Overzicht van generatieve AI-gatewaymogelijkheden in Azure API Management
VAN TOEPASSING OP: Alle API Management-lagen
In dit artikel worden mogelijkheden in Azure API Management geïntroduceerd om u te helpen bij het beheren van generatieve AI-API's, zoals de API's van Azure OpenAI Service. Azure API Management biedt een scala aan beleidsregels, metrische gegevens en andere functies om de beveiliging, prestaties en betrouwbaarheid te verbeteren voor de API's die uw intelligente apps leveren. Deze functies worden gezamenlijk generatieve AI-gatewaymogelijkheden (GenAI) genoemd voor uw generatieve AI-API's.
Notitie
- Dit artikel is gericht op mogelijkheden voor het beheren van API's die beschikbaar worden gemaakt door Azure OpenAI Service. Veel van de GenAI-gatewaymogelijkheden zijn van toepassing op andere LLM-API's (large language model), waaronder de API's die beschikbaar zijn via Deductie-API voor Azure AI-modellen.
- Generatieve AI-gatewaymogelijkheden zijn functies van de bestaande API-gateway van API Management, niet van een afzonderlijke API-gateway. Zie het overzicht van Azure API Management voor meer informatie over API Management.
Uitdagingen bij het beheren van generatieve AI-API's
Een van de belangrijkste resources die u hebt in generatieve AI-services is tokens. Azure OpenAI Service wijst quota toe voor uw modelimplementaties, uitgedrukt in tokens per minuut (TPM), die vervolgens wordt gedistribueerd over uw modelgebruikers, bijvoorbeeld verschillende toepassingen, ontwikkelaarsteams, afdelingen binnen het bedrijf, enzovoort.
Met Azure kunt u eenvoudig één app verbinden met Azure OpenAI Service: u kunt rechtstreeks verbinding maken met behulp van een API-sleutel met een TPM-limiet die rechtstreeks op het niveau van de modelimplementatie is geconfigureerd. Wanneer u echter begint met het uitbreiden van uw toepassingsportfolio, krijgt u meerdere apps te zien die één of zelfs meerdere Azure OpenAI Service-eindpunten aanroepen die zijn geïmplementeerd als PTU-exemplaren (Pay-as-You-Go of Provisioned Throughput Units ). Dat komt met bepaalde uitdagingen:
- Hoe wordt tokengebruik bijgehouden in meerdere toepassingen? Kunnen er kruislingse kosten worden berekend voor meerdere toepassingen/teams die gebruikmaken van Azure OpenAI Service-modellen?
- Hoe zorgt u ervoor dat één app niet het volledige TPM-quotum verbruikt, zodat andere apps geen optie hebben om Azure OpenAI Service-modellen te gebruiken?
- Hoe wordt de API-sleutel veilig gedistribueerd over meerdere toepassingen?
- Hoe wordt de belasting verdeeld over meerdere Azure OpenAI-eindpunten? Kunt u ervoor zorgen dat de vastgelegde capaciteit in PTU's is uitgeput voordat u terugvalt op instanties met betalen per gebruik?
In de rest van dit artikel wordt beschreven hoe Azure API Management u kan helpen deze uitdagingen aan te pakken.
Azure OpenAI-serviceresource als API importeren
Importeer een API vanuit een Azure OpenAI-service-eindpunt naar Azure API Management met behulp van één klikervaring. API Management stroomlijnt het onboardingproces door automatisch het OpenAPI-schema voor de Azure OpenAI-API te importeren en verificatie in te stellen voor het Azure OpenAI-eindpunt met behulp van beheerde identiteit, waardoor handmatige configuratie wordt verwijderd. Binnen dezelfde gebruiksvriendelijke ervaring kunt u beleidsregels voor tokenlimieten vooraf configureren en metrische tokengegevens verzenden.

Beleid voor tokenlimiet
Configureer het azure OpenAI-tokenlimietbeleid om limieten per API-consument te beheren en af te dwingen op basis van het gebruik van Azure OpenAI-servicetokens. Met dit beleid kunt u limieten instellen, uitgedrukt in tokens per minuut (TPM).
