Gegevens verplaatsen naar het vFXT-cluster - Parallelle gegevensopname
Nadat u een nieuw vFXT-cluster hebt gemaakt, is het mogelijk dat uw eerste taak bestaat uit het verplaatsen van gegevens naar een nieuw opslagvolume in Azure. Als uw gebruikelijke methode voor het verplaatsen van gegevens echter een eenvoudige kopieeropdracht van één client uitgeeft, ziet u waarschijnlijk een trage kopieerprestaties. Kopiëren met één thread is geen goede optie voor het kopiëren van gegevens naar de back-endopslag van het Avere vFXT-cluster.
Omdat het Avere vFXT for Azure-cluster een schaalbare cache met meerdere clients is, is de snelste en meest efficiënte manier om gegevens naar het cluster te kopiëren met meerdere clients. Deze techniek parallelliseert de opname van de bestanden en objecten.
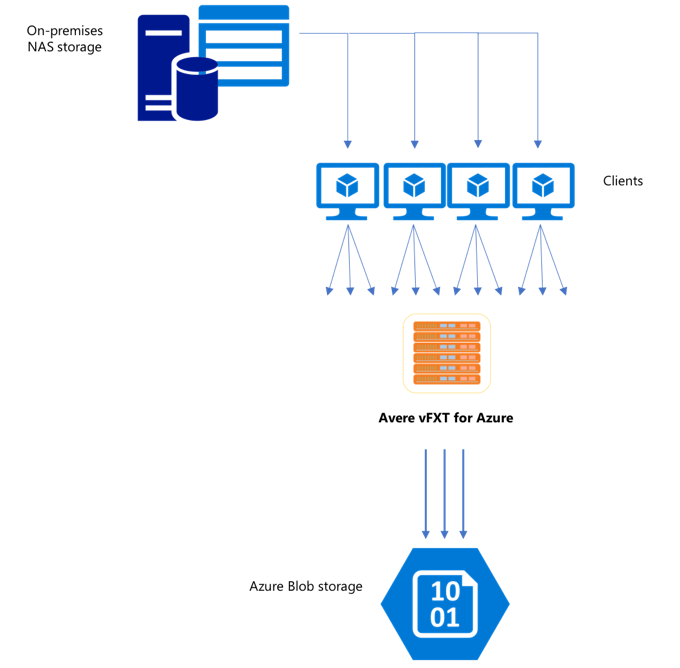
De cp of copy opdrachten die vaak worden gebruikt voor het overdragen van gegevens van het ene opslagsysteem naar het andere, zijn processen met één thread die slechts één bestand tegelijk kopiëren. Dit betekent dat de bestandsserver slechts één bestand tegelijk opneemt. Dit is een verspilling van de resources van het cluster.
In dit artikel worden strategieën beschreven voor het maken van een bestand met meerdere threads met meerdere threads om gegevens naar het Avere vFXT-cluster te verplaatsen. Hierin worden concepten en beslissingspunten voor bestandsoverdracht uitgelegd die kunnen worden gebruikt voor het efficiënt kopiëren van gegevens met behulp van meerdere clients en eenvoudige kopieeropdrachten.
Er worden ook enkele hulpprogramma's uitgelegd die u kunnen helpen. Het msrsync hulpprogramma kan worden gebruikt om het proces van het verdelen van een gegevensset gedeeltelijk te automatiseren in buckets en opdrachten te gebruiken rsync . Het parallelcp script is een ander hulpprogramma waarmee de bronmap wordt gelezen en kopieeropdrachten automatisch worden gelezen. rsync Het hulpprogramma kan ook in twee fasen worden gebruikt om een snellere kopie te bieden die nog steeds gegevensconsistentie biedt.
Klik op de koppeling om naar een sectie te gaan:
- Voorbeeld van handmatig kopiëren - Een grondige uitleg met behulp van kopieeropdrachten
- Voorbeeld van rsync in twee fasen
- Voorbeeld van gedeeltelijk geautomatiseerd (msrsync)
- Voorbeeld van parallelle kopie
Gegevens ingestor VM-sjabloon
Er is een Resource Manager-sjabloon beschikbaar op GitHub om automatisch een virtuele machine te maken met de parallelle hulpprogramma's voor gegevensopname die in dit artikel worden genoemd.
