Een big data-architectuur is ontworpen voor het verwerken van de opname, verwerking en analyse van gegevens die te groot of complex zijn voor traditionele databasesystemen.

Big data-oplossingen hebben doorgaans betrekking op een of meer van de volgende typen workload:
- Batchverwerking van big data-at-rest-bronnen.
- Realtime verwerking van big data in beweging.
- Interactieve verkenning van big data.
- Predictive analytics en machine learning.
De meeste big data-architecturen bevatten enkele of alle volgende onderdelen:
gegevensbronnen: alle big data-oplossingen beginnen met een of meer gegevensbronnen. Voorbeelden zijn:
- Toepassingsgegevensarchieven, zoals relationele databases.
- Statische bestanden die worden geproduceerd door toepassingen, zoals webserverlogboekbestanden.
- Realtime gegevensbronnen, zoals IoT-apparaten.
gegevensopslag: gegevens voor batchverwerkingsbewerkingen worden doorgaans opgeslagen in een gedistribueerd bestandsarchief dat grote hoeveelheden grote bestanden in verschillende indelingen kan bevatten. Dit soort opslag wordt vaak een data lakegenoemd. Opties voor het implementeren van deze opslag zijn Onder andere Azure Data Lake Store- of blobcontainers in Azure Storage.
Batch-verwerking: omdat de gegevenssets zo groot zijn, moet vaak een big data-oplossing gegevensbestanden verwerken met behulp van langlopende batchtaken om de gegevens te filteren, aggregeren en anderszins voor te bereiden op analyse. Meestal zijn deze taken het lezen van bronbestanden, het verwerken ervan en het schrijven van de uitvoer naar nieuwe bestanden. Opties zijn onder andere het gebruik van gegevensstromen, gegevenspijplijnen in Microsoft Fabric.
realtime berichtopname: als de oplossing realtime bronnen bevat, moet de architectuur een manier bevatten om realtime berichten vast te leggen en op te slaan voor stroomverwerking. Dit kan een eenvoudig gegevensarchief zijn, waarbij binnenkomende berichten in een map worden geplaatst voor verwerking. Veel oplossingen hebben echter een opslag voor berichtopname nodig om te fungeren als buffer voor berichten en om uitschalen, betrouwbare bezorging en andere semantiek van berichten in de wachtrij te ondersteunen. Opties zijn Onder andere Azure Event Hubs, Azure IoT Hubs en Kafka.
Stream-verwerking: nadat realtime berichten zijn vastgelegd, moet de oplossing deze verwerken door de gegevens te filteren, samen te aggregateren en anders voor te bereiden op analyse. De verwerkte streamgegevens worden vervolgens naar een uitvoersink geschreven. Azure Stream Analytics biedt een beheerde stroomverwerkingsservice op basis van permanent uitgevoerde SQL-query's die worden uitgevoerd op niet-gebonden streams. Een andere optie is het gebruik van realtime intelligence in Microsoft Fabric, waarmee u KQL-query's kunt uitvoeren wanneer de gegevens worden opgenomen.
Analytische gegevensopslag: veel big data-oplossingen bereiden gegevens voor op analyse en dienen vervolgens de verwerkte gegevens in een gestructureerde indeling die kan worden opgevraagd met behulp van analytische hulpprogramma's. Het analytische gegevensarchief dat wordt gebruikt om deze query's te bedienen, kan een relationeel datawarehouse in kimballstijl zijn, zoals te zien is in de meeste traditionele BI-oplossingen (Business Intelligence) of een lakehouse met medalbytes-architectuur (Bronze, Silver en Gold). Azure Synapse Analytics biedt een beheerde service voor grootschalige, cloudgebaseerde datawarehousing. U kunt ook microsoft Fabric gebruiken voor zowel de opties warehouse als lakehouse, die kunnen worden opgevraagd met behulp van SQL en Spark.
analyse en rapportage: het doel van de meeste big data-oplossingen is om inzicht te krijgen in de gegevens via analyse en rapportage. Om gebruikers in staat te stellen de gegevens te analyseren, kan de architectuur een gegevensmodelleringslaag bevatten, zoals een multidimensionale OLAP-kubus of tabellair gegevensmodel in Azure Analysis Services. Het kan ook ondersteuning bieden voor selfservice BI, met behulp van de modellerings- en visualisatietechnologieën in Microsoft Power BI of Microsoft Excel. Analyse en rapportage kunnen ook de vorm aannemen van interactieve gegevensverkenning door gegevenswetenschappers of gegevensanalisten. Voor deze scenario's biedt Microsoft Fabric u hulpprogramma's zoals notebooks waar de gebruiker SQL of een programmeertaal naar keuze kan kiezen.
