Uitleg van aggregatie en weergave van metrische gegevens in Azure Monitor
In dit artikel wordt de aggregatie van metrische gegevens in de tijdreeksdatabase uitgelegd die de metrische gegevens en aangepaste metrische gegevens van het Azure Monitor-platform back-ups maakt. Het artikel is ook van toepassing op metrische standaardgegevens van Application Insights.
Deze informatie in dit artikel is complex en wordt verstrekt voor degenen die dieper willen ingaan op het metrische systeem. U hoeft deze niet te begrijpen om metrische gegevens van Azure Monitor effectief te kunnen gebruiken.
Overzicht en termen
Wanneer u een metrische waarde aan een grafiek toevoegt, selecteert Metrics Explorer automatisch de standaardaggregatie. De standaardinstelling is logisch in de basisscenario's, maar u kunt verschillende aggregaties gebruiken om meer inzicht te krijgen in de metrische gegevens. Voor het weergeven van verschillende aggregaties in een grafiek moet u begrijpen hoe metrics Explorer deze verwerkt.
Laten we eerst een paar termen duidelijk definiëren:
- Metrische waarde : één meetwaarde die is verzameld voor een specifieke resource.
- Time-Series-database : een database die is geoptimaliseerd voor de opslag en het ophalen van gegevenspunten die allemaal een waarde en een bijbehorende tijdstempel bevatten.
- Periode: een algemene periode.
- Tijdsinterval : de periode tussen het verzamelen van twee metrische waarden.
- Tijdsbereik : de tijdsperiode die wordt weergegeven in een grafiek. De standaardwaarde is 24 uur. Er zijn alleen specifieke bereiken beschikbaar.
- Tijdgranulariteit of tijdsinterval : de tijdsperiode die wordt gebruikt om waarden samen te voegen om weergave in een grafiek mogelijk te maken. Er zijn alleen specifieke bereiken beschikbaar. Het huidige minimum is 1 minuut. De tijdgranulariteitswaarde moet kleiner zijn dan het geselecteerde tijdsbereik, anders wordt slechts één waarde weergegeven voor de hele grafiek.
- Aggregatietype : een type statistiek dat wordt berekend op basis van meerdere metrische waarden.
- Aggregatie : het proces van het nemen van meerdere invoerwaarden en deze vervolgens gebruiken om één uitvoerwaarde te produceren via de regels die zijn gedefinieerd door het aggregatietype. Bijvoorbeeld het nemen van een gemiddelde van meerdere waarden.
Samenvatting van proces
Metrische gegevens zijn een reeks waarden die zijn opgeslagen met een tijdstempel. In Azure worden de meeste metrische gegevens opgeslagen in de tijdreeksdatabase van Azure Metrics. Wanneer u een grafiek tekent, worden de waarden van de geselecteerde metrische gegevens opgehaald uit de database en vervolgens afzonderlijk geaggregeerd op basis van de gekozen tijdgranulariteit (ook wel tijdsinterval genoemd). U selecteert de grootte van de tijdgranulariteit met behulp van de tijdkiezer van Metrics Explorer. Als u geen expliciete selectie maakt, wordt de tijdgranulariteit automatisch geselecteerd op basis van het geselecteerde tijdsbereik. Zodra deze optie is geselecteerd, worden de metrische waarden die tijdens elk granulariteitsinterval zijn vastgelegd, samengevoegd en in de grafiek geplaatst: één gegevenspunt per interval.
Typen aggregatie
Er zijn vijf eenvoudige aggregatietypen beschikbaar in de Metrics Explorer. Metrics Explorer verbergt de aggregaties die niet relevant zijn en kunnen niet worden gebruikt voor een bepaalde metrische waarde.
- Som : de som van alle waarden die zijn vastgelegd tijdens het aggregatie-interval. Ook wel de totalaggregatie genoemd.
- Aantal : het aantal metingen dat is vastgelegd tijdens het aggregatie-interval. Count kijkt niet naar de waarde van de meting, alleen het aantal records.
- Gemiddelde : het gemiddelde van de metrische waarden die zijn vastgelegd tijdens het aggregatie-interval. Voor de meeste metrische gegevens is deze waarde Som/Aantal.
- Min. De kleinste waarde die is vastgelegd tijdens het aggregatie-interval.
- Max : de grootste waarde die is vastgelegd tijdens het aggregatie-interval.
Stel dat in een grafiek de metrische gegevens Network Out Total voor een virtuele machine worden weergegeven met behulp van de SOM-aggregatie gedurende de afgelopen periode van 24 uur. Het tijdsbereik en de granulariteit kunnen worden gewijzigd in de rechterbovenhoek van de grafiek, zoals te zien is in de volgende schermopname.
