In dit artikel wordt beschreven hoe een ontwikkelteam metrische gegevens heeft gebruikt om knelpunten te vinden en de prestaties van een gedistribueerd systeem te verbeteren. Het artikel is gebaseerd op het testen van de werkelijke belasting die we hebben uitgevoerd voor een voorbeeldtoepassing. De toepassing is afkomstig van de basislijn Azure Kubernetes Service (AKS) voor microservices.
Dit artikel maakt deel uit van een serie. Lees hier het eerste deel.
Scenario: Een clienttoepassing initieert een zakelijke transactie die meerdere stappen omvat.
Dit scenario omvat een toepassing voor het bezorgen van drones die wordt uitgevoerd op AKS. Klanten gebruiken een web-app om leveringen per drone te plannen. Elke transactie vereist meerdere stappen die worden uitgevoerd door afzonderlijke microservices op de back-end:
- De Leveringsservice beheert de leveringen.
- De Drone Scheduler-service plant drones voor ophalen.
- De pakketservice beheert pakketten.
Er zijn twee andere services: een opnameservice die clientaanvragen accepteert en deze in een wachtrij plaatst voor verwerking, en een werkstroomservice die de stappen in de werkstroom coördineert.
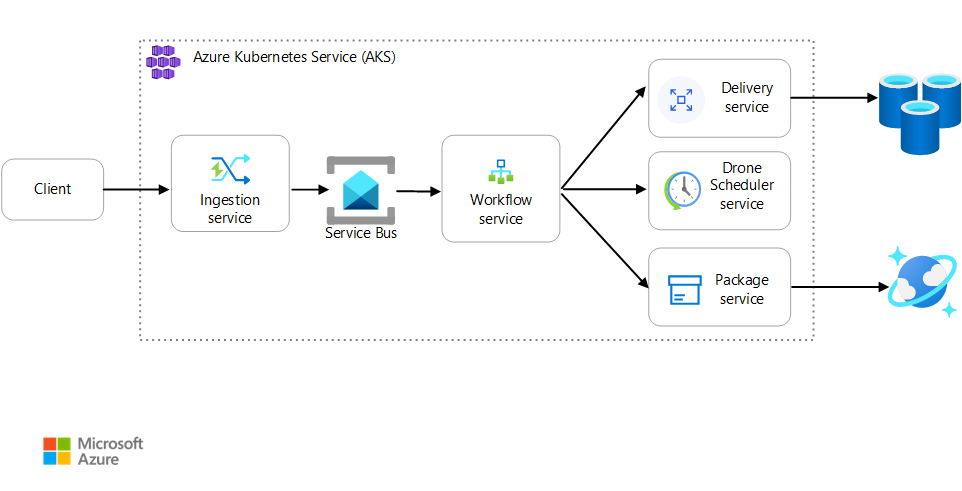
Zie Een microservicearchitectuur ontwerpen voor meer informatie over dit scenario.
Test 1: Basislijn
Voor de eerste belastingstest heeft het team een AKS-cluster met zes knooppunten gemaakt en drie replica's van elke microservice geïmplementeerd. De belastingstest was een stapsgewijze belastingstest, beginnend bij twee gesimuleerde gebruikers en maximaal 40 gesimuleerde gebruikers.
| Instelling | Waarde |
|---|---|
| Clusterknooppunten | 6 |
| Peulen | 3 per service |
In de volgende grafiek ziet u de resultaten van de belastingstest, zoals wordt weergegeven in Visual Studio. De paarse lijn plot gebruikersbelasting en de oranje lijn zet het totale aantal aanvragen uit.
