Wat is tekst naar spraak?
In dit overzicht krijgt u informatie over de voordelen en mogelijkheden van de tekst-naar-spraakfunctie van de Speech-service, die deel uitmaakt van Azure AI-services.
Met tekst naar spraak kunnen uw toepassingen, hulpprogramma's of apparaten tekst omzetten in menselijke, zoals gesynthetiseerde spraak. De spraakfunctie voor tekst wordt ook wel spraaksynthese genoemd. Gebruik menselijke, zoals vooraf samengestelde neurale stemmen, of maak een aangepaste neurale stem die uniek is voor uw product of merk. Zie Taal- en spraakondersteuning voor de Speech-service voor een volledige lijst met ondersteunde stemmen, talen en landinstellingen.
Kernfuncties
Tekst naar spraak bevat de volgende functies:
| Functie | Samenvatting | Demo |
|---|---|---|
| Vooraf samengestelde neurale stem (neurale spraak genoemd op de pagina met prijzen) | Zeer natuurlijke out-of-the-box stemmen. Maak een Azure-abonnement en spraakresource en gebruik vervolgens de Speech SDK of ga naar de Speech Studio-portal en selecteer vooraf gemaakte neurale stemmen om aan de slag te gaan. Controleer de prijsgegevens. | Controleer de spraakgalerie en bepaal de juiste stem voor uw zakelijke behoeften. |
| Aangepaste neurale spraak (aangepaste neurale spraak genoemd op de pagina met prijzen) | Gebruiksvriendelijke selfservice voor het creëren van een natuurlijke merkstem, met beperkte toegang voor verantwoordelijk gebruik. Maak een Azure-abonnement en spraakresource (met de S0-laag) en pas deze toe om de aangepaste spraakfunctie te gebruiken. Nadat u toegang hebt gekregen, gaat u naar de Speech Studio-portal en selecteert u Custom Voice om aan de slag te gaan. Controleer de prijsgegevens. | Controleer de stemvoorbeelden. |
Meer informatie over neurale tekst naar spraakfuncties
Tekst-naar-spraak maakt gebruik van diepe neurale netwerken om de stemmen van computers vrijwel niet te onderscheiden van de opnamen van mensen. Met de duidelijke articulatie van woorden vermindert neurale tekst naar spraak de luistermoeheid aanzienlijk wanneer gebruikers interactie hebben met AI-systemen.
De patronen van stress en intonatie in gesproken taal worden prosody genoemd. Traditionele tekst-naar-spraaksystemen splitsen prosody op in afzonderlijke taalkundige analyse- en akoestische voorspellingsstappen die worden beheerd door onafhankelijke modellen. Dat kan leiden tot gedempte spraaksynthese.
Hier volgt meer informatie over neurale tekst naar spraakfuncties in de Speech-service en hoe ze de limieten van traditionele tekst naar spraaksystemen overwinnen:
Realtime spraaksynthese: gebruik de Speech SDK of REST API om tekst naar spraak te converteren met behulp van vooraf gemaakte neurale stemmen of aangepaste neurale stemmen.
Asynchrone synthese van lange audio: Gebruik de batchsynthese-API om tekst asynchroon te synthetiseren naar spraakbestanden die langer zijn dan 10 minuten (bijvoorbeeld audioboeken of lezingen). In tegenstelling tot synthese die wordt uitgevoerd via de Speech SDK of Speech to text REST API, worden antwoorden niet in realtime geretourneerd. De verwachting is dat aanvragen asynchroon worden verzonden, antwoorden worden gepeild naar en gesynthetiseerde audio wordt gedownload wanneer de service deze beschikbaar maakt.
Vooraf gebouwde neurale stemmen: Azure AI Speech maakt gebruik van diepe neurale netwerken om de limieten van traditionele spraaksynthese met betrekking tot stress en intonatie in gesproken taal te overwinnen. Prosody voorspelling en spraaksynthese worden gelijktijdig uitgevoerd, wat resulteert in meer vloeiende en natuurlijk klinkende uitvoer. Elk vooraf samengesteld neurale spraakmodel is beschikbaar op 24 kHz en 48 kHz. U kunt neurale stemmen gebruiken om:
- Maak interacties met chatbots en spraakassistenten natuurlijker en aantrekkelijker.
- Digitale teksten zoals e-books converteren naar audioboeken.
- Verbeter navigatiesystemen in de auto.
Zie Taal- en spraakondersteuning voor de Speech-service voor een volledige lijst met vooraf samengestelde azure AI Speech neurale stemmen.
Tekst naar spraakuitvoer verbeteren met SSML: Speech Synthesis Markup Language (SSML) is een xml-opmaaktaal die wordt gebruikt om tekst aan te passen aan spraakuitvoer. Met SSML kunt u de toonhoogte aanpassen, pauzes toevoegen, uitspraak verbeteren, spreeksnelheid wijzigen, volume aanpassen en meerdere stemmen aan één document toewijzen.
