Gegevensopslagmodellen begrijpen
Moderne bedrijfssystemen beheren steeds grotere hoeveelheden heterogene gegevens. Deze heterogeniteit betekent dat één gegevensarchief meestal niet de beste aanpak is. In plaats daarvan is het vaak beter om verschillende typen gegevens op te slaan in verschillende gegevensarchieven, elk gericht op een specifieke workload of een specifiek gebruikspatroon. De term polyglot persistence wordt gebruikt om oplossingen te beschrijven die gebruikmaken van een combinatie van technologieën voor gegevensopslag. Daarom is het belangrijk om inzicht te hebben in de belangrijkste opslagmodellen en hun compromissen.
Het selecteren van het juiste gegevensarchief voor uw vereisten is een belangrijke ontwerpbeslissing. Er zijn letterlijk honderden implementaties waaruit u kunt kiezen tussen SQL- en NoSQL-databases. Gegevensarchieven worden vaak gecategoriseerd op basis van de structuur van gegevens en de typen bewerkingen die ze ondersteunen. In dit artikel worden verschillende van de meest voorkomende opslagmodellen beschreven. Houd er rekening mee dat een bepaalde technologie voor gegevensopslag meerdere opslagmodellen kan ondersteunen. Een relationele databasebeheersystemen (RDBMS) ondersteunt bijvoorbeeld ook sleutel-/waarde- of grafiekopslag. In feite is er een algemene trend voor zogenaamde multimodel ondersteuning, waarbij één databasesysteem meerdere modellen ondersteunt. Maar het is nog steeds handig om de verschillende modellen op hoog niveau te begrijpen.
Niet alle gegevensarchieven in een bepaalde categorie bieden dezelfde functieset. De meeste gegevensarchieven bieden functionaliteit aan de serverzijde om gegevens op te vragen en te verwerken. Soms is deze functionaliteit ingebouwd in de engine voor gegevensopslag. In andere gevallen worden de mogelijkheden voor gegevensopslag en -verwerking gescheiden en zijn er mogelijk verschillende opties voor verwerking en analyse. Gegevensarchieven ondersteunen ook verschillende programmatische en beheerinterfaces.
Over het algemeen moet u eerst overwegen welk opslagmodel het meest geschikt is voor uw vereisten. Overweeg vervolgens een bepaald gegevensarchief binnen die categorie, op basis van factoren zoals functieset, kosten en beheergemak.
Notitie
In het Microsoft Cloud Adoption Framework voor Azurevindt u meer informatie over het identificeren en controleren van uw vereisten voor de gegevensservice voor cloudimplementatie. Op dezelfde manier kunt u ook meer te weten komen over het selecteren van opslaghulpprogramma's en -services.
Relationele databasebeheersystemen
Relationele databases organiseren gegevens als een reeks tweedimensionale tabellen met rijen en kolommen. De meeste leveranciers bieden een dialect van de Structured Query Language (SQL) voor het ophalen en beheren van gegevens. Een RDBMS implementeert doorgaans een transactioneel consistent mechanisme dat voldoet aan het ACID-model (Atomic, Consistent, Isolated, Durable) voor het bijwerken van informatie.
Een RDBMS ondersteunt doorgaans een schema-on-write-model, waarbij de gegevensstructuur van tevoren wordt gedefinieerd en alle lees- of schrijfbewerkingen moeten het schema gebruiken.
Dit model is zeer nuttig wanneer sterke consistentiegaranties belangrijk zijn, waarbij alle wijzigingen atomisch zijn en transacties altijd de gegevens in een consistente status achterlaten. Een RDBMS kan echter over het algemeen niet horizontaal worden uitgeschaald zonder de gegevens op een of andere manier te sharden. De gegevens in een RDBMS moeten ook worden genormaliseerd, wat niet geschikt is voor elke gegevensset.