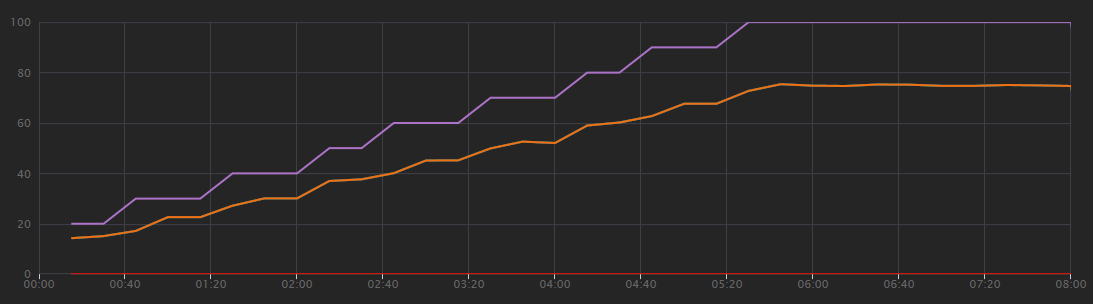
Het eerste wat u zich bij dit scenario moet realiseren, is dat clientaanvragen per seconde geen nuttige prestatiemeter zijn. Dat komt omdat de toepassing aanvragen asynchroon verwerkt, zodat de client meteen een antwoord krijgt. De antwoordcode is altijd HTTP 202 (geaccepteerd), wat betekent dat de aanvraag is geaccepteerd, maar dat de verwerking niet is voltooid.
Wat we echt willen weten, is of de back-end de aanvraagsnelheid bijhoudt. De Service Bus-wachtrij kan pieken opvangen, maar als de back-end een langdurige belasting niet kan verwerken, loopt de verwerking steeds verder achter.
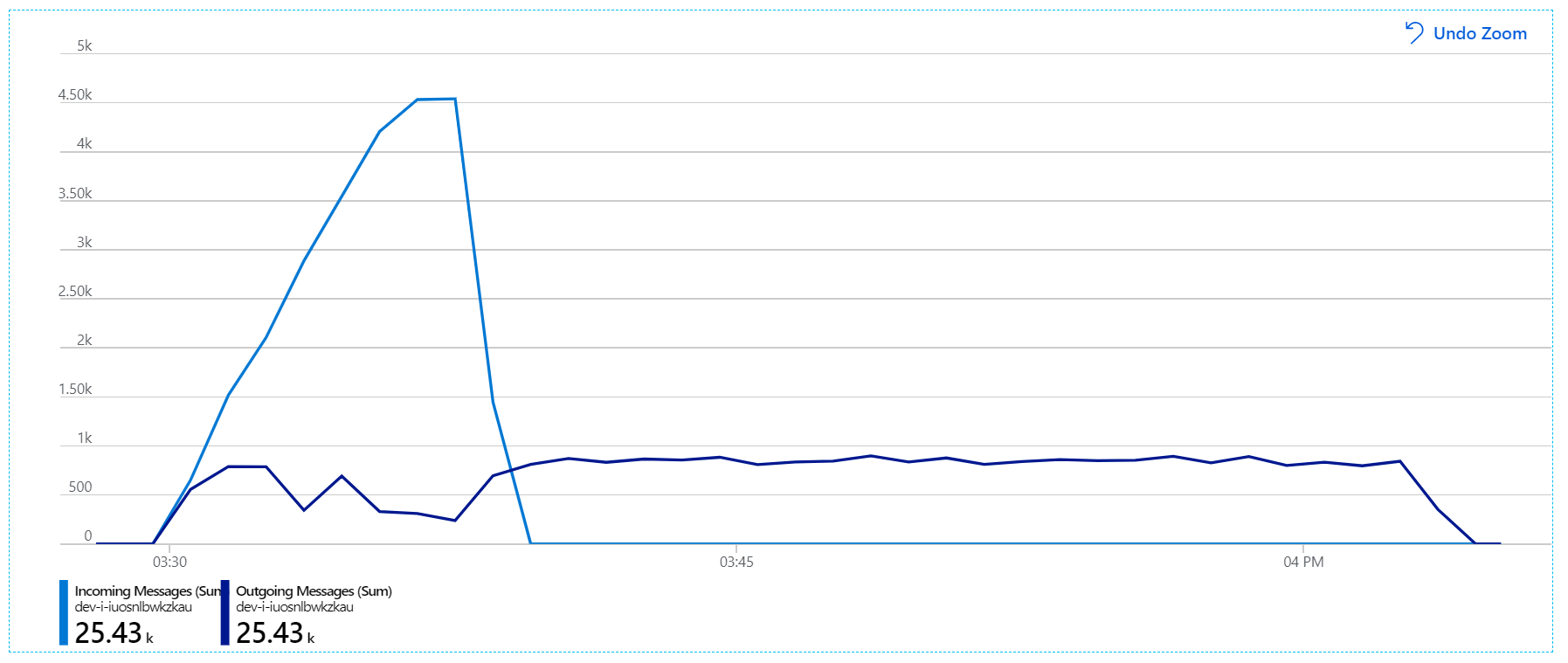
Hier volgt een meer informatieve grafiek. Hiermee wordt het aantal binnenkomende en uitgaande berichten in de Service Bus-wachtrij uit gezet. Inkomende berichten worden in lichtblauw weergegeven en uitgaande berichten worden in het donkerblauw weergegeven:
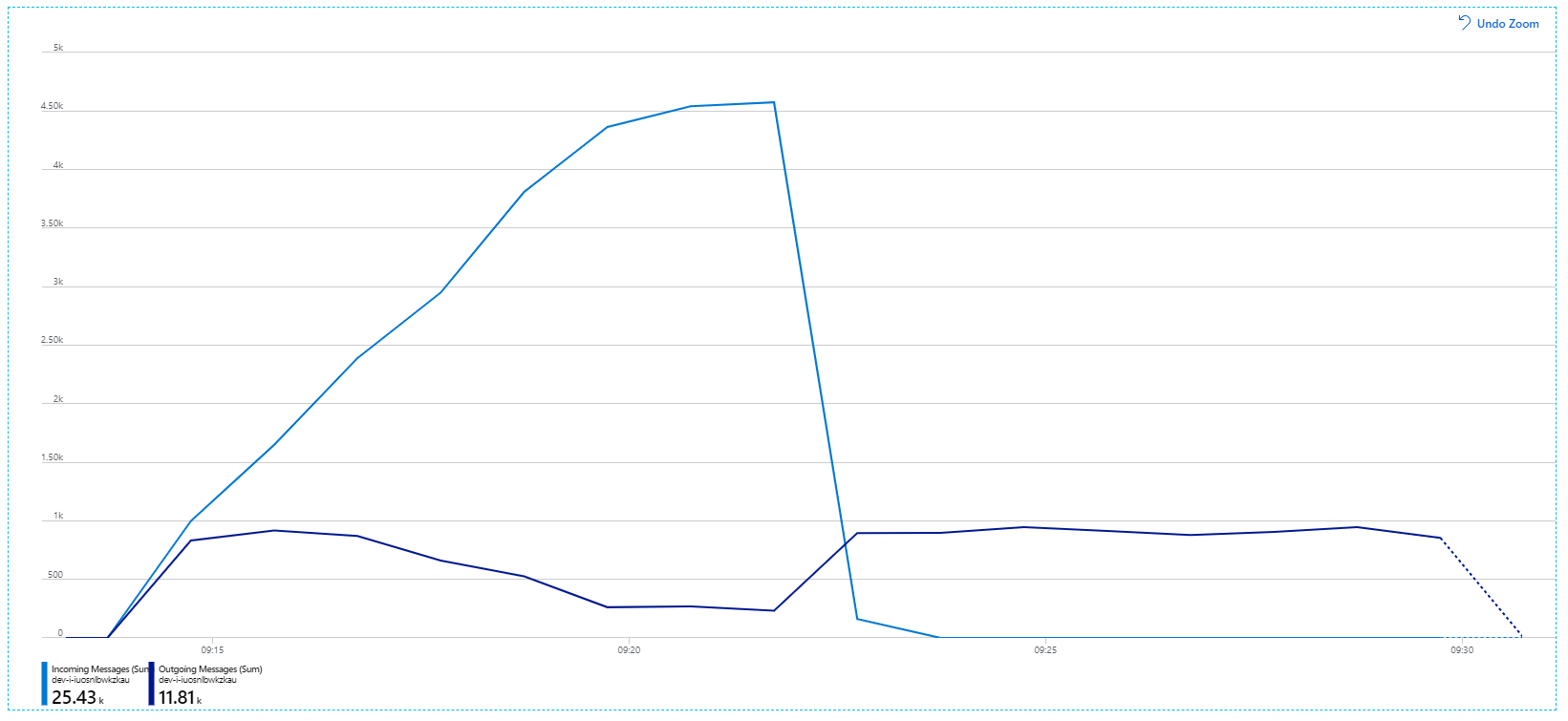
In deze grafiek ziet u dat de snelheid van binnenkomende berichten toeneemt, een piek bereikt en vervolgens weer daalt naar nul aan het einde van de belastingstest. Maar het aantal uitgaande berichten piekt vroeg in de test en daalt vervolgens daadwerkelijk. Dit betekent dat de werkstroomservice, die de aanvragen afhandelt, niet bijhoudt. Zelfs nadat de belastingtest is beëindigd (rond 9:22 in de grafiek), worden berichten nog steeds verwerkt omdat de werkstroomservice de wachtrij blijft leegmaken.
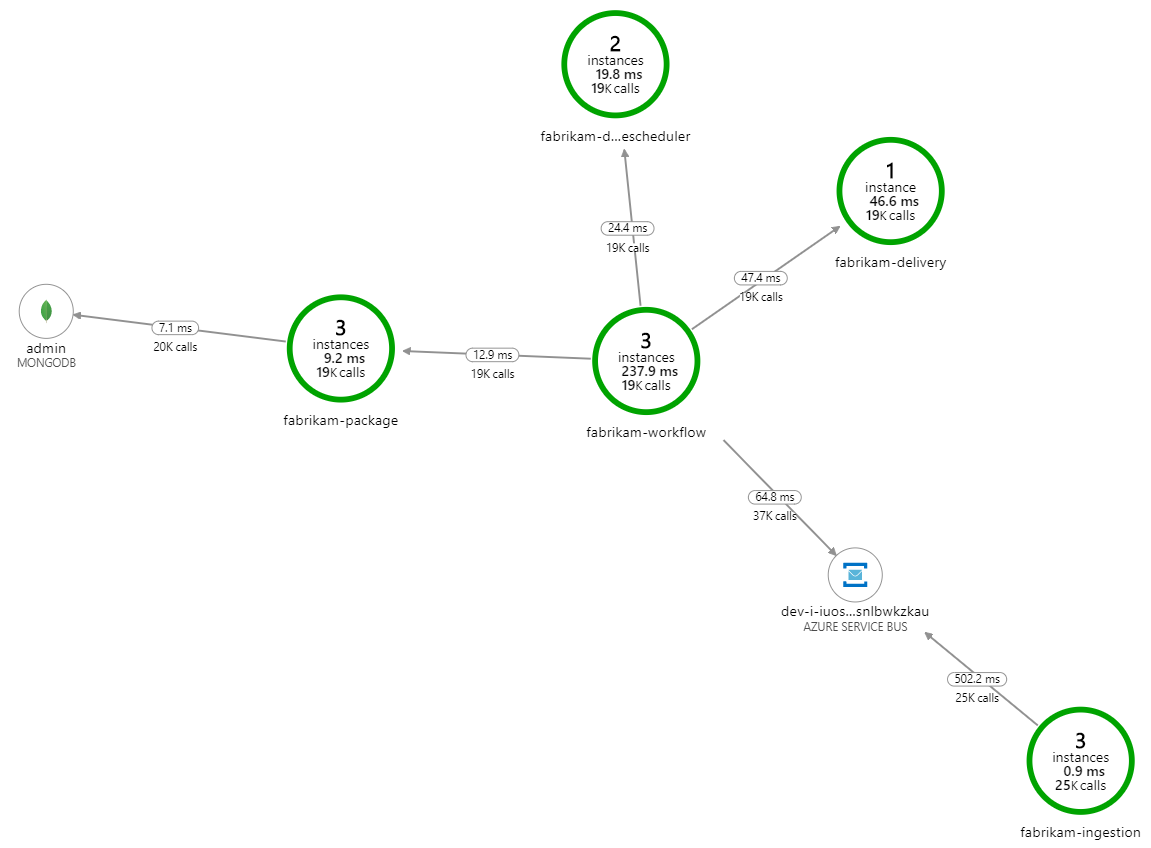
Wat vertraagt de verwerking? Het eerste waar u op moet letten, zijn fouten of uitzonderingen die kunnen wijzen op een systematisch probleem. Het toepassingsoverzicht in Azure Monitor toont de grafiek van aanroepen tussen onderdelen en is een snelle manier om problemen op te sporen en vervolgens door te klikken voor meer informatie.