U kunt SSML gebruiken om uw eigen lexicons te definiëren of over te schakelen naar verschillende spreekstijlen. Met de meertalige stemmen kunt u de spreektalen ook aanpassen via SSML. Als u de spraakuitvoer voor uw scenario wilt verbeteren, raadpleegt u Synthese verbeteren met Spraaksynthese markup Language en Spraaksynthese met het hulpprogramma Voor het maken van audio-inhoud.
Visemes: Visemes zijn de belangrijkste houdingen in waargenomen spraak, met inbegrip van de positie van de lippen, kaak en tong bij het produceren van een bepaald foneme. Visemes heeft een sterke correlatie met stemmen en telefoontjes.
Met behulp van viseme-gebeurtenissen in Speech SDK kunt u gezichtsanimatiegegevens genereren. Deze gegevens kunnen worden gebruikt om gezichten te animeren in lipleescommunicatie, onderwijs, entertainment en klantenservice. Viseme wordt momenteel alleen ondersteund voor de
en-USneurale stemmen (US English).
Notitie
Naast neurale stemmen van Azure AI Speech (niet-HD) kunt u ook hd-stemmen (Hd) van Azure AI Speech (high definition) en neurale stemmen van Azure OpenAI (HD en niet-HD) gebruiken. De HD-stemmen bieden een hogere kwaliteit voor veelzijdigere scenario's.
Sommige stemmen ondersteunen niet alle SSML-tags (Speech Synthesis Markup Language). Dit omvat neurale tekst naar spraak HD-stemmen, persoonlijke stemmen en ingesloten stemmen.
- Voor HD-stemmen (Azure AI Speech high definition) raadpleegt u hier de SSML-ondersteuning.
- Voor persoonlijke stem vindt u hier de SSML-ondersteuning.
- Raadpleeg hier de SSML-ondersteuning voor ingesloten stemmen.
Aan de slag
Zie de quickstart om aan de slag te gaan met tekst naar spraak. Tekst naar spraak is beschikbaar via de Speech SDK, de REST API en de Speech CLI.
Tip
Als u tekst wilt converteren naar spraak zonder code, kunt u het hulpprogramma Audio-inhoud maken in Speech Studio gebruiken.
Voorbeeldcode
Voorbeeldcode voor tekst-naar-spraak is beschikbaar op GitHub. Deze voorbeelden hebben betrekking op tekst naar spraakconversie in de populairste programmeertalen:
Aangepaste neurale spraak
Naast vooraf samengestelde neurale stemmen kunt u aangepaste neurale stemmen maken die uniek zijn voor uw product of merk. Het enige wat nodig is om aan de slag te gaan, is een handvol audiobestanden en de bijbehorende transcripties. Zie Aan de slag met aangepaste neurale spraak voor meer informatie.
Prijsnotitie
Factureerbare tekens
Wanneer u de functie tekst naar spraak gebruikt, wordt u gefactureerd voor elk teken dat wordt geconverteerd naar spraak, inclusief interpunctie. Hoewel het SSML-document zelf niet factureerbaar is, worden optionele elementen die worden gebruikt om aan te passen hoe de tekst wordt geconverteerd naar spraak, zoals telefoontjes en toonhoogte, meegeteld als factureerbare tekens. Hier volgt een lijst met factureerbare functies:
- Tekst die is doorgegeven aan de tekst naar spraakfunctie in de hoofdtekst van de SSML van de aanvraag
- Alle markeringen in het tekstveld van de aanvraagtekst in de SSML-indeling, met uitzondering
<speak>van en<voice>tags - Letters, leestekens, spaties, tabs, markeringen en alle spaties
- Elk codepunt dat is gedefinieerd in Unicode
Zie de prijzen van de Speech-service voor gedetailleerde informatie.
Belangrijk
Elk Chinees teken wordt geteld als twee tekens voor facturering, waaronder kanji die wordt gebruikt in het Japans, hanja gebruikt in het Koreaans of hanzi die in andere talen wordt gebruikt.
Trainings- en hostingtijd voor aangepaste neurale spraak modelleren
Aangepaste neurale spraaktraining en hosting worden zowel per uur berekend als gefactureerd per seconde. Zie prijzen van de Speech-service voor de prijs van de factureringseenheid.