Indeling: de meeste big data-oplossingen bestaan uit herhaalde gegevensverwerkingsbewerkingen, ingekapseld in werkstromen, die brongegevens transformeren, gegevens verplaatsen tussen meerdere bronnen en sinks, de verwerkte gegevens laden in een analytische gegevensopslag of de resultaten rechtstreeks naar een rapport of dashboard pushen. Als u deze werkstromen wilt automatiseren, kunt u een indelingstechnologie zoals Azure Data Factory- of Microsoft Fabric-pijplijnen gebruiken.
Azure bevat veel services die kunnen worden gebruikt in een big data-architectuur. Ze vallen grofweg in twee categorieën:
- Beheerde services, waaronder Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub en Azure Data Factory.
- Opensource-technologieën op basis van het Apache Hadoop-platform, waaronder HDFS, HBase, Hive, Spark en Kafka. Deze technologieën zijn beschikbaar in Azure in de Azure HDInsight-service.
Deze opties sluiten elkaar niet wederzijds uit en veel oplossingen combineren opensource-technologieën met Azure-services.
Wanneer u deze architectuur gebruikt
Houd rekening met deze architectuurstijl wanneer u het volgende moet doen:
- Gegevens opslaan en verwerken in volumes die te groot zijn voor een traditionele database.
- Ongestructureerde gegevens transformeren voor analyse en rapportage.
- Niet-gebonden gegevensstromen in realtime vastleggen, verwerken en analyseren, of met lage latentie.
- Gebruik Azure Machine Learning of Azure Cognitive Services.
Voordelen
- Technologie-keuzes. U kunt beheerde Azure-services en Apache-technologieën in HDInsight-clusters combineren en matchen om te investeren in bestaande vaardigheden of technologie.
- prestaties via parallelle uitvoering. Big data-oplossingen profiteren van parallelle uitvoering, waardoor oplossingen met hoge prestaties kunnen worden geschaald naar grote hoeveelheden gegevens.
- elastisch schalen. Alle onderdelen in de big data-architectuur ondersteunen het uitschalen van inrichting, zodat u uw oplossing kunt aanpassen aan kleine of grote workloads en alleen betaalt voor de resources die u gebruikt.
- Interoperabiliteit met bestaande oplossingen. De onderdelen van de big data-architectuur worden ook gebruikt voor IoT-verwerking en ZAKELIJKE BI-oplossingen, zodat u een geïntegreerde oplossing kunt maken voor gegevensworkloads.
Uitdagingen
- Complexiteit. Big data-oplossingen kunnen zeer complex zijn, met talloze onderdelen voor het afhandelen van gegevensopname uit meerdere gegevensbronnen. Het kan lastig zijn om big data-processen te bouwen, testen en problemen op te lossen. Bovendien kunnen er een groot aantal configuratie-instellingen zijn voor meerdere systemen die moeten worden gebruikt om de prestaties te optimaliseren.
- vaardighedenset. Veel big data-technologieën zijn zeer gespecialiseerd en maken gebruik van frameworks en talen die niet typisch zijn voor algemenere toepassingsarchitecturen. Aan de andere kant ontwikkelen big data-technologieën nieuwe API's die voortbouwen op meer gevestigde talen.
- Technology maturity. Veel van de technologieën die in big data worden gebruikt, ontwikkelen zich. Hoewel de belangrijkste Hadoop-technologieën zoals Hive en spark zijn gestabiliseerd, introduceren opkomende technologieën zoals delta of ijsberg uitgebreide wijzigingen en verbeteringen. Beheerde services zoals Microsoft Fabric zijn relatief jong, vergeleken met andere Azure-services en zullen zich waarschijnlijk in de loop van de tijd ontwikkelen.