Het toepassingsoverzicht laat natuurlijk zien dat de werkstroomservice fouten krijgt van de Delivery-service:
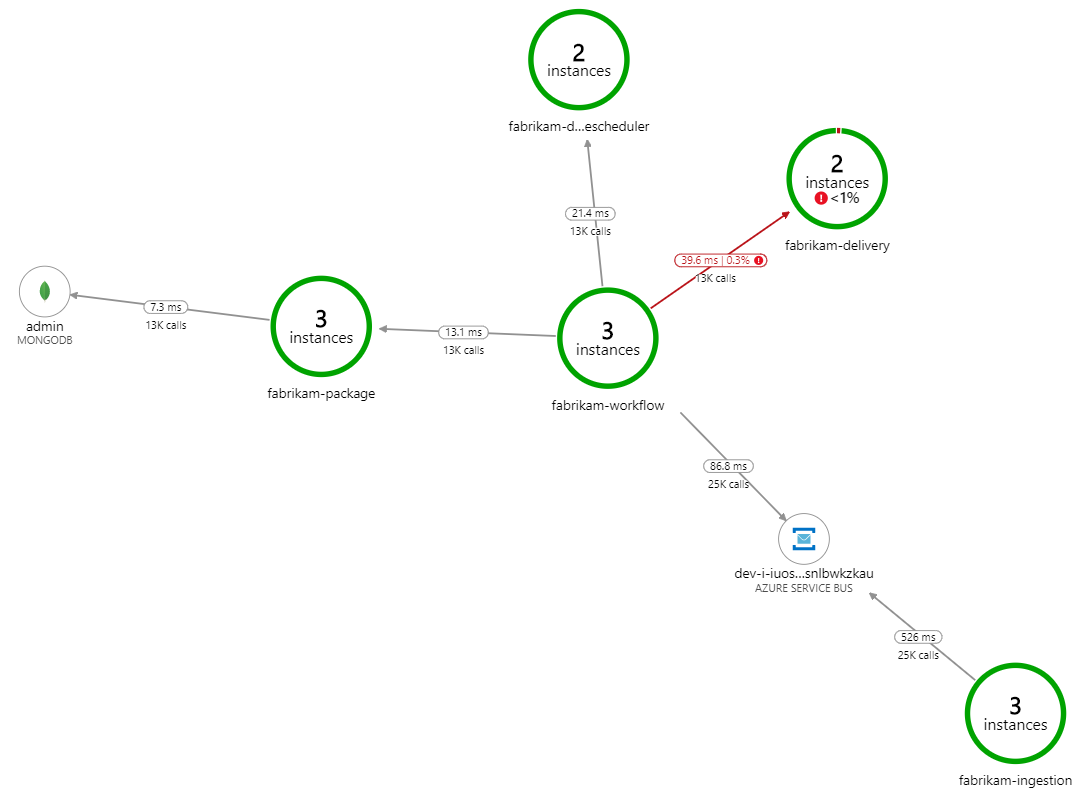
Als u meer details wilt zien, selecteert u een knooppunt in de grafiek en klikt u in een end-to-end transactieweergave. In dit geval ziet u dat de Leveringsservice HTTP 500-fouten retourneert. De foutberichten geven aan dat er een uitzondering wordt gegenereerd vanwege geheugenlimieten in Azure Cache voor Redis.
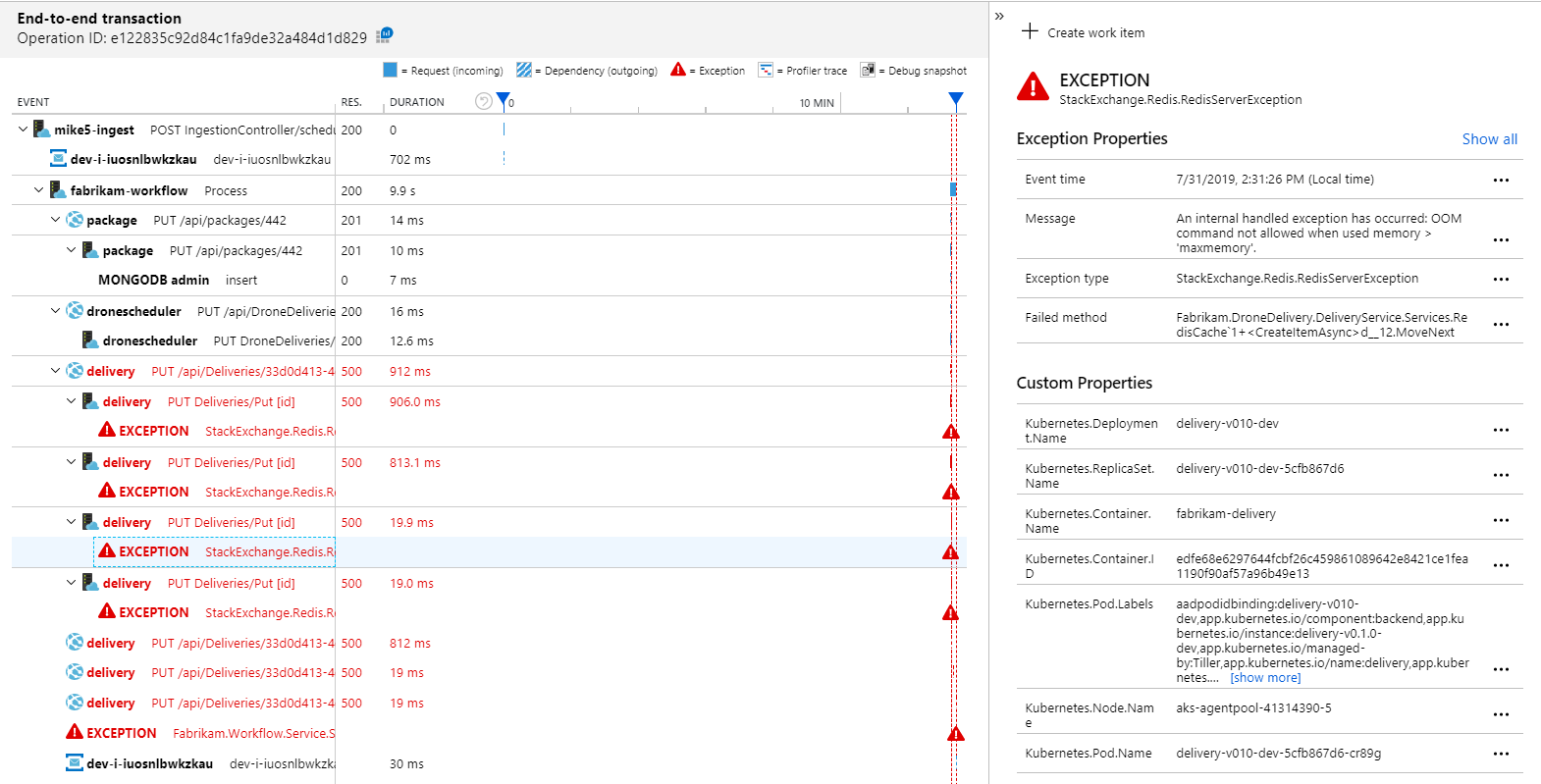
Mogelijk ziet u dat deze aanroepen naar Redis niet worden weergegeven in het toepassingsoverzicht. Dat komt omdat de .NET-bibliotheek voor Application Insights geen ingebouwde ondersteuning biedt voor het bijhouden van Redis als een afhankelijkheid. (Zie Automatisch verzamelen van afhankelijkheden voor een lijst met wat standaard wordt ondersteund.) Als alternatief kunt u de TrackDependency-API gebruiken om afhankelijkheid bij te houden. Bij belastingtests worden dit soort hiaten in de telemetrie vaak aan het licht gebracht, die kunnen worden hersteld.
