Zelfstudie: Vector similarity search on Azure OpenAI embeddings using Azure Cache voor Redis
In deze zelfstudie doorloopt u een basic vector similarity search use-case. U gebruikt insluitingen die zijn gegenereerd door de Azure OpenAI-service en de ingebouwde vectorzoekmogelijkheden van de Enterprise-laag van Azure Cache voor Redis om een query uit te voeren op een gegevensset met films om de meest relevante overeenkomst te vinden.
De zelfstudie maakt gebruik van de Wikipedia Movie Plots-gegevensset met plotbeschrijvingen van meer dan 35.000 films van Wikipedia over de jaren 1901 tot en met 2017. De gegevensset bevat een plotsamenvatting voor elke film, plus metagegevens zoals het jaar waarop de film werd uitgebracht, de regisseur(s), de hoofdcast en het genre. U volgt de stappen van de zelfstudie om insluitingen te genereren op basis van de samenvatting van de plot en de andere metagegevens te gebruiken om hybride query's uit te voeren.
In deze zelfstudie leert u het volgende:
- Een Azure Cache voor Redis-exemplaar maken dat is geconfigureerd voor vectorzoekopdrachten
- Installeer Azure OpenAI en andere vereiste Python-bibliotheken.
- Download de filmgegevensset en bereid deze voor op analyse.
- Gebruik het model text-embedding-ada-002 (versie 2) om insluitingen te genereren.
- Een vectorindex maken in Azure Cache voor Redis
- Gebruik cosinus-gelijkenis om zoekresultaten te rangschikken.
- Gebruik hybride queryfunctionaliteit via RediSearch om de gegevens vooraf te filteren en de vectorzoekopdrachten nog krachtiger te maken.
Belangrijk
In deze zelfstudie leert u hoe u een Jupyter Notebook bouwt. U kunt deze zelfstudie volgen met een Python-codebestand (.py) en vergelijkbare resultaten krijgen, maar u moet alle codeblokken in deze zelfstudie toevoegen aan het .py bestand en één keer uitvoeren om resultaten te zien. Met andere woorden, Jupyter Notebooks biedt tussenliggende resultaten wanneer u cellen uitvoert, maar dit is geen gedrag dat u kunt verwachten wanneer u in een Python-codebestand werkt.
Belangrijk
Als u in plaats daarvan wilt volgen in een voltooid Jupyter-notebook, downloadt u het Jupyter-notebookbestand met de naam tutorial.ipynb en slaat u het op in de nieuwe redis-vectormap.
Vereisten
- Een Azure-abonnement - Een gratis abonnement maken
- Toegang verleend tot Azure OpenAI in het gewenste Azure abonnement. Op dit moment moet u toegang tot Azure OpenAI aanvragen. U kunt toegang tot Azure OpenAI aanvragen door het formulier in te vullen op https://aka.ms/oai/access.
- Python 3.8 of nieuwere versie
- Jupyter Notebooks (optioneel)
- Een Azure OpenAI-resource met het geïmplementeerde model text-embedding-ada-002 (versie 2 ). Dit model is momenteel alleen beschikbaar in bepaalde regio's. Zie de handleiding voor resource-implementatie voor instructies over het implementeren van het model.