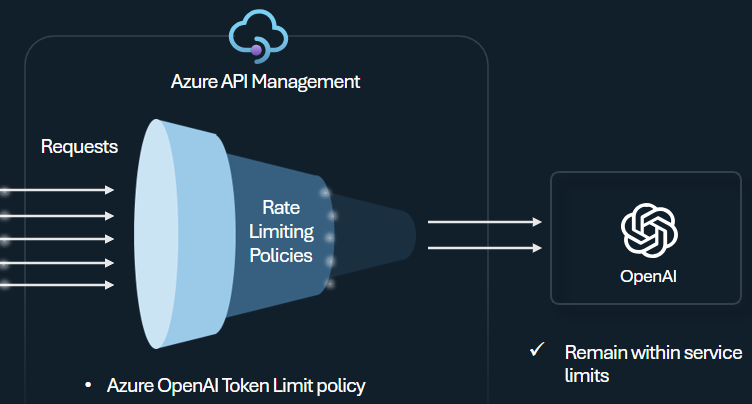
Dit beleid biedt flexibiliteit voor het toewijzen van limieten op basis van tokens voor tellersleutels, zoals abonnementssleutel, ip-adres van oorsprong of een willekeurige sleutel die is gedefinieerd via een beleidsexpressie. Het beleid maakt ook het vooraf berekenen van prompttokens aan de kant van Azure API Management mogelijk, waardoor onnodige aanvragen naar de back-end van de Azure OpenAI-service worden geminimaliseerd als de prompt de limiet al overschrijdt.
In het volgende basisvoorbeeld ziet u hoe u een TPM-limiet van 500 per abonnementssleutel instelt:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Tip
Voor het beheren en afdwingen van tokenlimieten voor LLM-API's die beschikbaar zijn via de Azure AI-modeldeductie-API, biedt API Management het equivalente llm-token-limit-beleid .
Metrische tokenbeleid verzenden
Het metrische tokenbeleid van Azure OpenAI verzendt metrische gegevens naar Application Insights over het verbruik van LLM-tokens via Azure OpenAI-service-API's. Het beleid biedt een overzicht van het gebruik van Azure OpenAI Service-modellen voor meerdere toepassingen of API-gebruikers. Dit beleid kan nuttig zijn voor terugstortingsscenario's, bewaking en capaciteitsplanning.
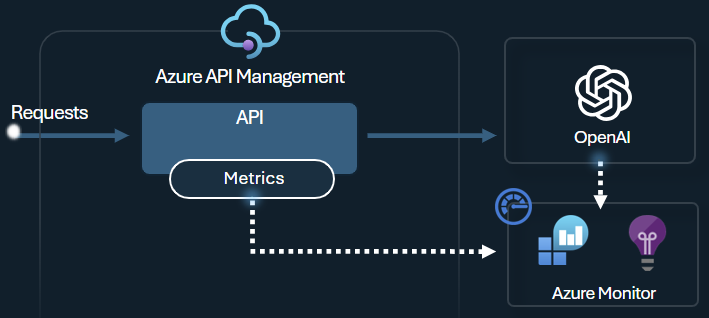
Met dit beleid worden prompts, voltooiingen en metrische gegevens over het totale tokengebruik vastgelegd en verzonden naar een Application Insights-naamruimte van uw keuze. Bovendien kunt u vooraf gedefinieerde dimensies configureren of selecteren om metrische gegevens over tokengebruik te splitsen, zodat u metrische gegevens kunt analyseren op abonnements-id, IP-adres of een aangepaste dimensie van uw keuze.
Met het volgende beleid worden bijvoorbeeld metrische gegevens verzonden naar Application Insights, gesplitst op client-IP-adres, API en gebruiker:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Tip
Om metrische gegevens te verzenden voor LLM-API's die beschikbaar zijn via de Azure AI-modeldeductie-API, biedt API Management het equivalente llm-emit-token-metric policy.
Back-end load balancer en circuitonderbreker
Een van de uitdagingen bij het bouwen van intelligente toepassingen is ervoor te zorgen dat de toepassingen bestand zijn tegen back-endfouten en hoge belastingen kunnen verwerken. Door uw Azure OpenAI-service-eindpunten te configureren met behulp van back-ends in Azure API Management, kunt u de taak over deze eindpunten verdelen. U kunt ook regels voor circuitonderbrekers definiëren om het doorsturen van aanvragen naar de back-ends van de Azure OpenAI-service te stoppen als ze niet reageren.
De back-end load balancer biedt ondersteuning voor round robin, gewogen en op prioriteit gebaseerde taakverdeling, waardoor u flexibiliteit hebt om een loaddistributiestrategie te definiëren die voldoet aan uw specifieke vereisten. Definieer bijvoorbeeld prioriteiten in de configuratie van de load balancer om een optimaal gebruik van specifieke Azure OpenAI-eindpunten te garanderen, met name de eindpunten die zijn gekocht als PTU's.