Test 2: Grotere cachegrootte
Voor de tweede belastingstest heeft het ontwikkelteam de cachegrootte in Azure Cache voor Redis verhoogd. (Zie Azure Cache voor Redis schalen.) Met deze wijziging zijn de uitzonderingen voor onvoldoende geheugen opgelost. In het toepassingsoverzicht worden nu nul fouten weergegeven:
Er is echter nog steeds een aanzienlijke vertraging bij het verwerken van berichten. Op het hoogtepunt van de belastingstest is de snelheid van binnenkomende berichten meer dan 5× de uitgaande snelheid:
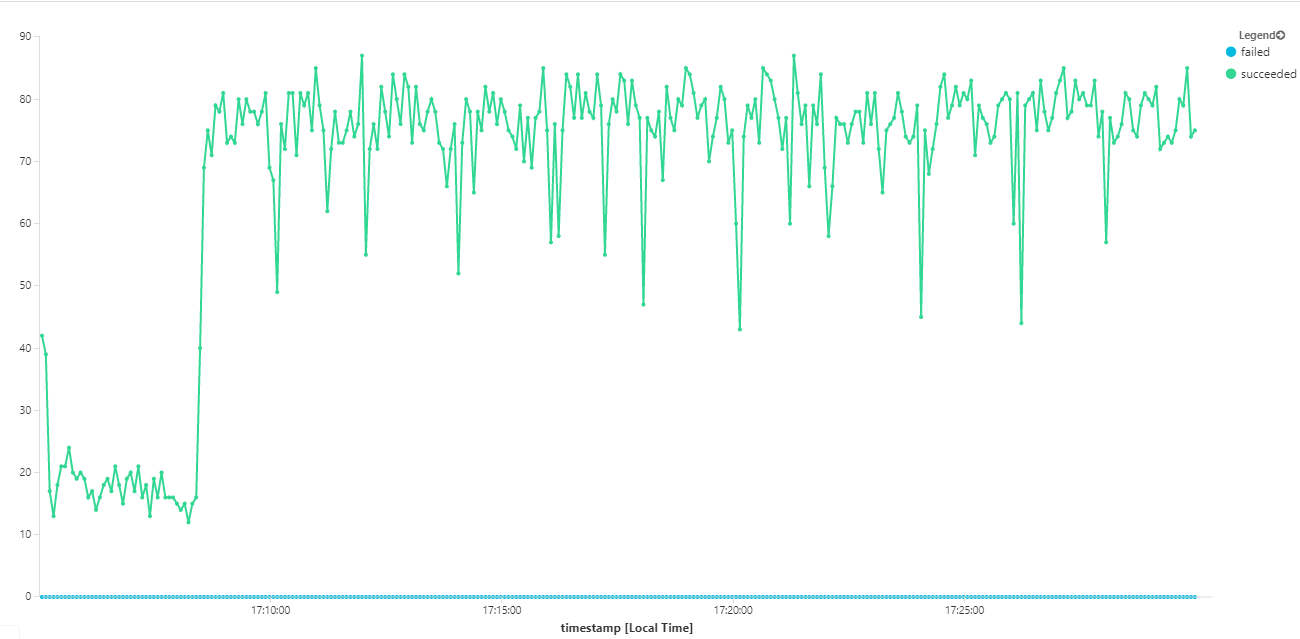
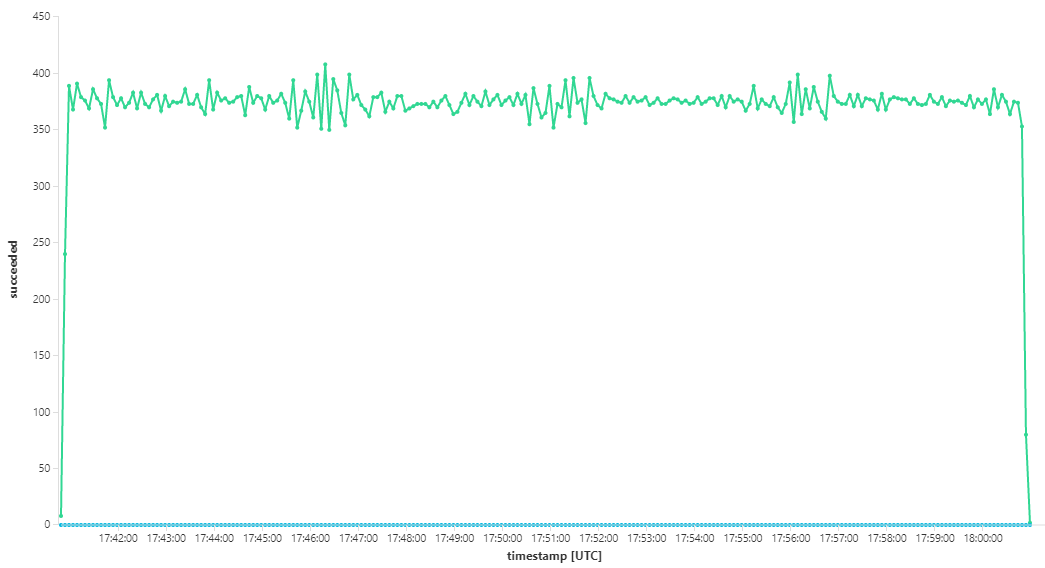
De volgende grafiek meet de doorvoer in termen van berichtvoltooiing, dat wil gezegd, de snelheid waarmee de Werkstroomservice de Service Bus-berichten markeert als voltooid. Elk punt in de grafiek vertegenwoordigt 5 seconden aan gegevens, met een maximale doorvoer van ~16 per seconde.
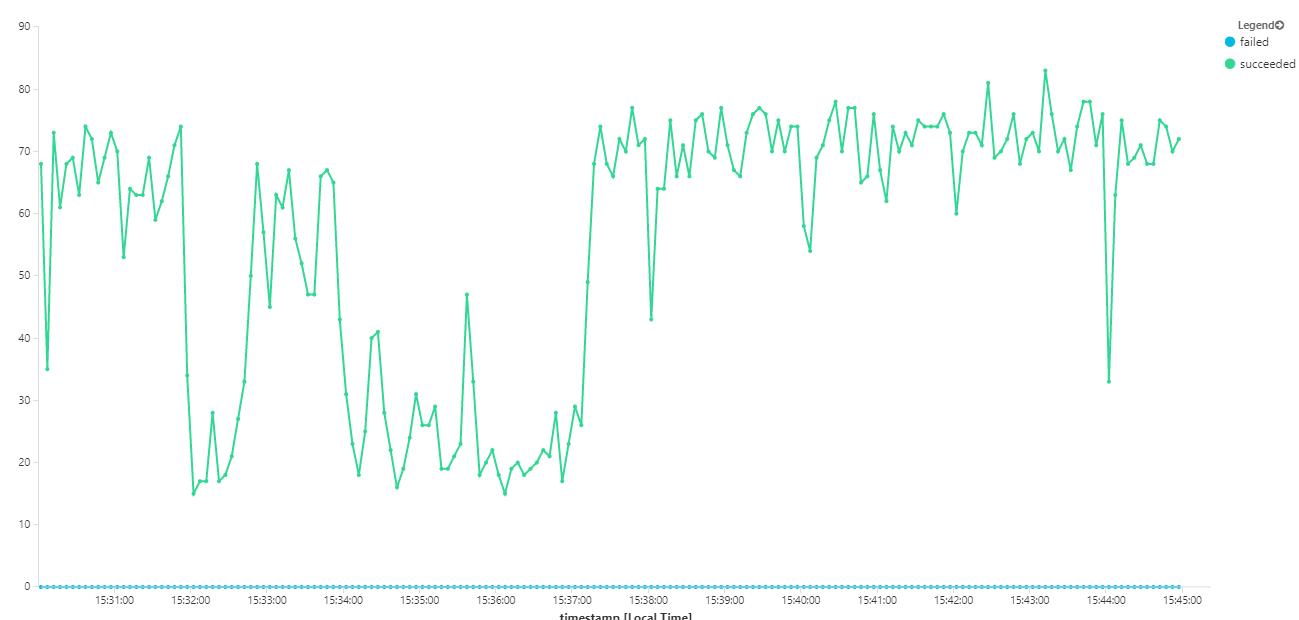
Deze grafiek is gegenereerd door een query uit te voeren in de Log Analytics-werkruimte met behulp van de Kusto-querytaal:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3: De back-endservices uitschalen
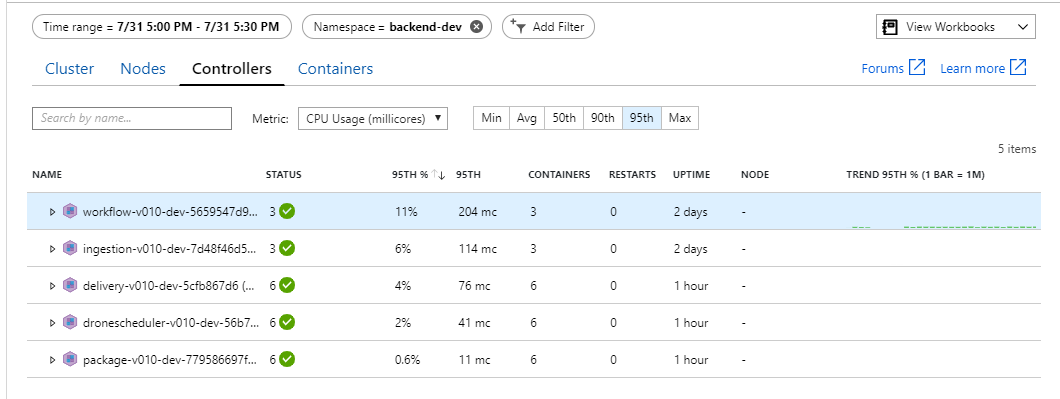
Het lijkt erop dat de back-end het knelpunt is. Een eenvoudige volgende stap is het uitschalen van de zakelijke services (Pakket, Levering en Drone Scheduler) en te kijken of de doorvoer verbetert. Voor de volgende belastingstest heeft het team deze services geschaald van drie replica's naar zes replica's.
