Fase voor het genereren van embeddings in RAG
In de vorige stappen van uw oplossing Retrieval-Augmented Generation (RAG) hebt u uw documenten onderverdeeld in segmenten en de segmenten verrijkt. In deze stap genereert u insluitingen voor deze segmenten en metagegevensvelden waarop u vectorzoekopdrachten wilt uitvoeren.
Dit artikel maakt deel uit van een reeks. Lees de inleiding .
Een insluiting is een wiskundige weergave van een object, zoals tekst. Wanneer een neuraal netwerk wordt getraind, worden er veel weergaven van een object gemaakt. Elke weergave heeft verbindingen met andere objecten in het netwerk. Een insluiting is belangrijk omdat hiermee de semantische betekenis van het object wordt vastgelegd.
De weergave van het ene object heeft verbindingen met representaties van andere objecten, zodat u objecten wiskundig kunt vergelijken. In het volgende voorbeeld ziet u hoe insluitingen semantische betekenis en relaties tussen elkaar vastleggen:
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
Insluitingen worden vergeleken met elkaar door gebruik te maken van de noties van overeenkomsten en afstand. In het volgende raster ziet u een vergelijking van insluitingen.

In een RAG-oplossing sluit u de gebruikersquery vaak in met hetzelfde insluitingsmodel als uw segmenten. Vervolgens zoekt u in uw database naar relevante vectoren om de meest semantisch relevante segmenten te retourneren. De oorspronkelijke tekst van de relevante segmenten wordt als grondgegevens doorgegeven aan het taalmodel.
Notitie
Vectoren vertegenwoordigen de semantische betekenis van tekst op een manier die wiskundige vergelijking mogelijk maakt. U moet de segmenten schoonmaken zodat de wiskundige nabijheid tussen vectoren nauwkeurig de semantische relevantie weergeeft.
Het belang van het insluitmodel
Het insluitmodel dat u kiest, kan de relevantie van uw vectorzoekresultaten aanzienlijk beïnvloeden. U moet rekening houden met het vocabulaire van het insluitmodel. Elk insluitmodel wordt getraind met een specifieke woordenlijst. De woordenlijstgrootte van het BERT-model is bijvoorbeeld ongeveer 30.000 woorden.
Het vocabulaire van een insluitmodel is belangrijk omdat het woorden verwerkt die niet op een unieke manier in de woordenlijst voorkomen. Als een woord zich niet in de woordenlijst van het model bevindt, wordt er nog steeds een vector voor berekend. Om dit te doen, splitsen veel modellen de woorden op in subwoorden. Ze behandelen de subwoorden als afzonderlijke tokens of aggregeren de vectoren voor de subwoorden om één insluiting te maken.
Het woord histamine bevindt zich bijvoorbeeld mogelijk niet in de woordenlijst van een insluitmodel. Het woord histamine heeft een semantische betekenis als een chemische stof die uw lichaam vrijgeeft, wat allergiesymptomen veroorzaakt. Het insluitmodel bevat geen histamine. Het kan dus het woord scheiden in subwoorden die zich in zijn woordenschat bevinden, zoals zijn, taen mijne.

De semantische betekenissen van deze subwoorden zijn verre van de betekenis van histamine. De afzonderlijke of gecombineerde vectorwaarden van de subwoorden resulteren in slechtere vectorovereenkomsten in vergelijking met als histamine zich in de woordenlijst van het model bevonden.
Een insluitmodel kiezen
Bepaal het juiste insluitingsmodel voor uw use-case. Houd rekening met de overlapping tussen de woorden van het insluitmodel en de woorden van uw gegevens wanneer u een insluitmodel kiest.

