Zelfstudie: Deel 3: Een aangepaste chattoepassing evalueren met de Azure AI Foundry SDK
In deze zelfstudie gebruikt u de Azure AI SDK (en andere bibliotheken) om de chat-app te evalueren die u in deel 2 van de reeks zelfstudies hebt gemaakt. In dit deel drie leert u het volgende:
- Een evaluatiegegevensset maken
- De chat-app evalueren met Azure AI-evaluators
- Uw app herhalen en verbeteren
Deze zelfstudie is deel drie van een driedelige zelfstudie.
Vereisten
- Voltooi deel 2 van de reeks zelfstudies om de chattoepassing te bouwen.
- Zorg ervoor dat u de stappen hebt uitgevoerd om telemetrielogboekregistratie toe te voegen vanuit deel 2.
De kwaliteit van de antwoorden van de chat-app evalueren
Nu u weet dat uw chat-app goed reageert op uw query's, waaronder met de chatgeschiedenis, is het tijd om te evalueren hoe deze werkt in een aantal verschillende metrische gegevens en meer gegevens.
U gebruikt een evaluator met een evaluatiegegevensset en de get_chat_response() doelfunctie en evalueert vervolgens de evaluatieresultaten.
Zodra u een evaluatie hebt uitgevoerd, kunt u verbeteringen aanbrengen in uw logica, zoals het verbeteren van uw systeemprompt en het observeren van hoe de reacties van de chat-app veranderen en verbeteren.
Evaluatiegegevensset maken
Gebruik de volgende evaluatiegegevensset, die voorbeeldvragen en verwachte antwoorden (waarheid) bevat.
Maak een bestand met de naam chat_eval_data.jsonl in de map assets .
Plak deze gegevensset in het bestand:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Evalueren met Azure AI-evaluators
Definieer nu een evaluatiescript dat het volgende doet:
- Genereer een doelfunctie-wrapper rond onze chat-app-logica.
- Laad de voorbeeldgegevensset
.jsonl. - Voer de evaluatie uit, waarbij de doelfunctie wordt gebruikt en voeg de evaluatiegegevensset samen met de antwoorden van de chat-app.
- Genereer een set met gpt-ondersteunde metrische gegevens (relevantie, basisheid en samenhang) om de kwaliteit van de reacties op de chat-app te evalueren.
- Voer de resultaten lokaal uit en registreert de resultaten in het cloudproject.
Met het script kunt u de resultaten lokaal bekijken door de resultaten in de opdrachtregel en een json-bestand uit te voeren.
Het script registreert ook de evaluatieresultaten naar het cloudproject, zodat u evaluatieuitvoeringen in de gebruikersinterface kunt vergelijken.
Maak een bestand met de naam evaluate.py in de hoofdmap.
Voeg de volgende code toe om de vereiste bibliotheken te importeren, een projectclient te maken en enkele instellingen te configureren:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Voeg code toe om een wrapper-functie te maken waarmee de evaluatie-interface voor de evaluatie van query's en antwoorden wordt geïmplementeerd:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Voeg ten slotte code toe om de evaluatie uit te voeren, bekijk de resultaten lokaal en geeft u een koppeling naar de evaluatieresultaten in de Azure AI Foundry-portal:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Het evaluatiemodel configureren
Omdat het evaluatiescript het model vaak aanroept, kunt u het aantal tokens per minuut voor het evaluatiemodel verhogen.
In deel 1 van deze reeks zelfstudies hebt u een .env-bestand gemaakt waarmee de naam van het evaluatiemodel wordt opgegeven. gpt-4o-mini Probeer de limiet voor tokens per minuut voor dit model te verhogen als u een beschikbaar quotum hebt. Als u onvoldoende quotum hebt om de waarde te verhogen, hoeft u zich geen zorgen te maken. Het script is ontworpen voor het afhandelen van limietfouten.
- Selecteer modellen en eindpunten in uw project in de Azure AI Foundry-portal.
- Selecteer gpt-4o-mini.
- Selecteer Bewerken.
- Als u een quotum hebt om de limiet voor tokens per minuut te verhogen, kunt u proberen deze te verhogen tot 30.
- Selecteer Opslaan en sluiten.