| Instelling | Waarde |
|---|---|
| Clusterknooppunten | 6 |
| Opnameservice | 3 replica's |
| Werkstroomservice | 3 replica's |
| Pakket, Levering, Drone Scheduler-services | 6 replica's per stuk |
Helaas laat deze belastingtest slechts een bescheiden verbetering zien. Uitgaande berichten blijven nog steeds niet bij inkomende berichten:
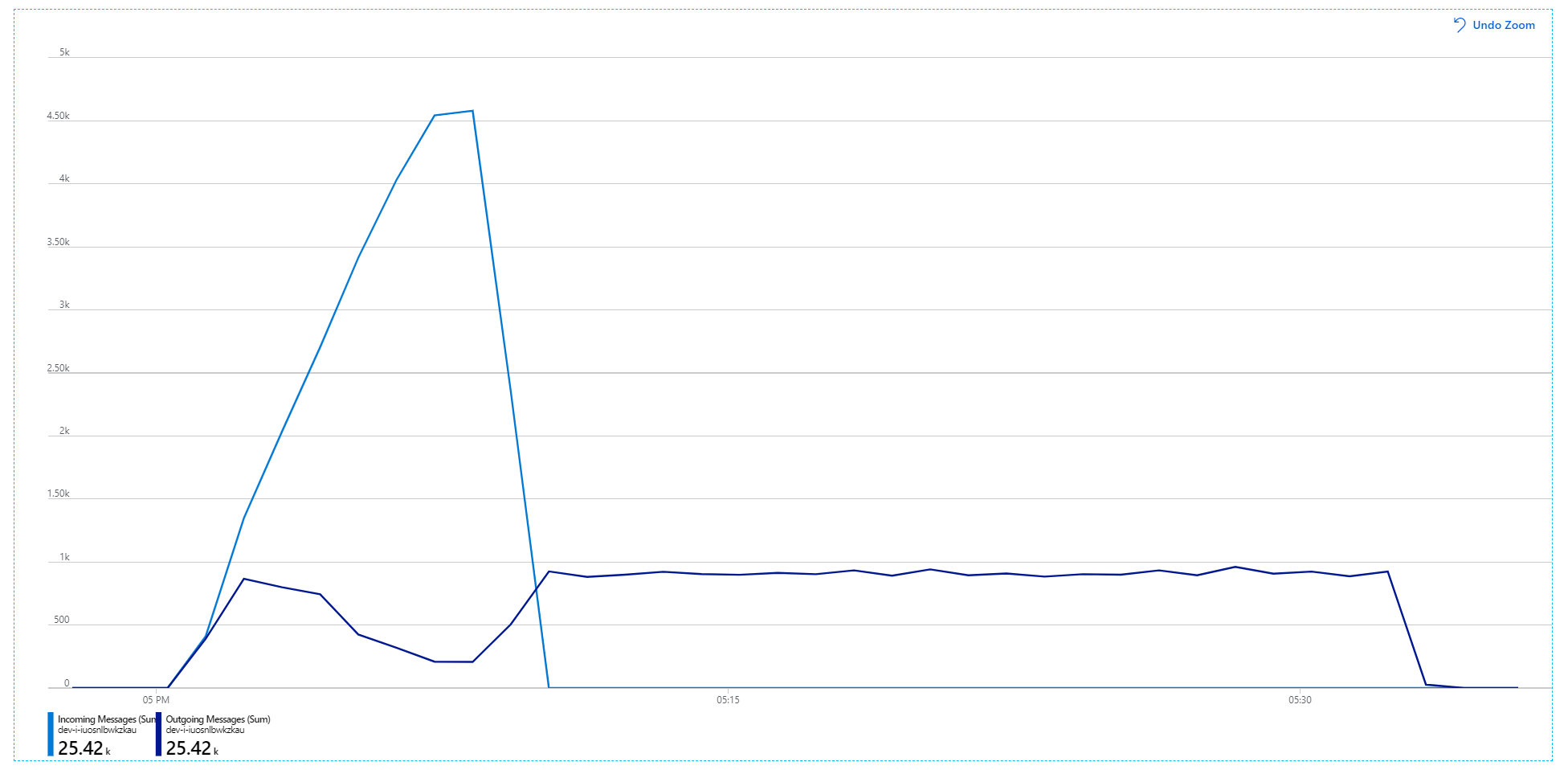
De doorvoer is consistenter, maar het maximum is ongeveer hetzelfde als bij de vorige test:
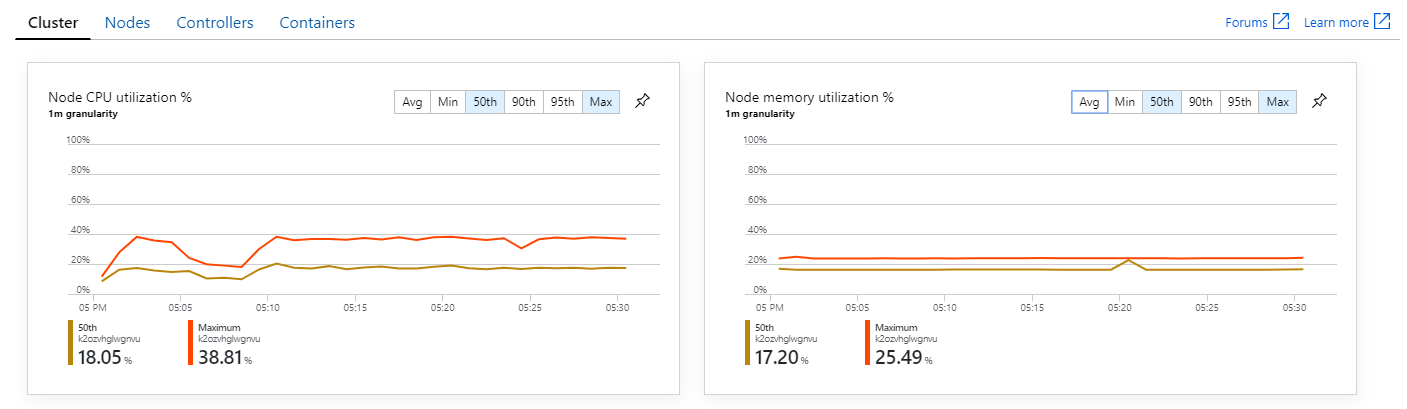
Bovendien lijkt het erop dat het probleem niet wordt veroorzaakt door resourceuitputting binnen het cluster als u azure Monitor container insights bekijkt. Ten eerste laten de metrische gegevens op knooppuntniveau zien dat het CPU-gebruik onder de 40% blijft, zelfs bij het 95e percentiel en dat het geheugengebruik ongeveer 20% is.
In een Kubernetes-omgeving is het mogelijk dat afzonderlijke pods resourcebeperkingen hebben, zelfs als de knooppunten dat niet zijn. Maar in de weergave op podniveau ziet u dat alle pods in orde zijn.
Uit deze test lijkt het erop dat het toevoegen van meer pods aan de back-end niet helpt. De volgende stap is om de werkstroomservice nauwkeuriger te bekijken om te begrijpen wat er gebeurt wanneer berichten worden verwerkt. Application Insights laat zien dat de gemiddelde duur van de bewerking van de werkstroomservice Process 246 ms is.
