Implementatie en testen voor bedrijfskritieke workloads in Azure
De implementatie en het testen van de bedrijfskritieke omgeving is een cruciaal onderdeel van de algehele referentiearchitectuur. De afzonderlijke toepassingsstempels worden geïmplementeerd met infrastructuur als code uit een opslagplaats voor broncode. Updates voor de infrastructuur en de toepassing bovenaan moeten worden geïmplementeerd zonder downtime voor de toepassing. Een DevOps-pijplijn voor continue integratie wordt aanbevolen om de broncode op te halen uit de opslagplaats en de afzonderlijke stempels in Azure te implementeren.
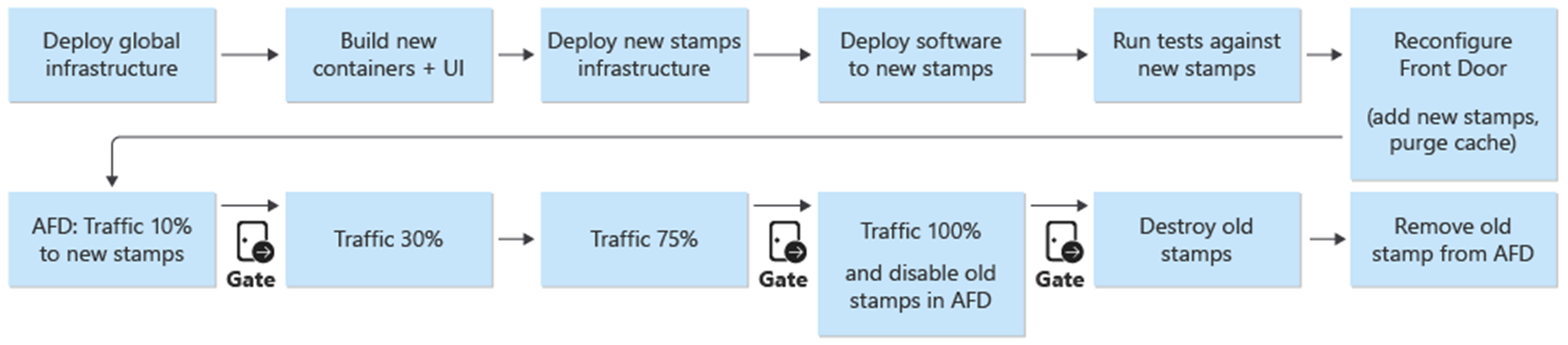
Implementatie en updates vormen het centrale proces in de architectuur. Infrastructuur- en toepassingsgerelateerde updates moeten worden geïmplementeerd op volledig onafhankelijke stempels. Alleen de onderdelen van de globale infrastructuur in de architectuur worden gedeeld via de stempels. Bestaande stempels in de infrastructuur worden niet aangeraakt. Infrastructuurupdates worden geïmplementeerd op deze nieuwe stempels. Op dezelfde manier worden de nieuwe toepassingsversies geïmplementeerd op deze nieuwe stempels.
De nieuwe stempels worden toegevoegd aan Azure Front Door. Verkeer wordt geleidelijk verplaatst naar de nieuwe stempels. Wanneer verkeer zonder problemen vanaf de nieuwe labels wordt geleverd, worden de vorige labels verwijderd.
Penetratietesten, chaos en stresstests worden aanbevolen voor de geïnstalleerde omgeving. Proactief testen van de infrastructuur detecteert zwakke plekken en hoe de geïmplementeerde toepassing zich gedraagt als er een fout opgetreden is.
Implementatie
De implementatie van de infrastructuur in de referentiearchitectuur is afhankelijk van de volgende processen en onderdelen:
DevOps-: de broncode van GitHub en pijplijnen voor de infrastructuur.
nul downtime-updates: updates en upgrades worden geïmplementeerd in de omgeving zonder downtime voor de geïmplementeerde toepassing.
Omgevingen : kortlevende en permanente omgevingen die worden gebruikt voor de architectuur.
gedeelde en toegewezen resources : Azure-resources die zijn toegewezen en gedeeld met de stempels en de algehele infrastructuur.