De trainingstijd van aangepaste neurale spraak (CNV) wordt gemeten door 'rekenuur' (een eenheid om de actieve tijd van de machine te meten). Normaal gesproken worden bij het trainen van een spraakmodel twee computingtaken parallel uitgevoerd. De berekende rekenuren zijn dus langer dan de werkelijke trainingstijd. Gemiddeld duurt het minder dan één rekenuur om een CNV Lite-stem te trainen; terwijl voor CNV Pro meestal 20 tot 40 rekenuren nodig zijn om een stem in één stijl te trainen en ongeveer 90 rekenuren om een stem met meerdere stijlen te trainen. De CNV-trainingstijd wordt gefactureerd met een limiet van 96 rekenuren. Dus in het geval dat een spraakmodel wordt getraind in 98 rekenuren, worden er slechts 96 rekenuren in rekening gebracht.
Het hosten van aangepaste neurale spraak (CNV)-eindpunten wordt gemeten op basis van de werkelijke tijd (uur). De hostingtijd (uren) voor elk eindpunt wordt elke dag berekend om 00:00 UTC voor de afgelopen 24 uur. Als het eindpunt bijvoorbeeld 24 uur actief is op dag 1, wordt het 24 uur om 00:00 UTC gefactureerd op de tweede dag. Als het eindpunt zojuist is gemaakt of opgeschort gedurende de dag, wordt het gefactureerd voor de geaccumuleerde lopende tijd tot 00:00 UTC de tweede dag. Als het eindpunt momenteel niet wordt gehost, wordt het niet gefactureerd. Naast de dagelijkse berekening om 00:00 UTC elke dag, wordt de facturering ook onmiddellijk geactiveerd wanneer een eindpunt wordt verwijderd of opgeschort. Voor een eindpunt dat is gemaakt om 08:00 UTC op 1 december, wordt het hostinguur bijvoorbeeld berekend op 16 uur om 00:00 UTC op 2 december en 24 uur om 00:00 UTC op 3 december. Als de gebruiker het hosten van het eindpunt om 16:30 UTC op 3 december onderbreekt, wordt de duur (16,5 uur) van 00:00 tot 16:30 UTC op 3 december berekend voor facturering.
Persoonlijke stem
Wanneer u de persoonlijke spraakfunctie gebruikt, wordt u gefactureerd voor zowel profielopslag als synthese.
- Profielopslag: Nadat een persoonlijk spraakprofiel is gemaakt, wordt het gefactureerd totdat het van het systeem wordt verwijderd. De factureringseenheid is per spraak per dag. Als spraakopslag minder dan 24 uur duurt, wordt deze nog steeds gefactureerd als één volledige dag.
- Synthese: gefactureerd per teken. Zie de bovenstaande factureerbare tekens voor meer informatie over factureerbare tekens.
Avatar tekst naar spraak
Wanneer u de functie tekst-naar-spraak-avatar gebruikt, worden de kosten per seconde gefactureerd op basis van de lengte van de video-uitvoer. Voor de realtime avatar worden kosten echter per seconde gefactureerd op basis van de tijd waarop de avatar actief is, ongeacht of deze spreekt of stil blijft. Raadpleeg de tips 'Lokale video gebruiken voor inactiviteit' in de voorbeeldcode van de avatarchat om de kosten voor realtime avatargebruik te optimaliseren.
Aangepaste tekst-naar-spraak-avatartraining is tijd die wordt gemeten door 'rekenuur' (machineuitvoeringstijd) en gefactureerd per seconde. De duur van de training varieert, afhankelijk van de hoeveelheid gegevens die u gebruikt. Normaal gesproken duurt het gemiddeld 20-40 rekenuren om een aangepaste avatar te trainen. De avatartrainingstijd wordt gefactureerd met een limiet van 96 rekenuren. Dus in het geval dat een avatarmodel wordt getraind in 98 rekenuren, worden er slechts 96 rekenuren in rekening gebracht.
Avatar-hosting wordt per seconde per eindpunt gefactureerd. U kunt uw eindpunt onderbreken om kosten te besparen. Als u uw eindpunt wilt onderbreken, kunt u het rechtstreeks verwijderen. Als u het opnieuw wilt gebruiken, implementeert u het eindpunt opnieuw.
Metrische gegevens van Azure-tekst naar spraak bewaken
Het bewaken van belangrijke metrische gegevens die zijn gekoppeld aan tekst-naar-spraakservices is van cruciaal belang voor het beheren van resourcegebruik en het beheren van de kosten. In deze sectie wordt uitgelegd hoe u gebruiksgegevens kunt vinden in Azure Portal en gedetailleerde definities kunt opgeven van de belangrijkste metrische gegevens. Zie het overzicht van metrische gegevens van Azure Monitor voor meer informatie over metrische gegevens van Azure Monitor.
Gebruiksgegevens vinden in Azure Portal
Als u uw Azure-resources effectief wilt beheren, is het essentieel dat u regelmatig gebruiksgegevens opent en bekijkt. U kunt als volgt de gebruiksgegevens vinden:
Ga naar Azure Portal en meld u aan met uw Azure-account.