Azure services
- Azure SQL Database | (beveiligingsbasislijn)
- Azure Database for MySQL- | (beveiligingsbasislijn)
- Azure Database for PostgreSQL- | (beveiligingsbasislijn)
- Azure Database for MariaDB | (beveiligingsbasislijn)
Werkdruk
- Records worden regelmatig gemaakt en bijgewerkt.
- Er moeten meerdere bewerkingen worden uitgevoerd in één transactie.
- Relaties worden afgedwongen met behulp van databasebeperkingen.
- Indexen worden gebruikt om queryprestaties te optimaliseren.
Gegevenstype
- Gegevens worden sterk genormaliseerd.
- Databaseschema's zijn vereist en afgedwongen.
- Veel-op-veel-relaties tussen gegevensentiteiten in de database.
- Beperkingen worden gedefinieerd in het schema en opgelegd aan gegevens in de database.
- Voor gegevens is een hoge integriteit vereist. Indexen en relaties moeten nauwkeurig worden bijgehouden.
- Voor gegevens is een sterke consistentie vereist. Transacties werken op een manier die ervoor zorgt dat alle gegevens 100% consistent zijn voor alle gebruikers en processen.
- De grootte van afzonderlijke gegevensvermeldingen is klein tot middelgroot.
Voorbeelden
- Voorraadbeheer
- Orderbeheer
- Rapportagedatabase
- Boekhouding
Sleutel/waarde opslag
Een sleutel-/waardearchief koppelt elke gegevenswaarde aan een unieke sleutel. De meeste key/value stores ondersteunen alleen eenvoudige bewerkingen voor opvragen, invoegen en verwijderen. Als u een waarde (gedeeltelijk of volledig) wilt wijzigen, moet een toepassing de bestaande gegevens voor de gehele waarde overschrijven. In de meeste implementaties is het lezen of schrijven van één waarde een atomische bewerking.
Een toepassing kan willekeurige gegevens opslaan als een set waarden. Alle schemagegevens moeten door de toepassing worden verstrekt. In het sleutel-/waardearchief wordt de waarde op basis van de sleutel opgehaald of opgeslagen.
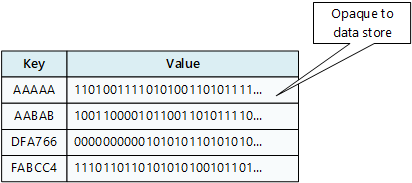
Sleutel-/waardearchieven zijn sterk geoptimaliseerd voor toepassingen die eenvoudige zoekopdrachten uitvoeren, maar zijn minder geschikt als u gegevens in verschillende sleutel-/waardearchieven moet opvragen. Sleutel-/waardearchieven zijn ook niet geoptimaliseerd voor het uitvoeren van query's op waarde.
Eén sleutel/waardearchief kan zeer schaalbaar zijn, omdat het gegevensarchief eenvoudig gegevens kan distribueren over meerdere knooppunten op afzonderlijke computers.
Azure services
- Azure Cosmos DB for Table en Azure Cosmos DB for NoSQL | (Azure Cosmos DB Security Baseline)
- Azure Cache voor Redis | (beveiligingsbasislijn)
- Azure Table Storage- | (beveiligingsbasislijn)
Werkdruk
- Gegevens worden geopend met één sleutel, zoals een woordenlijst.
- Er zijn geen joins, vergrendelingen of samenvoegingen vereist.
- Er worden geen aggregatiemechanismen gebruikt.
- Secundaire indexen worden over het algemeen niet gebruikt.
Gegevenstype
- Elke sleutel is gekoppeld aan één waarde.
- Er is geen schema-afdwinging.
- Geen relaties tussen entiteiten.