Implementatie: DevOps
De DevOps-onderdelen bieden de broncodeopslagplaats en CI/CD-pijplijnen voor de implementatie van de infrastructuur en updates. GitHub en Azure Pipelines zijn gekozen als de onderdelen.
GitHub-: bevat de broncodeopslagplaatsen voor de toepassing en infrastructuur.
Azure Pipelines: de pijplijnen die door de architectuur worden gebruikt voor alle build-, test- en releasetaken.
Een extra onderdeel in het ontwerp dat voor de implementatie wordt gebruikt, zijn buildagents. Door Microsoft gehoste buildagents worden gebruikt als onderdeel van Azure Pipelines om de infrastructuur en updates te implementeren. Het gebruik van door Microsoft gehoste buildagents verwijdert de beheerlast voor ontwikkelaars om de buildagent te onderhouden en bij te werken.
Voor meer informatie over Azure Pipelines, zie Wat is Azure Pipelines?.

Zie voor meer informatie Implementatie en testen voor bedrijfskritieke workloads in Azure: Implementaties van infrastructuur als code
Uitrol: Updates zonder downtime
De updatestrategie zonder downtime in de referentiearchitectuur is essentieel voor de algemene bedrijfskritieke toepassing. De methodologie voor vervanging in plaats van de postzegels te upgraden zorgt voor een nieuwe installatie van de toepassing in een infrastructuurstempel. De referentiearchitectuur maakt gebruik van een blauw/groene benadering en maakt afzonderlijke test- en ontwikkelomgevingen mogelijk.
Er zijn twee hoofdonderdelen van de referentiearchitectuur:
Infrastructuur - Azure-services en -resources. Geïmplementeerd met Terraform en de bijbehorende configuratie.
Application: de gehoste service of toepassing die gebruikers bedient. Op basis van Docker-containers en npm-ingebouwde artefacten in HTML en JavaScript voor de gebruikersinterface van de toepassing met één pagina (SPA).
In veel systemen wordt ervan uitgegaan dat toepassingsupdates vaker voorkomen dan infrastructuurupdates. Als gevolg hiervan worden verschillende updateprocedures ontwikkeld voor elk. Met een openbare cloudinfrastructuur kunnen wijzigingen sneller plaatsvinden. Er is één implementatieproces gekozen voor toepassingsupdates en infrastructuurupdates. Eén benadering zorgt ervoor dat infrastructuur- en toepassingsupdates altijd gesynchroniseerd zijn. Met deze methode kunt u het volgende doen:
Een consistent proces: minder kans op fouten als infrastructuur- en toepassingsupdates samen worden gecombineerd in een release, opzettelijk of niet.
Schakelt blue/green-implementatie in: elke update wordt geïmplementeerd met behulp van een geleidelijke migratie van verkeer naar de nieuwe release.
Eenvoudigere implementatie en foutopsporing van de toepassing: het hele stempel host nooit meerdere versies van de toepassing naast elkaar.
Eenvoudige terugdraaibewerking : verkeer kan worden teruggezet naar de stempels waarop de vorige versie wordt uitgevoerd als er fouten of problemen optreden.
Eliminatie van handmatige wijzigingen en configuratiedrift - Elke omgeving is een nieuwe uitrol.