Navigeer naar Resources en selecteer uw resource die u wilt bewaken.
Selecteer Metrische gegevens onder Bewaking in het linkermenu.
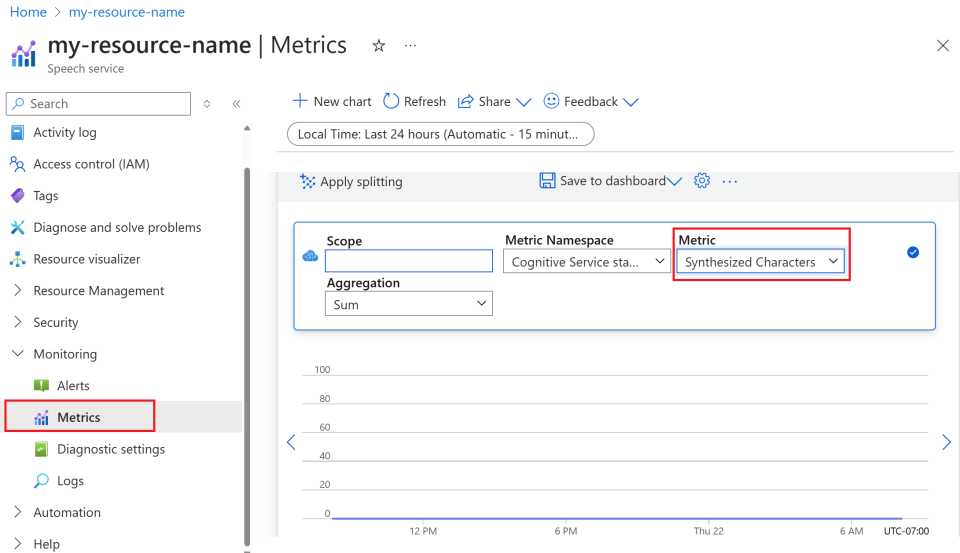
Metrische weergaven aanpassen.
U kunt gegevens filteren op resourcetype, metrische gegevenstype, tijdsbereik en andere parameters om aangepaste weergaven te maken die overeenkomen met uw bewakingsbehoeften. Daarnaast kunt u de metrische weergave opslaan in dashboards door Opslaan in dashboard te selecteren voor eenvoudige toegang tot veelgebruikte metrische gegevens.
Waarschuwingen instellen.
Als u het gebruik effectiever wilt beheren, stelt u waarschuwingen in door te navigeren naar het tabblad Waarschuwingen onder Bewaking in het linkermenu. Waarschuwingen kunnen u waarschuwen wanneer uw gebruik specifieke drempelwaarden bereikt, waardoor onverwachte kosten worden voorkomen.
Definitie van metrische gegevens
Hier volgt een tabel waarin de belangrijkste metrische gegevens voor Azure-tekst naar spraak worden samengevat.
| Naam van metrische waarde | Beschrijving |
|---|---|
| Gesynthetiseerde tekens | Houdt het aantal tekens bij dat wordt geconverteerd naar spraak, inclusief vooraf samengestelde neurale spraak en aangepaste neurale spraak. Zie Factureerbare tekens voor meer informatie over factureerbare tekens. |
| Video seconden gesynthetiseerd | Meet de totale duur van videosynthese, waaronder batch-avatarsynthese, realtime avatarsynthese en aangepaste avatarsynthese. |
| Avatar-model hosting seconden | Houdt de totale tijd bij in seconden dat uw aangepaste avatarmodel wordt gehost. |
| Hostinguren voor spraakmodel | Houdt de totale tijd bij in uren dat uw aangepaste neurale spraakmodel wordt gehost. |
| Trainingsminuten voor spraakmodel | Meet de totale tijd in minuten voor het trainen van uw aangepaste neurale spraakmodel. |
Naslagdocumentatie
Verantwoorde AI
Een AI-systeem omvat niet alleen de technologie, maar ook de mensen die het gebruiken, de mensen die worden beïnvloed door het systeem en de omgeving waarin het wordt geïmplementeerd. Lees de transparantienotities voor meer informatie over verantwoord AI-gebruik en -implementatie in uw systemen.
- Transparantienotitie en gebruiksvoorbeelden voor aangepaste neurale spraak
- Kenmerken en beperkingen voor het gebruik van aangepaste neurale spraak
- Beperkte toegang tot aangepaste neurale spraak
- Richtlijnen voor een verantwoorde implementatie van synthetische spraaktechnologie
- Openbaarmaking voor spraaktalent
- Richtlijnen voor openbaarmakingsontwerp
- Ontwerppatronen voor openbaarmaking
- Gedragscode voor tekst-naar-spraakintegraties
- Gegevens, privacy en beveiliging voor aangepaste neurale spraak