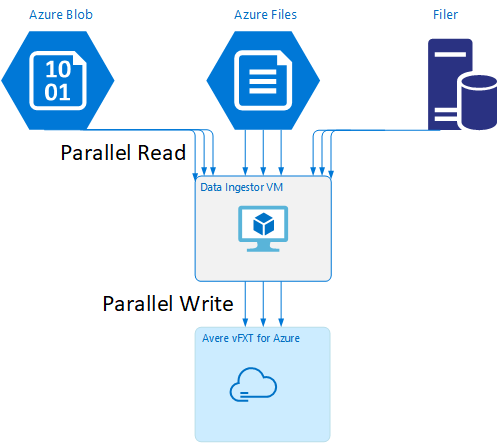
De gegevens ingestor-VM maakt deel uit van een zelfstudie waarin de zojuist gemaakte VM het Avere vFXT-cluster koppelt en het bootstrapscript van het cluster downloadt. Lees Bootstrap voor een data ingestor-VM voor meer informatie.
Strategische planning
Wanneer u een strategie ontwerpt om gegevens parallel te kopiëren, moet u de afwegingen in bestandsgrootte, het aantal bestanden en de mapdiepte begrijpen.
- Wanneer bestanden klein zijn, is de metrische waarde van belang bestanden per seconde.
- Wanneer bestanden groot zijn (10MiBi of hoger), is de metrische waarde bytes per seconde.
Elk kopieerproces heeft een doorvoersnelheid en een door bestanden overgedragen snelheid, die kan worden gemeten door de lengte van de kopieeropdracht te bepalen en rekening te houden met de bestandsgrootte en het aantal bestanden. Uitleg over het meten van de tarieven valt buiten het bereik van dit document, maar het is belangrijk om te begrijpen of u met kleine of grote bestanden te maken krijgt.
Voorbeeld van handmatig kopiëren
U kunt handmatig een kopie met meerdere threads op een client maken door meer dan één kopieeropdracht tegelijk uit te voeren op de achtergrond tegen vooraf gedefinieerde sets bestanden of paden.
De Linux-/UNIX-opdracht cp bevat het argument -p voor het behouden van eigendom en mtime-metagegevens. Het toevoegen van dit argument aan de onderstaande opdrachten is optioneel. (Door het argument toe te voegen, wordt het aantal aanroepen van het bestandssysteem dat van de client naar het doelbestandssysteem wordt verzonden, verhoogd voor het wijzigen van metagegevens.)
In dit eenvoudige voorbeeld worden twee bestanden parallel gekopieerd:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Nadat u deze opdracht hebt uitgegeven, ziet u jobs dat er twee threads worden uitgevoerd.
Voorspelbare bestandsstructuur
Als uw bestandsnamen voorspelbaar zijn, kunt u expressies gebruiken om parallelle kopieerthreads te maken.
Als uw map bijvoorbeeld 1000 bestanden bevat die opeenvolgend zijn genummerd, 0001 1000kunt u de volgende expressies gebruiken om tien parallelle threads te maken die elk 100 bestanden kopiëren:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Onbekende bestandsnaamstructuur
Als uw structuur voor bestandsnamen niet voorspelbaar is, kunt u bestanden groeperen op mapnamen.
In dit voorbeeld worden volledige mappen verzameld die moeten worden verzonden naar cp opdrachten die als achtergrondtaken worden uitgevoerd:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Nadat de bestanden zijn verzameld, kunt u parallelle kopieeropdrachten uitvoeren om de submappen en alle bijbehorende inhoud recursief te kopiëren:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Wanneer koppelpunten toevoegen
Nadat u voldoende parallelle threads hebt tegen één koppelpunt voor het bestandssysteem van één doel, is er een punt waar het toevoegen van meer threads geen meer doorvoer geeft. (De doorvoer wordt gemeten in bestanden/seconde of bytes per seconde, afhankelijk van uw type gegevens.) Of erger, overthreading kan soms leiden tot een afname van de doorvoer.