Vertakkingsstrategie
De basis van de updatestrategie is het gebruik van vertakkingen in de Git-opslagplaats. De referentiearchitectuur maakt gebruik van drie typen vertakkingen:
| Filiaal (if referring to an organizational branch) | Beschrijving |
|---|---|
feature/* en fix/* |
De toegangspunten voor elke wijziging. Ontwikkelaars maken deze vertakkingen en moeten ze een beschrijvende naam geven, zoals feature/catalog-update of fix/worker-timeout-bug. Wanneer wijzigingen gereed zijn om te worden samengevoegd, wordt er een pull request (PR) aangemaakt tegen de main-branch. Ten minste één revisor moet alle pull-aanvragen goedkeuren. Met beperkte uitzonderingen moet elke wijziging die wordt voorgesteld in een pull request, worden doorlopen via de end-to-end validatiepijplijn (E2E). Ontwikkelaars moeten de E2E-pijplijn gebruiken om wijzigingen in een volledige omgeving te testen en fouten op te sporen. |
main |
De voortdurend bewegende en stabiele tak. Meestal gebruikt voor integratietests. Wijzigingen in main worden alleen aangebracht via pull-aanvragen. Een branchebeleid verbiedt directe wijzigingen. Nachtreleases op basis van de permanente integration (int)-omgeving worden automatisch uitgevoerd vanuit de main branch. De main tak wordt als stabiel beschouwd. Het zou veilig moeten zijn om aan te nemen dat op elk moment een release kan worden gemaakt. |
release/* |
Release-vertakkingen worden alleen gemaakt op basis van de main vertakking. De vertakkingen volgen de indeling release/2021.7.X. Vertakkingsbeleid zorgt ervoor dat alleen repositorybeheerders release/* vertakkingen mogen maken. Alleen deze branches worden gebruikt voor implementatie in de prod-omgeving. |
Zie voor meer informatie Implementatie en testen voor bedrijfskritieke workloads in Azure: Vertakkingsstrategie
Sneloplossingen
Wanneer een hotfix dringend is vereist vanwege een bug of ander probleem en het normale releaseproces niet kan doorlopen, is er een hotfix-pad beschikbaar. Essentiële beveiligingsupdates en oplossingen voor de gebruikerservaring die niet zijn gedetecteerd tijdens de eerste test, worden beschouwd als geldige voorbeelden van hotfixes.
De hotfix moet worden gemaakt in een nieuwe fix-branch en vervolgens worden samengevoegd in main met behulp van een reguliere pull request. In plaats van een nieuwe release branch te maken, wordt de hotfix 'cherry-picked' in een bestaande release branch. Deze vertakking is al geïmplementeerd in de prod-omgeving. De CI/CD-pijplijn die oorspronkelijk de releasebranch heeft geïmplementeerd met alle tests, wordt opnieuw uitgevoerd en implementeert de hotfix als onderdeel van de pijplijn.
Om grote problemen te voorkomen, is het belangrijk dat de hotfix enkele geïsoleerde commits bevat die gemakkelijk kunnen worden gekozen en geïntegreerd in de release branch. Als geïsoleerde commits niet kunnen worden uitgevoerd om te integreren in de release-branch, is dat een indicatie dat de wijziging niet in aanmerking komt als hotfix. Implementeer de wijziging als een volledige nieuwe release. Combineer deze met een terugdraaiactie naar een voormalige stabiele versie totdat de nieuwe release kan worden geïmplementeerd.
Implementatie: Omgevingen
De referentiearchitectuur maakt gebruik van twee soorten omgevingen voor de infrastructuur:
kortdurende: de E2E-validatiepijplijn wordt gebruikt voor het implementeren van omgevingen met korte levensduur. Kortlevende omgevingen worden gebruikt voor pure validatie- of foutopsporingsomgevingen voor ontwikkelaars. Validatieomgevingen kunnen worden gemaakt op basis van de
feature/*vertakking, onderworpen aan tests en vervolgens vernietigd als alle tests zijn geslaagd. Foutopsporingsomgevingen worden op dezelfde manier geïmplementeerd als validatie, maar worden niet onmiddellijk vernietigd. Deze omgevingen mogen niet langer dan een paar dagen bestaan en moeten worden verwijderd wanneer de bijbehorende pull request van de featurebranch wordt samengevoegd.Permanente : in de permanente omgevingen zijn er
integration (int)enproduction (prod)versies. Deze omgevingen leven continu en worden niet vernietigd. De omgevingen maken gebruik van vaste domeinnamen, zoalsint.mission-critical.app. In een echte implementatie van de referentiearchitectuur moet er eenstaging(preprod)-omgeving worden toegevoegd. Destaging-omgeving wordt gebruikt voor het implementeren en valideren vanreleasevertakkingen met hetzelfde updateproces alsprod(Blauw/Groen-implementatie).Integration (int) - De
int-versie wordt 's nachts geïmplementeerd vanuit demainbranch met hetzelfde proces alsprod. De overschakeling van verkeer is sneller dan de vorige release-eenheid. In plaats van het verkeer geleidelijk over te schakelen over meerdere dagen, zoals inprod, wordt het proces voorintbinnen een paar minuten of uren voltooid. Deze snellere overstap zorgt ervoor dat de bijgewerkte omgeving de volgende ochtend gereed is. Oude stempels worden automatisch verwijderd als alle tests in de pijplijn zijn geslaagd.Production - - De
prod-versie wordt alleen geïmplementeerd vanuitrelease/*vertakkingen. De verkeersoverschakeling maakt gebruik van gedetailleerdere stappen. Er is een handmatige goedkeuringspoort tussen elke stap. Elke release maakt nieuwe regionale stempels en implementeert de nieuwe toepassingsversie op de stempels. Bestaande stempels worden niet in het proces aangeraakt. De belangrijkste overweging voorprodis dat het "altijd ingeschakeld"moet zijn. Geplande of ongeplande downtime mag nooit plaatsvinden. De enige uitzondering hierop zijn fundamentele wijzigingen in de databaselaag. Mogelijk is er een gepland onderhoudsvenster nodig.