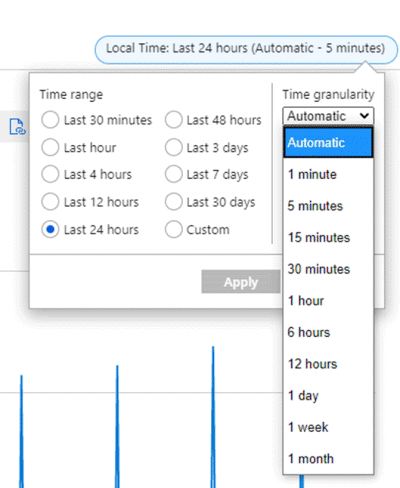
Voor tijdgranulariteit = 30 minuten en het tijdsbereik = 24 uur:
- De grafiek wordt getekend uit 48 gegevenspunten. Dat is 24 uur x 2 gegevenspunten per uur (60min/30min) geaggregeerde gegevenspunten van 1 minuut.
- Het lijndiagram verbindt 48 puntjes in het grafiekdiagramgebied.
- Elk gegevenspunt vertegenwoordigt de som van alle netwerk-outbytes die tijdens elke relevante periode van 30 minuten zijn verzonden.

Klik op de afbeeldingen in deze sectie om grotere versies weer te geven.
Als u de tijdgranulariteit overzet naar 15 minuten, wordt de grafiek getrokken van 96 geaggregeerde gegevenspunten. Dat wil gezegd: 60min/15min = 4 gegevenspunten per uur x 24 uur.

Voor tijdgranulariteit van 5 minuten krijgt u 24 x (60/5) = 288 punten.
Voor tijdgranulariteit van 1 minuut (het kleinste mogelijke in de grafiek) krijgt u 24 x 60/1 = 1440 punten.

De grafieken zien er anders uit voor deze samenvattingen, zoals wordt weergegeven in de vorige schermafbeeldingen. U ziet hoe deze VIRTUELE machine veel uitvoer heeft in een kleine periode ten opzichte van de rest van het tijdvenster.
Met de tijdgranulariteit kunt u de verhouding 'signaal-naar-ruis' in een grafiek aanpassen. Hogere aggregaties verwijderen ruis en vlakken pieken af. Let op de variaties in de onderste grafiek van 1 minuten en hoe deze worden uitgevlakt wanneer u naar hogere granulariteitswaarden gaat.
Dit vloeiende gedrag is belangrijk wanneer u deze gegevens naar andere systemen verzendt, bijvoorbeeld waarschuwingen. Normaal gesproken wilt u meestal niet worden gewaarschuwd door korte pieken in de CPU-tijd van meer dan 90%. Maar als de CPU 5 minuten op 90% blijft, is dat waarschijnlijk belangrijk. Als u een waarschuwingsregel instelt voor CPU (of metrische gegevens), kan de tijdgranulariteit groter worden het aantal valse waarschuwingen dat u ontvangt, verminderen.
Het is belangrijk om vast te stellen wat 'normaal' is voor uw workload om te weten welk tijdsinterval het beste is. Dit is een van de voordelen van dynamische waarschuwingen. Dit is een ander onderwerp dat hier niet wordt behandeld.
Hoe het systeem metrische gegevens verzamelt
Gegevensverzameling verschilt per metrische waarde.
Notitie
De onderstaande voorbeelden zijn vereenvoudigd ter illustratie en de werkelijke metrische gegevens die in elke aggregatie zijn opgenomen, worden beïnvloed door de gegevens die beschikbaar zijn wanneer de evaluatie plaatsvindt.
Frequentie van meetverzameling
Er zijn twee soorten verzamelingsperioden.
Normaal : de metrische waarde wordt verzameld met een consistent tijdsinterval dat niet varieert.
Op basis van activiteit: de metrische waarde wordt verzameld op basis van wanneer een transactie van een bepaald type plaatsvindt. Elke transactie heeft een metrische vermelding en een tijdstempel. Ze worden niet met regelmatige tussenpozen verzameld, dus er is een verschillend aantal records gedurende een bepaalde periode.
Granulariteit
De minimale tijdgranulariteit is 1 minuut, maar het onderliggende systeem kan gegevens sneller vastleggen, afhankelijk van de metrische waarde. Het CPU-percentage voor een Azure-VM wordt bijvoorbeeld vastgelegd met een tijdsinterval van 15 seconden. Omdat HTTP-fouten worden bijgehouden als transacties, kunnen ze gemakkelijk veel meer dan één minuut overschrijden. Andere metrische gegevens, zoals SQL Storage, worden vastgelegd met een tijdsinterval van elke 20 minuten. Deze keuze is aan de afzonderlijke resourceprovider en het type. De meeste proberen het kleinste tijdsinterval mogelijk te maken.
Dimensies, splitsen en filteren
Metrische gegevens worden vastgelegd voor elke afzonderlijke resource. Het niveau waarop de metrische gegevens worden verzameld, opgeslagen en in een grafiek kunnen worden weergegeven, kan echter variëren. Dit niveau wordt vertegenwoordigd door andere metrische gegevens die beschikbaar zijn in dimensies voor metrische gegevens. Elke afzonderlijke resourceprovider bepaalt hoe gedetailleerd de gegevens zijn die ze verzamelen. Azure Monitor definieert alleen hoe dergelijke details moeten worden weergegeven en opgeslagen.