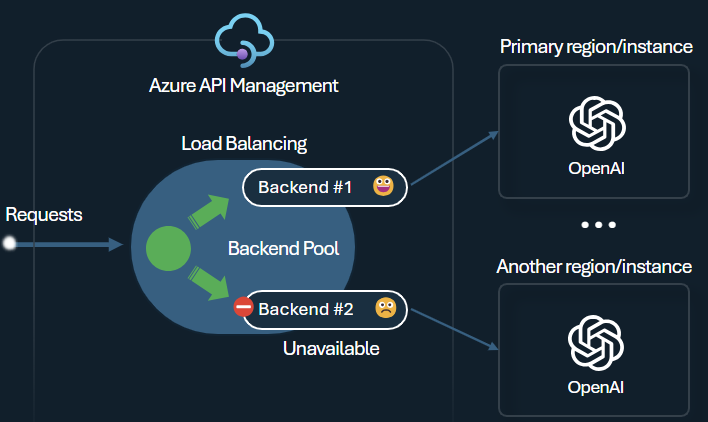
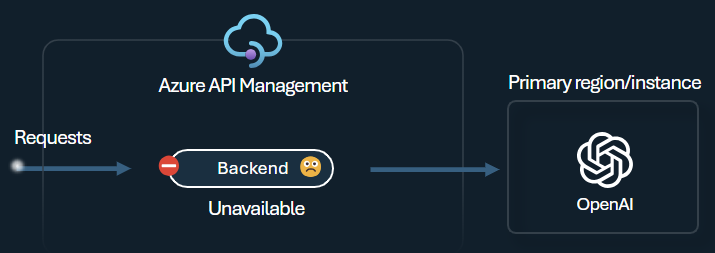
De onderbreking van het back-endcircuit heeft een dynamische duur van de rit, waarbij waarden worden toegepast uit de header Opnieuw proberen na die door de back-end is opgegeven. Dit zorgt voor nauwkeurig en tijdig herstel van de back-ends, waardoor het gebruik van uw prioriteitsback-ends wordt gemaximaliseerd.
Semantisch cachebeleid
Configureer semantisch cachebeleid van Azure OpenAI om het tokengebruik te optimaliseren door voltooiingen op te slaan voor vergelijkbare prompts.
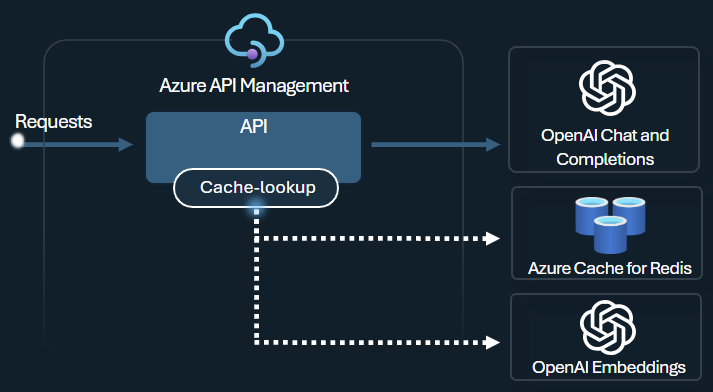
Schakel in API Management semantische caching in met behulp van Azure Redis Enterprise of een andere externe cache die compatibel is met RediSearch en onboarding naar Azure API Management. Met behulp van de Azure OpenAI Service Embeddings-API, de azure-openai-semantic-cache-store en azure-openai-semantic-cache-lookup policies store en ophalen semantisch vergelijkbare prompt voltooiingen uit de cache. Deze aanpak zorgt ervoor dat voltooiingen opnieuw worden gebruikt, wat resulteert in verminderd tokenverbruik en verbeterde responsprestaties.
Tip
Als u semantische caching wilt inschakelen voor LLM-API's die beschikbaar zijn via de Azure AI-modeldeductie-API, biedt API Management het equivalente beleid llm-semantic-cache-store-policy en llm-semantic-cache-lookup-policy .
Labs en voorbeelden
- Labs voor de GenAI-gatewaymogelijkheden van Azure API Management
- Azure API Management (APIM) - Azure OpenAI-voorbeeld (Node.js)
- Python-voorbeeldcode voor het gebruik van Azure OpenAI met API Management
Overwegingen voor architectuur en ontwerp
- GenAI-gatewayreferentiearchitectuur met API Management
- Ai Hub Gateway-landingszoneversneller
- Een gatewayoplossing ontwerpen en implementeren met Azure OpenAI-resources
- Een gateway gebruiken vóór meerdere Azure OpenAI-implementaties of -exemplaren
Gerelateerde inhoud
- Blog: Introductie van GenAI-mogelijkheden in Azure API Management
- Blog: Azure Content Safety integreren met API Management voor Azure OpenAI-eindpunten
- Training: Uw generatieve AI-API's beheren met Azure API Management
- Slimme taakverdeling voor OpenAI-eindpunten en Azure API Management
- Toegang tot Azure OpenAI-API's verifiëren en autoriseren met behulp van Azure API Management