- Security. Big data-oplossingen zijn meestal afhankelijk van het opslaan van alle statische gegevens in een gecentraliseerde data lake. Het beveiligen van de toegang tot deze gegevens kan lastig zijn, met name wanneer de gegevens moeten worden opgenomen en gebruikt door meerdere toepassingen en platforms.
Aanbevolen procedures
parallellisme gebruiken. De meeste big data-verwerkingstechnologieën verdelen de workload over meerdere verwerkingseenheden. Hiervoor moeten statische gegevensbestanden worden gemaakt en opgeslagen in een gesplitste indeling. Gedistribueerde bestandssystemen zoals HDFS kunnen de lees- en schrijfprestaties optimaliseren en de werkelijke verwerking wordt parallel uitgevoerd door meerdere clusterknooppunten, wat de totale taaktijden vermindert. Het gebruik van gesplitste gegevensindeling wordt sterk aanbevolen, zoals Parquet.
Partitiegegevens. Batchverwerking vindt meestal plaats volgens een terugkerend schema, bijvoorbeeld wekelijks of maandelijks. Partitioneer gegevensbestanden en gegevensstructuren zoals tabellen, op basis van tijdelijke perioden die overeenkomen met het verwerkingsschema. Dit vereenvoudigt het opnemen van gegevens en het plannen van taken en maakt het eenvoudiger om fouten op te lossen. Het partitioneren van tabellen die worden gebruikt in Hive-, Spark- of SQL-query's, kan ook de prestaties van query's aanzienlijk verbeteren.
schema-on-read-semantiek toepassen. Met behulp van een data lake kunt u opslag voor bestanden in meerdere indelingen combineren, ongeacht of ze gestructureerd, semigestructureerd of ongestructureerd zijn. Gebruik schema-on-read semantiek, die een schema projecteert op de gegevens wanneer de gegevens worden verwerkt, niet wanneer de gegevens worden opgeslagen. Dit bouwt flexibiliteit in de oplossing en voorkomt knelpunten tijdens gegevensopname die worden veroorzaakt door gegevensvalidatie en typecontrole.
Gegevens in-placeverwerken. Traditionele BI-oplossingen maken vaak gebruik van een ETL-proces (extract, transform and load) om gegevens naar een datawarehouse te verplaatsen. Met grotere volumes en een grotere verscheidenheid aan indelingen maken big data-oplossingen doorgaans gebruik van variaties van ETL, zoals transformatie, extraheren en laden (TEL). Met deze benadering worden de gegevens verwerkt in het gedistribueerde gegevensarchief, waarbij ze worden getransformeerd naar de vereiste structuur voordat de getransformeerde gegevens worden verplaatst naar een analytische gegevensopslag.
Balans tussen gebruik en tijdkosten. Voor batchverwerkingstaken is het belangrijk om rekening te houden met twee factoren: de kosten per eenheid van de rekenknooppunten en de kosten per minuut van het gebruik van deze knooppunten om de taak te voltooien. Een batchtaak kan bijvoorbeeld acht uur duren met vier clusterknooppunten. Het kan echter zijn dat de taak alleen gedurende de eerste twee uur alle vier de knooppunten gebruikt. Daarna zijn er slechts twee knooppunten vereist. In dat geval zou het uitvoeren van de hele taak op twee knooppunten de totale taaktijd verhogen, maar zou deze niet verdubbelen, dus de totale kosten zouden minder zijn. In sommige bedrijfsscenario's kan een langere verwerkingstijd beter zijn dan de hogere kosten voor het gebruik van onderbenutte clusterbronnen.
