De Kusto-querytaal (KQL) omvat machine learning-operators, functies en invoegtoepassingen voor tijdreeksanalyse, anomaliedetectie, prognose en hoofdoorzaakanalyse. Gebruik deze KQL-mogelijkheden om geavanceerde gegevensanalyses uit te voeren in Azure Monitor zonder de overhead van het exporteren van gegevens naar externe machine learning-hulpprogramma's.
In deze zelfstudie leert u het volgende:
- Een tijdreeks maken
- Afwijkingen in een tijdreeks identificeren
- Instellingen voor anomaliedetectie aanpassen om resultaten te verfijnen
- De hoofdoorzaak van afwijkingen analyseren
Notitie
Deze zelfstudie bevat koppelingen naar een Log Analytics-demoomgeving waarin u de KQL-queryvoorbeelden kunt uitvoeren. De gegevens in de demo-omgeving zijn dynamisch, dus de queryresultaten zijn niet hetzelfde als de queryresultaten die in dit artikel worden weergegeven. U kunt echter dezelfde KQL-query's en -principals implementeren in uw eigen omgeving en alle Azure Monitor-hulpprogramma's die gebruikmaken van KQL.
Vereisten
- Een Azure-account met een actief abonnement. Gratis een account maken
- Een werkruimte met logboekgegevens.
Vereiste machtigingen
U moet bijvoorbeeld machtigingen hebben Microsoft.OperationalInsights/workspaces/query/*/read voor de Log Analytics-werkruimten die u opvraagt, zoals opgegeven door de ingebouwde rol log analytics-lezer.
Een tijdreeks maken
Gebruik de KQL-operator make-series om een tijdreeks te maken.