Bepaal eerst of u domeinspecifieke inhoud hebt. Zijn uw documenten bijvoorbeeld specifiek voor een use-case, uw organisatie of een branche? Een goede manier om domeinspecifiekheid te bepalen, is om te controleren of u de entiteiten en trefwoorden in uw inhoud op internet kunt vinden. Als u dat kunt, kan een algemeen insluitmodel waarschijnlijk ook.
Algemene of niet-domeinspecifieke inhoud
Wanneer u een algemeen insluitingsmodel kiest, begint u met het Hugging Face leaderboard. Haal up-to-datum van het embedden van modelranglijsten op. Evalueer hoe de modellen met uw gegevens werken en begin met de topclassificatiemodellen.
Domeinspecifieke inhoud
Bepaal voor domeinspecifieke inhoud of u een domeinspecifiek model kunt gebruiken. Uw gegevens bevinden zich bijvoorbeeld in het bio-domein, dus u kunt het BioGPT-modelgebruiken. Dit taalmodel is vooraf getraind op een grote verzameling medische literatuur. U kunt het gebruiken voor bio-tekstanalyse en -generatie. Als er domeinspecifieke modellen beschikbaar zijn, evalueert u hoe deze modellen met uw gegevens werken.
Als u geen domeinspecifiek model hebt of als het domeinspecifieke model niet goed presteert, kunt u een algemeen insluitmodel verfijnen met uw domeinspecifieke woordenlijst.
Belangrijk
Voor elk model dat u kiest, moet u controleren of de licentie aan uw behoeften voldoet en het model de benodigde taalondersteuning biedt.
Insluitingsmodellen evalueren
Als u een insluitmodel wilt evalueren, visualiseert u de insluitingen en evalueert u de afstand tussen de vraag- en segmentvectoren.
Insluitingen visualiseren
U kunt bibliotheken, zoals t-SNE, gebruiken om de vectoren voor uw segmenten en uw vraag in een X-Y-grafiek te tekenen. Vervolgens kunt u bepalen hoe ver de segmenten van elkaar zijn en van de vraag. In de volgende grafiek ziet u segmentvectoren die zijn uitgezet. De twee pijlen in de buurt van elkaar vertegenwoordigen twee segmentvectoren. De andere pijl vertegenwoordigt een vraagvector. U kunt deze visualisatie gebruiken om te begrijpen hoe ver de vraag zich van de segmenten bevindt.
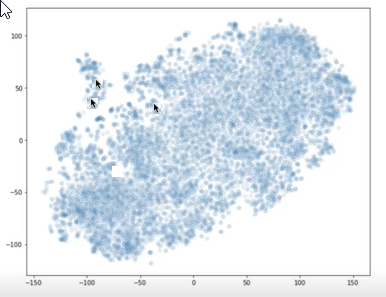
Twee pijlen wijzen naar punten in de buurt van elkaar en een andere pijl toont een tekenpunt ver van de andere twee.
Insluitingsafstanden berekenen
U kunt een programmatische methode gebruiken om te evalueren hoe goed uw insluitingsmodel werkt met uw vragen en segmenten. Bereken de afstand tussen de vraagvectoren en de segmentvectoren. U kunt de Euclidische afstand of de Manhattan-afstand gebruiken.
Economie insluiten
Wanneer u een insluitmodel kiest, moet u een afweging maken tussen prestaties en kosten. Grote insluitingsmodellen hebben meestal betere prestaties bij het benchmarken van gegevenssets. Maar dankzij de verbeterde prestaties worden kosten opgehoogd. Grote vectoren vereisen meer ruimte in een vectordatabase. Ze vereisen ook meer rekenresources en tijd om insluitingen te vergelijken. Kleine insluitingsmodellen hebben meestal lagere prestaties op dezelfde benchmarks. Ze vereisen minder ruimte in uw vectordatabase en minder rekenkracht en tijd om insluitingen te vergelijken.
Wanneer u uw systeem ontwerpt, moet u rekening houden met de kosten voor het insluiten van opslag, rekenkracht en prestatievereisten. U moet de prestaties van de modellen valideren door middel van experimenten. De openbaar beschikbare benchmarks zijn voornamelijk academische gegevenssets en zijn mogelijk niet rechtstreeks van toepassing op uw bedrijfsgegevens en gebruiksvoorbeelden. Afhankelijk van de vereisten kunt u de prestaties verbeteren ten opzichte van de kosten of een afweging van goede prestaties accepteren voor lagere kosten.