Voorbeelden
- Gegevens opslaan in cache
- Sessiebeheer
- Gebruikersvoorkeur en profielbeheer
- Productaanbieding en advertentieaanbieding
Document databases
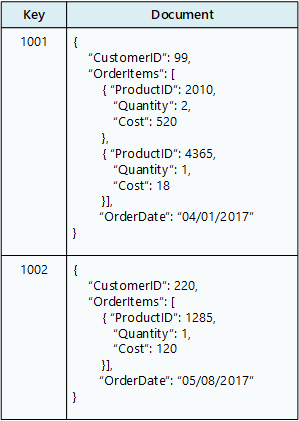
In een documentdatabase wordt een verzameling documentenopgeslagen, waarbij elk document bestaat uit benoemde velden en gegevens. De gegevens kunnen eenvoudige waarden of complexe elementen zijn, zoals lijsten en subverzamelingen. Documenten worden opgehaald met unieke sleutels.
Normaal gesproken bevat een document de gegevens voor één entiteit, zoals een klant of een order. Een document kan informatie bevatten die zou worden verspreid over verschillende relationele tabellen in een RDBMS. Documenten hoeven niet dezelfde structuur te hebben. Toepassingen kunnen verschillende gegevens opslaan in documenten wanneer de bedrijfsvereisten veranderen.
Azure service
Werkdruk
- Invoeg- en updatebewerkingen zijn gebruikelijk.
- Geen object-relationele impedantie komt niet overeen. Documenten kunnen beter overeenkomen met de objectstructuren die worden gebruikt in toepassingscode.
- Afzonderlijke documenten worden opgehaald en geschreven als één blok.
- Voor gegevens is index voor meerdere velden vereist.
Gegevenstype
- Gegevens kunnen op een niet-genormaliseerde manier worden beheerd.
- De grootte van afzonderlijke documentgegevens is relatief klein.
- Elk documenttype kan een eigen schema gebruiken.
- Documenten kunnen optionele velden bevatten.
- Documentgegevens zijn semi-gestructureerd, wat betekent dat gegevenstypen van elk veld niet strikt zijn gedefinieerd.
Voorbeelden
- Productcatalogus
- Inhoudsbeheer
- Voorraadbeheer
Grafiekdatabases
In een grafiekdatabase worden twee soorten informatie, knooppunten en randen opgeslagen. Randen geven relaties tussen knooppunten op. Knooppunten en randen kunnen eigenschappen hebben die informatie bieden over dat knooppunt of die rand, vergelijkbaar met kolommen in een tabel. Randen kunnen ook een richting hebben die de aard van de relatie aangeeft.
Grafiekdatabases kunnen efficiënt query's uitvoeren in het netwerk van knooppunten en randen en de relaties tussen entiteiten analyseren. In het volgende diagram ziet u de personeelsdatabase van een organisatie die is gestructureerd als een grafiek. De entiteiten zijn werknemers en afdelingen en de randen geven rapportagerelaties en de afdelingen waarin werknemers werken aan.
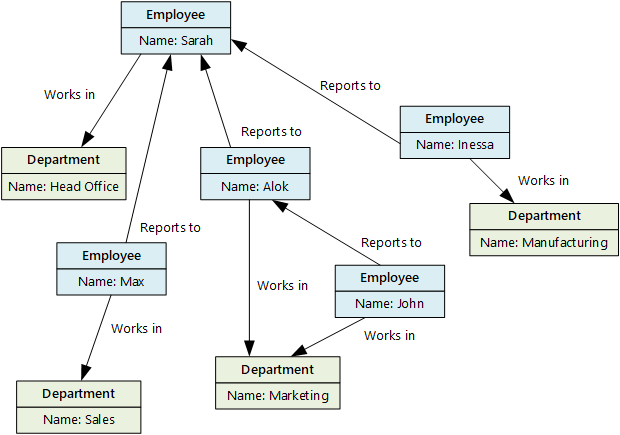
Deze structuur maakt het eenvoudig om query's uit te voeren zoals 'Zoek alle werknemers die direct of indirect rapporteren aan Sarah' of 'Wie werkt op dezelfde afdeling als John?' Voor grote grafieken met veel entiteiten en relaties kunt u zeer snel zeer complexe analyses uitvoeren. Veel grafiekdatabases bieden een querytaal die u kunt gebruiken om een netwerk van relaties efficiënt te doorlopen.