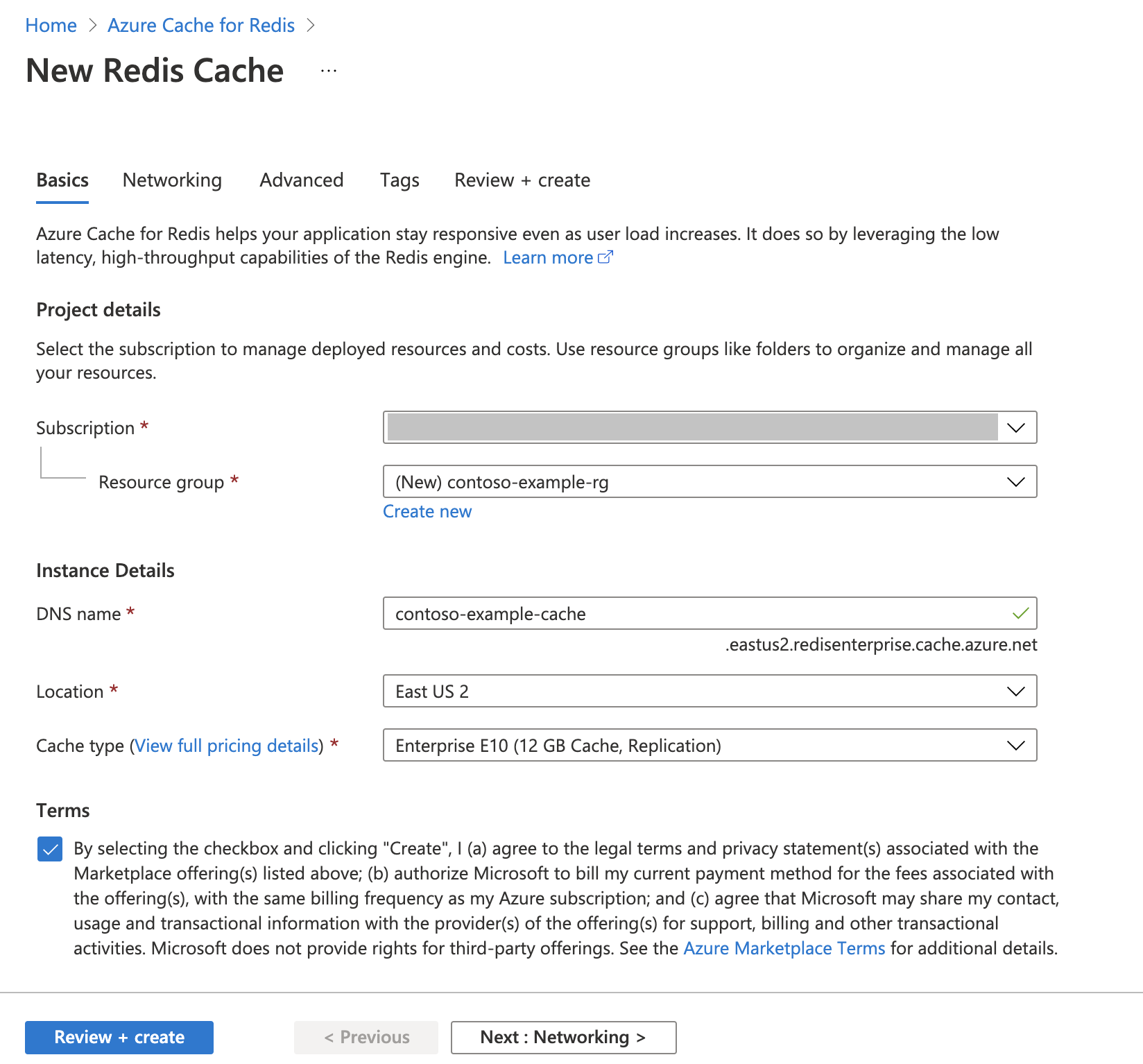
Een Azure Cache voor Redis-exemplaar maken
Volg de quickstart: Een Redis Enterprise-cachehandleiding maken. Controleer op de pagina Geavanceerd of u de RediSearch-module hebt toegevoegd en het enterpriseclusterbeleid hebt gekozen. Alle andere instellingen kunnen overeenkomen met de standaardinstelling die in de quickstart wordt beschreven.
Het duurt enkele minuten voordat de cache is gemaakt. U kunt ondertussen verdergaan met de volgende stap.
De ontwikkelomgeving instellen
Maak een map op uw lokale computer met de naam redis-vector op de locatie waar u uw projecten meestal opslaat.
Maak een nieuw Python-bestand (tutorial.py) of Jupyter Notebook (tutorial.ipynb) in de map.
Installeer de vereiste Python-pakketten:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
De gegevensset downloaden
Navigeer in een webbrowser naar https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Meld u aan of registreer u bij Kaggle. Registratie is vereist om het bestand te downloaden.
Selecteer de koppeling Downloaden op Kaggle om het archive.zip-bestand te downloaden.
Pak het archive.zip-bestand uit en verplaats de wiki_movie_plots_deduped.csv naar de map redis-vector .
Bibliotheken importeren en verbindingsgegevens instellen
Als u azure OpenAI wilt aanroepen, hebt u een eindpunt en een sleutel nodig. U hebt ook een eindpunt en een sleutel nodig om verbinding te maken met Azure Cache voor Redis.
Ga naar uw Azure OpenAI-resource in Azure Portal.
Zoek eindpunt en sleutels in de sectie Resourcebeheer . Kopieer uw eindpunt en toegangssleutel, omdat u beide nodig hebt voor het verifiëren van uw API-aanroepen. Een voorbeeldeindpunt is:
https://docs-test-001.openai.azure.com. U kuntKEY1ofKEY2gebruiken.Ga naar de pagina Overzicht van uw Azure Cache voor Redis resource in Azure Portal. Kopieer uw eindpunt.
Zoek toegangssleutels in de sectie Instellingen . Kopieer uw toegangssleutel. U kunt
PrimaryofSecondarygebruiken.Voeg de volgende code toe aan een nieuwe codecel:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Werk de waarde van
API_KEYenRESOURCE_ENDPOINTmet de sleutel- en eindpuntwaarden van uw Azure OpenAI-implementatie bij.DEPLOYMENT_NAMEmoet worden ingesteld op de naam van uw implementatie met behulp van hettext-embedding-ada-002 (Version 2)insluitingsmodel enMODEL_NAMEmoet het specifieke insluitingsmodel zijn dat wordt gebruikt.Werk
REDIS_ENDPOINTen met het eindpunt enREDIS_PASSWORDde sleutelwaarde van uw Azure Cache voor Redis exemplaar bij.Belangrijk
We raden u ten zeerste aan om omgevingsvariabelen of een geheimbeheerder zoals Azure Key Vault te gebruiken om de api-sleutel, het eindpunt en de implementatienaamgegevens door te geven. Deze variabelen worden hier ter vereenvoudiging in tekst zonder opmaak ingesteld.
Codecel 2 uitvoeren.
Gegevensset importeren in pandas en gegevens verwerken
Vervolgens leest u het CSV-bestand in een Pandas DataFrame.
Voeg de volgende code toe aan een nieuwe codecel:
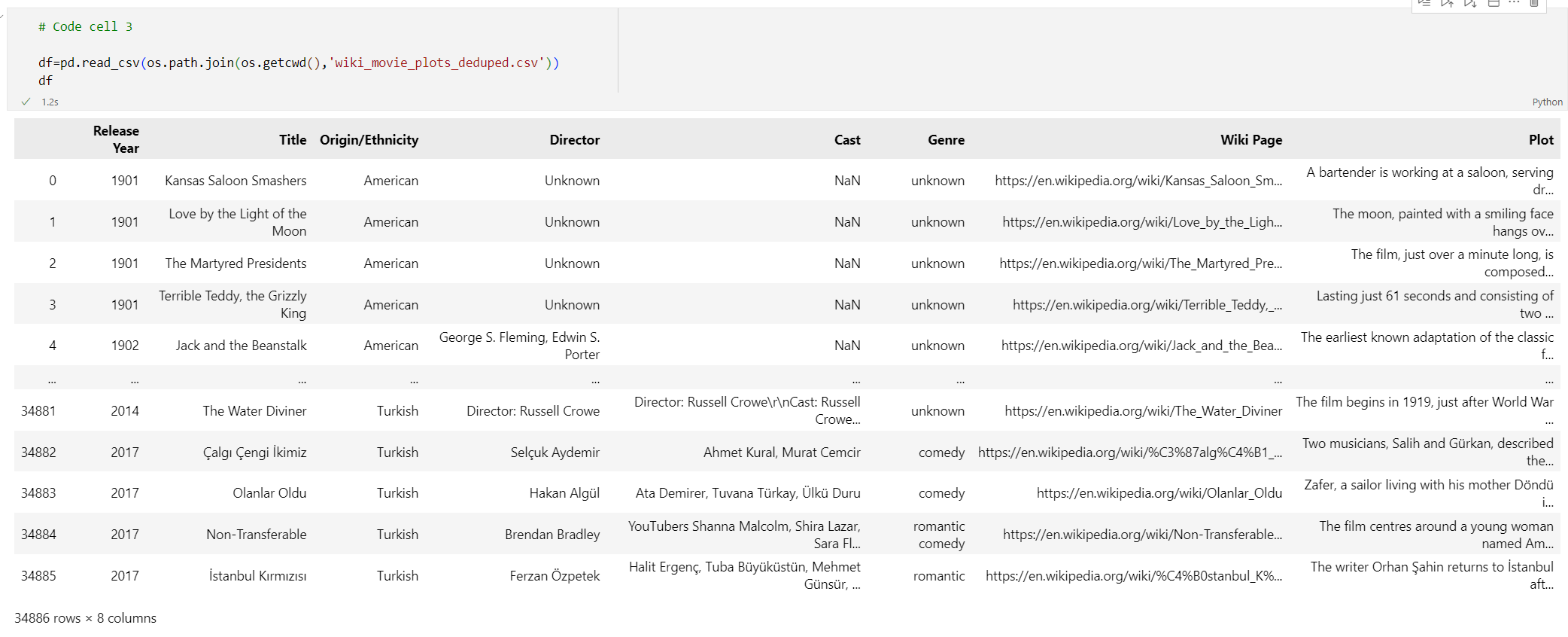
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfVoer codecel 3 uit. U moet de volgende uitvoer zien:
Vervolgens verwerkt u de gegevens door een
idindex toe te voegen, spaties uit de kolomtitels te verwijderen en filtert u de films om alleen films te nemen die na 1970 en uit Engelstalige landen of regio's zijn gemaakt. Deze filterstap vermindert het aantal films in de gegevensset, waardoor de kosten en tijd die nodig zijn voor het genereren van insluitingen verlaagt. U kunt de filterparameters wijzigen of verwijderen op basis van uw voorkeuren.Als u de gegevens wilt filteren, voegt u de volgende code toe aan een nieuwe codecel:
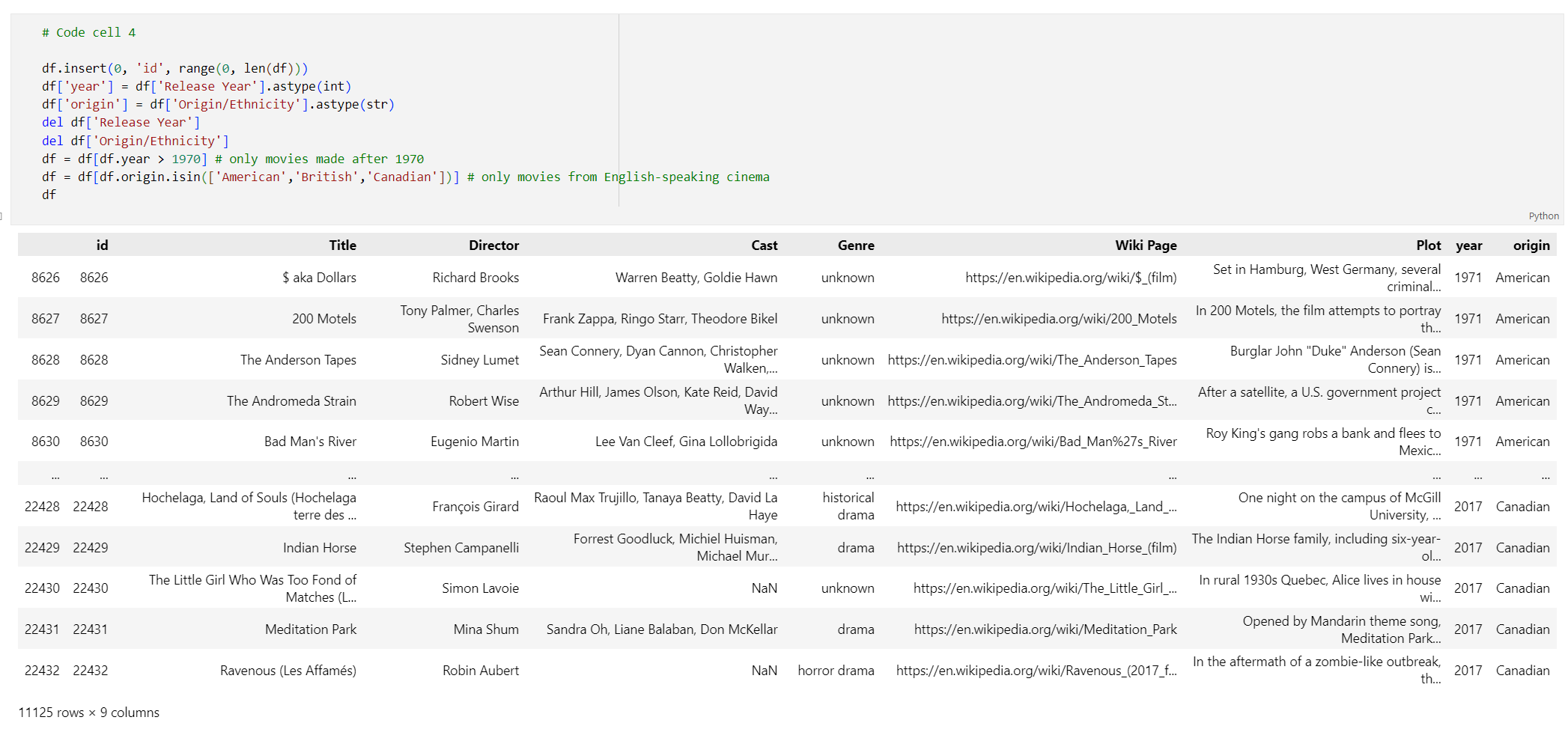
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfVoer codecel 4 uit. De volgende resultaten wordt weergegeven.
Maak een functie om de gegevens op te schonen door witruimte en interpunctie te verwijderen en gebruik deze vervolgens tegen het gegevensframe dat de plot bevat.
Voeg de volgende code toe aan een nieuwe codecel en voer deze uit:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Verwijder tot slot alle vermeldingen die plotbeschrijvingen bevatten die te lang zijn voor het insluitingsmodel. (Met andere woorden, ze vereisen meer tokens dan de limiet van 8192 token.) en berekent u vervolgens het aantal tokens dat is vereist voor het genereren van insluitingen. Dit is ook van invloed op de prijzen voor het genereren van insluitingen.
Voeg de volgende code toe aan een nieuwe codecel:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Codecel 6 uitvoeren. De uitvoer moet er ongeveer als volgt uitzien:
Number of movies: 11125 Number of tokens required:7044844Belangrijk
Raadpleeg prijzen voor Azure OpenAI Service om de kosten voor het genereren van insluitingen te berekenen op basis van het aantal vereiste tokens.


DataFrame laden in LangChain
Laad het DataFrame in LangChain met behulp van de DataFrameLoader klasse. Zodra de gegevens zich in LangChain-documenten bevinden, is het veel eenvoudiger om LangChain-bibliotheken te gebruiken om insluitingen te genereren en overeenkomsten te zoeken. Stel Plot in als zodanig page_content_column dat insluitingen in deze kolom worden gegenereerd.
Voeg de volgende code toe aan een nieuwe codecel en voer deze uit:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Insluitingen genereren en laden in Redis
Nu de gegevens zijn gefilterd en geladen in LangChain, maakt u insluitingen zodat u een query kunt uitvoeren op de plot voor elke film. De volgende code configureert Azure OpenAI, genereert insluitingen en laadt de insluitingsvectoren in Azure Cache voor Redis.
Voeg de volgende code toe aan een nieuwe codecel:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Voer codecel 8 uit. Dit kan meer dan 30 minuten duren. Er wordt ook een
redis_schema.yamlbestand gegenereerd. Dit bestand is handig als u verbinding wilt maken met uw index in Azure Cache voor Redis exemplaar zonder dat u insluitingen opnieuw hoeft te genereren.
Belangrijk
De snelheid waarmee insluitingen worden gegenereerd, is afhankelijk van het quotum dat beschikbaar is voor het Azure OpenAI-model. Met een quotum van 240.000 tokens per minuut duurt het ongeveer 30 minuten om de 7M-tokens in de gegevensset te verwerken.
Vectorzoekquery's uitvoeren
Nu uw gegevensset, de Azure OpenAI-service-API en het Redis-exemplaar zijn ingesteld, kunt u zoeken met behulp van vectoren. In dit voorbeeld worden de tien belangrijkste resultaten voor een bepaalde query geretourneerd.
Voeg de volgende code toe aan uw Python-codebestand:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Voer codecel 9 uit. U moet de volgende uitvoer zien:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)De overeenkomstscore wordt geretourneerd samen met de rangorde van films op gelijkenis. U ziet dat specifiekere query's overeenkomstenscores hebben die sneller omlaag in de lijst afnemen.
Hybride zoekopdrachten
Aangezien RediSearch ook beschikt over uitgebreide zoekfunctionaliteit bovenop vectorzoekopdrachten, is het mogelijk om resultaten te filteren op de metagegevens in de gegevensset, zoals filmgenre, cast, releasejaar of regisseur. In dit geval filtert u op basis van het genre
comedy.Voeg de volgende code toe aan een nieuwe codecel:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Voer codecel 10 uit. U moet de volgende uitvoer zien:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Met Azure Cache voor Redis en Azure OpenAI Service kunt u insluitingen en vectorzoekopdrachten gebruiken om krachtige zoekmogelijkheden toe te voegen aan uw toepassing.
Resources opschonen
Als u de resources wilt blijven gebruiken die u in dit artikel hebt gemaakt, moet u de resourcegroep behouden.
Als u klaar bent met de resources, kunt u de Azure-resourcegroep verwijderen die u hebt gemaakt om kosten te voorkomen.
Belangrijk
Het verwijderen van een resourcegroep kan niet ongedaan worden gemaakt. Wanneer u een resourcegroep verwijdert, worden alle resources in de groep definitief verwijderd. Zorg ervoor dat u niet per ongeluk de verkeerde resourcegroep of resources verwijdert. Als u de resources in een bestaande resourcegroep hebt gemaakt die resources bevat die u wilt behouden, kunt u elke resource afzonderlijk verwijderen in plaats van de resourcegroep te verwijderen.
Een resourcegroep verwijderen
Meld u aan bij Azure Portal en selecteer vervolgens Resourcegroepen.
Selecteer de resourcegroep die u wilt verwijderen.
Als er veel resourcegroepen zijn, gebruikt u het vak Filter voor een veld... en typt u de naam van de resourcegroep die u voor dit artikel hebt gemaakt. Selecteer de resourcegroep in de lijst met resultaten.
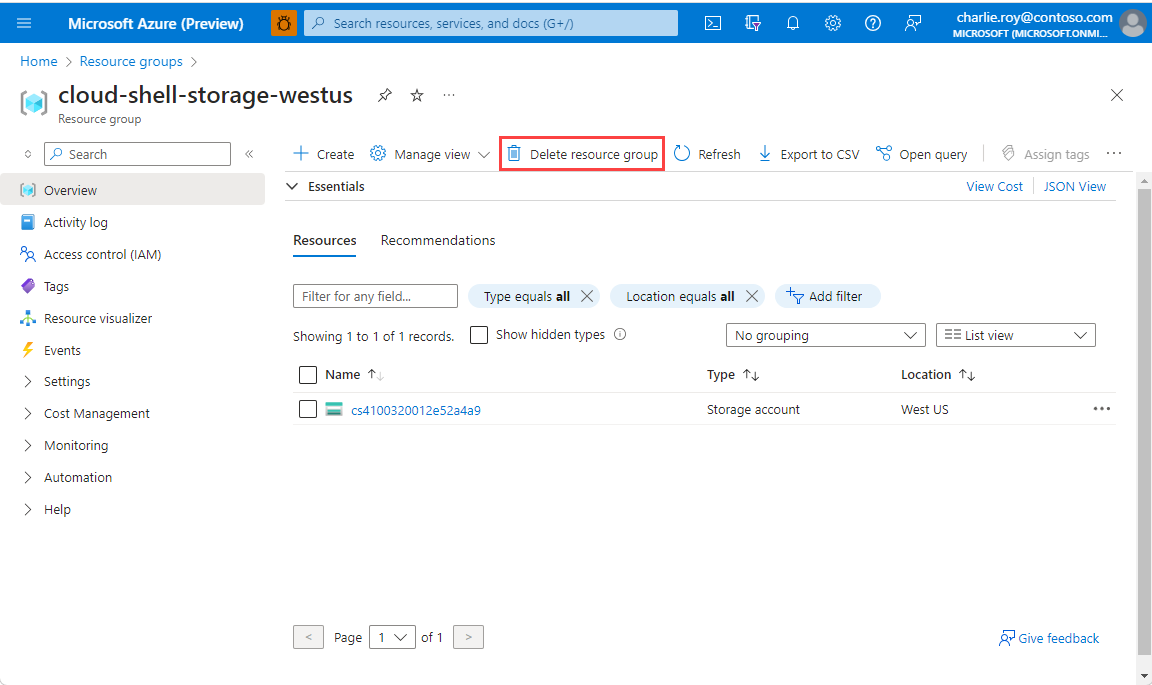
Selecteer Resourcegroep verwijderen.