Het evaluatiescript uitvoeren
Meld u vanuit uw console aan bij uw Azure-account met de Azure CLI:
az loginInstalleer het vereiste pakket:
pip install azure-ai-evaluation[remote]Voer nu het evaluatiescript uit:
python evaluate.py
De evaluatie-uitvoer interpreteren
In de console-uitvoer ziet u een antwoord voor elke vraag, gevolgd door een tabel met samengevatte metrische gegevens. (Mogelijk ziet u verschillende kolommen in de uitvoer.)
Als u de limiet voor tokens per minuut voor uw model niet kunt verhogen, ziet u mogelijk een aantal time-outfouten, die worden verwacht. Het evaluatiescript is ontworpen om deze fouten af te handelen en door te gaan met het uitvoeren.
Notitie
U kunt er ook veel WARNING:opentelemetry.attributes: zien. Deze kunnen veilig worden genegeerd en hebben geen invloed op de evaluatieresultaten.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Evaluatieresultaten weergeven in de Azure AI Foundry-portal
Zodra de evaluatie is voltooid, volgt u de koppeling om de evaluatieresultaten weer te geven op de pagina Evaluatie in de Azure AI Foundry-portal.
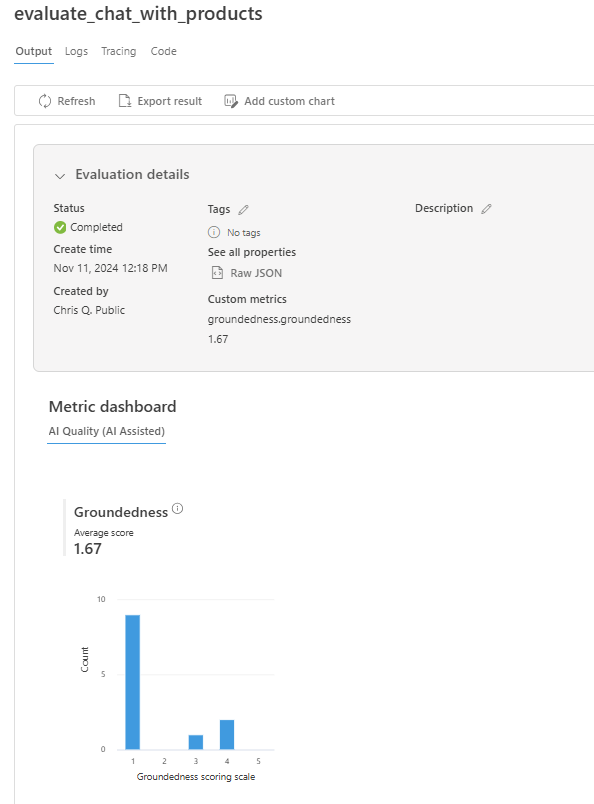
U kunt ook de afzonderlijke rijen bekijken en metrische scores per rij bekijken en de volledige context/documenten bekijken die zijn opgehaald. Deze metrische gegevens kunnen handig zijn bij het interpreteren en opsporen van fouten in evaluatieresultaten.