Azure services
- Azure Cosmos DB voor Apache Gremlin- | (beveiligingsbasislijn)
- SQL Server- | (beveiligingsbasislijn)
Werkdruk
- Complexe relaties tussen gegevensitems met veel hops tussen gerelateerde gegevensitems.
- De relatie tussen gegevensitems is dynamisch en verandert in de loop van de tijd.
- Relaties tussen objecten zijn eersteklas burgers, zonder dat er refererende sleutels en joins nodig zijn om door te gaan.
Gegevenstype
- Knooppunten en relaties.
- Knooppunten zijn vergelijkbaar met tabelrijen of JSON-documenten.
- Relaties zijn net zo belangrijk als knooppunten en worden rechtstreeks in de querytaal weergegeven.
- Samengestelde objecten, zoals een persoon met meerdere telefoonnummers, worden meestal onderverdeeld in afzonderlijke, kleinere knooppunten, gecombineerd met doorkruisbare relaties
Voorbeelden
- Organigrammen
- Sociale grafieken
- Fraudedetectie
- Aanbevelingsengines
Gegevensanalyse
Gegevensanalysearchieven bieden zeer parallelle oplossingen voor het opnemen, opslaan en analyseren van gegevens. De gegevens worden verdeeld over meerdere servers om de schaalbaarheid te maximaliseren. Grote gegevensbestandsindelingen, zoals CSV-bestanden (scheidingstekens), parquet-en ORC- worden veel gebruikt in gegevensanalyse. Historische gegevens worden doorgaans opgeslagen in dataopslagplaatsen zoals blob-opslag of Azure Data Lake Storage Gen2, die vervolgens als externe tabellen door Azure Synapse, Databricks of HDInsight worden benaderd. Een typisch scenario waarin gegevens worden gebruikt die zijn opgeslagen als Parquet-bestanden voor prestaties, wordt beschreven in het artikel Externe tabellen gebruiken met Synapse SQL.
Azure services
- Azure Synapse Analytics- | (beveiligingsbasislijn)
- Azure Data Lake | (beveiligingsbasislijn)
- Azure Data Explorer- | (beveiligingsbasislijn)
- Azure Analysis Services-
- HDInsight- | (beveiligingsbasislijn)
- Azure Databricks- | (beveiligingsbasislijn)
Werkdruk
- Gegevensanalyse
- Enterprise Business Intelligence
Gegevenstype
- Historische gegevens uit meerdere bronnen.
- Normaal gesproken gedenormaliseerd in een 'ster' of 'sneeuwvlok'-schema, bestaande uit feiten- en dimensietabellen.
- Meestal geladen met nieuwe gegevens op geplande basis.
- Dimensietabellen bevatten vaak meerdere historische versies van een entiteit, aangeduid als een langzaam veranderende dimensie.
Voorbeelden
- Enterprise datawarehouse
Kolomfamiliedatabases
Een kolomfamiliedatabase ordent gegevens in rijen en kolommen. In de eenvoudigste vorm kan een kolomfamiliedatabase op zijn minst op een relationele database lijken. De echte kracht van een kolomfamiliedatabase ligt in de gedenormaliseerde benadering van het structureren van sparse-gegevens.
U kunt een kolomfamiliedatabase beschouwen als het opslaan van tabelgegevens met rijen en kolommen, maar de kolommen zijn onderverdeeld in groepen die bekend staan als kolomfamilies. Elke kolomfamilie bevat een set kolommen die logisch aan elkaar zijn gerelateerd en die doorgaans worden opgehaald of bewerkt als een eenheid. Andere gegevens die afzonderlijk worden geopend, kunnen worden opgeslagen in afzonderlijke kolomfamilies. Binnen een kolomfamilie kunnen nieuwe kolommen dynamisch worden toegevoegd en rijen kunnen worden geparseerd (een rij hoeft dus geen waarde te hebben voor elke kolom).
