In dit artikel worden overwegingen beschreven voor het beheren van gegevens in een microservicesarchitectuur. Omdat elke microservice zijn eigen gegevens beheert, zijn gegevensintegriteit en gegevensconsistentie kritieke uitdagingen.
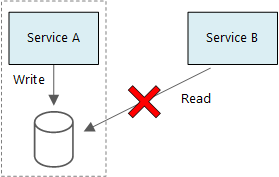
Een basisprincipe van microservices is dat elke service zijn eigen gegevens beheert. Twee services mogen geen gegevensarchief delen. In plaats daarvan is elke service verantwoordelijk voor een eigen privégegevensarchief, waartoe andere services geen rechtstreeks toegang hebben.
De reden voor deze regel is om onbedoelde koppeling tussen services te voorkomen, wat kan leiden als services dezelfde onderliggende gegevensschema's delen. Als er een wijziging in het gegevensschema is, moet de wijziging worden gecoördineerd voor elke service die afhankelijk is van die database. Door het gegevensarchief van elke service te isoleren, kunnen we het bereik van wijzigingen beperken en de flexibiliteit van echt onafhankelijke implementaties behouden. Een andere reden is dat elke microservice mogelijk zijn eigen gegevensmodellen, query's of lees-/schrijfpatronen heeft. Als u een gedeeld gegevensarchief gebruikt, beperkt u de mogelijkheid van elk team om de gegevensopslag voor hun specifieke service te optimaliseren.
Deze aanpak leidt natuurlijk tot polyglot persistence : het gebruik van meerdere technologieën voor gegevensopslag binnen één toepassing. Voor één service zijn mogelijk de schema-on-read-mogelijkheden van een documentdatabase vereist. Een andere heeft mogelijk de referentiële integriteit nodig die wordt geleverd door een RDBMS. Elk team is gratis om de beste keuze te maken voor hun service.
Notitie
Het is prima voor services om dezelfde fysieke databaseserver te delen. Het probleem treedt op wanneer services hetzelfde schema delen of naar dezelfde set databasetabellen lezen en schrijven.
Uitdagingen
Er zijn enkele uitdagingen op het gebied van deze gedistribueerde benadering voor het beheren van gegevens. Ten eerste kan er redundantie zijn in de gegevensarchieven, waarbij hetzelfde gegevensitem op meerdere plaatsen wordt weergegeven. Gegevens kunnen bijvoorbeeld worden opgeslagen als onderdeel van een transactie en vervolgens ergens anders worden opgeslagen voor analyse, rapportage of archivering. Gedupliceerde of gepartitioneerde gegevens kunnen leiden tot problemen met gegevensintegriteit en consistentie. Wanneer gegevensrelaties meerdere services omvatten, kunt u geen traditionele technieken voor gegevensbeheer gebruiken om de relaties af te dwingen.
Traditionele gegevensmodellering maakt gebruik van de regel 'één feit op één plaats'. Elke entiteit wordt precies één keer weergegeven in het schema. Andere entiteiten kunnen verwijzingen naar de entiteit bevatten, maar deze niet dupliceren. Het voor de hand liggende voordeel van de traditionele benadering is dat updates op één plek worden uitgevoerd, waardoor problemen met gegevensconsistentie worden voorkomen. In een microservicesarchitectuur moet u overwegen hoe updates worden doorgegeven in services en hoe u uiteindelijke consistentie kunt beheren wanneer gegevens op meerdere plaatsen worden weergegeven zonder sterke consistentie.
Benaderingen voor het beheren van gegevens
Er is geen enkele benadering die in alle gevallen juist is, maar hier volgen enkele algemene richtlijnen voor het beheren van gegevens in een microservicesarchitectuur.
Definieer het vereiste consistentieniveau per onderdeel en geef waar mogelijk de voorkeur aan uiteindelijke consistentie. Krijg inzicht in de plaatsen in het systeem waar u sterke consistentie of ACID-transacties nodig hebt, en de plaatsen waar uiteindelijke consistentie acceptabel is. Review Using tactische DDD to design microservices for further component guidance.
Wanneer u sterke consistentiegaranties nodig hebt, kan één service de bron van waarheid voor een bepaalde entiteit vertegenwoordigen, die beschikbaar wordt gesteld via een API. Andere services kunnen hun eigen kopie van de gegevens of een subset van de gegevens bevatten die uiteindelijk consistent zijn met de hoofdgegevens, maar die niet als de bron van waarheid worden beschouwd. Stel bijvoorbeeld een e-commercesysteem voor met een klantenservice en een aanbevelingsservice. De aanbevelingsservice luistert mogelijk naar gebeurtenissen van de orderservice, maar als een klant een restitutie aanvraagt, is het de orderservice, niet de aanbevelingsservice, die de volledige transactiegeschiedenis heeft.