U wordt gevraagd om het verwijderen van de resourcegroep te bevestigen. Typ ter bevestiging de naam van de resourcegroep. Selecteer vervolgens Verwijderen.
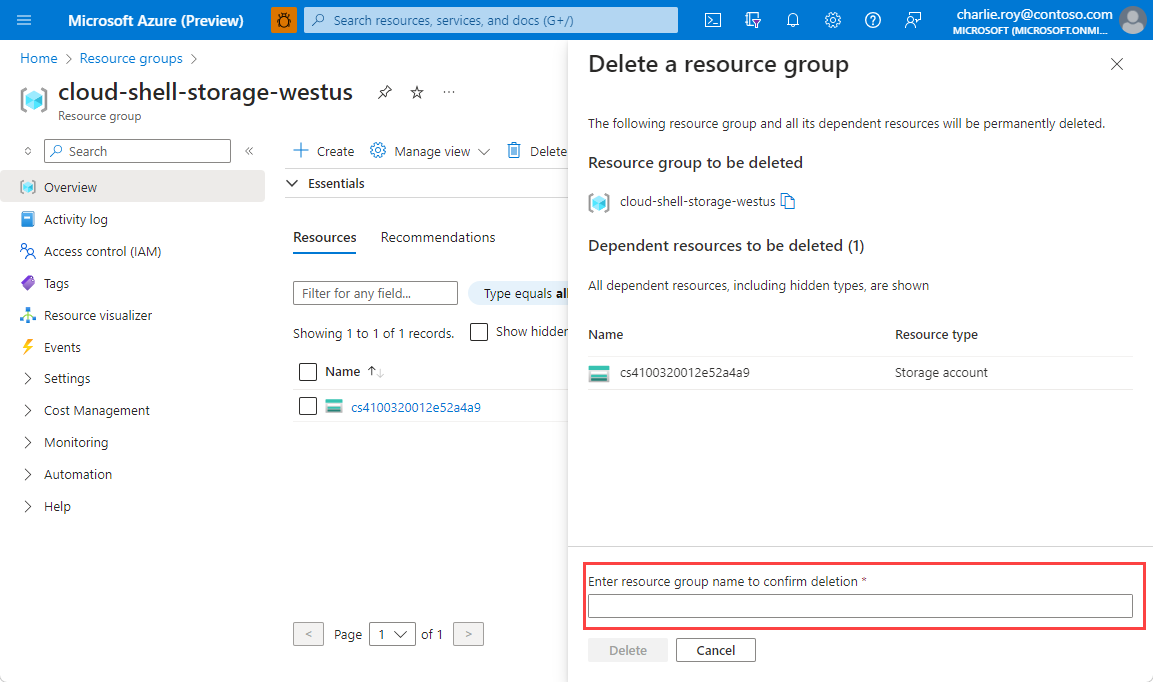
Na enkele ogenblikken worden de resourcegroep en alle bijbehorende resources verwijderd.
Gerelateerde inhoud
- Meer informatie over Azure Cache voor Redis
- Meer informatie over Azure Cache voor Redis vectorzoekmogelijkheden
- Meer informatie over insluitingen die zijn gegenereerd door de Azure OpenAI-service
- Meer informatie over cosinus-gelijkenis
- Lees hoe u een ai-app bouwt met OpenAI en Redis
- Een Q&A-app bouwen met semantische antwoorden