Uitrol: Gedeelde en toegewezen middelen
De permanente omgevingen (int en prod) binnen de referentiearchitectuur hebben verschillende typen resources, afhankelijk van of ze worden gedeeld met de volledige infrastructuur of toegewezen aan een afzonderlijke stempel. Resources kunnen worden toegewezen aan een bepaalde release en bestaan alleen totdat de volgende release-eenheid wordt overgenomen.
Release-eenheden
Een release-eenheid bestaat uit verschillende regionale markers per specifieke releaseversie. Stempels bevatten alle hulpmiddelen die niet worden gedeeld met de andere stempels. Dit zijn virtuele netwerken, Azure Kubernetes Service-cluster, Event Hubs en Azure Key Vault. Azure Cosmos DB en ACR worden geconfigureerd met Terraform-gegevensbronnen.
Wereldwijd gedeelde middelen
Alle resources die worden gedeeld tussen release-eenheden, worden gedefinieerd in een onafhankelijke Terraform-sjabloon. Deze resources zijn Front Door, Azure Cosmos DB, Container Registry (ACR) en de Log Analytics-werkruimten en andere bewakingsgerelateerde resources. Deze resources worden geïmplementeerd voordat de eerste regionale stempel van een release-eenheid wordt geïmplementeerd. Naar de resources wordt verwezen in de Terraform-sjablonen voor de stempels.
Voordeur
Front Door is een wereldwijd gedeelde bron tussen verschillende afdelingen, maar de configuratie is iets afwijkend van de andere wereldwijde bronnen. Front Door moet opnieuw worden geconfigureerd nadat een nieuwe stempel is geïmplementeerd. Front Door moet opnieuw worden geconfigureerd om het verkeer geleidelijk over te schakelen naar de nieuwe stempels.
De back-endconfiguratie van Front Door kan niet rechtstreeks worden gedefinieerd in de Terraform-sjabloon. De configuratie wordt ingevoegd met Terraform-variabelen. De variabelewaarden worden samengesteld voordat de Terraform-implementatie wordt gestart.
De configuratie van afzonderlijke onderdelen voor de Front Door-implementatie wordt gedefinieerd als:
Front-end- - Sessieaffiniteit is geconfigureerd om ervoor te zorgen dat gebruikers tijdens één sessie niet schakelen tussen verschillende ui-versies.
Origins - Front Door is geconfigureerd met twee soorten oorsprongsgroepen:
Een oorsprongsgroep voor statische opslag die de gebruikersinterface dient. De groep bevat de websiteopslagaccounts van alle actieve release-eenheden. Verschillende gewichten kunnen worden toegewezen aan de oorsprongen van verschillende release-eenheden om het verkeer geleidelijk naar een nieuwere eenheid te verplaatsen. Aan elke oorsprong van een release-eenheid moet hetzelfde gewicht zijn toegewezen.
Een oorsprongsgroep voor de API, die wordt gehost in Azure Kubernetes Service. Als er release-eenheden met verschillende API-versies zijn, bestaat er voor elke release-eenheid een API-oorspronggroep. Als alle release-eenheden dezelfde compatibele API bieden, worden alle origins toegevoegd aan dezelfde groep en verschillende gewichten toegewezen.
routeringsregels: er zijn twee typen routeringsregels:
Een routeringsregel voor de gebruikersinterface die is gekoppeld aan de UI-opslag oorsprongsgroep.