Als dit gebeurt, kunt u koppelpunten aan de clientzijde toevoegen aan andere IP-adressen van het vFXT-cluster, met behulp van hetzelfde pad voor koppelen van externe bestandssysteem:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Door koppelpunten aan de clientzijde toe te voegen, kunt u extra kopieeropdrachten naar de extra /mnt/destination[1-3] koppelpunten afsplitsen, waardoor verdere parallelle uitvoering wordt bereikt.
Als uw bestanden bijvoorbeeld erg groot zijn, kunt u de kopieeropdrachten definiëren voor het gebruik van afzonderlijke doelpaden, waarbij u meer opdrachten parallel verzendt vanaf de client die de kopie uitvoert.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
In het bovenstaande voorbeeld worden alle drie de doelkoppelingspunten gericht op de kopieerprocessen van het clientbestand.
Wanneer clients toevoegen
Als u tot slot de mogelijkheden van de client hebt bereikt, levert het toevoegen van meer kopieerthreads of extra koppelpunten geen extra bestanden per seconde of bytes per seconde op. In dat geval kunt u een andere client implementeren met dezelfde set koppelpunten waarop eigen sets bestandskopieprocessen worden uitgevoerd.
Voorbeeld:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Bestandsmanifesten maken
Nadat u de bovenstaande benaderingen (meerdere copy-threads per bestemming, meerdere bestemmingen per client, meerdere clients per netwerk toegankelijk bronbestandssysteem) hebt begrepen, kunt u deze aanbeveling overwegen: bestandsmanifesten bouwen en deze vervolgens gebruiken met kopieeropdrachten voor meerdere clients.
In dit scenario wordt de UNIX-opdracht find gebruikt om manifesten van bestanden of mappen te maken:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Dit resultaat omleiden naar een bestand: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Vervolgens kunt u het manifest doorlopen met behulp van BASH-opdrachten om bestanden te tellen en de grootte van de submappen te bepalen:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Ten slotte moet u de daadwerkelijke opdrachten voor het kopiëren van bestanden naar de clients maken.
Als u vier clients hebt, gebruikt u deze opdracht:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Als u vijf clients hebt, gebruikt u ongeveer als volgt:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
En voor zes.... Extrapoleer indien nodig.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
U krijgt N resulterende bestanden, één voor elk van uw N-clients met de padnamen naar de niveau-vier mappen die zijn verkregen als onderdeel van de uitvoer van de find opdracht.
Gebruik elk bestand om de kopieeropdracht te bouwen:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Het bovenstaande geeft u N-bestanden , elk met een kopieeropdracht per regel, die kunnen worden uitgevoerd als een BASH-script op de client.
Het doel is om meerdere threads van deze scripts gelijktijdig per client parallel uit te voeren op meerdere clients.
Een rsync-proces in twee fasen gebruiken
Het standaardhulpprogramma rsync werkt niet goed voor het vullen van cloudopslag via het Avere vFXT for Azure-systeem, omdat er een groot aantal bewerkingen voor het maken en hernoemen van bestanden wordt gegenereerd om gegevensintegriteit te garanderen. U kunt de --inplace optie rsync echter veilig gebruiken om de meer zorgvuldige kopieerprocedure over te slaan als u dat volgt met een tweede uitvoering die de bestandsintegriteit controleert.
Met een standaard rsync kopieerbewerking wordt een tijdelijk bestand gemaakt en gevuld met gegevens. Als de gegevensoverdracht is voltooid, wordt de naam van het tijdelijke bestand gewijzigd in de oorspronkelijke bestandsnaam. Deze methode garandeert consistentie, zelfs als de bestanden tijdens het kopiëren worden geopend. Met deze methode worden echter meer schrijfbewerkingen gegenereerd, waardoor de bestandsverplaatsing door de cache wordt vertraagd.
Met de optie --inplace wordt het nieuwe bestand rechtstreeks op de uiteindelijke locatie geschreven. Bestanden zijn niet gegarandeerd consistent tijdens de overdracht, maar dat is niet belangrijk als u een opslagsysteem voor later gebruik aan het voorbereiden bent.