In het volgende diagram ziet u een voorbeeld met twee kolomfamilies, Identity en Contact Info. De gegevens voor een entiteit hebben dezelfde row key in elke kolomfamilie. Deze structuur, waarbij de rijen voor een bepaald object in een kolomfamilie dynamisch kunnen variëren, is een belangrijk voordeel van de kolomfamiliebenadering, waardoor deze vorm van gegevensarchief zeer geschikt is voor het opslaan van gestructureerde, vluchtige gegevens.

In tegenstelling tot een sleutel-/waardearchief of een documentdatabase slaan de meeste kolomfamiliedatabases gegevens op in sleutelvolgorde in plaats van door een hash te berekenen. Met veel implementaties kunt u indexen maken voor specifieke kolommen in een kolomfamilie. Met indexen kunt u gegevens ophalen op basis van kolomwaarden in plaats van de rijsleutel.
Lees- en schrijfbewerkingen voor een rij zijn meestal atomisch met één kolomfamilie, hoewel sommige implementaties atomiciteit bieden in de hele rij, die meerdere kolomfamilies omvatten.
Azure services
- Azure Cosmos DB voor Apache Cassandra- | (beveiligingsbasislijn)
- HBase in HDInsight | (beveiligingsbasislijn)
Werkdruk
- De meeste kolomfamiliedatabases voeren schrijfbewerkingen zeer snel uit.
- Update- en verwijderbewerkingen zijn zeldzaam.
- Ontworpen om hoge doorvoer en toegang met lage latentie te bieden.
- Ondersteunt eenvoudige querytoegang tot een bepaalde set velden binnen een veel grotere record.
- Zeer schaalbaar.
Gegevenstype
- Gegevens worden opgeslagen in tabellen die bestaan uit een sleutelkolom en een of meer kolomfamilies.
- Specifieke kolommen kunnen variëren per afzonderlijke rijen.
- Afzonderlijke cellen worden geopend via get- en put-opdrachten
- Meerdere rijen worden geretourneerd met behulp van een scanopdracht.
Voorbeelden
- Aanbevelingen
- Personalisatie
- Sensorgegevens
- Telemetrie
- Messaging
- Analyse van sociale media
- Webanalyse
- Activiteitenbewaking
- Weer- en andere tijdreeksgegevens
Zoekprogrammadatabases
Met een zoekmachinedatabase kunnen toepassingen zoeken naar informatie die is opgeslagen in externe gegevensarchieven. Een zoekmachinedatabase kan enorme hoeveelheden gegevens indexeren en bijna realtime toegang bieden tot deze indexen.
Indexen kunnen multidimensionaal zijn en kunnen ondersteuning bieden voor zoekopdrachten in vrije tekst in grote hoeveelheden tekstgegevens. Indexering kan worden uitgevoerd met behulp van een pull-model, geactiveerd door de zoekmachinedatabase of met behulp van een pushmodel, geïnitieerd door externe toepassingscode.
Zoeken kan exact of fuzzy zijn. Een fuzzy zoekopdracht zoekt documenten die overeenkomen met een set termen en berekent hoe nauwkeurig deze overeenkomen. Sommige zoekmachines ondersteunen ook taalkundige analyses die overeenkomsten kunnen retourneren op basis van synoniemen, generieke uitbreidingen (bijvoorbeeld overeenkomende dogs met pets) en afleidingen (overeenkomende woorden met dezelfde stam).
Azure service
Werkdruk
- Gegevensindexen uit meerdere bronnen en services.
- Queries zijn ad-hoc en kunnen complex zijn.
- Zoeken in volledige tekst is vereist.
- Ad hoc zelfbedieningsquery is vereist.