Een routeringsregel voor elke API die momenteel wordt ondersteund door de oorsprongen. Bijvoorbeeld:
/api/1.0/*en/api/2.0/*.
Als een release een nieuwe versie van de back-end-API's introduceert, worden de wijzigingen weergegeven in de gebruikersinterface die wordt geïmplementeerd als onderdeel van de release. Een specifieke release van de gebruikersinterface roept altijd een specifieke versie van de API-URL aan. Gebruikers van een UI-versie gebruiken automatisch de desbetreffende backend-API. Er zijn specifieke routeringsregels nodig voor verschillende exemplaren van de API-versie. Deze regels zijn gekoppeld aan de bijbehorende oorsprongsgroepen. Als er geen nieuwe API is geïntroduceerd, worden alle API-gerelateerde routeringsregels gekoppeld aan de groep met één oorsprong. In dit geval maakt het niet uit of een gebruiker de gebruikersinterface van een andere release dan de API gebruikt.
Implementatie: implementatieproces
Een blauw/groen implementatie is het doel van het implementatieproces. Er wordt een nieuwe release van een release/*-vertakking geïmplementeerd in de prod-omgeving. Gebruikersverkeer wordt geleidelijk verplaatst naar de systemen voor de nieuwe release.
Als eerste stap in het implementatieproces van een nieuwe versie wordt de infrastructuur voor de nieuwe release-eenheid geïmplementeerd met Terraform. Door de implementatiepijplijn voor de infrastructuur uit te voeren, wordt de nieuwe infrastructuur geïmplementeerd vanuit een geselecteerde releasebranch. Tegelijkertijd met het inrichten van de infrastructuur worden de containerafbeeldingen gebouwd of geïmporteerd en naar het wereldwijd gedeelde containerregister (ACR) geüpload. Wanneer de vorige processen zijn voltooid, wordt de toepassing geïmplementeerd op de stempels. Vanuit het oogpunt van implementatie is het één pijplijn met meerdere afhankelijke fasen. Dezelfde pijplijn kan opnieuw worden uitgevoerd voor hotfix-implementaties.
Nadat de nieuwe release-eenheid is geïmplementeerd en gevalideerd, wordt de nieuwe eenheid toegevoegd aan Front Door om gebruikersverkeer te ontvangen.
Een switch/parameter die onderscheid maakt tussen releases die wel en geen nieuwe API-versie introduceren, moet worden gepland. Op basis van of de release een nieuwe API-versie introduceert, moet er een nieuwe origin-groep met de API-back-ends worden gemaakt. U kunt ook nieuwe API-back-ends toevoegen aan een bestaande oorspronkelijke groep. Nieuwe UI-opslagaccounts worden toegevoegd aan de bijbehorende bestaande oorspronkelijke groep. Gewichten voor nieuwe bronnen moeten worden ingesteld op basis van de gewenste verkeersverdeling. Er moet een nieuwe routeringsregel worden gemaakt die overeenkomt met de juiste oorspronkelijke groep.
Als onderdeel van de toevoeging van de nieuwe release-eenheid moeten de gewichten van de nieuwe oorsprongen worden ingesteld op het gewenste minimale gebruikersverkeer. Als er geen problemen worden gedetecteerd, moet de hoeveelheid gebruikersverkeer gedurende een bepaalde periode worden verhoogd naar de nieuwe oorspronkelijke groep. Als u de gewichtsparameters wilt aanpassen, moeten dezelfde implementatiestappen opnieuw worden uitgevoerd met de gewenste waarden.
Demontage van release-eenheid
Als onderdeel van de implementatiepijplijn voor een release-eenheid is er een vernietigingsfase die alle stempels verwijdert zodra een release-eenheid niet meer nodig is. Al het verkeer wordt verplaatst naar een nieuwe versie van de release. Deze fase omvat het verwijderen van verwijzingen naar release-eenheden in Front Door. Deze verwijdering is essentieel om de release van een nieuwe versie op een latere datum mogelijk te maken. Front Door moet verwijzen naar één release-eenheid om voorbereid te zijn op een toekomstige release.