Wanneer u een metrische waarde in Metric Explorer in kaart brengt, hebt u de mogelijkheid om de grafiek te splitsen op basis van een dimensie. Als u een grafiek splitst, zoekt u naar de onderliggende gegevens voor meer details en ziet u dat de gegevens in metric explorer zijn weergegeven of gefilterd.
Microsoft.ApiManagement/service heeft bijvoorbeeld Location als dimensie voor veel metrische gegevens.
Capaciteit is een van deze metrische gegevens. Als de locatiedimensie impliceert dat het onderliggende systeem een metrische record opslaat voor de capaciteit van elke locatie, in plaats van slechts één voor het cumulatieve bedrag. U kunt die informatie vervolgens ophalen of splitsen in een metrische grafiek.
Als u de totale duur van gatewayaanvragen bekijkt, zijn er twee dimensies Locatie en Hostnaam, zodat u de locatie van een duur weet en van welke hostnaam deze afkomstig is.
Een van de flexibelere metrische gegevens, Requests, heeft 7 verschillende dimensies.
Raadpleeg het artikel metrische gegevens van Azure Monitor voor meer informatie over elke metrische waarde en de beschikbare dimensies. Daarnaast kan de documentatie voor elke resourceprovider en elk type aanvullende informatie geven over de dimensies en wat ze meten.
U kunt splitsen en filteren gebruiken om in een probleem te graven. Hieronder ziet u een voorbeeld van een afbeelding met de gemiddelde schijfschrijfbytes voor een groep virtuele machines in een resourcegroep. We hebben een samenteling van alle VM's met deze metrische waarde, maar we willen misschien kijken welke verantwoordelijk zijn voor de pieken rond 6:00 uur. Zijn ze dezelfde machine? Hoeveel machines zijn betrokken?

Klik op de afbeeldingen in deze sectie om grotere versies weer te geven.
Wanneer we splitsen toepassen, kunnen we de onderliggende gegevens zien, maar het is een beetje een puinhoop. Blijkt dat er 20 VM's worden samengevoegd in de bovenstaande grafiek. In dit geval hebben we onze muis gebruikt om de muisaanwijzer over de grote piek om 6:00 uur te bewegen die aangeeft dat CH-DCVM11 de oorzaak is. Maar het is moeilijk om de rest van de gegevens te zien die aan die VM zijn gekoppeld, omdat andere VM's de grafiek onbelangrijker maken.

Door filteren te gebruiken, kunnen we de grafiek opschonen om te zien wat er echt gebeurt. U kunt de VM's die u wilt zien, controleren of uitschakelen. Let op de stippellijnen. Deze worden vermeld in een latere sectie.

Zie Geavanceerde functies van Metrics Explorer- filters en splitsingen voor meer informatie over het weergeven van gesplitste dimensiegegevens in een metric explorer-grafiek.
NULL- en nulwaarden
Wanneer het systeem metrische gegevens van een resource verwacht, maar deze niet ontvangt, wordt er een NULL-waarde vastgelegd. NULL is anders dan een nulwaarde, wat belangrijk wordt in de berekening van aggregaties en grafieken. NULL-waarden worden niet meegeteld als geldige metingen.
NULL's worden anders weergegeven in verschillende grafieken. Spreidingsdiagrammen slaan over met een punt in het diagram. Staafdiagrammen slaan de balk over. In lijndiagrammen kan NULL worden weergegeven als stippellijnen of stippellijnen , zoals in de schermafbeelding in de vorige sectie. Bij het berekenen van gemiddelden met NULL's zijn er minder gegevenspunten waaruit het gemiddelde moet worden genomen. Dit gedrag kan soms leiden tot een onverwachte daling van waarden in een grafiek, maar minder dan als de waarde is geconverteerd naar een nul en wordt gebruikt als een geldig gegevenspunt.
Aangepaste metrische gegevens gebruiken altijd NULL's wanneer er geen gegevens worden ontvangen. Met metrische platformgegevens bepaalt elke resourceprovider of nullen of NULL's moet worden gebruikt op basis van wat het meest zinvol is voor een bepaalde metrische waarde.
Azure Monitor-waarschuwingen gebruiken de waarden die de resourceprovider schrijft naar de metrische database, dus het is belangrijk om te weten hoe de resourceprovider nulls verwerkt door eerst de gegevens weer te geven.
Hoe aggregatie werkt
In de grafieken met metrische gegevens in het vorige systeem worden verschillende typen geaggregeerde gegevens weergegeven. In het systeem worden de gegevens vooraf samengevoegd, zodat de aangevraagde grafieken sneller kunnen worden weergegeven zonder veel herhaalde berekeningen.
In dit voorbeeld:
- We verzamelen een fictieve transactionele metriek met de naam HTTP-fouten
- Server is een dimensie voor de metrische http-fouten .
- We hebben 3 servers - Server A, B en C.
Ter vereenvoudiging van de uitleg beginnen we alleen met het aggregatietype SUM.