De tweede rsync bewerking fungeert als een consistentiecontrole voor de eerste bewerking. Omdat de bestanden al zijn gekopieerd, is de tweede fase een snelle scan om ervoor te zorgen dat de bestanden op de bestemming overeenkomen met de bestanden op de bron. Als bestanden niet overeenkomen, worden ze opnieuw gecopieerd.
U kunt beide fasen samen in één opdracht uitgeven:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Deze methode is een eenvoudige en tijd effectieve methode voor gegevenssets tot het aantal bestanden dat de interne mapbeheerder kan verwerken. (Dit zijn doorgaans 200 miljoen bestanden voor een cluster met 3 knooppunten, 500 miljoen bestanden voor een cluster met zes knooppunten, enzovoort.)
Het hulpprogramma msrsync gebruiken
Het msrsync hulpprogramma kan ook worden gebruikt om gegevens te verplaatsen naar een back-endkern-filer voor het Avere-cluster. Dit hulpprogramma is ontworpen om het bandbreedtegebruik te optimaliseren door meerdere parallelle rsync processen uit te voeren. Het is beschikbaar via GitHub op https://github.com/jbd/msrsync.
msrsync breekt de bronmap op in afzonderlijke buckets en voert vervolgens afzonderlijke rsync processen uit op elke bucket.
Voorlopige tests met behulp van een VM met vier kernen toonden de beste efficiëntie bij het gebruik van 64 processen. Gebruik de msrsync optie -p om het aantal processen in te stellen op 64.
U kunt het --inplace argument ook gebruiken met msrsync opdrachten. Als u deze optie gebruikt, kunt u overwegen om een tweede opdracht uit te voeren (zoals bij rsync, hierboven beschreven) om de gegevensintegriteit te waarborgen.
msrsync kan alleen schrijven naar en van lokale volumes. De bron en het doel moeten toegankelijk zijn als lokale koppeling in het virtuele netwerk van het cluster.
Als u een Azure-cloudvolume wilt vullen msrsync met een Avere-cluster, volgt u deze instructies:
Installeren
msrsyncen de bijbehorende vereisten (rsync en Python 2.6 of hoger)Bepaal het totale aantal bestanden en mappen dat moet worden gekopieerd.
Gebruik bijvoorbeeld het hulpprogramma
prime.pyAvere met argumentenprime.py --directory /path/to/some/directory(beschikbaar door url https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.pyte downloaden).Als u dit niet gebruikt
prime.py, kunt u het aantal items als volgt berekenen met het GNU-hulpprogrammafind:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Deel het aantal items door 64 om het aantal items per proces te bepalen. Gebruik dit nummer met de
-foptie om de grootte van de buckets in te stellen wanneer u de opdracht uitvoert.Geef de
msrsyncopdracht om bestanden te kopiëren:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Als u deze optie gebruikt
--inplace, voegt u een tweede uitvoering toe zonder de optie om te controleren of de gegevens correct zijn gekopieerd:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Deze opdracht is bijvoorbeeld ontworpen voor het verplaatsen van 11.000 bestanden in 64 processen van /test/source-repository naar /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Het script voor parallel kopiëren gebruiken
Het parallelcp script kan ook handig zijn voor het verplaatsen van gegevens naar de back-endopslag van uw vFXT-cluster.
Met het onderstaande script wordt het uitvoerbare bestand parallelcptoegevoegd. (Dit script is ontworpen voor Ubuntu. Als u een andere distributie gebruikt, moet u afzonderlijk installeren parallel .)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Voorbeeld van parallelle kopie
In dit voorbeeld wordt het parallelle kopieerscript gebruikt om te compileren glibc met behulp van bronbestanden uit het Avere-cluster.
De bronbestanden worden opgeslagen op het koppelpunt van het Avere-cluster en de objectbestanden worden opgeslagen op de lokale harde schijf.
Dit script maakt gebruik van het bovenstaande parallelle kopieerscript. De optie -j wordt gebruikt met parallelcp en make om parallellisatie te krijgen.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j