Controlelijsten
Als onderdeel van het releaseritme moet er een controlelijst vóór en na de release worden gebruikt. Het volgende voorbeeld is van items die minimaal in een controlelijst moeten staan.
controlelijst vóór de release: controleer het volgende voordat u een release start:
Zorg ervoor dat de laatste versie van de
mainbranch is geïmplementeerd en getest in deint-omgeving.Werk het changelog-bestand bij via een pull request voor de
mainbranch.Maak een
release/tak vanuit demaintak.
controlelijst na release - Voordat oude stempels worden vernietigd en hun verwijzingen uit Front Door worden verwijderd, controleert u of:
Clusters ontvangen geen binnenkomend verkeer meer.
Event Hubs en andere berichtenwachtrijen bevatten geen niet-verwerkte berichten.
Implementatie: Beperkingen en risico's van de updatestrategie
De updatestrategie die in deze referentiearchitectuur wordt beschreven, heeft enkele beperkingen en risico's die moeten worden vermeld:
Hogere kosten: bij het vrijgeven van updates zijn veel van de infrastructuuronderdelen twee keer actief voor de releaseperiode.
Front Door-complexiteit: het updateproces in Front Door is complex om te implementeren en te onderhouden. De mogelijkheid om effectieve blauw/groene implementaties zonder downtime uit te voeren, is afhankelijk van het goed werken.
Kleine wijzigingen tijdrovend: het updateproces resulteert in een langer releaseproces voor kleine wijzigingen. Deze beperking kan gedeeltelijk worden verzacht met het hotfixproces dat in de vorige sectie wordt beschreven.
Implementatie: Overwegingen voor vooruitwaartse compatibiliteit van toepassingsgegevens
De updatestrategie kan ondersteuning bieden voor meerdere versies van een API en werkonderdelen die gelijktijdig worden uitgevoerd. Omdat Azure Cosmos DB wordt gedeeld tussen twee of meer versies, is het mogelijk dat gegevenselementen die door één versie zijn gewijzigd, mogelijk niet altijd overeenkomen met de versie van de API of werkrollen die deze gebruiken. De API-lagen en -werkrollen moeten het ontwerp voor compatibiliteit vooruit implementeren. In eerdere versies van de API- of werkrolonderdelen worden gegevens verwerkt die zijn ingevoegd door een latere API- of werkrolonderdeelversie. Het negeert delen die het niet begrijpt.
Testen
De referentiearchitectuur bevat verschillende tests die in verschillende fasen in de test-implementatie worden gebruikt.
Deze tests omvatten:
eenheidstests: met deze tests wordt gecontroleerd of de bedrijfslogica van de toepassing werkt zoals verwacht. De referentiearchitectuur bevat een voorbeeldsuite met eenheidstests die automatisch worden uitgevoerd voordat elke container wordt gebouwd door Azure Pipelines. Als een test mislukt, stopt de pijplijn. Het bouwen en uitrollen stopt. De ontwikkelaar moet het probleem oplossen voordat de pijplijn opnieuw kan worden uitgevoerd.
belastingtests: deze tests helpen bij het evalueren van de capaciteit, schaalbaarheid en mogelijke knelpunten voor een bepaalde workload of stack. De referentie-implementatie bevat een generator voor gebruikersbelasting om synthetische belastingpatronen te maken die kunnen worden gebruikt om echt verkeer te simuleren. De loadgenerator kan ook onafhankelijk van de referentie-implementatie worden gebruikt.
Smoketests - Deze tests bepalen of de infrastructuur en werklast beschikbaar zijn en functioneren zoals verwacht. Smoke tests worden uitgevoerd als onderdeel van elke deployment.
UI-tests: met deze tests wordt gecontroleerd of de gebruikersinterface is geïmplementeerd en werkt zoals verwacht. De huidige implementatie legt alleen schermopnamen van verschillende pagina's vast na de implementatie zonder daadwerkelijk testen.