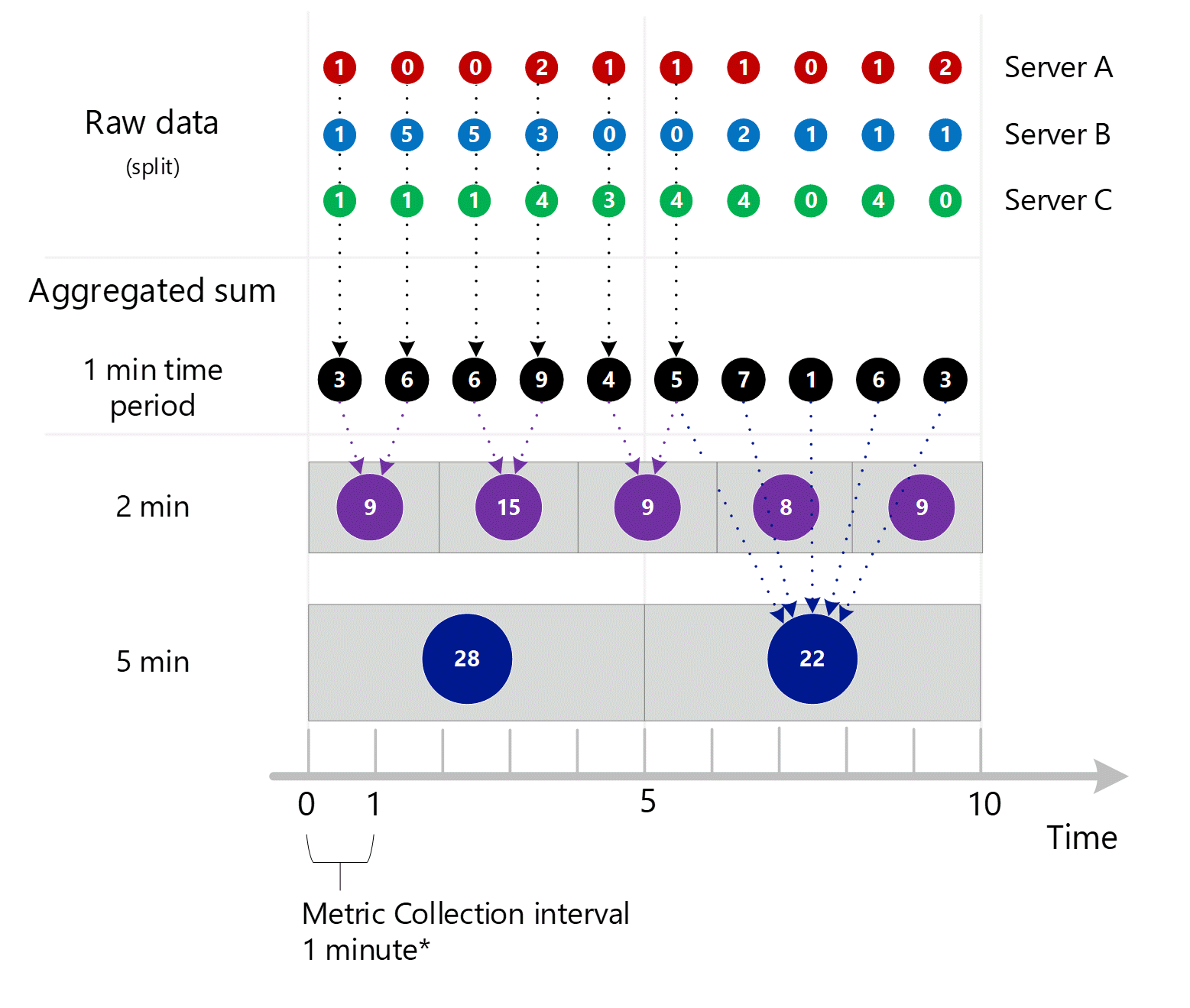
Aggregatie van subminut tot 1 minuut
De eerste onbewerkte metrische gegevens worden verzameld en opgeslagen in de metrische gegevensdatabase van Azure Monitor. In dit geval bevat elke server transactierecords die zijn opgeslagen met een tijdstempel, omdat Server een dimensie is. Aangezien de kleinste periode die u als klant kunt bekijken 1 minuut is, worden deze tijdstempels eerst geaggregeerd in metrische waarden van 1 minuut voor elke afzonderlijke server. Het aggregatieproces voor Server B wordt weergegeven in de onderstaande afbeelding. Servers A en C worden op dezelfde manier uitgevoerd en hebben verschillende gegevens.
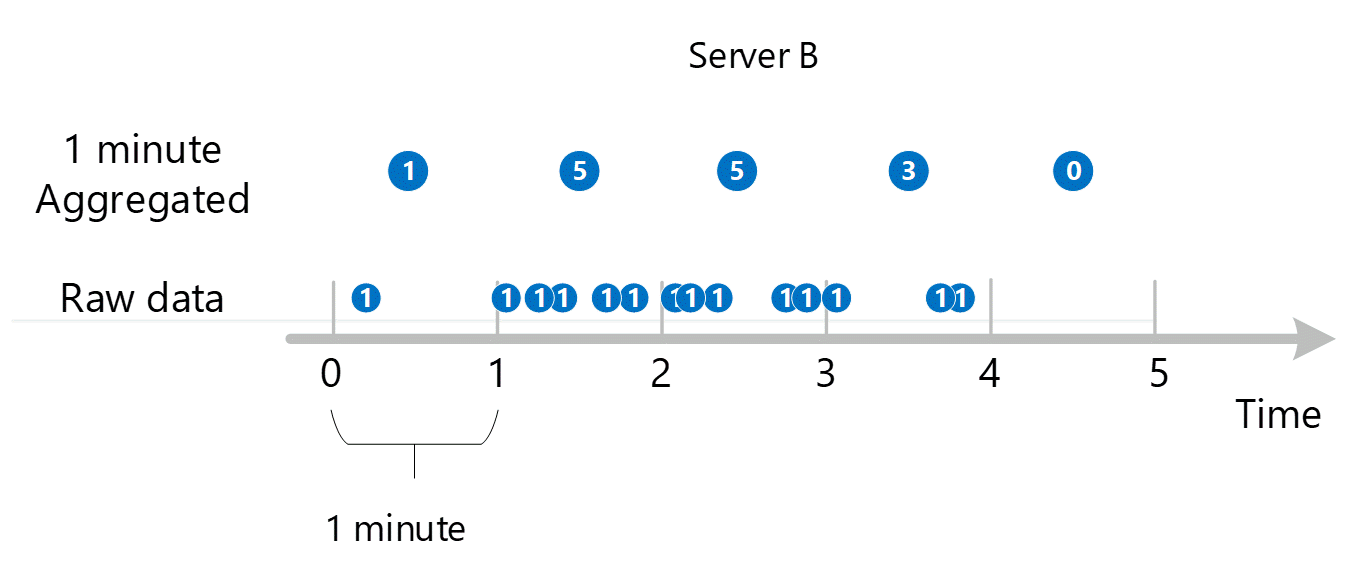
De resulterende geaggregeerde waarden van 1 minuut worden opgeslagen als nieuwe vermeldingen in de metrische database, zodat ze kunnen worden verzameld voor latere berekeningen.
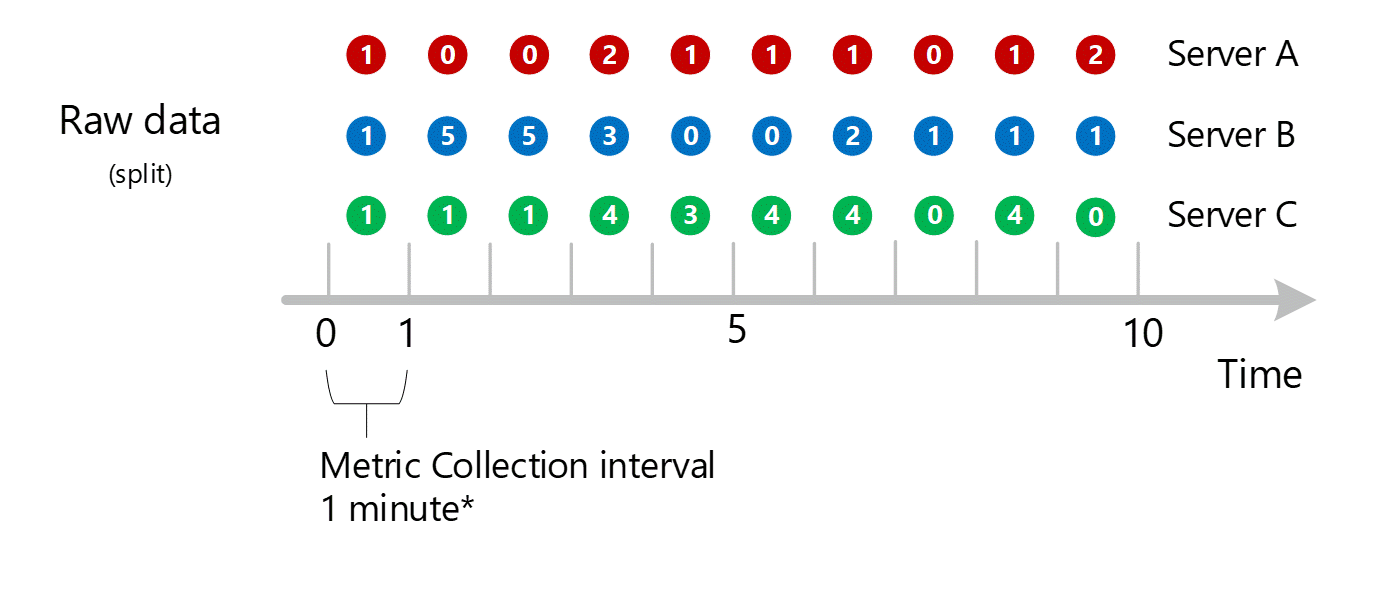
Dimensieaggregatie
De berekeningen van 1 minuut worden vervolgens samengevouwen per dimensie en opnieuw opgeslagen als afzonderlijke records. In dit geval worden alle gegevens van alle afzonderlijke servers samengevoegd tot een metrische interval van 1 minuut en opgeslagen in de database met metrische gegevens voor gebruik in latere aggregaties.
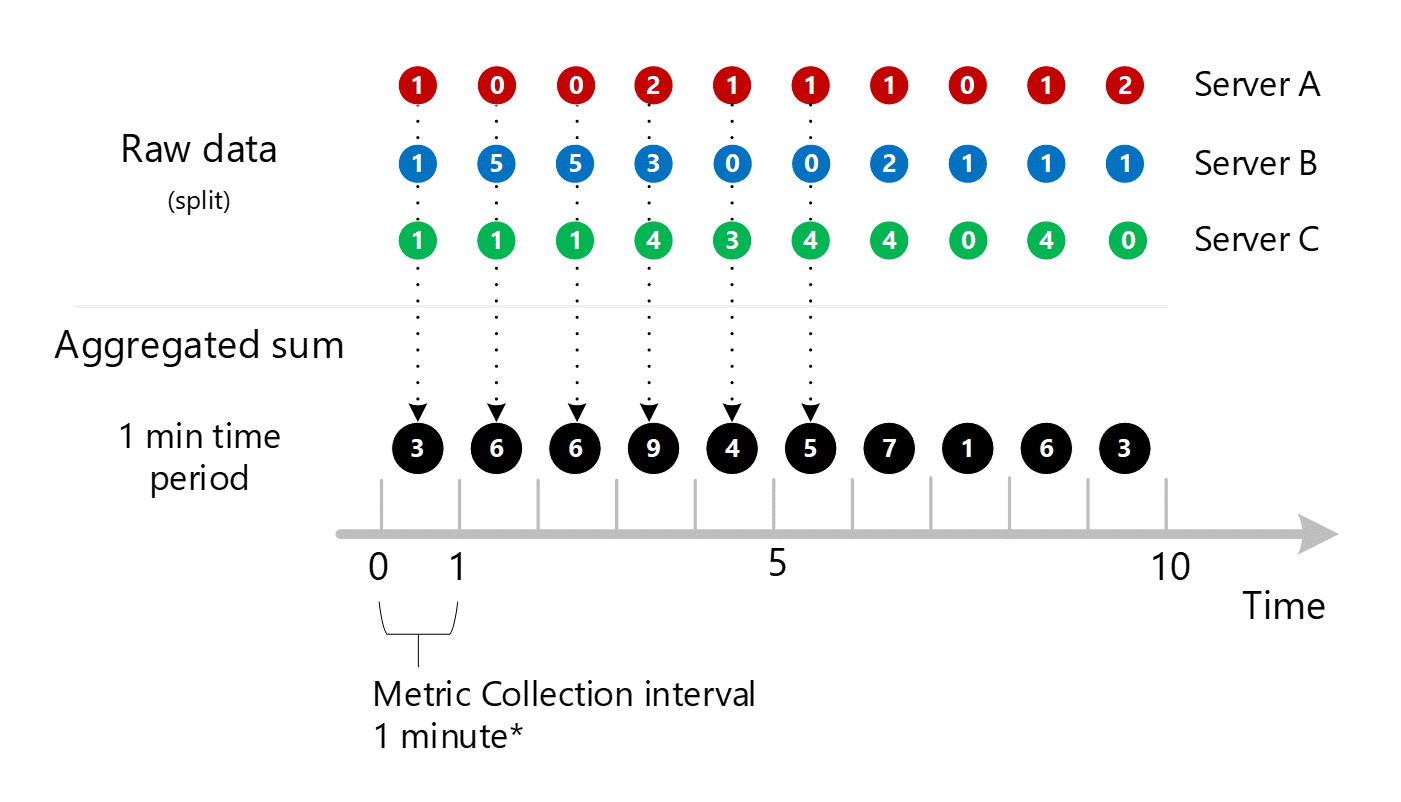
Voor de duidelijkheid toont de volgende tabel de aggregatiemethode.
| Periode | Server A | Server B | Server C | Som (A+B+C) |
|---|---|---|---|---|
| Minuut 1 | 1 | 1 | 1 | 3 |
| Minuut 2 | 0 | 5 | 1 | 6 |
| Minuut 3 | 0 | 5 | 1 | 6 |
| Minuut 4 | 2 | 3 | 4 | 9 |
| Minuut 5 | 1 | 0 | 3 | 4 |
| Minuut 6 | 1 | 0 | 4 | 5 |
| Minuut 7 | 1 | 2 | 4 | 7 |
| Minuut 8 | 0 | 1 | 0 | 1 |
| Minuut 9 | 1 | 1 | 4 | 6 |
| Minuut 10 | 2 | 1 | 0 | 3 |
Er wordt hierboven slechts één dimensie weergegeven, maar hetzelfde aggregatie- en opslagproces vindt plaats voor alle dimensies die door een metrische waarde worden ondersteund.
- Verzamel waarden in een geaggregeerde waarde van 1 minuut die door die dimensie is ingesteld. Sla deze waarden op.
- Vouw de dimensie samen in een geaggregeerde SOM van 1 minuut. Sla deze waarden op.
Laten we een andere dimensie introduceren van HTTP-fouten met de naam NetworkAdapter. Stel dat we een verschillend aantal adapters per server hebben.
- Server A heeft 1 adapter
- Server B heeft 2 adapters
- Server C heeft 3 adapters
We verzamelen gegevens voor de volgende transacties afzonderlijk. Ze worden gemarkeerd met:
- Een tijd
- Een waarde
- De server van waaruit de transactie afkomstig is
- De adapter van waaruit de transactie afkomstig is
Elk van deze subminutestreams wordt vervolgens geaggregeerd in tijdreekswaarden van 1 minuut en opgeslagen in de metrische Azure Monitor-database:
- Server A, Adapter 1
- Server B, Adapter 1
- Server B, Adapter 2
- Server C, Adapter 1
- Server C, Adapter 2
- Server C, Adapter 3
Bovendien worden de volgende samengevouwen aggregaties ook opgeslagen:
- Server A, Adapter 1 (omdat er niets is om samen te vouwen, wordt deze opnieuw opgeslagen)
- Server B, Adapter 1+2
- Server C, Adapter 1+2+3
- Servers ALL, Adapters ALL
Dit laat zien dat metrische gegevens met grote aantallen dimensies een groter aantal aggregaties hebben. Het is niet belangrijk om alle permutaties te kennen, alleen de redenering te begrijpen. Het systeem wil zowel de afzonderlijke gegevens als de geaggregeerde gegevens laten opslaan voor snelle ophaaltijd voor toegang in een grafiek. Het systeem kiest de meest relevante opgeslagen aggregatie of de onderliggende onbewerkte gegevens, afhankelijk van wat u wilt weergeven.
Aggregatie zonder dimensies
Omdat deze metrische waarde een dimensieserver heeft, kunt u de onderliggende gegevens voor server A, B en C hierboven openen via splitsen en filteren, zoals eerder in dit artikel is uitgelegd. Als de metrische waarde geen server als dimensie heeft, hebt u als klant alleen toegang tot de geaggregeerde som van 1 minuut die in het diagram zwart wordt weergegeven. Dat wil gezegd, de waarden van 3, 6, 6, 9, enzovoort. Het systeem zou ook niet het onderliggende werk doen om gesplitste waarden te aggregeren die ze nooit zouden gebruiken in Metric Explorer of ze te verzenden via de REST API voor metrische gegevens.
Tijdgranulaties van meer dan 1 minuut bekijken
Als u bij een grotere granulariteit om metrische gegevens vraagt, gebruikt het systeem de geaggregeerde sommen van 1 minuut om de sommen voor de grotere tijdgranulariteiten te berekenen. Onder stippellijnen ziet u de optelmethode voor de granulaties van 2 minuten en 5 minuten. Nogmaals, we laten alleen het aggregatietype SOM zien om het eenvoudig te maken.
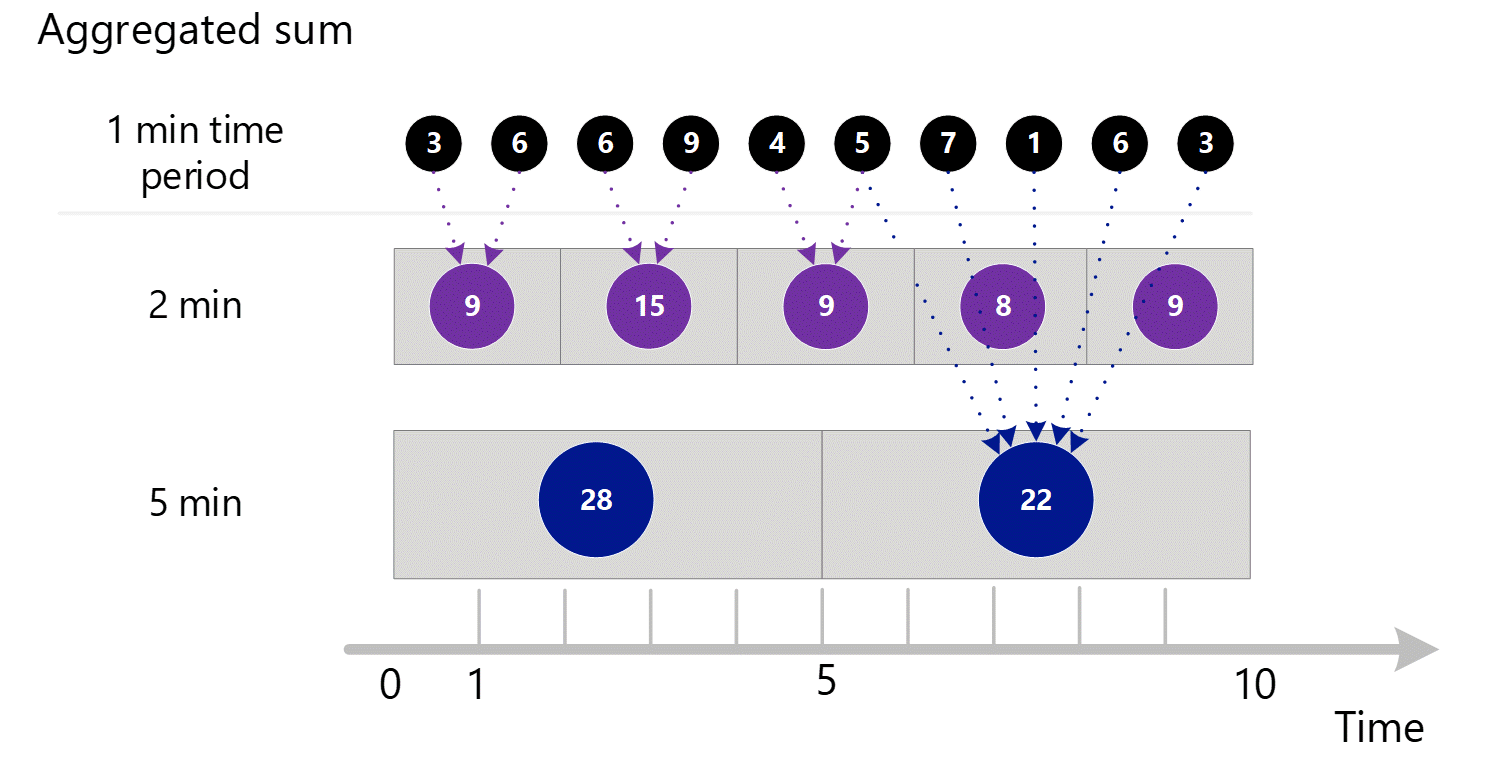
Voor de granulariteit van 2 minuten.
| Periode | Bedragen |
|---|---|
| Minuut 1 & 2 | (3 + 6) = 9 |
| Minuut 3 & 4 | (6 + 9) = 15 |
| Minuut 4 & 5 | (4 + 5) = 9 |
| Minuut 6 & 7 | (7 + 1) = 8 |
| Minuut 8 & 9 | (6 + 3) = 9 |
Voor granulariteit van 5 minuten.
| Periode | Bedragen |
|---|---|
| Minuut 1 tot en met 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minuut 6 tot en met 10 | 5 + 7 + 1 + 6 + 3 = 22 |
Het systeem maakt gebruik van de opgeslagen geaggregeerde gegevens die de beste prestaties bieden.
Hieronder ziet u het grotere diagram voor het bovenstaande aggregatieproces van 1 minuut, waarbij sommige pijlen zijn weggelaten om de leesbaarheid te verbeteren.
Complexer voorbeeld
Hieronder volgt een groter voorbeeld met behulp van waarden voor een fictieve metriek met de naam HTTP-reactietijd in milliseconden. Hier introduceren we andere complexiteitsniveaus.
- We tonen aggregatie voor Som, Aantal, Min en Max en de berekening voor Gemiddelde.
- We tonen NULL-waarden en hoe deze van invloed zijn op berekeningen.
Bekijk het volgende voorbeeld. In de vakken en pijlen ziet u voorbeelden van hoe de waarden worden geaggregeerd en berekend.
Hetzelfde vooraggregatieproces van 1 minuut zoals beschreven in de vorige sectie vindt plaats voor Sommen, Aantal, Minimum en Maximum. Het gemiddelde wordt echter NIET vooraf samengevoegd. Het wordt opnieuw berekend met behulp van geaggregeerde gegevens om berekeningsfouten te voorkomen.

Houd rekening met minuut 6 voor de aggregatie van 1 minuut, zoals hierboven is gemarkeerd. Dit moment is het punt waarop Server B offline ging en de rapportagegegevens stopte, mogelijk vanwege een herstart.
Vanaf minuut 6 hierboven zijn de berekende aggregatietypen van 1 minuut:
| Aggregatietype | Weergegeven als | Opmerkingen |
|---|---|---|
| Sum | 53+20=73 | |
| Tellen | 2 | Geeft het effect van NULLS weer. De waarde zou 3 zijn als de server online was geweest. |
| Minimum | 20 | |
| Maximum | 53 | |
| Gemiddeld | 73 / 2 | Altijd de som gedeeld door het aantal. Het wordt nooit opgeslagen en altijd opnieuw berekend voor elke keer dat granulariteit de geaggregeerde getallen voor die granulariteit gebruikt. Let op de herberekening voor de granulaties van 5 minuten en 10 minuten, zoals hierboven is gemarkeerd. |
De kleur van de rode tekst geeft waarden aan die mogelijk buiten het normale bereik vallen en laat zien hoe ze worden doorgegeven (of mislukken) omdat de tijdgranulariteit toeneemt. U ziet hoe min en max geven aan dat er onderliggende afwijkingen zijn, terwijl de gemiddelden en sommen die informatie verliezen naarmate uw tijdgranulariteit toeneemt.
U kunt ook zien dat de NULL's een betere berekening van het gemiddelde geven dan als er in plaats daarvan nullen zijn gebruikt.
Notitie
Hoewel dit niet het geval is in dit voorbeeld, is Count gelijk aan Sum in gevallen waarin een metrische waarde altijd wordt vastgelegd met de waarde 1. Dit is gebruikelijk wanneer een metrische waarde het optreden van een transactionele gebeurtenis bijhoudt, bijvoorbeeld het aantal HTTP-fouten dat in een eerder voorbeeld in dit artikel wordt vermeld.