We gaan een tijdreeks maken op basis van logboeken in de tabel Gebruik, die informatie bevat over hoeveel gegevens elke tabel in een werkruimte elk uur opneemt, inclusief factureerbare en niet-factureerbare gegevens.
Deze query gebruikt make-series om de totale hoeveelheid factureerbare gegevens weer te geven die elke dag in elke tabel in de werkruimte zijn opgenomen, in de afgelopen 21 dagen:
Klik hier om een query uit te voeren
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
In de resulterende grafiek ziet u duidelijk enkele afwijkingen, bijvoorbeeld in de AzureDiagnostics en SecurityEvent gegevenstypen:
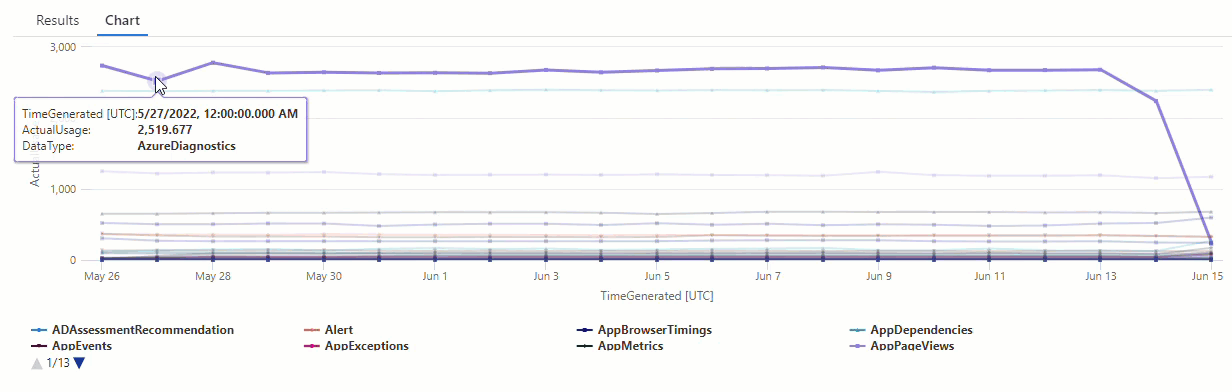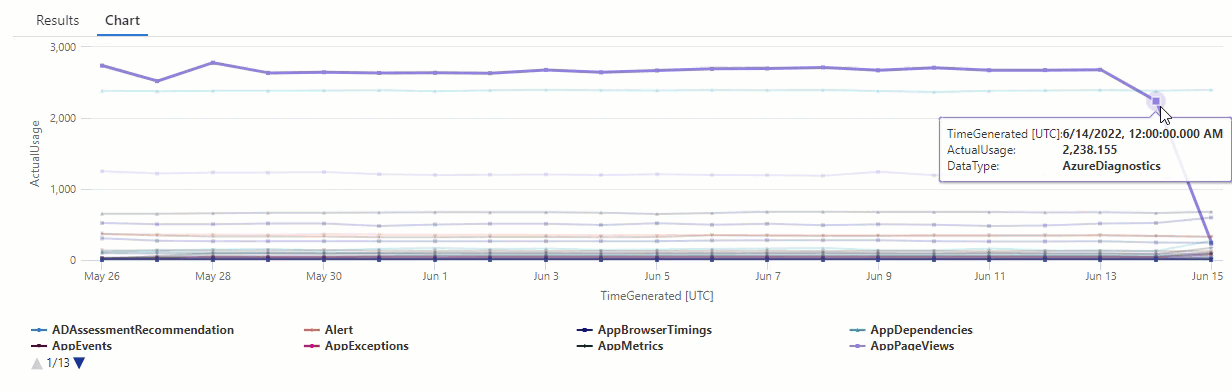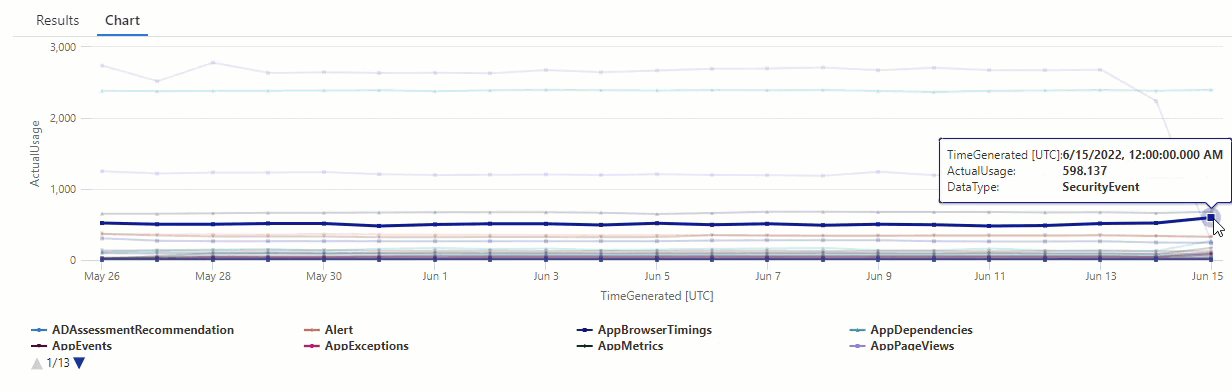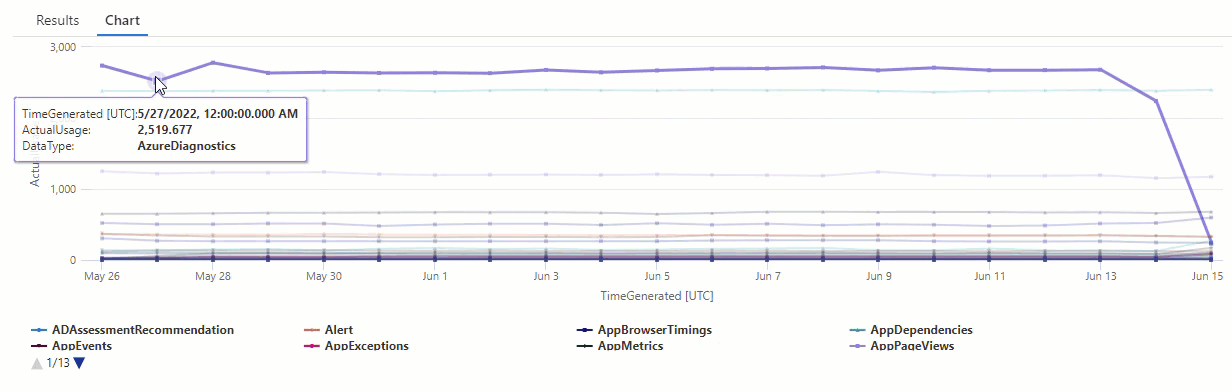
Vervolgens gebruiken we een KQL-functie om alle afwijkingen in een tijdreeks weer te geven.
Notitie
Zie operator make-series voor meer informatie over make-series syntaxis en gebruik.
Afwijkingen in een tijdreeks zoeken
De series_decompose_anomalies() functie gebruikt een reeks waarden als invoer en extraheert afwijkingen.
Laten we de resultatenset van onze tijdreeksquery als invoer voor de series_decompose_anomalies() functie geven:
Klik hier om een query uit te voeren
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Deze query retourneert alle gebruiksafwijkingen voor alle tabellen in de afgelopen drie weken:

Als u de queryresultaten bekijkt, ziet u dat de functie:
- Berekent een verwacht dagelijks gebruik voor elke tabel.
- Vergelijkt het werkelijke dagelijkse gebruik met het verwachte gebruik.
- Wijst een anomaliescore toe aan elk gegevenspunt, wat de mate aangeeft van de afwijking van het werkelijke gebruik van het verwachte gebruik.
- Identificeert positieve (
1) en negatieve (-1) afwijkingen in elke tabel.
Notitie
Zie series_decompose_anomalies() voor meer informatie over series_decompose_anomalies() syntaxis en gebruik.
Instellingen voor anomaliedetectie aanpassen om resultaten te verfijnen
Het is raadzaam om de eerste queryresultaten te bekijken en zo nodig aanpassingen aan de query aan te brengen. Uitbijters in invoergegevens kunnen van invloed zijn op het leren van de functie en mogelijk moet u de anomaliedetectie-instellingen van de functie aanpassen om nauwkeurigere resultaten te krijgen.
Filter de resultaten van de series_decompose_anomalies() query op afwijkingen in het AzureDiagnostics gegevenstype:

De resultaten tonen twee afwijkingen op 14 juni en 15 juni. Vergelijk deze resultaten met de grafiek uit onze eerste make-series query, waar u andere afwijkingen kunt zien op 27 mei en 28:

Het verschil in resultaten treedt op omdat de series_decompose_anomalies() functie afwijkingen beoordeelt ten opzichte van de verwachte gebruikswaarde, die de functie berekent op basis van het volledige bereik van waarden in de invoerreeks.
Als u meer verfijnde resultaten van de functie wilt krijgen, sluit u het gebruik op 15 juni uit, wat een uitbijter is vergeleken met de andere waarden in de reeks, uit van het leerproces van de functie.
De syntaxis van de series_decompose_anomalies() functie is:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points geeft het aantal punten aan het einde van de reeks op dat moet worden uitgesloten van het leerproces (regressie).
Als u het laatste gegevenspunt wilt uitsluiten, stelt u het 1volgende inTest_points:
Klik hier om een query uit te voeren
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filter de resultaten voor het AzureDiagnostics gegevenstype:

Alle afwijkingen in de grafiek uit onze eerste make-series query worden nu weergegeven in de resultatenset.
De hoofdoorzaak van afwijkingen analyseren
Als u verwachte waarden vergelijkt met afwijkende waarden, krijgt u inzicht in de oorzaak van de verschillen tussen de twee sets.
De KQL-invoegtoepassing diffpatterns() vergelijkt twee gegevenssets van dezelfde structuur en vindt patronen die verschillen tussen de twee gegevenssets karakteriseren.
Deze query vergelijkt AzureDiagnostics het gebruik op 15 juni, de extreme uitschieter in ons voorbeeld, met het tabelgebruik op andere dagen:
Klik hier om een query uit te voeren
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
De query identificeert elke vermelding in de tabel zoals op AnomalyDate (15 juni) of OtherDates. De diffpatterns() invoegtoepassing splitst vervolgens deze gegevenssets , genaamd A (OtherDates in ons voorbeeld) en B (AnomalyDate in ons voorbeeld) en retourneert een aantal patronen die bijdragen aan de verschillen in de twee sets:

Als u de queryresultaten bekijkt, ziet u de volgende verschillen:
- Er zijn 24.892.147 exemplaren van opname van de CH1-GEARAMAAKS-resource op alle andere dagen in het tijdsbereik van de query en geen opname van gegevens uit deze resource op 15 juni. Gegevens van de CH1-GEARAMAAKS-resource zijn 73,36% van de totale opname op andere dagen in het querytijdbereik en 0% van de totale opname op 15 juni.
- Er zijn 2.168.448 exemplaren van opname van de NSG-TESTSQLMI519 resource op alle andere dagen in het tijdsbereik van de query en 110.544 exemplaren van opname van deze resource op 15 juni. Gegevens van de NSG-TESTSQLMI519-resource zijn 6,39% van de totale opname op andere dagen in het querytijdbereik en 25,61% van de opname op 15 juni.
U ziet dat er gemiddeld 108.422 exemplaren van opname van de NSG-TESTSQLMI519 resource zijn gedurende de 20 dagen waaruit de andere dagen bestaan (deel 2.168.448 door 20). Daarom is de opname van de NSG-TESTSQLMI519-resource op 15 juni niet aanzienlijk anders dan de opname van deze resource op andere dagen. Omdat er echter geen opname is van CH1-GEARAMAAKS op 15 juni, maakt de opname van NSG-TESTSQLMI519 een aanzienlijk hoger percentage van de totale opname op de anomaliedatum in vergelijking met andere dagen.
In de kolom PercentDiffAB wordt het absolute verschil tussen het percentagepunt tussen A en B (|PercentA - PercentB|), de belangrijkste meting van het verschil tussen de twee sets. De invoegtoepassing retourneert standaard diffpatterns() een verschil van meer dan 5% tussen de twee gegevenssets, maar u kunt deze drempelwaarde aanpassen. Als u bijvoorbeeld alleen verschillen van 20% of meer tussen de twee gegevenssets wilt retourneren, kunt u instellen | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) in de bovenstaande query. De query retourneert nu slechts één resultaat:

Notitie
Zie de invoegtoepassing voor diff-patronen voor meer informatie over diffpatterns() syntaxis en gebruik.
Volgende stappen
Meer informatie over: