Failover en patching voor Azure Managed Redis (preview)
Voor het bouwen van tolerante en succesvolle clienttoepassingen is het essentieel om inzicht te hebben in failover in de Azure Managed Redis-service (preview). Een failover kan deel uitmaken van geplande beheerbewerkingen of kan worden veroorzaakt door niet-geplande hardware- of netwerkfouten. Een veelvoorkomend gebruik van cachefailover wordt gebruikt wanneer de beheerservice de binaire Azure Managed Redis-bestanden patcht.
In dit artikel vindt u deze informatie:
- Wat is een failover?
- Hoe failover optreedt tijdens het patchen.
- Een tolerante clienttoepassing bouwen.
Wat is een failover?
Laten we beginnen met een overzicht van failover voor Azure Managed Redis.
Een beknopt overzicht van cachearchitectuur
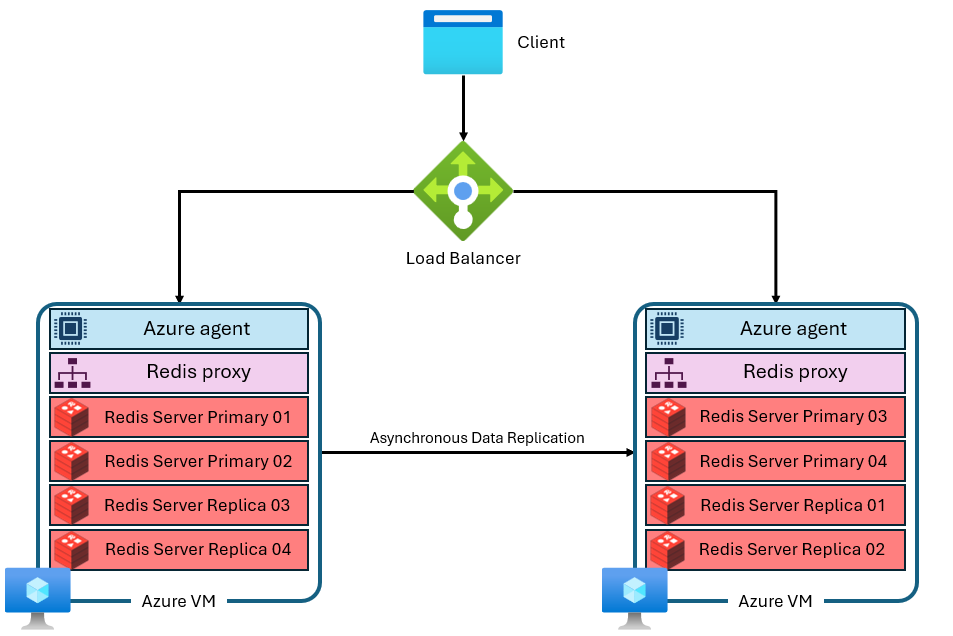
Een cache is samengesteld uit meerdere virtuele machines met afzonderlijke en privé-IP-adressen. Elke virtuele machine (of knooppunt) voert meerdere Redis-serverprocessen (ook wel 'shards' genoemd) parallel uit. Meerdere shards zorgen voor efficiënter gebruik van vCPU's op elke virtuele machine en hogere prestaties. Niet alle primaire Redis-shards bevinden zich op dezelfde VM/hetzelfde knooppunt. In plaats daarvan worden primaire en replica-shards verdeeld over beide knooppunten. Omdat primaire shards meer CPU-resources gebruiken dan replica-shards, kunnen met deze benadering meer primaire shards parallel worden uitgevoerd. Elk knooppunt heeft een proxyproces met hoge prestaties voor het beheren van de shards, het afhandelen van verbindingsbeheer en het activeren van zelfherstel. Een shard is mogelijk niet beschikbaar terwijl de andere beschikbaar blijven.
Gedetailleerde informatie over Azure Managed Redis Architecture vindt u hier.
Uitleg van een failover
Er treedt een failover op wanneer een of meer replicashards zichzelf promoveren tot primaire shards en de oude primaire shards bestaande verbindingen sluiten. Een failover kan gepland of ongepland zijn.
Er vindt een geplande failover plaats gedurende twee verschillende tijden:
- Systeemupdates, zoals Redis-patches of upgrades van het besturingssysteem.
- Beheerbewerkingen, zoals schalen en opnieuw opstarten.
Omdat de knooppunten voorafgaande kennisgeving van de update ontvangen, kunnen ze samen rollen wisselen en de Load Balancer van de wijziging snel bijwerken. Een geplande failover wordt doorgaans binnen 1 seconde voltooid.
Een niet-geplande failover kan optreden vanwege hardwarestoringen, netwerkfouten of andere onverwachte storingen naar een of meer knooppunten in het cluster. De replicashard('s) op de resterende knooppunten bevorderen zichzelf tot primair om de beschikbaarheid te behouden, maar het proces duurt langer. Een replicashard moet eerst detecteren dat de primaire shard niet beschikbaar is voordat het failoverproces kan worden gestart. De replica-shard moet ook verifiëren dat deze niet-geplande fout niet tijdelijk of lokaal is, om onnodige failover te voorkomen. Deze vertraging in de detectie betekent dat een niet-geplande failover doorgaans binnen 10 tot 15 seconden wordt voltooid.
Hoe vindt patching plaats?
De Azure Managed Redis-service werkt uw cache regelmatig bij met de nieuwste platformfuncties en oplossingen. Als u een patch voor een cache wilt uitvoeren, voert de service de volgende stappen uit:
- De service maakt nieuwe up-to-date VM's ter vervanging van alle VM's die worden gepatcht.
- Vervolgens bevordert het een van de nieuwe VM's als de clusterleider.
- Eén voor één worden alle knooppunten die worden gepatcht uit het cluster verwijderd. Alle shards op deze VM's worden gedegradeerd en gemigreerd naar een van de nieuwe VM's.
- Ten slotte worden alle vm's die zijn vervangen, verwijderd.
Elke shard van een geclusterde cache wordt afzonderlijk gepatcht en sluit geen verbindingen met een andere shard.
Meerdere caches in dezelfde resourcegroep en regio worden ook één voor één gepatcht. Caches die zich in verschillende resourcegroepen of verschillende regio's bevinden, kunnen tegelijkertijd worden gepatcht.
Omdat volledige gegevenssynchronisatie plaatsvindt voordat het proces wordt herhaald, is het onwaarschijnlijk dat gegevensverlies plaatsvindt voor uw cache. U kunt gegevensverlies verder beschermen door gegevens te exporteren en persistentie in te schakelen.
Extra cachebelasting
Wanneer een failover plaatsvindt, moeten de caches gegevens van het ene knooppunt naar het andere repliceren. Deze replicatie veroorzaakt een zekere belastingstoename in zowel servergeheugen als CPU. Als het cache-exemplaar al zwaar is beladen, kunnen clienttoepassingen een verhoogde latentie ervaren. In extreme gevallen ontvangen clienttoepassingen mogelijk time-outuitzonderingen.
Wat is de invloed van een failover op mijn clienttoepassing?
Clienttoepassingen kunnen enkele fouten ontvangen van hun Azure Managed Redis-exemplaar. Het aantal fouten voor een clienttoepassing is afhankelijk van het aantal bewerkingen die op het moment van de failover in behandeling waren voor die verbinding. Voor verbindingen die worden gerouteerd door het knooppunt waarop de verbindingen zijn verbroken, treden fouten op.
Veel clientbibliotheken kunnen verschillende typen fouten veroorzaken wanneer verbindingen worden verbroken, waaronder:
- Time-outuitzonderingen
- Verbindingsuitzonderingen
- Socket-uitzonderingen
Het aantal en het type uitzonderingen is afhankelijk van waar de aanvraag zich in het codepad bevindt wanneer de cache de verbindingen sluit. Een bewerking die bijvoorbeeld een aanvraag verzendt, maar geen antwoord heeft ontvangen wanneer de failover optreedt, kan een time-outuitzondering krijgen. Nieuwe aanvragen voor het gesloten verbindingsobject ontvangen verbindingsuitzonderingen totdat de nieuwe verbinding tot stand is gebracht.
De meeste clientbibliotheken proberen opnieuw verbinding te maken met de cache als ze hiervoor zijn geconfigureerd. Onvoorziene fouten kunnen de bibliotheekobjecten echter af en toe in een onherstelbare status plaatsen. Als fouten langer dan een vooraf geconfigureerde tijd blijven bestaan, moet het verbindingsobject opnieuw worden gemaakt. In Microsoft.NET en andere objectgeoriënteerde talen kunt u de verbinding opnieuw maken zonder de toepassing opnieuw te starten met behulp van een ForceReconnect-patroon.
Wat zijn de updates die onder onderhoud zijn opgenomen?
Onderhoud omvat deze updates:
- Redis Server-updates: elke update of patch van de binaire Redis-serverbestanden.
- Updates voor virtuele machines (VM's): alle updates van de virtuele machine die als host fungeert voor de Redis-service. VM-updates omvatten het patchen van softwareonderdelen in de hostingomgeving om netwerkonderdelen te upgraden of uit bedrijf te nemen.
Wordt onderhoud weergegeven in de servicestatus in Azure Portal vóór een patch?
Nee, onderhoud wordt niet weergegeven onder servicestatus in de portal of op een andere plaats.
Wijzigingen in de configuratie van het clientnetwerk
Bepaalde wijzigingen aan de netwerkconfiguratie aan de clientzijde kunnen geen verbindingsfouten veroorzaken. Voorbeelden van dergelijke wijzigingen:
- Het virtuele IP-adres van een clienttoepassing is verwisseld tussen faserings- en productiesites.
- De grootte of het aantal exemplaren van uw toepassing zijn geschaald.
Dergelijke wijzigingen kunnen een verbindingsprobleem veroorzaken dat meestal minder dan één minuut duurt. Uw clienttoepassing verliest waarschijnlijk de verbinding met andere externe netwerkbronnen, maar ook met de Azure Managed Redis-service.
Tolerantie inbouwen
U kunt failovers niet volledig vermijden. Schrijf in plaats daarvan uw clienttoepassingen om bestand te zijn tegen verbindingsonderbrekingen en mislukte aanvragen. De meeste clientbibliotheken maken automatisch opnieuw verbinding met het cache-eindpunt, maar weinigen proberen mislukte aanvragen opnieuw uit te voeren. Afhankelijk van het toepassingsscenario kan het zinvol zijn om logica voor opnieuw proberen met uitstel te gebruiken.
Hoe maak ik mijn toepassing veerkrachtig?
Raadpleeg deze ontwerppatronen om veerkrachtige clients te bouwen, met name de patronen voor circuitonderbreker en opnieuw proberen:
- Betrouwbaarheidspatronen - Cloudontwerppatronen
- Richtlijnen voor opnieuw proberen voor Azure-services - Aanbevolen procedures voor cloudtoepassingen
- Nieuwe pogingen implementeren met exponentieel uitstel