Foutinjectietests: deze tests kunnen geautomatiseerd of handmatig worden uitgevoerd. Geautomatiseerd testen in de architectuur integreert Azure Chaos Studio als onderdeel van de implementatiepijplijnen.
Testen: Frameworks
De online referentie-implementatie maakt gebruik van bestaande testmogelijkheden en frameworks waar mogelijk.
| Kader | Test | Beschrijving |
|---|---|---|
| eenheidseenheid | Eenheid | Dit framework wordt gebruikt voor het testen van het .NET Core-gedeelte van de implementatie. Azure Pipelines voert eenheidstests automatisch uit voordat de container wordt gebouwd. |
| JMeter met Azure Load Testing | Laden | Azure Load Testing is een beheerde service die wordt gebruikt voor het uitvoeren van Apache JMeter definities van belastingstests. |
| Sprinkhaan | Laden | Locust is een opensource-framework voor belastingstests dat is geschreven in Python. |
| Toneelschrijver | Gebruikersinterface en rook | Playwright is een open source Node.js bibliotheek voor het automatiseren van Chromium, Firefox en WebKit met één API. De Playwright-testdefinitie kan ook onafhankelijk van de referentie-implementatie worden gebruikt. |
| Azure Chaos Studio | Foutinjectie | De referentie-implementatie maakt gebruik van Azure Chaos Studio als een optionele stap in de E2E-validatiepijplijn om fouten in te voeren voor tolerantievalidatie. |
Testen: Testen van foutinjectie en Chaos Engineering
Gedistribueerde toepassingen moeten tolerant zijn voor service- en onderdeelstoringen. Foutinjectie testen (ook wel foutinjectie of Chaos Engineering genoemd) is de praktijk van het onderwerpen van toepassingen en diensten aan echte stress en fouten.
Tolerantie is een eigenschap van een volledig systeem en het injecteren van fouten helpt bij het vinden van problemen in de toepassing. Door deze problemen op te lossen, kunt u de tolerantie van toepassingen valideren in onbetrouwbare omstandigheden, ontbrekende afhankelijkheden en andere fouten.
Handmatige en automatische tests kunnen worden uitgevoerd op basis van de infrastructuur om fouten en problemen in de implementatie te vinden.
Automatisch
De referentiearchitectuur integreert Azure Chaos Studio om een set Azure Chaos Studio-experimenten te implementeren en uit te voeren om verschillende fouten op stempelniveau te injecteren. Chaos-experimenten kunnen worden uitgevoerd als een optioneel onderdeel van de E2E-implementatiepijplijn. Wanneer de tests worden uitgevoerd, wordt de optionele belastingstest altijd parallel uitgevoerd. De belastingstest wordt gebruikt om belasting op het cluster te creëren om het effect van de geïnjecteerde fouten te valideren.
Handmatig
Foutinjectietests moeten handmatig worden uitgevoerd in een E2E-validatieomgeving. Deze omgeving zorgt voor volledige representatieve tests zonder risico op interferentie van andere omgevingen. De meeste fouten die met de tests worden gegenereerd, zijn direct te zien in de Application Insights Live metrics weergave. De resterende fouten zijn beschikbaar in de weergave Fouten en de bijbehorende logboektabellen. Voor andere fouten is diepere foutopsporing vereist, zoals het gebruik van kubectl om het gedrag in Azure Kubernetes Service te observeren.
Twee voorbeelden van mislukte injectietests die worden uitgevoerd op basis van de referentiearchitectuur zijn:
DNS (Domain Name Service) - gebaseerd op foutinjectie - een testgeval dat meerdere problemen kan simuleren. DNS-omzettingsfouten door het falen van een DNS-server of Azure DNS. Testen op basis van DNS kan helpen bij het simuleren van algemene verbindingsproblemen tussen een client en een service, bijvoorbeeld wanneer de BackgroundProcessor geen verbinding kan maken met de Event Hubs.