Gegevenstype
- Semi-gestructureerde of ongestructureerde tekst
- Tekst met verwijzing naar gestructureerde gegevens
Voorbeelden
- Productcatalogi
- Site zoeken
- Logboekregistratie
Tijdreeksdatabases
Tijdreeksgegevens zijn een set waarden die zijn geordend op tijd. Tijdreeksdatabases verzamelen doorgaans grote hoeveelheden gegevens in realtime uit een groot aantal bronnen. Updates zijn zeldzaam en verwijderingen worden vaak uitgevoerd als bulkbewerkingen. Hoewel de records die naar een tijdreeksdatabase zijn geschreven, over het algemeen klein zijn, zijn er vaak een groot aantal records en kan de totale gegevensgrootte snel toenemen.
Azure service
Werkdruk
- Records worden over het algemeen opeenvolgend in tijdsvolgorde toegevoegd.
- Een overweldigend deel van de bewerkingen (95-99%) zijn schrijfbewerkingen.
- Updates zijn zeldzaam.
- Verwijderingen worden bulksgewijs uitgevoerd en worden gemaakt in aaneengesloten blokken of records.
- Gegevens worden opeenvolgend gelezen in oplopende of aflopende tijdsvolgorde, vaak parallel.
Gegevenstype
- Een tijdstempel wordt gebruikt als de primaire sleutel en het sorteermechanisme.
- Tags kunnen aanvullende informatie definiëren over het type, de oorsprong en andere informatie over de vermelding.
Voorbeelden
- Bewaking en gebeurtenistelemetrie.
- Sensor- of andere IoT-gegevens.
Objectopslag
Objectopslag is geoptimaliseerd voor het opslaan en ophalen van grote binaire objecten (afbeeldingen, bestanden, video- en audiostreams, grote toepassingsgegevensobjecten en documenten, schijfinstallatiekopieën van virtuele machines). Grote gegevensbestanden worden ook populair gebruikt in dit model, bijvoorbeeld bestand met scheidingstekens (CSV), parquet-en ORC-. Objectarchieven kunnen zeer grote hoeveelheden ongestructureerde gegevens beheren.
Azure-service
- Azure Blob Storage- | (beveiligingsbasislijn)
- Azure Data Lake Storage Gen2- | (beveiligingsbasislijn)
Werkdruk
- Geïdentificeerd door sleutel.
- Inhoud is doorgaans een element, zoals een scheidingsteken, afbeelding of videobestand.
- Inhoud moet duurzaam en extern zijn voor elke toepassingslaag.
Gegevenstype
- De gegevensgrootte is groot.
- Waarde is ondoorzichtig.
Voorbeelden
- Afbeeldingen, video's, office-documenten, PDF-bestanden
- Statische HTML, JSON, CSS
- Logboek- en auditbestanden
- Database-backups
Gedeelde bestanden
Soms kan het gebruik van eenvoudige platte bestanden de meest effectieve manier zijn om informatie op te slaan en op te halen. Als u bestandsshares gebruikt, kunnen bestanden via een netwerk worden geopend. Gezien de juiste beveiligings- en gelijktijdige mechanismen voor toegangsbeheer kan het delen van gegevens op deze manier gedistribueerde services in staat stellen om zeer schaalbare gegevenstoegang te bieden voor het uitvoeren van eenvoudige bewerkingen op laag niveau, zoals eenvoudige lees- en schrijfaanvragen.
Azure service
Werkdruk
- Migratie van bestaande apps die communiceren met het bestandssysteem.
- Hiervoor is een SMB-interface vereist.
Gegevenstype
- Bestanden in een hiërarchische set mappen.
- Toegankelijk met standaard I/O-bibliotheken.
Voorbeelden
- Verouderde bestanden
- Gedeelde inhoud die toegankelijk is tussen een aantal VM's of app-exemplaren
Met behulp van dit inzicht in verschillende gegevensopslagmodellen is de volgende stap het evalueren van uw werklast en applicatie en bepalen welke gegevensopslag aan uw specifieke behoeften voldoet. Gebruik de beslissingsstructuur voor gegevensopslag om u te helpen met dit proces.
Volgende stappen
- Azure Cloud Storage Solutions and Services
- uw opslagopties controleren
- Inleiding tot Azure Storage-
- Inleiding tot Azure Data Explorer