Resources scheiden. Probeer waar mogelijk resources te scheiden op basis van de werkbelastingen om scenario's zoals één workload te voorkomen die alle resources gebruikt terwijl andere wachten.
gegevensopnameindelen. In sommige gevallen kunnen bestaande bedrijfstoepassingen gegevensbestanden schrijven voor batchverwerking rechtstreeks in Azure Storage-blobcontainers, waar ze kunnen worden gebruikt door downstreamservices zoals Microsoft Fabric. U moet echter vaak de opname van gegevens uit on-premises of externe gegevensbronnen in de data lake indelen. Gebruik een indelingswerkstroom of pijplijn, zoals de werkstroom of pijplijn die wordt ondersteund door Azure Data Factory of Microsoft Fabric, om dit op een voorspelbare en centraal beheerbare manier te bereiken.
Gevoelige gegevens vroegwissen. De werkstroom voor gegevensopname moet gevoelige gegevens vroeg in het proces wissen om te voorkomen dat deze in de data lake worden opgeslagen.
IoT-architectuur
Internet of Things (IoT) is een gespecialiseerde subset van big data-oplossingen. In het volgende diagram ziet u een mogelijke logische architectuur voor IoT. In het diagram worden de onderdelen voor gebeurtenisstreaming van de architectuur benadrukt.
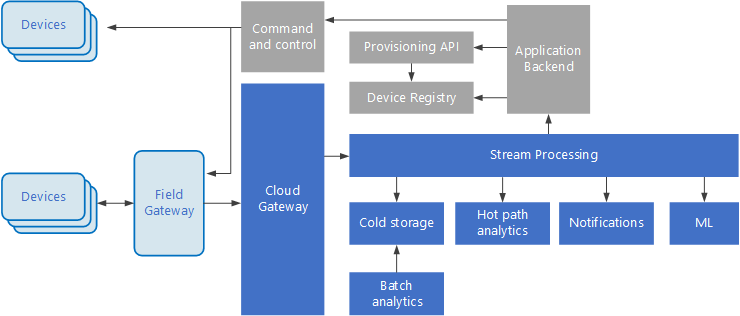
De cloudgateway apparaatgebeurtenissen opneemt aan de cloudgrens, met behulp van een betrouwbaar berichtensysteem met lage latentie.
Apparaten kunnen gebeurtenissen rechtstreeks naar de cloudgateway verzenden of via een veldgateway. Een veldgateway is een gespecialiseerd apparaat of software, meestal geplaatst met de apparaten, die gebeurtenissen ontvangt en doorstuurt naar de cloudgateway. De veldgateway kan ook de onbewerkte apparaatgebeurtenissen vooraf verwerken, functies uitvoeren zoals filteren, aggregatie of protocoltransformatie.
Na opname doorlopen gebeurtenissen een of meer streamprocessors die de gegevens (bijvoorbeeld naar opslag) kunnen routeren of analyses en andere verwerkingen kunnen uitvoeren.
Hier volgen enkele veelvoorkomende soorten verwerking. (Deze lijst is zeker niet volledig.)
Gebeurtenisgegevens schrijven naar koude opslag, voor archivering of batchanalyse.
Dynamische padanalyse, het analyseren van de gebeurtenisstroom in (bijna) realtime, om afwijkingen te detecteren, patronen te herkennen in rollende tijdvensters of waarschuwingen te activeren wanneer een specifieke voorwaarde in de stroom voorkomt.
Het verwerken van speciale typen niet-telemetrieberichten van apparaten, zoals meldingen en waarschuwingen.
Machine learning.
In de vakken die grijs zijn gearceerd, worden onderdelen van een IoT-systeem weergegeven die niet rechtstreeks zijn gerelateerd aan gebeurtenisstreaming, maar die hier voor volledigheid zijn opgenomen.
Het apparaatregister is een database van de ingerichte apparaten, waaronder de apparaat-id's en meestal metagegevens van apparaten, zoals locatie.
De inrichtings-API is een algemene externe interface voor het inrichten en registreren van nieuwe apparaten.
In sommige IoT-oplossingen kunnen opdracht- en besturingsberichten naar apparaten worden verzonden.
Deze sectie heeft een zeer hoog niveau van IoT gepresenteerd en er zijn veel subtiliteiten en uitdagingen die u moet overwegen. Zie IoT-architecturenvoor meer informatie.
Volgende stappen
- Meer informatie over big data-architecturen.
- Meer informatie over IoT-architecturen.