In scenario's met één host kunt u het lokale
hosts-bestand wijzigen om DNS-omzetting te overschrijven. In een grotere omgeving met meerdere dynamische servers zoals AKS is eenhostsbestand niet haalbaar. privé-DNS-zones van Azure kunnen worden gebruikt als alternatief voor het testen van foutscenario's.Azure Event Hubs en Azure Cosmos DB zijn twee van de Azure-services die worden gebruikt in de referentie-implementatie die kunnen worden gebruikt voor het injecteren van DNS-fouten. DNS-resolutie van Event Hubs kan worden gemanipuleerd met een Azure privé-DNS-zone die is gekoppeld aan het virtuele netwerk van een van de instances. Azure Cosmos DB is een wereldwijd gerepliceerde service met specifieke regionale eindpunten. Manipulatie van de DNS-records voor deze eindpunten kan een fout voor een specifieke regio simuleren en de failover van clients testen.
Firewall blokkeert: de meeste Azure-services ondersteunen firewalltoegangsbeperkingen op basis van virtuele netwerken en/of IP-adressen. In de referentie-infrastructuur worden deze beperkingen gebruikt om de toegang tot Azure Cosmos DB of Event Hubs te beperken. Een eenvoudige procedure is het verwijderen van bestaande Toestaan regels of het toevoegen van nieuwe Blokkeren regels. Met deze procedure kunnen onjuiste configuraties van firewalls of servicestoringen worden gesimuleerd.
De volgende voorbeeldservices in de referentie-implementatie kunnen worden getest met een firewalltest:
Dienst Resultaat Key Vault- Wanneer de toegang tot Key Vault wordt geblokkeerd, is het meest directe effect het mislukken van het opstarten van nieuwe pods. Het Key Vault CSI-stuurprogramma dat geheimen ophaalt bij het opstarten van een pod, kan zijn taken niet uitvoeren en voorkomt daardoor dat de pod start. Bijbehorende foutberichten kunnen worden waargenomen met kubectl describe po CatalogService-deploy-my-new-pod -n workload. Bestaande pods blijven werken, hoewel hetzelfde foutbericht wordt waargenomen. De resultaten van de periodieke updatecontrole voor geheimen genereren het foutbericht. Hoewel deze niet is getest, werkt het uitvoeren van een implementatie niet terwijl Key Vault niet toegankelijk is. Terraform- en Azure CLI-taken in de pijplijnuitvoering doen aanvragen naar Key Vault.Event Hubs Wanneer de toegang tot Event Hubs wordt geblokkeerd, mislukken nieuwe berichten die worden verzonden door de CatalogService en HealthService. Het ophalen van berichten door BackgroundProcess mislukt langzaam, met een totale fout binnen een paar minuten. Azure Cosmos DB Als u het bestaande firewallbeleid voor een virtueel netwerk verwijdert, mislukt de Health Service met minimale vertraging. Met deze procedure wordt alleen een specifiek geval gesimuleerd, namelijk een volledige Azure Cosmos DB-storing. De meeste foutcases die zich op regionaal niveau voordoen, worden automatisch beperkt met transparante failover van de client naar een andere Azure Cosmos DB-regio. Het testen van op DNS gebaseerde foutinjectie die eerder is beschreven, is een zinvollere test voor Azure Cosmos DB. ACR- ( Container Registry) Wanneer de toegang tot ACR wordt geblokkeerd, blijft het maken van nieuwe pods die eerder op een AKS-knooppunt zijn opgehaald en in de cache worden opgeslagen, verder werken. De creatie werkt nog steeds vanwege de K8s deployment-vlag pullPolicy=IfNotPresent. Knooppunten kunnen geen nieuwe pods starten en falen onmiddellijk metErrImagePullfouten als het knooppunt niet voor de blokkade een afbeelding ophaalt en in de cache opslaat.kubectl describe podgeeft het bijbehorende403 Forbiddenbericht weer.AKS-ingress Load Balancer De wijziging van de inkomende regels voor HTTP(S) (poorten 80 en 443) in de door AKS beheerde netwerkbeveiligingsgroep (NSG) naar Weigeren zorgt ervoor dat het verkeer van gebruikers of gezondheidstests het cluster niet kan bereiken. Het testen van deze storing is moeilijk te bepalen wat de hoofdoorzaak is, welke werd gesimuleerd als een blokkade in het netwerkpad tussen Front Door en een regionale stempel. Front Door detecteert deze fout onmiddellijk en haalt de stempel uit de circulatie.