We kunnen ook een query uitvoeren om metrische gegevens op te halen over de afzonderlijke bewerkingen binnen elke transactie:
| Doel | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| levering | 37 | 57 |
| pakket | 12 | 17 |
| dronescheduler | 21 | 41 |
De eerste rij in deze tabel vertegenwoordigt de Service Bus-wachtrij. De andere rijen zijn de aanroepen naar de back-endservices. Ter referentie volgt de Log Analytics-query voor deze tabel:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
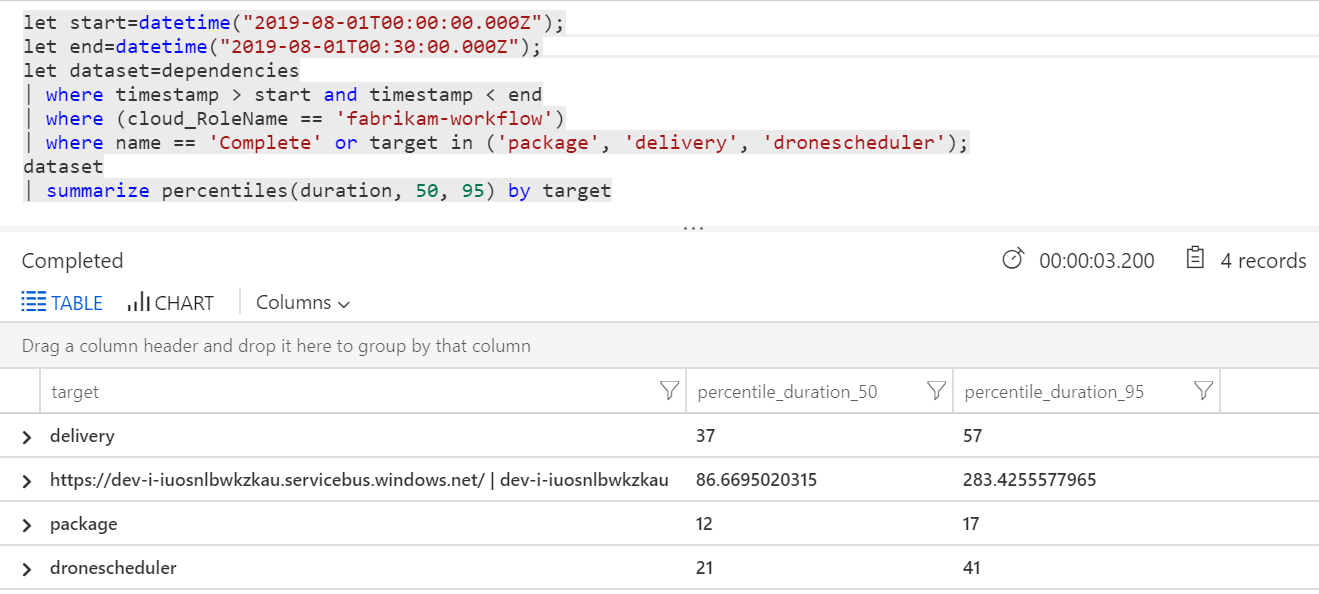
Deze latenties zien er redelijk uit. Maar dit is het belangrijkste inzicht: als de totale bewerkingstijd ~250 ms is, wordt hiermee een strikte bovengrens ingesteld voor hoe snel berichten serieel kunnen worden verwerkt. De sleutel tot het verbeteren van de doorvoer is daarom meer parallellisme.
Dat moet mogelijk zijn in dit scenario, om twee redenen:
- Dit zijn netwerkoproepen, dus de meeste tijd wordt besteed aan het wachten op I/O-voltooiing
- De berichten zijn onafhankelijk en hoeven niet op volgorde te worden verwerkt.
Test 4: Parallellisme verhogen
Voor deze test heeft het team zich gericht op het verhogen van parallelle uitvoering. Hiervoor hebben ze twee instellingen aangepast op de Service Bus-client die wordt gebruikt door de werkstroomservice:
| Instelling | Beschrijving | Standaard | Nieuwe waarde |
|---|---|---|---|
MaxConcurrentCalls |
Het maximum aantal berichten dat gelijktijdig moet worden verwerkt. | 1 | 20 |
PrefetchCount |
Hoeveel berichten de client van tevoren in de lokale cache ophaalt. | 0 | 3000 |
Zie Aanbevolen procedures voor prestatieverbeteringen met Service Bus Messaging voor meer informatie over deze instellingen. Het uitvoeren van de test met deze instellingen heeft de volgende grafiek opgeleverd:
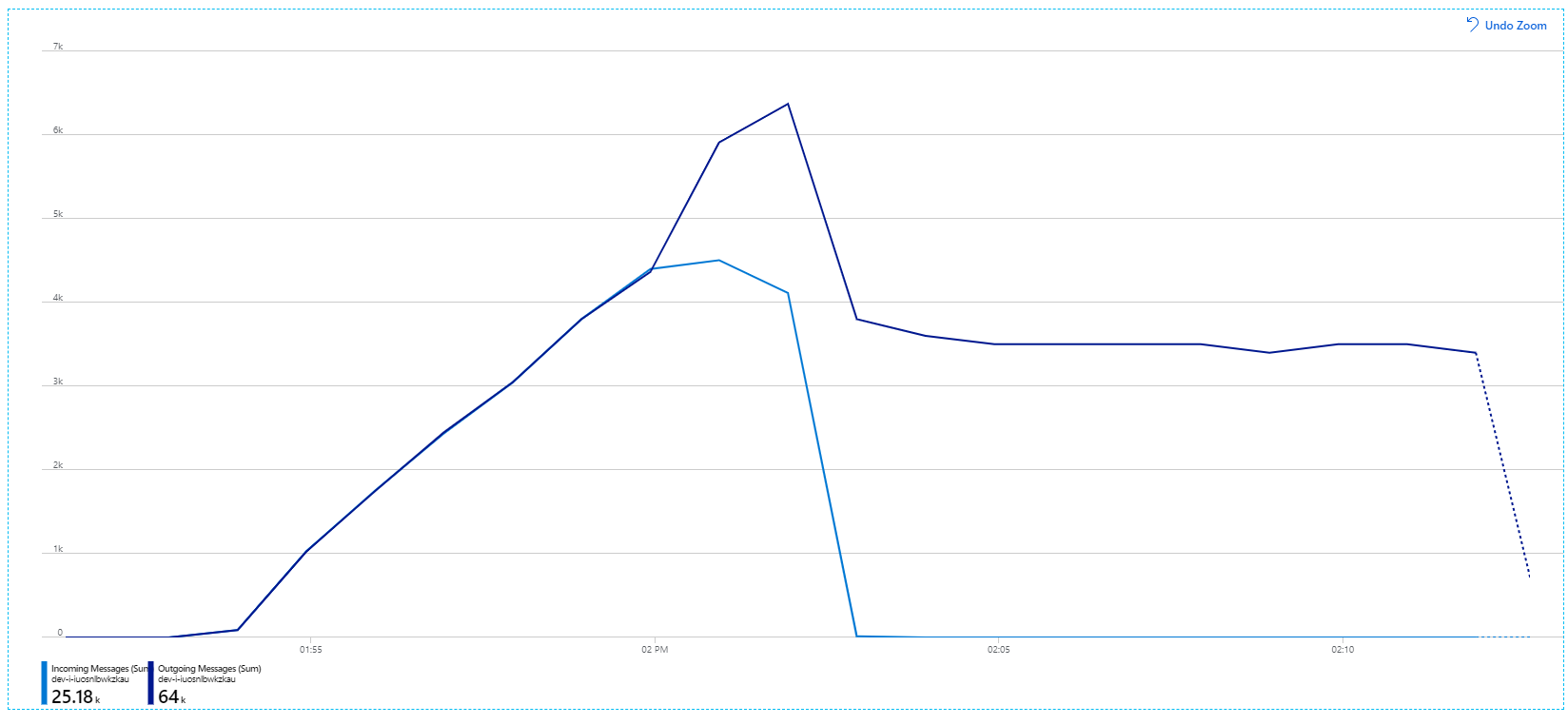
Zoals u zich nog herinnert, worden binnenkomende berichten weergegeven in lichtblauw en uitgaande berichten in donkerblauw.
Op het eerste gezicht is dit een heel vreemde grafiek. Gedurende een tijdje houdt de frequentie van uitgaande berichten exact het aantal binnenkomende berichten bij. Maar dan, rond de 2:03-markering, wordt de snelheid van binnenkomende berichten afgevlakken, terwijl het aantal uitgaande berichten blijft stijgen en in feite het totale aantal binnenkomende berichten overschrijdt. Dat lijkt onmogelijk.
De aanwijzing voor dit mysterie vindt u in de weergave Afhankelijkheden in Application Insights. Deze grafiek bevat een overzicht van alle aanroepen die de werkstroomservice heeft uitgevoerd naar Service Bus:
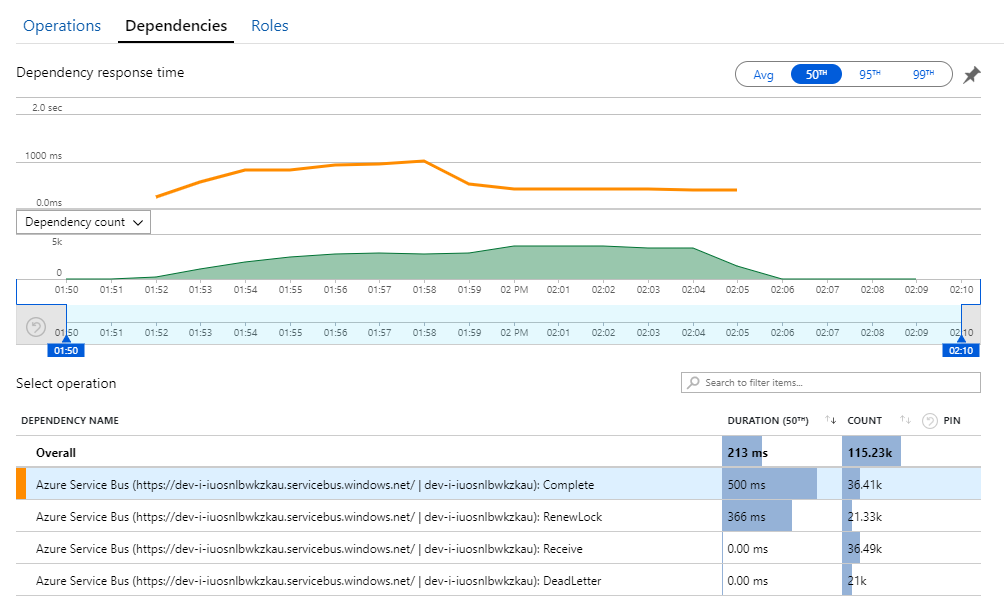
Let op die vermelding voor DeadLetter. Deze aanroepen geven aan dat berichten in de wachtrij met onbestelbare berichten van Service Bus worden geplaatst.
Als u wilt begrijpen wat er gebeurt, moet u de semantiek van Peek-Lock in Service Bus begrijpen. Wanneer een client Peek-Lock gebruikt, wordt een bericht atomisch opgehaald en vergrendeld door Service Bus. Terwijl de vergrendeling is vastgehouden, wordt het bericht gegarandeerd niet bezorgd bij andere ontvangers. Als de vergrendeling verloopt, wordt het bericht beschikbaar voor andere ontvangers. Na een maximum aantal bezorgingspogingen (dat kan worden geconfigureerd), plaatst Service Bus de berichten in een wachtrij met onbestelbare berichten, waar deze later kan worden onderzocht.
Houd er rekening mee dat de werkstroomservice grote batches berichten vooraf afhaalt( 3000 berichten tegelijk). Dit betekent dat de totale tijd voor het verwerken van elk bericht langer is, wat resulteert in een time-out van berichten, teruggaan naar de wachtrij en uiteindelijk in de wachtrij met onbestelbare berichten.
U kunt dit gedrag ook zien in de uitzonderingen, waarbij talrijke MessageLostLockException uitzonderingen worden vastgelegd:
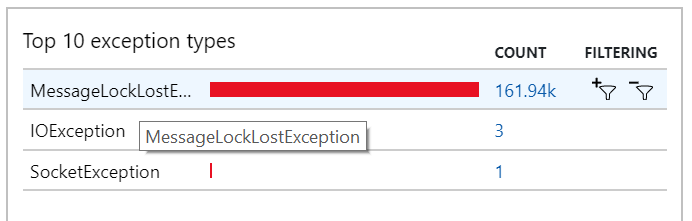
Test 5: Vergrendelingsduur verhogen
Voor deze belastingstest is de duur van de berichtvergrendeling ingesteld op 5 minuten, om time-outs van vergrendeling te voorkomen. De grafiek van binnenkomende en uitgaande berichten laat nu zien dat het systeem de snelheid van binnenkomende berichten bijhoudt:
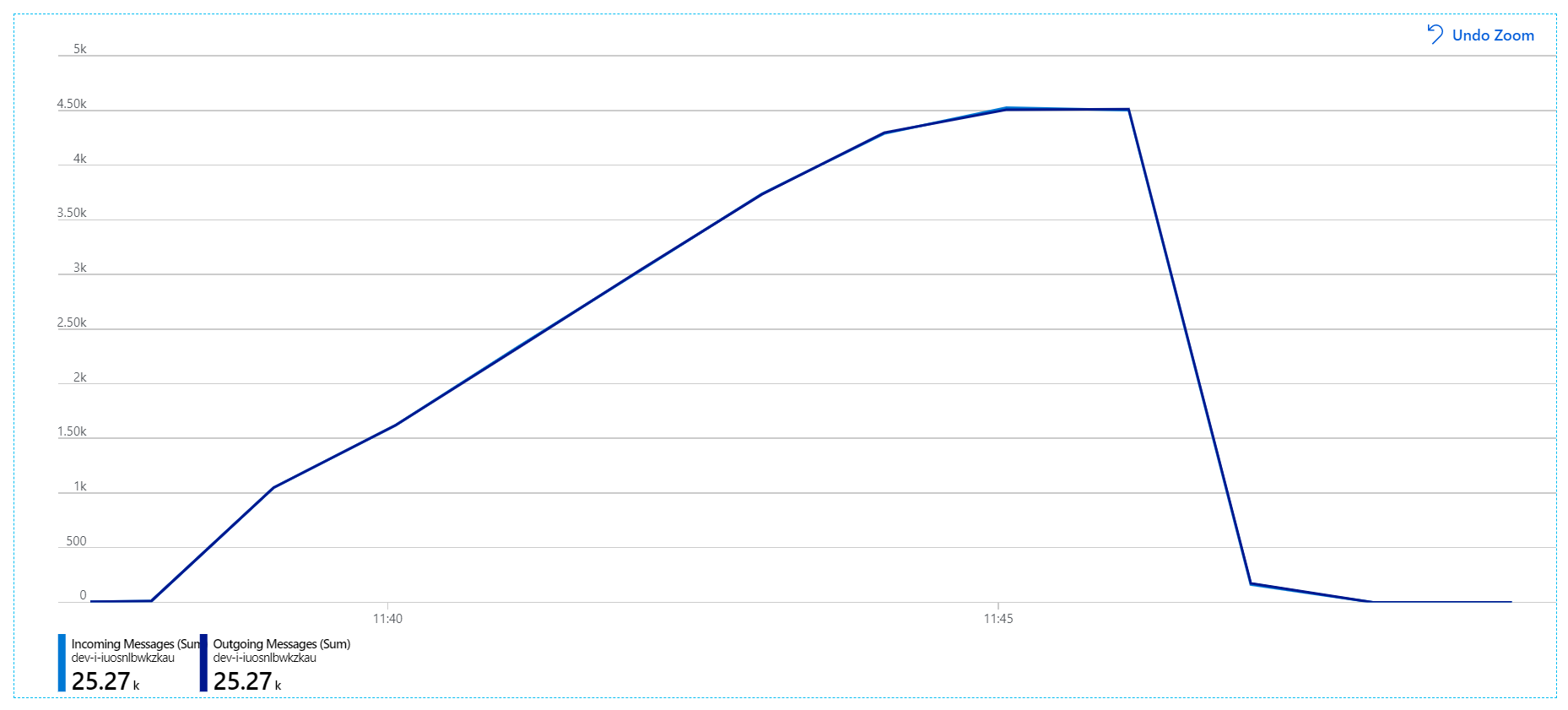
Gedurende de totale duur van de belastingstest van 8 minuten heeft de toepassing 25 K-bewerkingen voltooid, met een piekdoorvoer van 72 bewerkingen per seconde, wat een toename van 400% van de maximale doorvoer vertegenwoordigt.
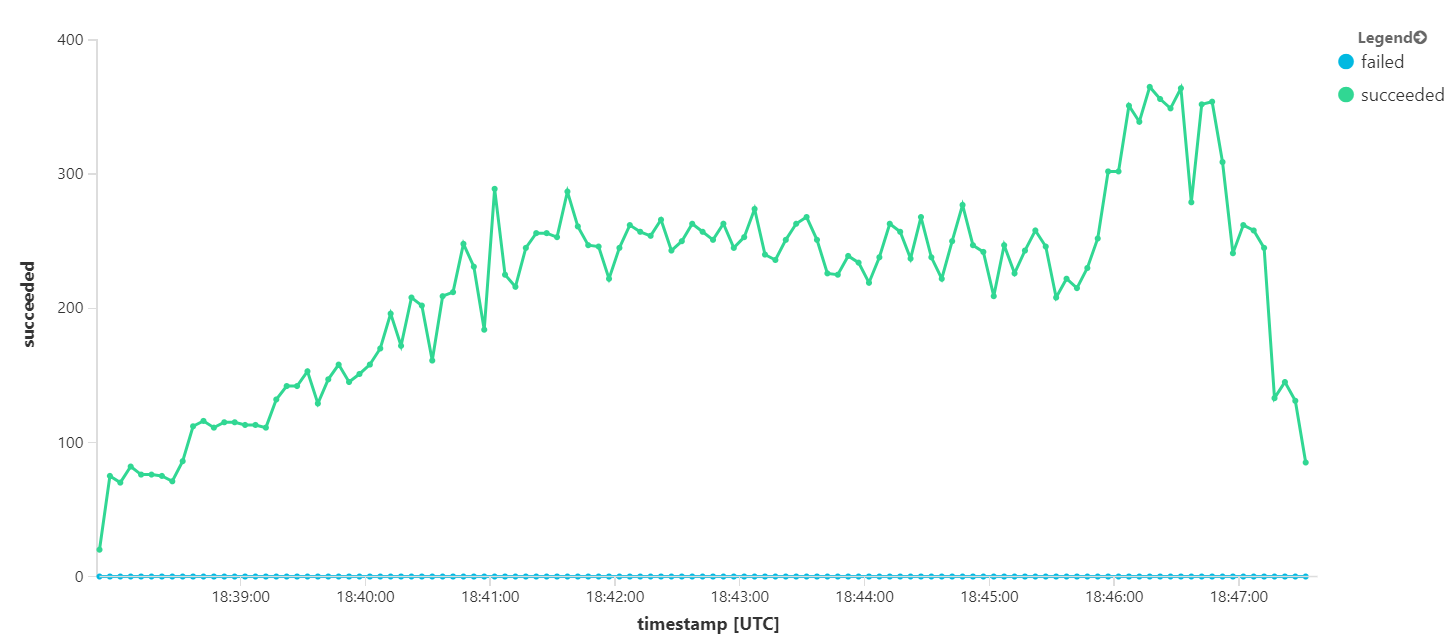
Uit het uitvoeren van dezelfde test met een langere duur bleek echter dat de toepassing deze snelheid niet kon ondersteunen:
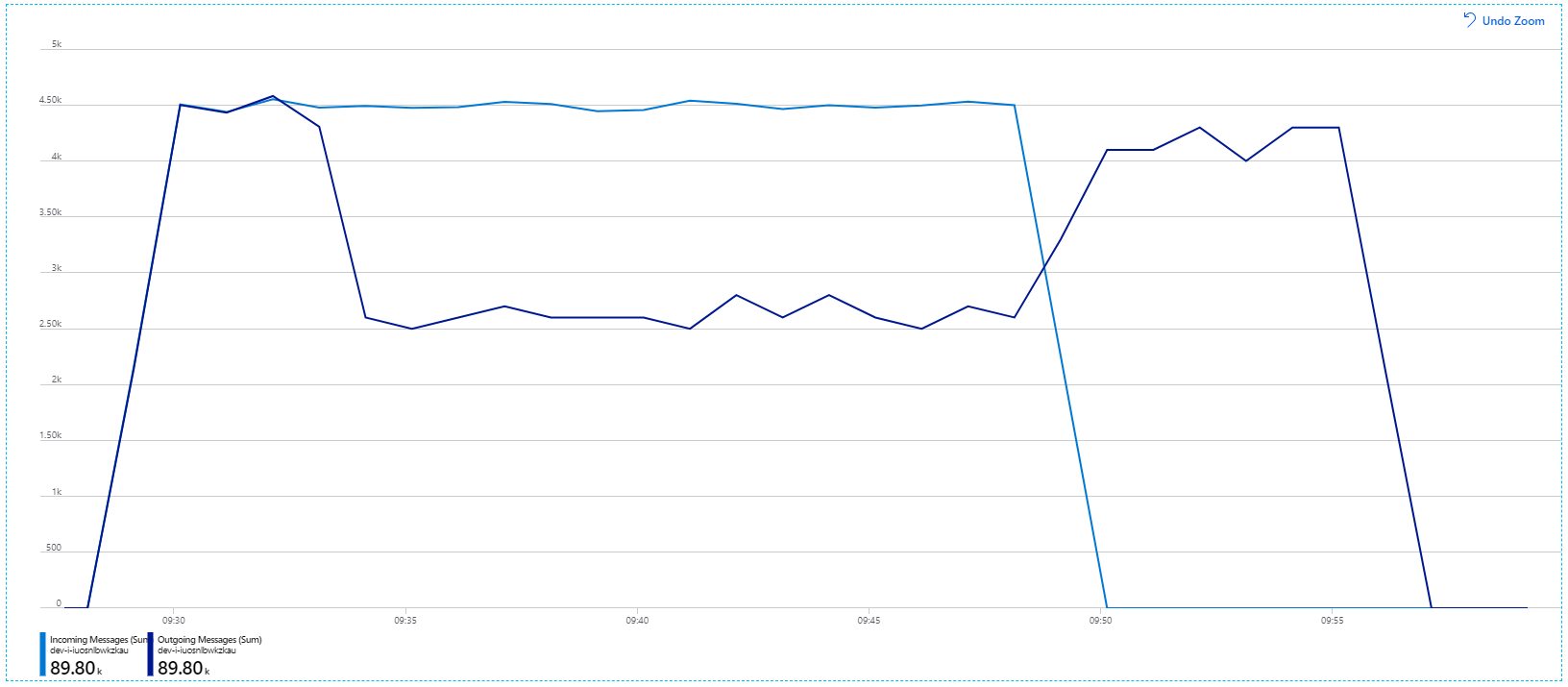
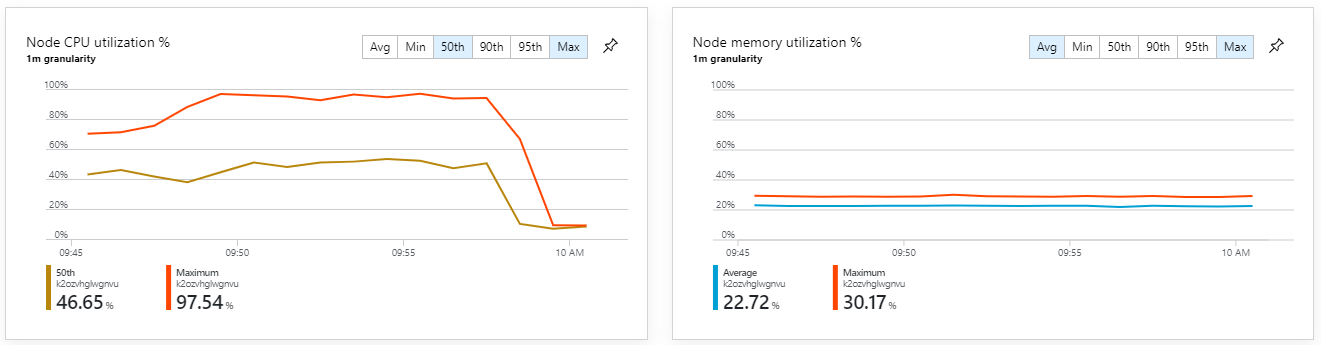
De metrische containergegevens laten zien dat het maximale CPU-gebruik bijna 100% was. Op dit moment lijkt de toepassing CPU-gebonden te zijn. Het schalen van het cluster kan de prestaties nu verbeteren, in tegenstelling tot de vorige poging om uit te schalen.
Test 6: De back-endservices (opnieuw) uitschalen
Voor de laatste belastingstest in de reeks heeft het team het Kubernetes-cluster en de pods als volgt uitgeschaald:
| Instelling | Waarde |
|---|---|
| Clusterknooppunten | 12 |
| Opnameservice | 3 replica's |
| Werkstroomservice | 6 replica's |
| Pakket, Levering, Drone Scheduler-services | Elk 9 replica's |
Deze test heeft geresulteerd in een hogere doorvoer, zonder aanzienlijke vertraging bij het verwerken van berichten. Bovendien bleef het CPU-gebruik van knooppunten lager dan 80%.
Samenvatting
Voor dit scenario zijn de volgende knelpunten geïdentificeerd:
- Uitzonderingen voor onvoldoende geheugen in Azure Cache voor Redis.
- Gebrek aan parallellisme in berichtverwerking.
- Onvoldoende duur van berichtvergrendeling, wat leidt tot time-outs voor vergrendeling en het plaatsen van berichten in de wachtrij met onbestelbare berichten.
- CPU-uitputting.
Om deze problemen vast te stellen, is het ontwikkelteam gebaseerd op de volgende metrische gegevens:
- De snelheid van inkomende en uitgaande Service Bus-berichten.
- Toepassingsoverzicht in Application Insights.
- Fouten en uitzonderingen.
- Aangepaste Log Analytics-query's.
- CPU- en geheugengebruik in Azure Monitor-container insights.
Volgende stappen
Zie Een microservicearchitectuur ontwerpen voor meer informatie over het ontwerp van dit scenario.