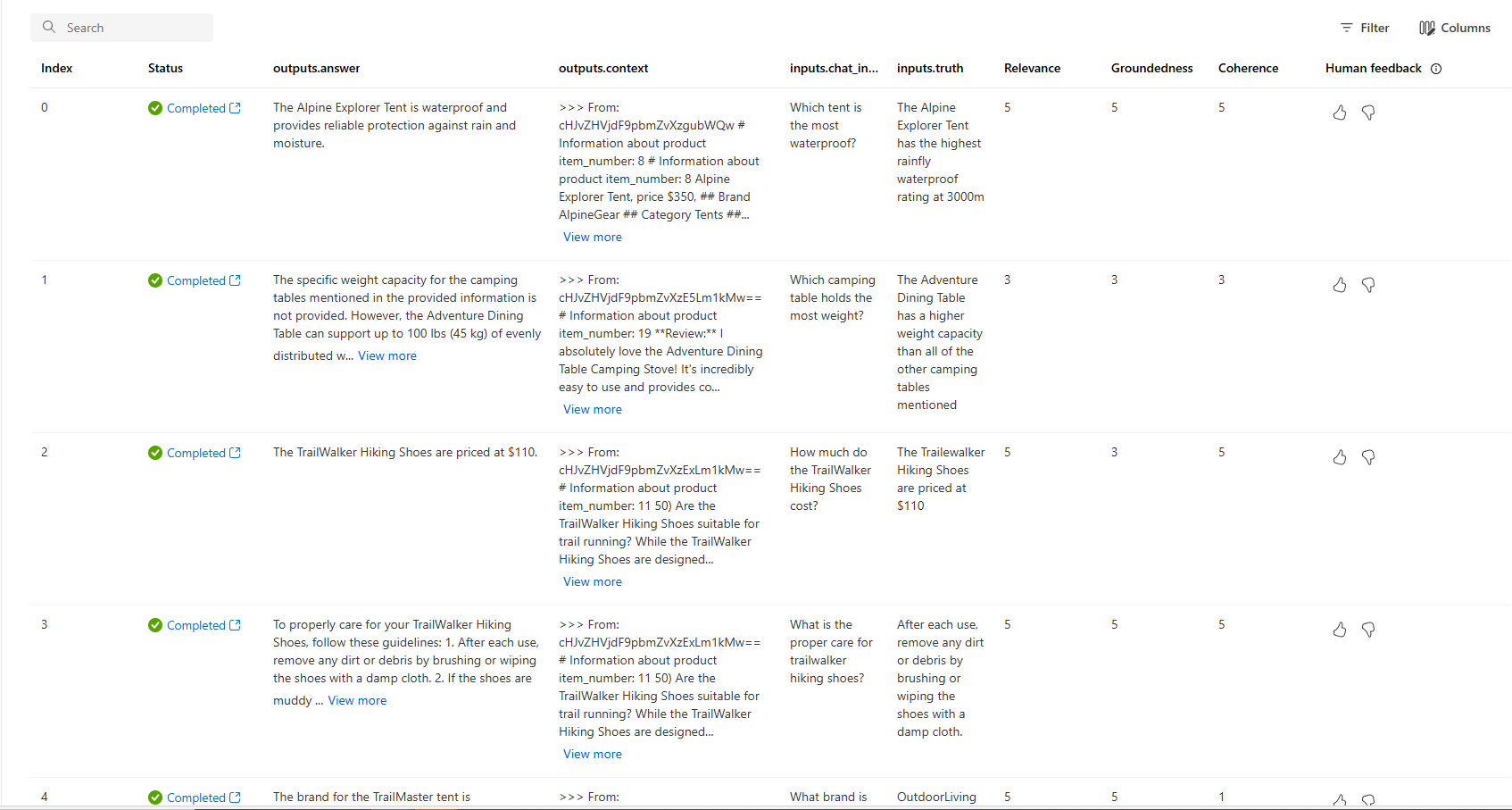
Zie Voor meer informatie over evaluatieresultaten in de Azure AI Foundry-portal de evaluatieresultaten weergeven in de Azure AI Foundry-portal.
Herhalen en verbeteren
U ziet dat de antwoorden niet goed zijn geaard. In veel gevallen beantwoordt het model een vraag in plaats van een antwoord. Dit is het resultaat van de instructies voor de promptsjabloon.
- Zoek in uw assets/grounded_chat.prompty bestand de zin 'Als de vraag is gerelateerd aan outdoor/camping gear en kleding, maar vaag, vragen om vragen te verduidelijken in plaats van te verwijzen naar documenten'.
- Wijzig de zin in 'Als de vraag betrekking heeft op buiten-/kampeertuig en kleding, maar vaag is, probeert u te antwoorden op basis van de referentiedocumenten, vraagt u vervolgens om verduidelijkingsvragen.'
- Sla het bestand op en voer het evaluatiescript opnieuw uit.
Probeer andere wijzigingen in de promptsjabloon of probeer verschillende modellen om te zien hoe de wijzigingen van invloed zijn op de evaluatieresultaten.
Resources opschonen
Als u onnodige Azure-kosten wilt voorkomen, moet u de resources verwijderen die u in deze zelfstudie hebt gemaakt als ze niet meer nodig zijn. Als u resources wilt beheren, kunt u Azure Portal gebruiken.