Gebruik voor transacties patronen zoals Scheduler Agent Supervisor en Compenserende transactie om gegevens consistent te houden in verschillende services. Mogelijk moet u een extra stukje gegevens opslaan waarmee de status van een werkeenheid wordt vastgelegd die meerdere services omvat, om gedeeltelijke fouten tussen meerdere services te voorkomen. Houd bijvoorbeeld een werkitem in een duurzame wachtrij terwijl er een transactie met meerdere stappen wordt uitgevoerd.
Sla alleen de gegevens op die een service nodig heeft. Een service heeft mogelijk alleen een subset met informatie over een domeinentiteit nodig. In de context Verzendgrens moeten we bijvoorbeeld weten welke klant is gekoppeld aan een bepaalde levering. Maar we hebben het factuuradres van de klant niet nodig, dat wordt beheerd door de context Gebonden accounts. Als u goed nadenkt over het domein en een DDD-benadering gebruikt, kunt u hier helpen.
Overweeg of uw services coherent en losjes gekoppeld zijn. Als twee services voortdurend informatie met elkaar uitwisselen, wat resulteert in chatty API's, moet u mogelijk uw servicegrenzen opnieuw tekenen door twee services samen te voegen of hun functionaliteit te herstructureren.
Gebruik een architectuurstijl op basis van gebeurtenissen. In deze architectuurstijl publiceert een service een gebeurtenis wanneer er wijzigingen zijn in de openbare modellen of entiteiten. Geïnteresseerde services kunnen zich abonneren op deze gebeurtenissen. Een andere service kan bijvoorbeeld de gebeurtenissen gebruiken om een gerealiseerde weergave te maken van de gegevens die geschikter zijn voor het uitvoeren van query's.
Een service die eigenaar is van gebeurtenissen, moet een schema publiceren dat kan worden gebruikt om het serialiseren en deserialiseren van de gebeurtenissen te automatiseren, om een nauwe koppeling tussen uitgevers en abonnees te voorkomen. Overweeg het JSON-schema of een framework zoals Microsoft Bond, Protobuf of Avro.
Op grote schaal kunnen gebeurtenissen een knelpunt in het systeem worden, dus overweeg om aggregatie of batching te gebruiken om de totale belasting te verminderen.
Voorbeeld: Gegevensarchieven kiezen voor de Drone Delivery-toepassing
In de vorige artikelen in deze reeks wordt een droneleveringsservice besproken als een lopend voorbeeld. Meer informatie over het scenario en de bijbehorende referentie-implementatie vindt u hier. Dit voorbeeld is ideaal voor de luchtvaart- en luchtvaartindustrie.
Om samen te vatten definieert deze toepassing verschillende microservices voor het plannen van leveringen per drone. Wanneer een gebruiker een nieuwe levering plant, bevat de clientaanvraag informatie over de levering, zoals ophaal- en afleverlocaties, en over het pakket, zoals grootte en gewicht. Deze informatie definieert een werkeenheid.
De verschillende back-endservices geven om verschillende delen van de informatie in de aanvraag en hebben ook verschillende lees- en schrijfprofielen.
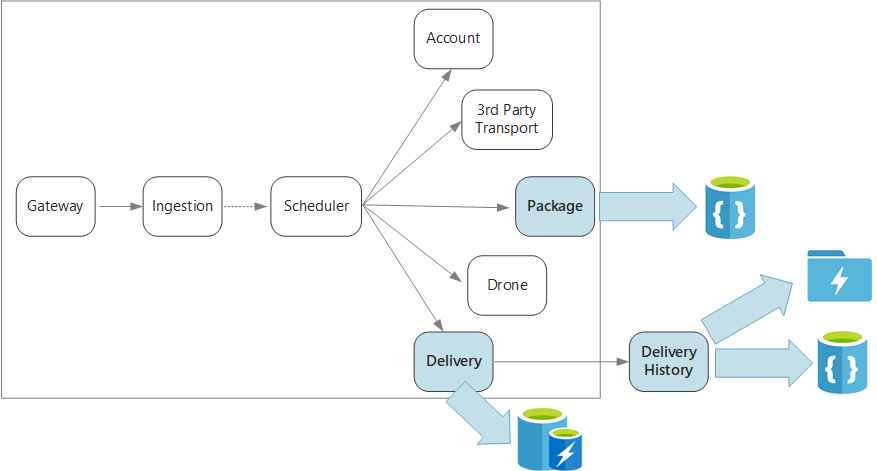
Leveringsservice
De Leveringsservice slaat informatie op over elke levering die momenteel wordt gepland of wordt uitgevoerd. Het luistert naar gebeurtenissen van de drones en houdt de status bij van leveringen die worden uitgevoerd. Er worden ook domeinevenementen met updates van de leveringsstatus verzonden.
