Problemen met het verzamelen van metrische prometheus-gegevens in Azure Monitor oplossen
Volg de stappen in dit artikel om de oorzaak te bepalen van prometheus-metrische gegevens die niet worden verzameld zoals verwacht in Azure Monitor.
Metrische gegevens voor replicapods worden verwijderd uit kube-state-metrics, aangepaste scrapedoelen in de ama-metrics-prometheus-config configuratiemap en aangepaste scrapedoelen die zijn gedefinieerd in de aangepaste resources. DaemonSet pods scrapen metrische gegevens van de volgende doelen op hun respectieve knooppunt: kubelet, cAdvisor, node-exporteren aangepaste scrape-doelen in de ama-metrics-prometheus-config-node configmap. De pod die u wilt weergeven van de logboeken en de Gebruikersinterface van Prometheus, is afhankelijk van het doel dat u onderzoekt.
Problemen oplossen met behulp van PowerShell-script
Als er een fout optreedt tijdens het inschakelen van bewaking voor uw AKS-cluster, volgt u deze instructies om het script voor probleemoplossing uit te voeren. Dit script is ontworpen om een basisdiagnose uit te voeren voor configuratieproblemen in uw cluster en u kunt de gegenereerde bestanden bijvoegen terwijl u een ondersteuningsaanvraag voor een snellere oplossing voor uw ondersteuningsaanvraag maakt.
Beperking van metrische gegevens
Azure Monitor Managed Service voor Prometheus heeft standaardlimieten en quota voor opname. Wanneer u de opnamelimieten bereikt, kan beperking optreden. U kunt een verhoging van deze limieten aanvragen. Zie De limieten van de Azure Monitor-service voor informatie over metrische prometheus-limieten.
Navigeer in Azure Portal naar uw Azure Monitor-werkruimte. Ga naar Metrics, en selecteer de metrische gegevens Active Time Series % Utilization en Events Per Minute Received % Utilization. Controleer of beide lager zijn dan 100%.
Onregelmatige hiaten in het verzamelen van metrische gegevens
Tijdens knooppuntupdates ziet u mogelijk een hiaat van 1 tot 2 minuten in metrische gegevens voor metrische gegevens die zijn verzameld van de collector op clusterniveau. Dit gat komt doordat het knooppunt waarop het wordt uitgevoerd, wordt bijgewerkt als onderdeel van een normaal updateproces. Dit is van invloed op clusterbrede doelen, zoals metrische gegevens van kube-state en aangepaste toepassingsdoelen die zijn gespecificeerd. Dit gebeurt wanneer uw cluster handmatig of via automatisch bijwerken wordt bijgewerkt. Dit gedrag wordt verwacht en treedt op omdat de node wordt uitgevoerd wanneer deze wordt bijgewerkt. Geen van onze aanbevolen waarschuwingsregels wordt beïnvloed door dit gedrag.
Podstatus
Controleer de podstatus met de volgende opdracht:
kubectl get pods -n kube-system | grep ama-metrics
Wanneer de service correct wordt uitgevoerd, wordt de volgende lijst met pods in de indeling ama-metrics-xxxxxxxxxx-xxxxx geretourneerd:
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*pod voor elk knooppunt in het cluster.
Elke podstatus moet zijn Running en een gelijk aantal herstarts hebben voor het aantal wijzigingen in de configuratiekaart dat is toegepast. De pod ama-metrics-operator-targets-* kan aan het begin een extra herstart hebben en dit is verwacht:

Als elke podstatus Running maar een of meer pods opnieuw zijn opgestart, voert u de volgende opdracht uit:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Deze opdracht geeft de reden voor het opnieuw opstarten. Het opnieuw opstarten van pods wordt verwacht als er wijzigingen in de configuratiemap zijn aangebracht. Als de reden voor het opnieuw opstarten is
OOMKilled, kan de pod het volume met metrische gegevens niet bijhouden. Zie de aanbevelingen voor schaalaanpassing voor het volume metrische gegevens.
Als de pods worden uitgevoerd zoals verwacht, controleert u de containerlogboeken op de volgende plaats.
Controleren op configuraties voor opnieuw labelen
Als er metrische gegevens ontbreken, kunt u ook controleren of u configuraties opnieuw hebt gelabeld. Zorg ervoor dat bij het opnieuw labelen van configuraties de doelen niet worden gefilterd en dat de labels die correct zijn geconfigureerd, niet overeenkomen met de doelen. Zie de configuratiedocumentatie voor Prometheus relabel config voor meer informatie.
Containerlogboeken
Bekijk de containerlogboeken met de volgende opdracht:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
Bij het opstarten worden eventuele initiële fouten rood afgedrukt, terwijl waarschuwingen geel worden afgedrukt. (Voor het weergeven van de gekleurde logboeken is ten minste PowerShell versie 7 of een Linux-distributie vereist.)
- Controleer of er een probleem is met het ophalen van het verificatietoken:
- Het bericht Geen configuratie aanwezig voor de AKS-resource wordt elke 5 minuten geregistreerd.
- De pod wordt elke 15 minuten opnieuw opgestart om het opnieuw te proberen met de fout: Er is geen configuratie aanwezig voor de AKS-resource.
- Zo ja, controleert u of de regel voor gegevensverzameling en het eindpunt voor gegevensverzameling aanwezig zijn in uw resourcegroep.
- Controleer ook of de Azure Monitor-werkruimte bestaat.
- Controleer of u geen privé-AKS-cluster hebt en of het niet is gekoppeld aan een Azure Monitor Private Link-bereik voor een andere service. Dit scenario wordt momenteel niet ondersteund.
Configuratieverwerking
Bekijk de containerlogboeken met de volgende opdracht:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Controleer of er geen fouten zijn bij het parseren van de Prometheus-configuratie, het samenvoegen met eventuele standaard scrapedoelen ingeschakeld en het valideren van de volledige configuratie.
- Als u wel een aangepaste Prometheus-configuratie hebt opgenomen, controleert u of deze wordt herkend in de logboeken. Zo niet:
- Controleer of uw configuratiemap de juiste naam heeft:
ama-metrics-prometheus-configin dekube-systemnaamruimte. - Controleer of uw Prometheus-configuratie zich in de configuratiemap bevindt onder een sectie die wordt aangeroepen
prometheus-config,datazoals hier wordt weergegeven:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Controleer of uw configuratiemap de juiste naam heeft:
- Als u aangepaste resources hebt gemaakt, zou u validatiefouten moeten zien tijdens het maken van pod-/servicemonitors. Als u de metrische gegevens van de doelen nog steeds niet ziet, controleert u of in de logboeken geen fouten worden weergegeven.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Controleer of er geen fouten zijn met
MetricsExtensionbetrekking tot verificatie met de Azure Monitor-werkruimte. - Controleer of er geen fouten zijn opgetreden bij het
OpenTelemetry collectorscrapen van de doelen.
Voer de volgende opdracht uit:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Met deze opdracht wordt een fout weergegeven als er een probleem is met verificatie met de Azure Monitor-werkruimte. In het onderstaande voorbeeld ziet u logboeken zonder problemen:
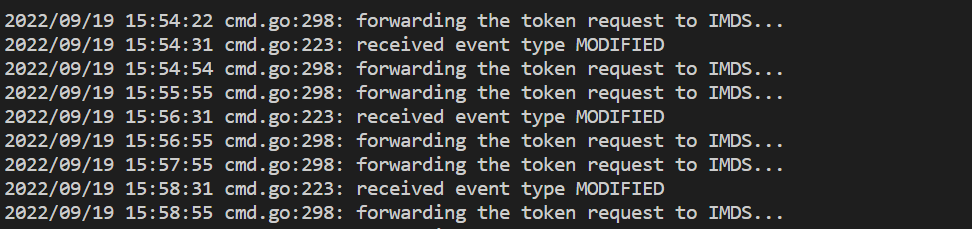

Als de logboeken geen fouten bevatten, kan de Prometheus-interface worden gebruikt voor foutopsporing om te controleren of de verwachte configuratie en doelen worden gesloopt.
Prometheus-interface
Elke ama-metrics-* pod heeft de gebruikersinterface van de Prometheus-agentmodus die beschikbaar is op poort 9090.
Aangepaste configuratie- en aangepaste resourcesdoelen worden door de ama-metrics-* pod en de knooppuntdoelen door de ama-metrics-node-* pod verwijderd.
Port-forward naar de replicapod of een van de daemon-set pods om de eindpunten voor configuratie, servicedetectie en doelen te controleren, zoals hier wordt beschreven om te controleren of de aangepaste configuraties juist zijn, de beoogde doelen zijn gedetecteerd voor elke taak en er zijn geen fouten met het scrapen van specifieke doelen.
Voer de opdracht kubectl port-forward <ama-metrics pod> -n kube-system 9090 uit.
Open een browser naar het adres
127.0.0.1:9090/config. Deze gebruikersinterface heeft de volledige scrape-configuratie. Controleer of alle taken zijn opgenomen in de configuratie.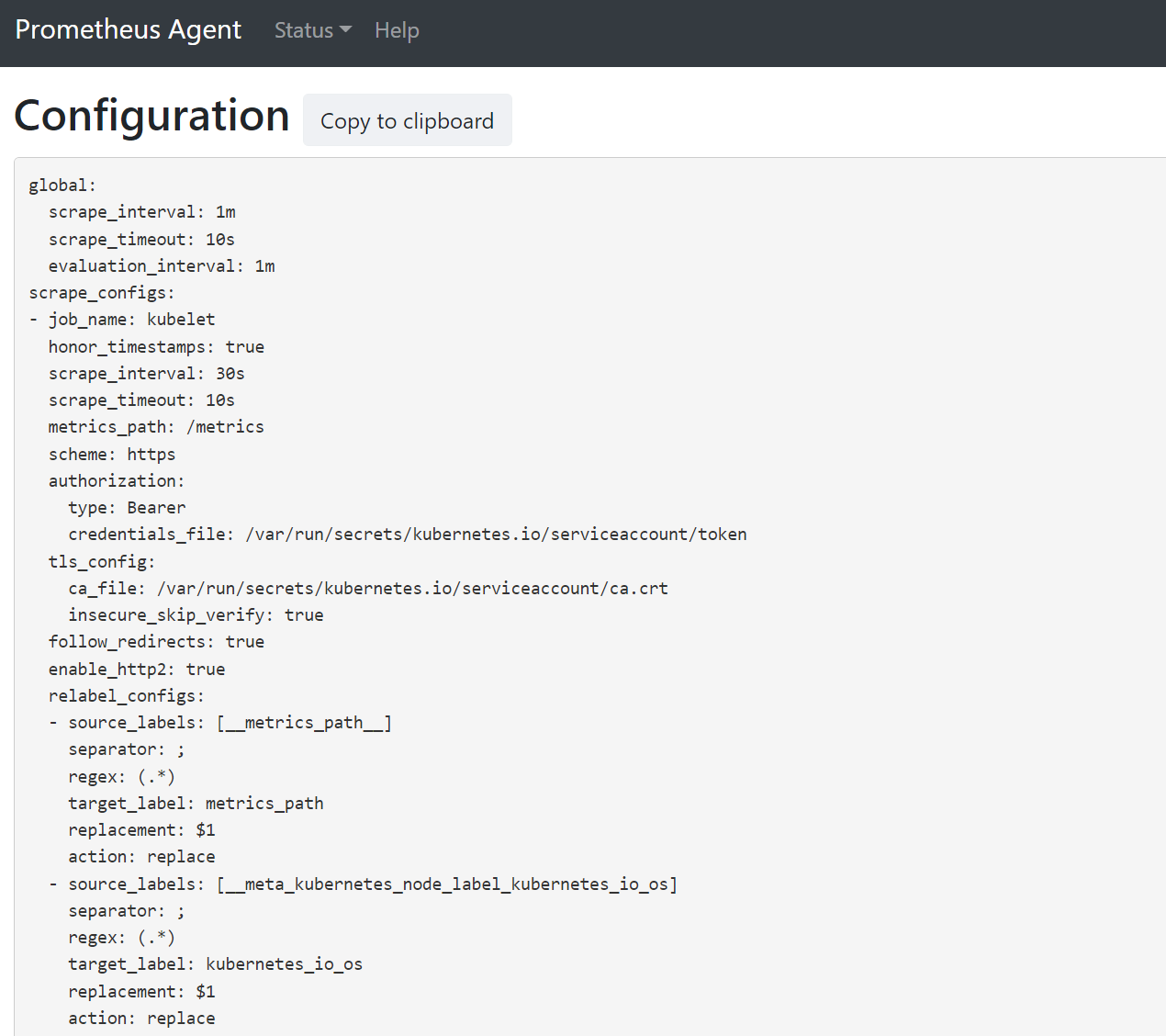
Ga naar de
127.0.0.1:9090/service-discoverydoelen die zijn gedetecteerd door het servicedetectieobject dat is opgegeven en wat de relabel_configs de doelen hebben gefilterd. Als u bijvoorbeeld metrische gegevens van een bepaalde pod mist, kunt u vinden of die pod is gedetecteerd en wat de URI ervan is. Vervolgens kunt u deze URI gebruiken bij het bekijken van de doelen om te zien of er scrapefouten zijn.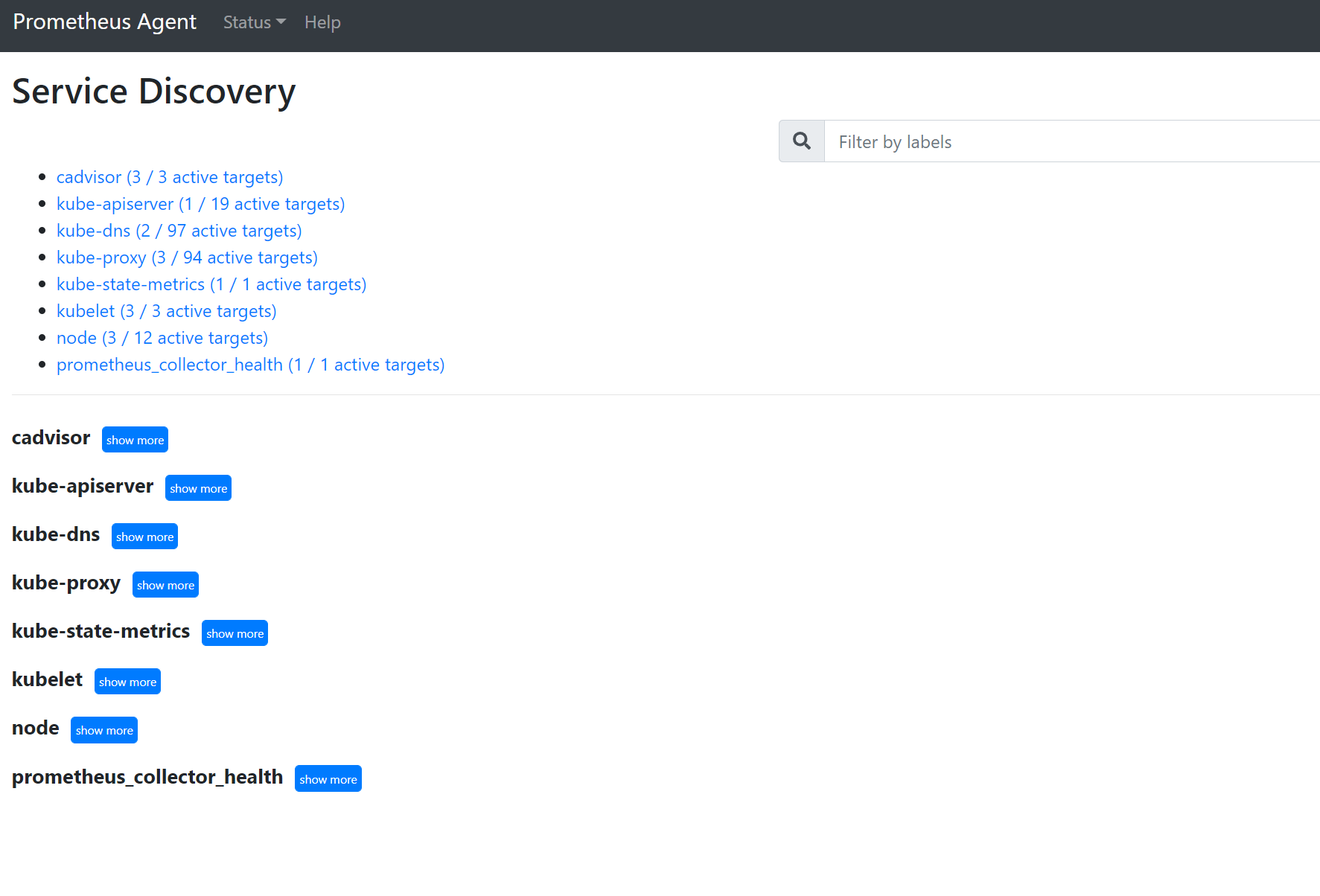
Ga naar
127.0.0.1:9090/targetsalle taken weergeven, de laatste keer dat het eindpunt voor die taak is verwijderd en eventuele fouten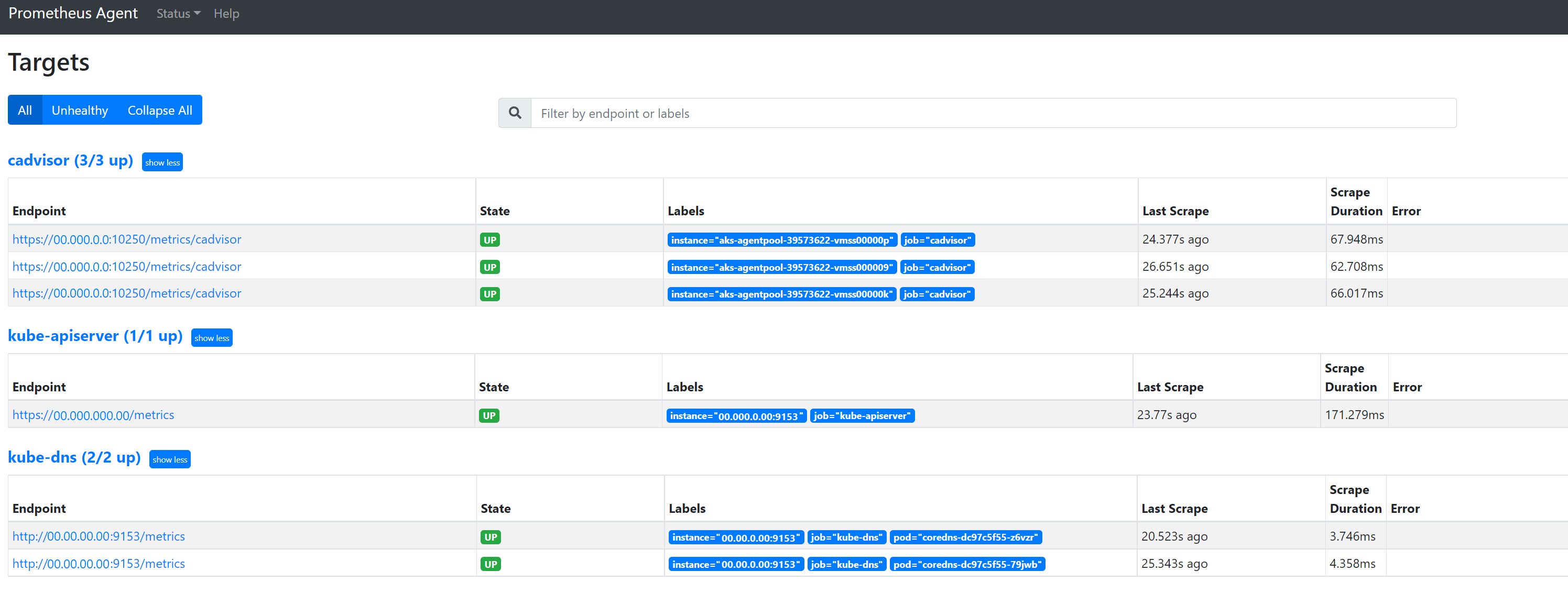



Aangepaste resources
- Als u aangepaste resources hebt opgenomen, controleert u of ze worden weergegeven onder configuratie, servicedetectie en -doelen.
Configuratie

Servicedetectie

Doelen

Als er geen problemen zijn en de beoogde doelen worden geschraapt, kunt u de exacte metrische gegevens bekijken die worden geschraapt door de foutopsporingsmodus in te schakelen.
Foutopsporingsmodus
Waarschuwing
Deze modus kan van invloed zijn op de prestaties en mag alleen korte tijd worden ingeschakeld voor foutopsporing.
De invoegtoepassing voor metrische gegevens kan worden geconfigureerd om te worden uitgevoerd in de foutopsporingsmodus door de instelling enabled van de configmap onder debug-mode te true wijzigen door de instructies hier te volgen.
Wanneer deze optie is ingeschakeld, worden alle prometheus-metrische gegevens die worden gesroot, gehost op poort 9091. Voer de volgende opdracht uit:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Ga naar 127.0.0.1:9091/metrics in een browser om te zien of de metrische gegevens zijn geschraapt door de OpenTelemetry Collector. Deze gebruikersinterface is toegankelijk voor elke ama-metrics-* pod. Als er geen metrische gegevens zijn, kan er een probleem zijn met de lengte van de metrische naam of het aantal labels. Controleer ook of het opnamequotum voor metrische gegevens van Prometheus wordt overschreden, zoals opgegeven in dit artikel.
Metrische namen, labelnamen en labelwaarden
Scraping van metrische gegevens heeft momenteel de beperkingen in de volgende tabel:
| Eigenschappen | Grenswaarde |
|---|---|
| Lengte van labelnaam | Kleiner dan of gelijk aan 511 tekens. Wanneer deze limiet voor een bepaalde tijdreeks in een taak wordt overschreden, mislukt de hele scrapetaak en worden metrische gegevens verwijderd uit die taak voordat ze worden opgenomen. U kunt de reden voor up=0 voor die taak zien en u ziet ook de reden voor up=0. |
| Lengte van labelwaarde | Kleiner dan of gelijk aan 1023 tekens. Wanneer deze limiet voor een bepaalde tijdreeks in een taak wordt overschreden, mislukt de hele scrape en worden metrische gegevens uit die taak verwijderd voordat ze worden opgenomen. U kunt de reden voor up=0 voor die taak zien en u ziet ook de reden voor up=0. |
| Aantal labels per tijdreeks | Kleiner dan of gelijk aan 63. Wanneer deze limiet voor een bepaalde tijdreeks in een taak wordt overschreden, mislukt de hele scrapetaak en worden metrische gegevens verwijderd uit die taak voordat ze worden opgenomen. U kunt de reden voor up=0 voor die taak zien en u ziet ook de reden voor up=0. |
| Lengte van metrische naam | Kleiner dan of gelijk aan 511 tekens. Wanneer deze limiet voor een bepaalde tijdreeks in een taak wordt overschreden, wordt alleen die bepaalde reeks verwijderd. MetricextensionConsoleDebugLog bevat traceringen voor de verwijderde metrische gegevens. |
| Labelnamen met verschillende behuizingen | Twee labels in hetzelfde metrische voorbeeld, waarbij verschillende behuizingen worden behandeld als dubbele labels en worden verwijderd wanneer ze worden opgenomen. De tijdreeks my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} wordt bijvoorbeeld verwijderd vanwege dubbele labels en ExampleLabel examplelabel worden gezien als dezelfde labelnaam. |
Opnamequotum controleren in Azure Monitor-werkruimte
Als u ziet dat metrische gegevens zijn gemist, kunt u eerst controleren of de opnamelimieten worden overschreden voor uw Azure Monitor-werkruimte. In Azure Portal kunt u het huidige gebruik voor elke Azure Monitor-werkruimte controleren. U kunt de huidige metrische gegevens over gebruik bekijken in het Metrics menu voor de Azure Monitor-werkruimte. De volgende metrische gegevens over gebruik zijn beschikbaar als standaardmetrieken voor elke Azure Monitor-werkruimte.
- Actieve tijdreeks: het aantal unieke tijdreeksen dat onlangs is opgenomen in de werkruimte gedurende de afgelopen 12 uur
- Actieve tijdreekslimiet : de limiet voor het aantal unieke tijdreeksen dat actief kan worden opgenomen in de werkruimte
- Gebruik van actieve tijdreekspercentage : het percentage actieve tijdreeksen dat wordt gebruikt
- Opgenomen gebeurtenissen per minuut - Het aantal gebeurtenissen (voorbeelden) per minuut dat onlangs is ontvangen
- Opgenomen limiet voor gebeurtenissen per minuut: het maximum aantal gebeurtenissen per minuut dat kan worden opgenomen voordat de limiet wordt beperkt
- Gebeurtenissen per minuut opgenomen % gebruik: het percentage van de huidige metrische opnamesnelheidslimiet die wordt gebruikt
Als u metrische gegevensopnamebeperking wilt voorkomen, kunt u een waarschuwing voor de opnamelimieten bewaken en instellen. Zie Opnamelimieten monitoren.
Raadpleeg servicequota en -limieten voor standaardquota en om te begrijpen wat er kan worden verhoogd op basis van uw gebruik. U kunt quotumverhoging aanvragen voor Azure Monitor-werkruimten met behulp van het Support Request menu voor de Azure Monitor-werkruimte. Zorg ervoor dat u de id, interne id en locatie/regio voor de Azure Monitor-werkruimte opneemt in de ondersteuningsaanvraag, die u kunt vinden in het menu Eigenschappen voor de Azure Monitor-werkruimte in Azure Portal.
Het maken van de Azure Monitor-werkruimte is mislukt vanwege de Evaluatie van Azure Policy
Als het maken van de Azure Monitor-werkruimte mislukt met de fout 'Resource-name-xyz' is niet toegestaan door beleid, is er mogelijk een Azure-beleid dat verhindert dat de resource wordt gemaakt. Als er een beleid is dat een naamconventie afdwingt voor uw Azure-resources of -resourcegroepen, moet u een uitzondering maken voor de naamconventie voor het maken van een Azure Monitor-werkruimte.
Wanneer u een Azure Monitor-werkruimte maakt, worden standaard een regel voor gegevensverzameling en een eindpunt voor gegevensverzameling in het formulier 'azure-monitor-workspace-name' automatisch gemaakt in een resourcegroep in de vorm 'MA_azure-monitor-workspace-name_location_managed'. Er is momenteel geen manier om de namen van deze resources te wijzigen en u moet een uitzondering voor Azure Policy instellen om de bovenstaande resources uit te schakelen voor beleidsevaluatie. Zie de uitzonderingsstructuur van Azure Policy.