Er wordt verwacht dat gebruikers regelmatig de status van een levering controleren terwijl ze wachten op hun pakket. De Delivery-service vereist daarom een gegevensarchief dat de doorvoer (lezen en schrijven) benadrukt via langetermijnopslag. De Delivery-service voert ook geen complexe query's of analyses uit, maar haalt gewoon de meest recente status voor een bepaalde levering op. Het Delivery Service-team heeft Azure Cache voor Redis gekozen voor de hoge lees-schrijfprestaties. De informatie die in Redis is opgeslagen, is relatief kort. Zodra een levering is voltooid, is de Leveringsgeschiedenisservice het systeem van record.
Leveringsgeschiedenisservice
De Delivery History-service luistert naar gebeurtenissen van de leveringsstatus van de Leveringsservice. Deze gegevens worden opgeslagen in langetermijnopslag. Er zijn twee verschillende gebruiksvoorbeelden voor deze historische gegevens, die verschillende vereisten voor gegevensopslag hebben.
Het eerste scenario is het samenvoegen van de gegevens voor gegevensanalyse om het bedrijf te optimaliseren of de kwaliteit van de service te verbeteren. Houd er rekening mee dat de Delivery History-service de werkelijke analyse van de gegevens niet uitvoert. Het is alleen verantwoordelijk voor de opname en opslag. Voor dit scenario moet de opslag worden geoptimaliseerd voor gegevensanalyse via een grote set gegevens, met behulp van een schema-on-read-benadering voor een verscheidenheid aan gegevensbronnen. Azure Data Lake Store is geschikt voor dit scenario. Data Lake Store is een Apache Hadoop-bestandssysteem dat compatibel is met Hadoop Distributed File System (HDFS) en is afgestemd op prestaties voor gegevensanalysescenario's.
In het andere scenario kunnen gebruikers de geschiedenis van een levering opzoeken nadat de levering is voltooid. Azure Data Lake is niet geoptimaliseerd voor dit scenario. Voor optimale prestaties raadt Microsoft aan tijdreeksgegevens op te slaan in Data Lake in mappen die zijn gepartitioneerd op datum. (Zie Azure Data Lake Store afstemmen op prestaties). Deze structuur is echter niet optimaal voor het opzoeken van afzonderlijke records op id. Tenzij u ook de tijdstempel kent, moet de volledige verzameling worden gescand door een zoekactie op id. De Delivery History-service slaat daarom ook een subset op van de historische gegevens in Azure Cosmos DB voor snellere zoekopdrachten. De records hoeven niet voor onbepaalde tijd in Azure Cosmos DB te blijven. Oudere leveringen kunnen na een maand worden gearchiveerd. Dit kan worden gedaan door een incidenteel batchproces uit te voeren. Het archiveren van oudere gegevens kan de kosten voor Cosmos DB verlagen terwijl de gegevens nog steeds beschikbaar blijven voor historische rapportage vanuit Data Lake.
Pakketservice
De pakketservice slaat informatie over alle pakketten op. De opslagvereisten voor het pakket zijn:
- Langetermijnopslag.
- Kan een groot aantal pakketten verwerken, waarvoor een hoge schrijfdoorvoer is vereist.
- Ondersteuning voor eenvoudige query's op pakket-id. Geen complexe joins of vereisten voor referentiële integriteit.
Omdat de pakketgegevens niet relationeel zijn, is een documentgerichte database geschikt en kan Azure Cosmos DB een hoge doorvoer bereiken met behulp van shardverzamelingen. Het team dat in de Package-service werkt, is bekend met de MEAN-stack (MongoDB, Express.js, AngularJS en Node.js), zodat ze de MongoDB-API voor Azure Cosmos DB selecteren. Hierdoor kunnen ze gebruikmaken van hun bestaande ervaring met MongoDB, terwijl ze profiteren van de voordelen van Azure Cosmos DB, een beheerde Azure-service.
Volgende stappen
Meer informatie over ontwerppatronen die u kunnen helpen bij het beperken van enkele veelvoorkomende uitdagingen in een microservicesarchitectuur.